梯度提升树GBD
转自 http://blog.csdn.net/u014568921/article/details/49383379
另外一个很容易理解的文章 :http://www.jianshu.com/p/005a4e6ac775
更多参考如下
Gradient Boosting Decision Tree,即梯度提升树,简称GBDT,也叫GBRT(Gradient Boosting Regression Tree),也称为Multiple Additive Regression Tree(MART),阿里貌似叫treelink。
首先学习GBDT要有决策树的先验知识。
Gradient Boosting Decision Tree,和随机森林(random forest)算法一样,也是通过组合弱学习器来形成一个强学习器。GBDT的发明者是Friedman,至于随机森林则是Friedman的好基友Breiman发明的。不过,GBDT算法中用到的决策树只能是回归树,这是因为该算法的每颗树学的是之前所有树结论之和的残差,这个残差就是一个累加预测值后能得到真实值。通过将每次预测出的结果与目标值的残差作为下一次学习的目标。
想看英文原文的:
greedy function approximation :a gradient boosting machine.--GBDT发明者Friedman的文章
Stochastic gradient boosting。还是Friedman的
Boosted Regression (Boosting): An introductory tutorial and a Stata plugin。
决策树
以CART决策树为例,简单介绍一下回归树的构建方法。



下面介绍gradient boost。
gradient boost
Boost是”提升”的意思,一般Boosting算法都是一个迭代的过程,每一次新的训练都是为了改进上一次的结果。我们熟悉的adaboost算法是boost算法体系中的一类。gradient boost也属于boost算法体系。
Gradient Boost其实是一个框架,里面可以套入很多不同的算法。每一次的计算都是为了减少上一次的残差,为了消除残差,我们可以在残差减少的梯度方向建立一个新的模型,所以说,每一个新模型的建立都为了使得之前的模型残差向梯度方向上减少。它用来优化loss function有很多种。

下面是通用的gradient boost框架



要学习的回归树的参数就是每个节点的分裂属性、最佳切点和节点的预测值。


GBDT算法流程

Friedman的文章greedy function approximation :a gradient boosting machine.中的least-square regression算法如下:

里面yi-Fm-1求得的即是残差,每次就是在这个基础上学习。
两个版本的GBDT
目前GBDT有两个不同的描述版本,网上写GBDT的大都没有说清楚自己说的是哪个版本,以及不同版本之间的不同是什么,读者看不同的介绍会得到不同的算法描述,实在让人很头痛。
残差版本把GBDT说成一个残差迭代树,认为每一棵回归树都在学习前N-1棵树的残差,前面所说的主要在描述这一版本。
Gradient版本把GBDT说成一个梯度迭代树,使用梯度下降法求解,认为每一棵回归树在学习前N-1棵树的梯度下降值。
要解决问题还是阅读Friedman的文章。
读完greedy function approximation :a gradient boosting machine.后,发现4.1-4.4写的是残差版本的GBDT,这一个版本主要用来回归;4.5-4.6写的是Gradient版本,它在残差版本的GBDT版本上做了Logistic变换,Gradient版本主要是用来分类的。
分类问题与回归问题不同,每棵树的样本的目标就不是一个数值了,而是每个样本在每个分类下面都有一个估值Fk(x)。
同逻辑回归一样,假如有K类,每一个样本的估计值为F1(x)...Fk(x),对其作logistic变化之后得到属于每一类的概率是P1(x)...pk(x),

则损失函数可以定义为负的log似然:

其中,yk为输入的样本数据的估计值,当一个样本x属于类别k时,yk = 1,否则yk = 0。
将Logistic变换的式子带入损失函数,并且对其求导,可以得到损失函数的梯度:

可以看出对多分类问题,新的一棵树拟合的目标仍是残差向量。
用Logistic变换后的算法如下:

对第一棵树,可以初始化每个样本在每个分类上的估计值Fk(x)都为0;计算logistic变换pk(x),计算残差向量,作为当前树的回归的目标,回归树的分裂过程仍可采用【左子树样本目标值(残差)和的平方均值+右子树样本目标值(残差)和的平方均值-父结点所有样本目标值(残差)和的平方均值】最大的那个分裂点与分裂特征值等方法;当回归树的叶子节点数目达到要求示,则该树建立完成;对每个叶子节点,利用落到该叶子节点的所有样本的残差向量,计算增益rjkm;更新每一个样本的估计值Fk(x);因此,又可以对估计进行logistic变化,利用样本的目标值计算残差向量,训练第二棵树了。
正则化regularization
Shrinkage:即学习率
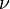 就是学习率。 一般情况下,越小的学习率,可以越好的逼近预测值,不容易产生过拟合,迭代次数会增加,经验上一般选取0.1左右。
就是学习率。 一般情况下,越小的学习率,可以越好的逼近预测值,不容易产生过拟合,迭代次数会增加,经验上一般选取0.1左右。

