KNN算法之KD树
KD树算法是先对数据集进行建模,然后搜索最近邻,最后一步是预测。
KD树中的K指的是样本特征的维数。
一、KD树的建立
m个样本n维特征,计算n个特征的方差,取方差最大的第k维特征作为根节点。选择第k维特征的中位数作为切分点,小于中位数的放左子树,大于中位数的放右子树,递归生成。

举例
有二维样本6个,{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)}:
1、找根节点,6个数据点在x、y维度上的方差分别是6.97,5.37,x维度方差最大,因此选择x维进行键树;
2、找切分点,x维中位数是(7,2),因此以这个点的x维度的取值进行划分;
3、x=7将空间分为左右两个部分,然后递归使用此方法,最后结果为:

(7,2)
/ \
(5,4) (9,6)
/ \ /
(2,3)(4,7) (8,1)
二、搜索最近邻
先找到包含目标点的叶子节点,然后以目标点为圆心,目标点到叶子节点距离为半径,得到超球体。最近邻的点一点在内部。
返回叶子节点的父节点,检查另一个叶子节点包含的超矩体是否和这个超球体相交,相交的话在这个叶子节点寻找有没有更近的近邻,更新。当回溯到根节点时,结束。此时保存的节点就是最近邻节点。
KD树划分后可以大大减少无效的最近邻搜索,很多样本点由于所在的超矩形体和超球体不相交,根本不需要计算距离。大大节省了计算时间。
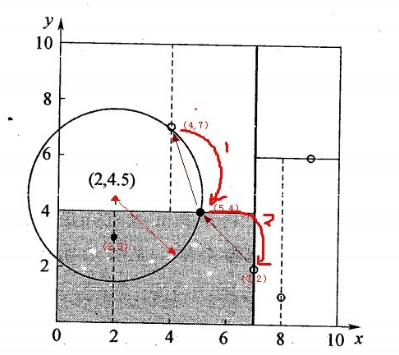
1、对(2,4.5)搜索最近邻,先从(7,2)开始找,2<7因此在左子树;
2、4.5>4,在右子空间找到叶子节点(4,7),计算距离为3.202,以它为半径得到超球体,返回父节点(5,4);
3、计算父节点与(2,4.5)的距离=3.041<3.202,更新保存的最近节点,同时由于左子空间与超球体相交,所以到左子空间中找有没有叶子节点;
4、左子空间中(2,3)节点与目标节点更近,找到最近邻。
三、KD树预测
在kd树搜索最近邻的基础上,选择到了第一个最近邻样本,把它设置为已选,然后第二轮中忽略这个样本,重新找最近邻。
四、球树
kd树对样本分布不均匀时,效果不好。
球树:每个分割快都是超球体。
过程:从球中选择一个离球的中心最远的点,然后选择第二个点离第一个点最远,将所有的点分配到这两个点上,计算聚类中心,然后对这两个小超球体递归使用这个方法
KNN算法之KD树的更多相关文章
- KNN算法与Kd树
最近邻法和k-近邻法 下面图片中只有三种豆,有三个豆是未知的种类,如何判定他们的种类? 提供一种思路,即:未知的豆离哪种豆最近就认为未知豆和该豆是同一种类.由此,我们引出最近邻算法的定义:为了判定未知 ...
- 【分类算法】K近邻(KNN) ——kd树(转载)
K近邻(KNN)的核心算法是kd树,转载如下几个链接: [量化课堂]一只兔子帮你理解 kNN [量化课堂]kd 树算法之思路篇 [量化课堂]kd 树算法之详细篇
- 从K近邻算法谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/v_july_v/article/details/8203674 ,感谢july的辛勤劳动 前言 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章 ...
- <转>从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/likika2012/article/details/39619687 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章待写:1.KD树:2.神经 ...
- 从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转载自:http://blog.csdn.net/v_july_v/article/details/8203674/ 从K近邻算法.距离度量谈到KD树.SIFT+BBF算法 前言 前两日,在微博上说: ...
