Storm编程入门API系列之Storm的Topology默认Workers、默认executors和默认tasks数目
关于,storm的启动我这里不多说了。
见博客
storm的3节点集群详细启动步骤(非HA和HA)(图文详解)
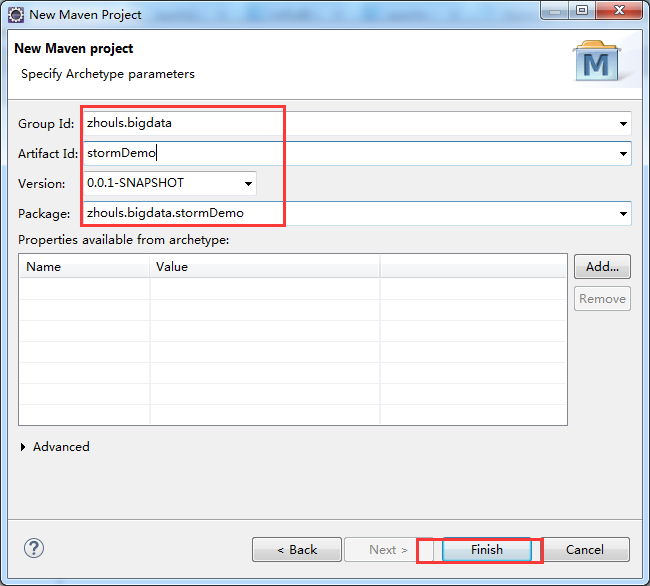
建立stormDemo项目
Group Id : zhouls.bigdata
Artifact Id : stormDemo
Package : stormDemo




<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.</modelVersion> <groupId>zhouls.bigdata</groupId>
<artifactId>stormDemo</artifactId>
<version>0.0.-SNAPSHOT</version>
<packaging>jar</packaging> <name>stormDemo</name>
<url>http://maven.apache.org</url> <properties>
<project.build.sourceEncoding>UTF-</project.build.sourceEncoding>
</properties> <dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.0.</version>
</dependency>
</dependencies>
</project>
编写代码StormTopology.java
以下是数字累加求和的例子
spout一直产生从1开始的递增数字
bolt进行汇总打印
package zhouls.bigdata.stormDemo; import java.util.Map; import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils; public class StormTopology { public static class MySpout extends BaseRichSpout{
private Map conf;
private TopologyContext context;
private SpoutOutputCollector collector;
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
this.conf = conf;
this.collector = collector;
this.context = context;
} int num = ;
public void nextTuple() {
num++;
System.out.println("spout:"+num);
this.collector.emit(new Values(num));
Utils.sleep();
} public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("num"));
} } public static class MyBolt extends BaseRichBolt{ private Map stormConf;
private TopologyContext context;
private OutputCollector collector;
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.stormConf = stormConf;
this.context = context;
this.collector = collector;
} int sum = ;
public void execute(Tuple input) {
Integer num = input.getIntegerByField("num");
sum += num;
System.out.println("sum="+sum);
} public void declareOutputFields(OutputFieldsDeclarer declarer) { } } public static void main(String[] args) {
TopologyBuilder topologyBuilder = new TopologyBuilder();
String spout_id = MySpout.class.getSimpleName();
String bolt_id = MyBolt.class.getSimpleName(); topologyBuilder.setSpout(spout_id, new MySpout());
topologyBuilder.setBolt(bolt_id, new MyBolt()).shuffleGrouping(spout_id); Config config = new Config();
String topology_name = StormTopology.class.getSimpleName();
if(args.length==){
//在本地运行
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology(topology_name, config, topologyBuilder.createTopology());
}else{
//在集群运行
try {
StormSubmitter.submitTopology(topology_name, config, topologyBuilder.createTopology());
} catch (AlreadyAliveException e) {
e.printStackTrace();
} catch (InvalidTopologyException e) {
e.printStackTrace();
} catch (AuthorizationException e) {
e.printStackTrace();
}
} } }

[hadoop@master apache-storm-1.0.]$ pwd
/home/hadoop/app/apache-storm-1.0.
