python学习--第二天 爬取王者荣耀英雄皮肤
今天目的是爬取所有英雄皮肤
在爬取所有之前,先完成一张皮肤的爬取
打开anacond调出编译器Jupyter Notebook
打开王者荣耀官网
下拉找到位于网页右边的英雄/皮肤
点击【+更多】

进入英雄皮肤页面
按键盘F12调出网页代码
点击进入调出页的【Network】(这里是谷歌浏览器,其他浏览器可能显示为’网络‘)

刷新网页 重新接收所有网页数据(不要关闭调出的Network页)
刷新后在Network下会看到所有的数据重新加载处来
找到名为【herolist.json】的json文件(有两个随便选中一个就行
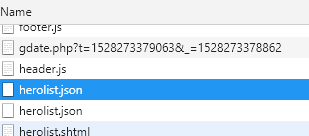
看右边会有这个文件的说明 复制这个json文件的URL地址:
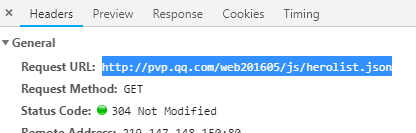
浏览器打开一个新窗口将地址粘贴进去,此时浏览器会自动下载【herolist.json】文件
在文件夹中能找到它
此时将程序写到这里
import urllib.request
import json
import os
v_herolist_url = urllib.request.urlopen('http://pvp.qq.com/web201605/js/herolist.json')
v_herolist = v_herolist_url.read()
当print(v_herolist)时,编译器底下会出现如下内容:
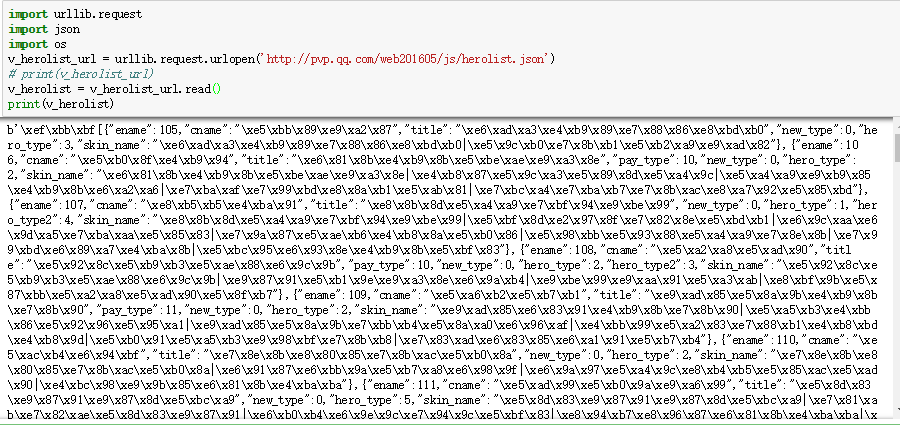
显示的\xe5\xbb这些是Unicode编码,要对它进行解码
v_herolist=v_herolist_url.read().decode('utf-8')
转换为json格式
hero_json=json.loads(v_herolist)
但此时输出的话会报错:
hero_json=json.loads(v_herolist)
print(hero_json) #报错,自己百度
v_herolist=v_herolist.encode('utf8')[:].decode('utf-8')

此时对其进行反编码并切掉python自动加入的编码方式声明’\xef\xbb\xbf‘
v_herolist=v_herolist.encode('utf8')[3:].decode('utf-8')
hero_json=json.loads(v_herolist)
print(hero_json)
爬取一张图片:
打开王者荣耀英雄/皮肤页面,随便选取一个英雄,在显示皮肤图片位置右击选中检查
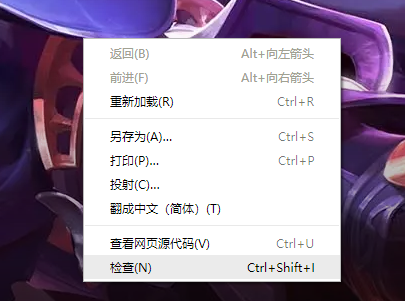
在元素页面中会有图片的地址:
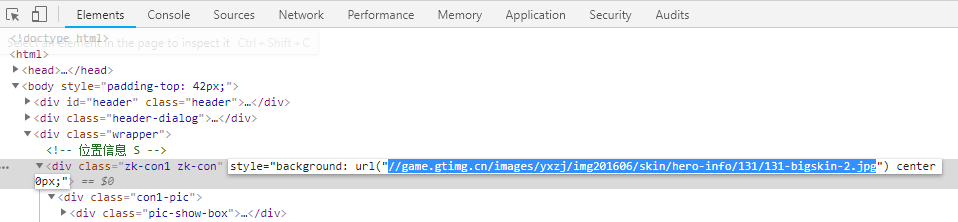
复制地址 并在首部加上 【http:】
创建本地文件夹存放图片
# 创建本地文件夹
hero_dir='D:\python practice\myhero\\' #文件夹后面要加两个‘\\’!!