- KNN 算法-实战篇-如何识别手写数字
公号:码农充电站pro 主页:https://codeshellme.github.io 上篇文章介绍了KNN 算法的原理,今天来介绍如何使用KNN 算法识别手写数字? 1,手写数字数据集 手写数字数 ...
- KD树
k-d树 在计算机科学里,k-d树( k-维树的缩写)是在k维欧几里德空间组织点的数据结构.k-d树可以使用在多种应用场合,如多维键值搜索(例:范围搜寻及最邻近搜索).k-d树是空间二分树(Binar ...
- 【数据结构与算法】k-d tree算法
k-d tree算法 k-d树(k-dimensional树的简称),是一种分割k维数据空间的数据结构.主要应用于多维空间关键数据的搜索(如:范围搜索和最近邻搜索). 应用背景 SIFT算法中做特征点 ...
- 一看就懂的K近邻算法(KNN),K-D树,并实现手写数字识别!
1. 什么是KNN 1.1 KNN的通俗解释 何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:K个最近的邻居,当K=1 ...
随机推荐
- 20191128 Spring Boot官方文档学习(9.11-9.17)
9.11.消息传递 Spring Boot提供了许多包含消息传递的启动器.本部分回答了将消息与Spring Boot一起使用所引起的问题. 9.11.1.禁用事务JMS会话 如果您的JMS代理不支持事 ...
- if——while表达式详解
①while循环的表达式是循环进行的条件,用作循环条件的表达式中一般至少包括一个能够改变表达式的变量,这个变量称为循环变量 ②当表达式的值为真(非零)(非空)时,执行循环体:为假(0)时,则循环结束 ...
- win10安装mysql时报错[MY-012576] [InnoDB] Unable to create temporary file; errno: 2
报错信息 解决: 在my.ini文件里面的 [mysqld]区段内加入: #自己指定的临时文件目录 tmpdir="临时目录" 添加好后初始化成功 接下来启动mysql服务的时候报 ...
- Win10使用自带功能创建系统映像备份时D盘被包含进去问题的解决
在使用Windows10系统时,使用Windows自带功能创建系统映像备份文件时碰到了一些问题,所以在此记录一下. 创建系统映像文件的步骤,如下: 1.打开 控制面板 -> 选择 系统和安全 - ...
- package.json的所有配置项及其用法,你都熟悉么
写在前面 在前端开发中,npm已经是必不可少的工具了.使用npm,不可避免的就要和package.json打交道.平时package.json用得挺多,但是没有认真看过官方文档.本文结合npm官方文档 ...
- Python中函数传递参数有四种形式
Python中函数传递参数有四种形式 fun1(a,b,c) fun2(a=1,b=2,c=3) fun3(*args) fun4(**kargs) 四种中最常见是前两种,基本上一般点的教程都会涉及, ...
- Windows 10 IoT Core Dashboard 无法安装的问题
有人在answers.microsoft.com问这个问题,官方给了个这样的回答,然后还锁定了问题不让别人回复 您好, 了解到您在使用时遇到问题. 请您详细描述下您的操作,请问您是在打开安装程序还是在 ...
- application session 实现简单的在线聊天人数的统计
写了快一年的asp.net,application对象还真没怎么用过.看了看书,根据这两个对象的特性写了一个简单的聊天室程序.真的是非常的简陋 ASP.Net中有两个重要的对象,一个是applicat ...
- 公用flex类
开发过程中,很多布局,用antd的栅格还是不灵活,flex弹性布局会更好用 Flex 是 Flexible Box 的缩写,意为"弹性布局",用来为盒状模型提供最大的灵活性. 注意 ...
- 继续死磕python
一.数据运算 算术运算 比较运算 赋值运算 逻辑运算 成员运算 身份运算 位运算 其中左右移运算是逻辑左右移即缺失位补0,而算数右移缺失补符号位(注意逻辑运算都是补码运算即都取补码再运算,然后结果也是 ...