[hadoop@master apache-storm-1.0.]$ ll
total
drwxrwxr-x hadoop hadoop May : bin
-rw-r--r-- hadoop hadoop Jul CHANGELOG.md
drwxrwxr-x hadoop hadoop Jul : conf
drwxrwxr-x hadoop hadoop Jul examples
drwxrwxr-x hadoop hadoop May : external
drwxrwxr-x hadoop hadoop Jul extlib
drwxrwxr-x hadoop hadoop Jul extlib-daemon
drwxrwxr-x hadoop hadoop May : lib
-rw-r--r-- hadoop hadoop Jul LICENSE
drwxrwxr-x hadoop hadoop May : log4j2
drwxrwxr-x hadoop hadoop May : logs
-rw-r--r-- hadoop hadoop Jul NOTICE
drwxrwxr-x hadoop hadoop May : public
-rw-r--r-- hadoop hadoop Jul README.markdown
-rw-r--r-- hadoop hadoop Jul RELEASE
-rw-r--r-- hadoop hadoop Jul SECURITY.md
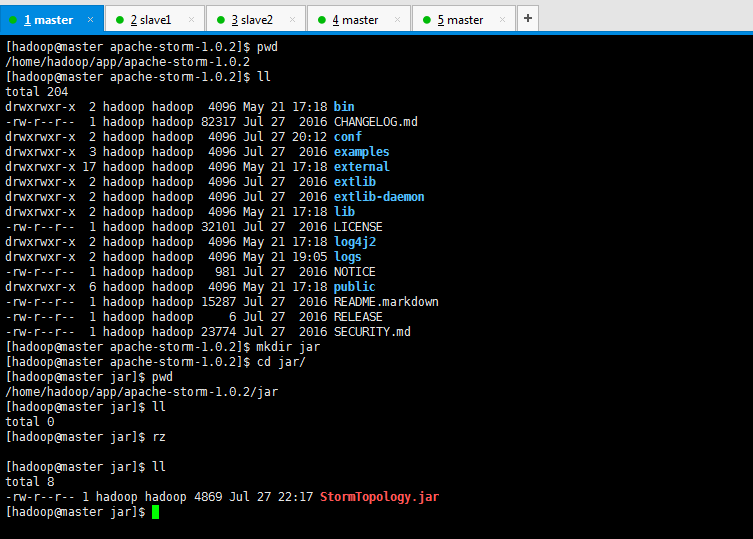
[hadoop@master apache-storm-1.0.]$ mkdir jar
[hadoop@master apache-storm-1.0.]$ cd jar/
[hadoop@master jar]$ pwd
/home/hadoop/app/apache-storm-1.0./jar
[hadoop@master jar]$ ll
total
[hadoop@master jar]$ rz [hadoop@master jar]$ ll
total