if not os.path.exists(hero_dir): #如果不存在这个文件夹 自动创建
os.mkdir(hero_dir)
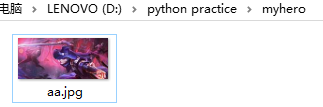
爬取这张皮肤图片
skin_url = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/131/131-bigskin-2.jpg' hero_img = hero_dir+"aa.jpg"
urllib.request.urlretrieve(skin_url,hero_img) #这里只是爬取到了一张 如何爬取多张?
爬取成功:

完整程序代码:
#王者荣耀皮肤爬取
import urllib.request
import json
import os
#爬取皮肤的json文件
v_herolist_url=urllib.request.urlopen("http://pvp.qq.com/web201605/js/herolist.json")
#请求
v_herolist=v_herolist_url.read().decode('utf-8') #要进行python字符串切割
#解码
#截取
#\xef\xbb\xbf 是python自动加入的编码方式声明 可以用正则表达式
v_herolist=v_herolist.encode('utf8')[3:].decode('utf-8')
hero_json=json.loads(v_herolist)
# 创建本地文件夹
hero_dir='D:\python practice\myhero\\'
if not os.path.exists(hero_dir):
os.mkdir(hero_dir)
skin_url = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/131/131-bigskin-2.jpg'
hero_img = hero_dir+"aa.jpg"
urllib.request.urlretrieve(skin_url,hero_img)
以下为多张皮肤爬取(只贴代码,有空详细解释):
#爬虫 -- 王者荣耀
import urllib.request
import json
import os #对计算机的操作
#json文件
v_herolist_url = urllib.request.urlopen("http://pvp.qq.com/web201605/js/herolist.json")
#请求
v_herolist = v_herolist_url.read().decode('utf-8')
#字符串的截取BOM脚本
# \xef\xbb\xbf -- python 自动加入的编码方式声明
v_hero = v_herolist.encode('utf8')[3:].decode('utf-8')
#转换json格式
#返回一个变量
hero_json = json.loads(v_hero)
#获取长度
hero_num = len(hero_json)
#皮肤网址
#http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/167/167-bigskin-5.jpg
#创建本地文件夹
hero_dir = 'D:\python practice\myhero\\'
if not os.path.exists(hero_dir):
os.mkdir(hero_dir)
for num in range(hero_num):
skinsname = hero_json[num]['skin_name'].split("|")
for i in range(len(skinsname)):
skin_name = hero_json[num]['ename']
#皮肤的数字标记
#皮肤地址
skin_url = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/'+str(skin_name)+'/'+str(skin_name)+'-bigskin-'+str(i+1)+'.jpg'
#要保存的地址
save_url=hero_dir+str(skin_name)+"_"+str(i+1)+".jpg"
urllib.request.urlretrieve(skin_url,save_url)
python学习--第二天 爬取王者荣耀英雄皮肤的更多相关文章
- Python爬取 | 王者荣耀英雄皮肤海报
这里只展示代码,具体介绍请点击下方链接. Python爬取 | 王者荣耀英雄皮肤海报 import requests import re import os import time import wi ...
- python 爬取王者荣耀英雄皮肤代码
import os, time, requests, json, re, sys from retrying import retry from urllib import parse "& ...