使用缩减训练集
Friedman提出在每次迭代时对base learner从原始训练集中随机抽取一部分(a subsample of the training set drawn at random without replacement)作为本次base learner去拟合的样本集可以提高算法最后的准确率。
限制叶节点中样本的数目
这个在决策树中已经提到过。
剪枝
这个在决策树中已经提到过。
限制每颗树的深度
树的深度一般取的比较小,需要根据实际情况来定。
迭代的次数d
也即最多有多少棵树,树太多可能造成过拟合,即在训练集上表现很好,测试集上表现糟糕;太少则会欠拟合。树的棵树和shrink有关,shrink越小,树会越多。
几个细节提一下
对初始分类器(函数)的选择就可以直接用0,通过平方差LOSS函数求得的残差当然就是样本本身了;也可以选择样本的均值;
一棵树的分裂过程只需要找到找到每个结点的分裂的特征id与特征值,而寻找的方法可以是平均最小均方差,也可以是使得(左子树样本目标值和的平方均值+右子树样本目标值和的平方均值-父结点所有样本目标值和的平方均值)最大的那个分裂点与分裂特征值等等方法;从而将样本分到左右子树中,继续上面过程;
注意样本的估计值Fk(x)是前面所有树的估值之和,因此,计算残差时,用样本的目标值减去Fk(x)就可以得到残差了
http://www.cnblogs.com/LeftNotEasy/archive/2011/03/07/random-forest-and-gbdt.html这篇文章关于分类讲得比较好,借鉴了他写的一些,例子也很好,大家可以看看。
https://github.com/MLWave/Kaggle-Ensemble-Guide
梯度提升树GBD的更多相关文章
- scikit-learn 梯度提升树(GBDT)调参小结
在梯度提升树(GBDT)原理小结中,我们对GBDT的原理做了总结,本文我们就从scikit-learn里GBDT的类库使用方法作一个总结,主要会关注调参中的一些要点. 1. scikit-learn ...
- 梯度提升树(GBDT)原理小结
在集成学习之Adaboost算法原理小结中,我们对Boosting家族的Adaboost算法做了总结,本文就对Boosting家族中另一个重要的算法梯度提升树(Gradient Boosting De ...
- 笔记︱决策树族——梯度提升树(GBDT)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 本笔记来源于CDA DSC,L2-R语言课程所 ...
- 梯度提升树(GBDT)原理小结(转载)
在集成学习值Adaboost算法原理和代码小结(转载)中,我们对Boosting家族的Adaboost算法做了总结,本文就对Boosting家族中另一个重要的算法梯度提升树(Gradient Boos ...
- 机器学习 之梯度提升树GBDT
目录 1.基本知识点简介 2.梯度提升树GBDT算法 2.1 思路和原理 2.2 梯度代替残差建立CART回归树 1.基本知识点简介 在集成学习的Boosting提升算法中,有两大家族:第一是AdaB ...
- Spark Gradient-boosted trees (GBTs)梯度提升树
梯度提升树(GBT)是决策树的集合. GBT迭代地训练决策树以便使损失函数最小化. spark.ml实现支持GBT用于二进制分类和回归,可以使用连续和分类特征. 导入包 import org.apac ...
- 梯度提升树GBDT算法
转自https://zhuanlan.zhihu.com/p/29802325 本文对Boosting家族中一个重要的算法梯度提升树(Gradient Boosting Decison Tree, 简 ...
- GBDT(梯度提升树)scikit-klearn中的参数说明及简汇
1.GBDT(梯度提升树)概述: GBDT是集成学习Boosting家族的成员,区别于Adaboosting.adaboosting是利用前一次迭代弱学习器的误差率来更新训练集的权重,在对更新权重后的 ...
- 04-07 scikit-learn库之梯度提升树
目录 scikit-learn库之梯度提升树 一.GradietBoostingClassifier 1.1 使用场景 1.2 参数 1.3 属性 1.4 方法 二.GradietBoostingCl ...
随机推荐
- 2019杭电多校第四场hdu6623 Minimal Power of Prime
Minimal Power of Prime 题目传送门 解题思路 先打\(N^\frac{1}{5}\)内的素数表,对于每一个n,先分解\(N^\frac{1}{5}\)范围内的素数,分解完后n变为 ...
- 如何在webpack开发中利用vue框架使用ES6中提供的新语法
在webpack中开发,会遇到一大推问题,特别是babel6升级到babel7,要跟新一大推插件,而对于安装babel的功能就是在webpack开发中,vue中能够是用ES6的新特性: 例如ES6中的 ...
- 把多个JavaScript函数绑定到onload事件处理函数上的技巧
一,onload事件发生条件 用户进入页面且页面所有元素都加载完毕.如果在页面的初始位置添加一个JavaScript函数,由于文档没有加载完毕,DOM不完整,可能导致函数执行错误或者达不到我们想要的效 ...
- jmeter 响应超时时间设置 压力增大,不能正常退出全部线程
当压力增大会出现connect timeout error 压力增大,不能正常退出全部线程: 解决办法:http request default--advance--timeouts 如填写1,表示大 ...
- SpringBoot开发详解(五)--Controller接收参数以及参数校验
原文链接:http://blog.csdn.net/qq_31001665 如有侵权,请联系博主删除博客,谢谢 Controller 中注解使用 接受参数的几种传输方式以及几种注解: 在上一篇中,我 ...
- python图像、视频转字符画
python图像转字符画需要用到matplotlib.pyplot库,视频转字符画需要用到opencv库,这里的代码基于python 3.5 图像转字符画需要先将图像转为灰度图,转灰度图的公式是 gr ...
- LeetCode Array Easy 88. Merge Sorted Array
Description Given two sorted integer arrays nums1 and nums2, merge nums2 into nums1 as one sorted ar ...
- 牛客多校第六场-H-Pair
链接:https://ac.nowcoder.com/acm/contest/887/H来源:牛客网 题目描述 Given three integers A, B, C. Count the numb ...
- 【sql】牛客网练习题 (共 61 题)
[1]查找最晚入职员工的所有信息 CREATE TABLE `employees` ( `emp_no` ) NOT NULL, `birth_date` date NOT NULL, `first_ ...
- VMware下Ubuntu全屏显示
开始是这样的 完了之后应该是这样的 1.点开菜单栏的 虚拟机---------> 安装VMware Tools 安装完了之后桌面会出现一个这样的图标 双击这个DVD,进去之后左侧目录出现了 ...