-rw-r--r-- hadoop hadoop Jul : StormTopology.jar
[hadoop@master jar]$
提交作业之前

[hadoop@master apache-storm-1.0.]$ pwd
/home/hadoop/app/apache-storm-1.0.
[hadoop@master apache-storm-1.0.]$ ll
total
drwxrwxr-x hadoop hadoop May : bin
-rw-r--r-- hadoop hadoop Jul CHANGELOG.md
drwxrwxr-x hadoop hadoop Jul : conf
drwxrwxr-x hadoop hadoop Jul examples
drwxrwxr-x hadoop hadoop May : external
drwxrwxr-x hadoop hadoop Jul extlib
drwxrwxr-x hadoop hadoop Jul extlib-daemon
drwxrwxr-x hadoop hadoop Jul : jar
drwxrwxr-x hadoop hadoop May : lib
-rw-r--r-- hadoop hadoop Jul LICENSE
drwxrwxr-x hadoop hadoop May : log4j2
drwxrwxr-x hadoop hadoop May : logs
-rw-r--r-- hadoop hadoop Jul NOTICE
drwxrwxr-x hadoop hadoop May : public
-rw-r--r-- hadoop hadoop Jul README.markdown
-rw-r--r-- hadoop hadoop Jul RELEASE
-rw-r--r-- hadoop hadoop Jul SECURITY.md
[hadoop@master apache-storm-1.0.]$ bin/storm jar jar/StormTopology.jar zhouls.bigdata.stormDemo.StormTopology aaa