- 利用python爬取王者荣耀英雄皮肤图片
前两天看到同学用python爬下来LOL的皮肤图片,感觉挺有趣的,我也想试试,于是决定来爬一爬王者荣耀的英雄和皮肤图片. 首先,我们找到王者的官网http://pvp.qq.com/web201605 ...
- python爬虫---爬取王者荣耀全部皮肤图片
代码: import requests json_headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win ...
- 20行Python代码爬取王者荣耀全英雄皮肤
引言王者荣耀大家都玩过吧,没玩过的也应该听说过,作为时下最火的手机MOBA游戏,咳咳,好像跑题了.我们今天的重点是爬取王者荣耀所有英雄的所有皮肤,而且仅仅使用20行Python代码即可完成. 准备工作 ...
- Python 爬取 "王者荣耀.英雄壁纸" 过程中的矛和盾
1. 前言 学习爬虫,最好的方式就是自己编写爬虫程序. 爬取目标网站上的数据,理论上讲是简单的,无非就是分析页面中的资源链接.然后下载.最后保存. 但是在实施过程却会遇到一些阻碍. 很多网站为了阻止爬 ...
- 用Python爬取"王者农药"英雄皮肤
0.引言 作为一款现象级游戏,王者荣耀,想必大家都玩过或听过,游戏里中各式各样的英雄,每款皮肤都非常精美,用做电脑壁纸再合适不过了.本篇就来教大家如何使用Python来爬取这些精美的英雄皮肤. 1.环 ...
- 用Python爬取"王者农药"英雄皮肤 原
padding: 10px; border-bottom: 1px solid #d3d3d3; background-color: #2e8b57; } .second-menu-item { pa ...
- python爬取王者荣耀全英雄皮肤
import os import requests url = 'https://pvp.qq.com/web201605/js/herolist.json' herolist = requests. ...
随机推荐
- Linux下安装gnuplot
sudo apt-get install gnuplot 但是在 terminal 里面输入: gnuplot 提示 Terminal type set to unknown.解决方法是安装 x11: ...
- MySQL使用版本号实现乐观锁
原创转载请注明出处:https://www.cnblogs.com/agilestyle/p/11608581.html 乐观锁适用于读多写少的应用场景 乐观锁Version图示 Project D ...
- 如何通过Dataphin构建数据中台新增100万用户?
欢迎来到数据中台小讲堂!这一期我们来看看,作为阿里巴巴数据中台(OneData - OneModel.OneID.OneService)方法论的产品载体,Dataphin如何帮助传统零售企业实现数字化 ...
- 数据挖掘:WAP-Tree与PLWAP-Tree
简介 我们首先应该从WAP-Tree说起,下面一段话摘自<Effective Web Log Mining using WAP Tree-Mine>原文 Abstract -World W ...
- 认识setFactory
平常设置或者获取一个View时,用的较多的是setContentView或LayoutInflater#inflate,setContentView内部也是通过调用LayoutInflater#inf ...
- sql:CallableStatement执行存储过程
/** * 使用CablleStatement调用存储过程 * @author APPle * */ public class Demo1 { /** * 调用带有输入参数的存储过程 * CALL p ...
- jQuery-resize和scroll的性能优化
## 下面是进行测试和研究怎么实现的用的 Document 改变页面大小试试 Document 滚动滚动条试试
- Linux下MySQL 命令导入导出sql文件
导出数据库 直接使用命令: mysqldump -u root -p database >database.sql 然后回车输入密码就可以了: mysqldump -u 数据库链接用户名 -p ...
- USACO 6.5 章节 世界上本没有龙 屠龙的人多了也便有了
All Latin Squares 题目大意 n x n矩阵(n=2->7) 第一行1 2 3 4 5 ..N 每行每列,1-N各出现一次,求总方案数 题解 n最大为7 显然打表 写了个先数值后 ...
- KMP算法——字符匹配
暴力匹配: 假设现在我们面临这样一个问题:有一个文本串S,和一个模式串P,现在要查找P在S中的位置,怎么查找呢? 如果用暴力匹配的思路,并假设现在文本串S匹配到 i 位置,模式串P匹配到 j 位置, ...