Running: /home/hadoop/app/jdk/bin/java -client -Ddaemon.name= -Dstorm.options= -Dstorm.home=/home/hadoop/app/apache-storm-1.0. -Dstorm.log.dir=/home/hadoop/app/apache-storm-1.0./logs -Djava.library.path=/usr/local/lib:/opt/local/lib:/usr/lib -Dstorm.conf.file= -cp /home/hadoop/app/apache-storm-1.0./lib/log4j-api-2.1.jar:/home/hadoop/app/apache-storm-1.0./lib/kryo-3.0..jar:/home/hadoop/app/apache-storm-1.0./lib/storm-rename-hack-1.0..jar:/home/hadoop/app/apache-storm-1.0./lib/log4j-core-2.1.jar:/home/hadoop/app/apache-storm-1.0./lib/slf4j-api-1.7..jar:/home/hadoop/app/apache-storm-1.0./lib/minlog-1.3..jar:/home/hadoop/app/apache-storm-1.0./lib/objenesis-2.1.jar:/home/hadoop/app/apache-storm-1.0./lib/clojure-1.7..jar:/home/hadoop/app/apache-storm-1.0./lib/servlet-api-2.5.jar:/home/hadoop/app/apache-storm-1.0./lib/log4j-slf4j-impl-2.1.jar:/home/hadoop/app/apache-storm-1.0./lib/log4j-over-slf4j-1.6..jar:/home/hadoop/app/apache-storm-1.0./lib/storm-core-1.0..jar:/home/hadoop/app/apache-storm-1.0./lib/disruptor-3.3..jar:/home/hadoop/app/apache-storm-1.0./lib/asm-5.0..jar:/home/hadoop/app/apache-storm-1.0./lib/reflectasm-1.10..jar:jar/StormTopology.jar:/home/hadoop/app/apache-storm-1.0./conf:/home/hadoop/app/apache-storm-1.0./bin -Dstorm.jar=jar/StormTopology.jar zhouls.bigdata.stormDemo.StormTopology aaa
[main] INFO o.a.s.StormSubmitter - Generated ZooKeeper secret payload for MD5-digest: -:-
[main] INFO o.a.s.s.a.AuthUtils - Got AutoCreds []
[main] INFO o.a.s.StormSubmitter - Uploading topology jar jar/StormTopology.jar to assigned location: /home/hadoop/data/storm/nimbus/inbox/stormjar-cf402e8a-abf7-46bc-a452-14b53aa6b25e.jar
[main] INFO o.a.s.StormSubmitter - Successfully uploaded topology jar to assigned location: /home/hadoop/data/storm/nimbus/inbox/stormjar-cf402e8a-abf7-46bc-a452-14b53aa6b25e.jar
[main] INFO o.a.s.StormSubmitter - Submitting topology StormTopology in distributed mode with conf {"storm.zookeeper.topology.auth.scheme":"digest","storm.zookeeper.topology.auth.payload":"-5252258187769573644:-8540038416575654367"}
[main] INFO o.a.s.StormSubmitter - Finished submitting topology: StormTopology
[hadoop@master apache-storm-1.0.]$
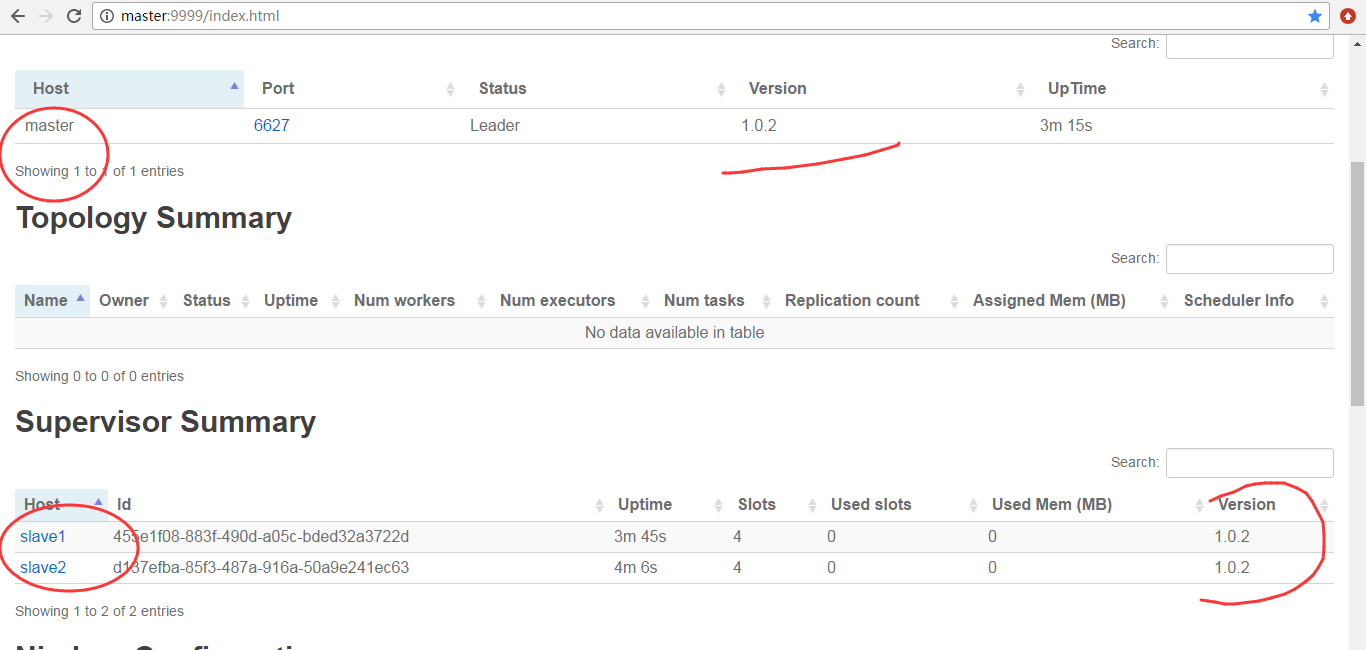
然后,查看storm 的ui界面
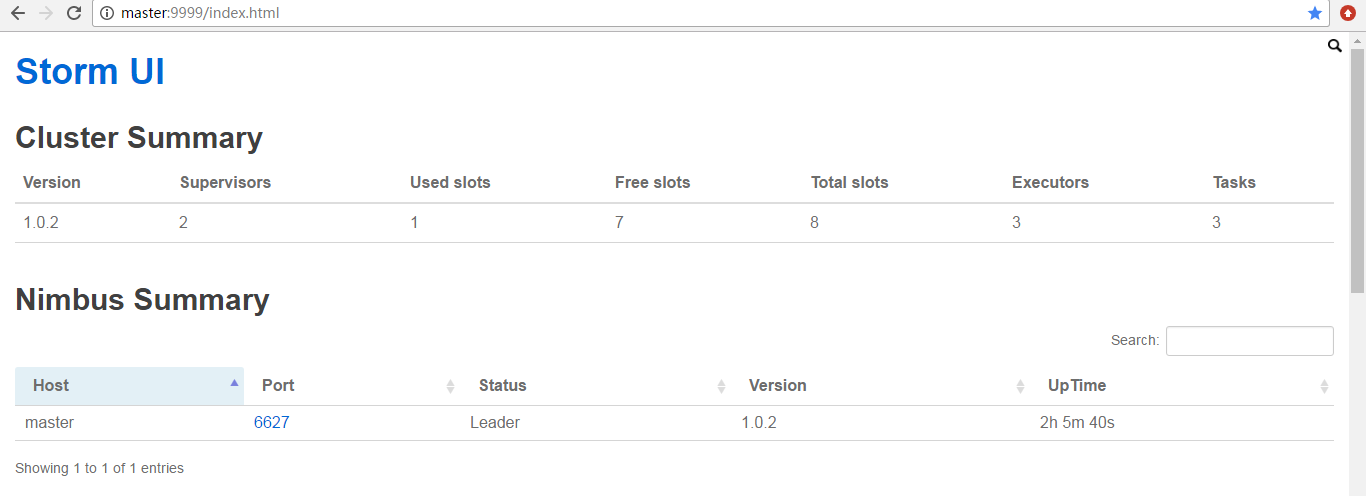


为什么,会是如上的数字呢?大家要学,就要深入去学和理解。
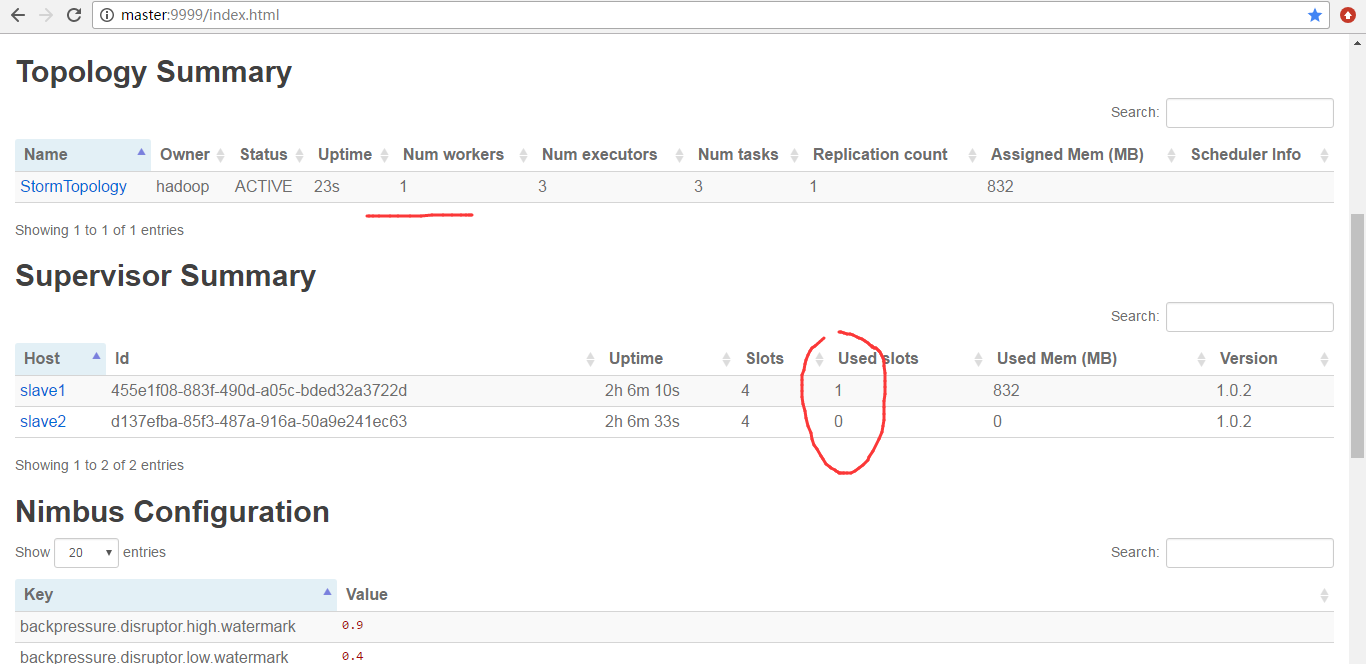
因为,默认Workers是1。所以是如上如图所示。
点击进去
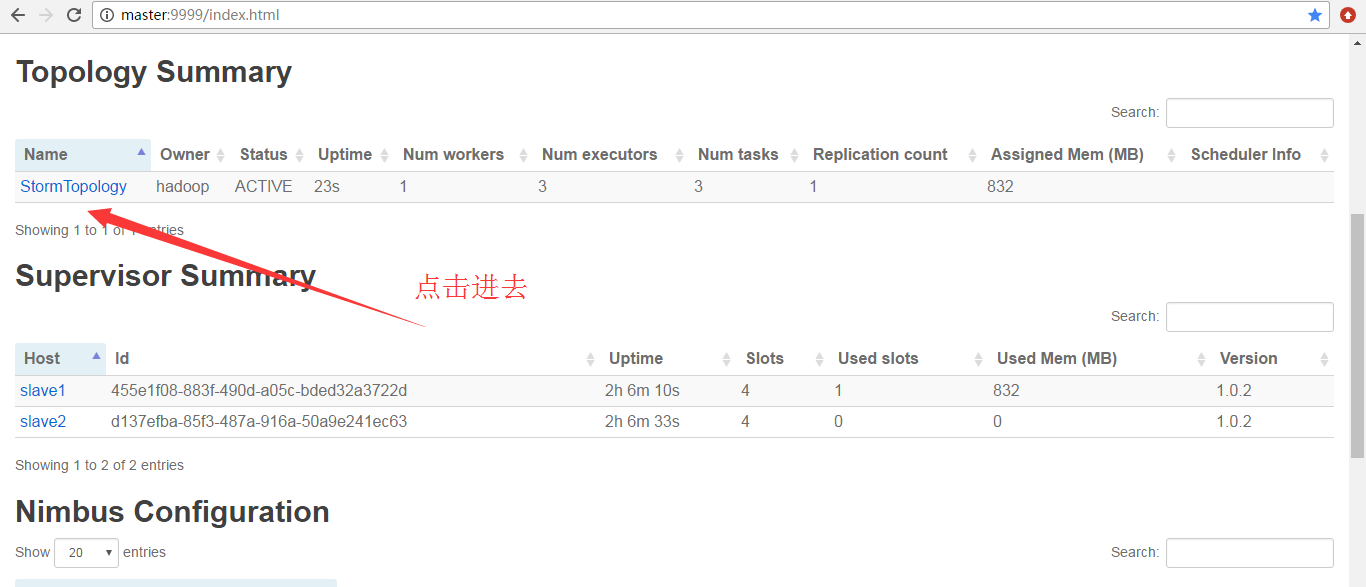

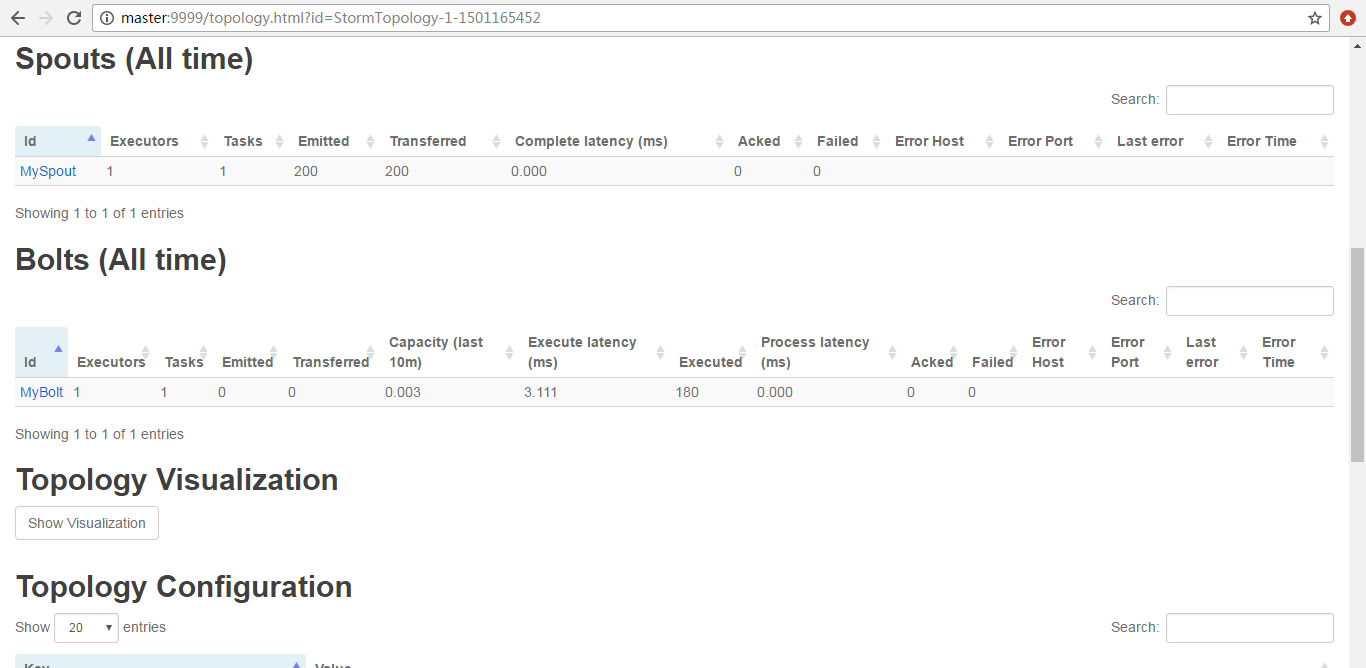


由此可见,
StormTopology默认是只有1个Worker、3个executors、3个tasks。
Storm编程入门API系列之Storm的Topology默认Workers、默认executors和默认tasks数目的更多相关文章
- Storm编程入门API系列之Storm的Topology多个Workers数目控制实现
前期博客 Storm编程入门API系列之Storm的Topology默认Workers.默认executors和默认tasks数目 继续编写 StormTopologyMoreWorker.java ...
- Storm编程入门API系列之Storm的Topology多个Executors数目控制实现
前期博客 Storm编程入门API系列之Storm的Topology默认Workers.默认executors和默认tasks数目 Storm编程入门API系列之Storm的Topology多个Wor ...
- Storm编程入门API系列之Storm的Topology多个tasks数目控制实现
前期博客 Storm编程入门API系列之Storm的Topology默认Workers.默认executors和默认tasks数目 Storm编程入门API系列之Storm的Topology多个Wor ...
- Storm编程入门API系列之Storm的定时任务实现
概念,见博客 Storm概念学习系列之storm的定时任务 Storm的定时任务,分为两种实现方式,都是可以达到目的的. 我这里,分为StormTopologyTimer1.java 和 Sto ...
- Storm编程入门API系列之Storm的Topology的stream grouping
概念,见博客 Storm概念学习系列之stream grouping(流分组) Storm的stream grouping的Shuffle Grouping 它是随机分组,随机派发stream里面的t ...
- Storm编程入门API系列之Storm的可靠性的ACK消息确认机制
概念,见博客 Storm概念学习系列之storm的可靠性 什么业务场景需要storm可靠性的ACK确认机制? 答:想要保住数据不丢,或者保住数据总是被处理.即若没被处理的,得让我们知道. publi ...
- Storm概念学习系列之storm的定时任务
不多说,直接上干货! 至于为什么,有storm的定时任务.这个很简单.但是,这个在工作中非常重要! 假设有如下的业务场景 这个spoult源源不断地发送数据,boilt呢会进行处理.然后呢,处理后的结 ...
- Storm概念学习系列之storm的可靠性
这个概念,对于理解storm很有必要. 1.worker进程死掉 worker是真实存在的.可以jps查看. 正是因为有了storm的可靠性,所以storm会重新启动一个新的worker进程. 2.s ...
- 第1节 storm编程:2、storm的基本介绍
课程大纲: 1.storm的基本介绍 2.storm的架构模型 3.storm的安装 4.storm的UI管理界面 5.storm的编程模型 6.storm的入门程序 7.storm的并行度 8.st ...
随机推荐
- im资源
https://github.com/oikomi/FishChatServer https://github.com/subrosa-io https://github.com/WhisperSys ...
- JAVA 需要理解的重点 二
1.常用设计模式 单例模式:懒汉式.饿汉式.双重校验锁.静态加载,内部类加载.枚举类加载.保证一个类仅有一个实例,并提供一个访问它的全局访问点. 代理模式:动态代理和静态代理,什么时候使用动态代理. ...
- JS正则对象 RegExp(有变量的时候使用),用来匹配搜索关键字(标红)
1,平常我们写js正则规则的时候,一般是这样写: var reg = /abc/; 然而,这样写的话,如果abc是一个变量这样就不行,我们需要下面这种写法: var abc = "汉字&qu ...
- java一些jar包的bug(不定期更新)
c3p0-0.9.5.jar 连接池jar包,常用于web项目,关闭连接池时,没有注销所有的driver 解决:可声明一个ServletContextListener的子类并设置监听,重写contex ...
- mongodb和mysql语法对比
MySQL: SELECT * FROM user Mongo: db.user.find() —————————————— MySQl: SELECT * FROM user WHERE name ...
- HrrpClient使用
使用HttpClient获取网页内容的过程 1.创建一个CloseableHttpClient类的实例: 2.使用这个实例执行HTTP请求,得到一个HttpResponse的实例: 3.最后,通过Ht ...
- Eigen::Map
http://cherishlc.iteye.com/blog/2116800 Map类 是 矩阵库Eigen中用来将内存数据 映射为 任意形状的矩阵的类.
- Identity Server 4 原理和实战(完结)_为 MVC 客户端刷新 Token
服务端修改token的过期使劲为60秒 过期了 仍然还能获取到api1的资源 api1,设置每隔一分钟就验证token 并且要求token必须要有超时时间这个参数, 1分钟后提示超时,两边都是一分钟, ...
- android系统的源代码获取(亲测可用)
1.在线阅读各版本源代码: http://androidxref.com/ 2.下载到本地: http://blog.csdn.net/yin1031468524/article/details/55 ...
- Linux环境下Nginx及负载均衡
Nginx 简介 Nginx 是一个高性能的 HTTP 和反向代理 Web 服务器,同时也提供了 IMAP/POP3/SMTP 服务.前向代理作为客户端的代理,服务端只知道代理的 IP 地址而不知道客 ...