SQL索引学习-聚集索引
这篇接着我们的索引学习系列,这次主要来分享一些有关聚集索引的问题。上一篇SQL索引学习-索引结构主要是从一些基础概念上给大家分享了我的理解,没有实例,有朋友就提到了聚集索引的问题,这里列出来一下:

- 其实,我想知道的就是对于一个大数据量的表,我应该用哪种索引,各有什么优缺点。如果能带一两个实例,就更perfect了。
- 看过很多这样文章,但具体还是不知道如何设计表和优化,比如:聚集和非聚集, 唯一与主键, 设计表事该如何取舍。应该有示例说明,这更容易理解,只是概念即使理解了也不容易消化。
上面两位朋友的问题有一个共同特点,就是希望有示例,因为这样容易让他们更加容易理解。但从我的角度来讲,有示例只能给你提供一个参考而已,够不成是否容易消化的关键因素,最好的办法是,通过自己的理解,自己有能力去做相应的实验,这样效果才是最好的,你也会发现更多的问题,每个项目都有自己的特点,所以性能优化这块也是需要因地制宜的。
聚集索引的存储结构

聚集索引的特点
- 索引的数据以及实际物理数据存储于同一张表中,这与非聚集索引不相同
- 物理数据或者叫关键字出现在叶子结点的双向链表中
- 非叶子结点不可能出现物理数据或者叫关键字
- 非叶子结点相当于叶子结点的索引
B+树的结构
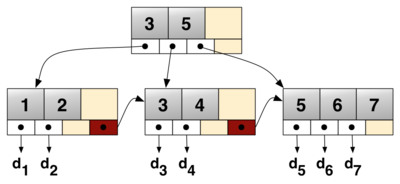
- 1,2,3,4,5,6,7为Key
- d1,d2,d3,d4,d5,d6,d7分别是数据
- 红色框是链接下一节点的指针
它的结构完全符合聚集索引的存储结构,所以我们说聚集索引的存储结构为B+树。
聚集索引的重要性
聚集索引的选择是数据库设计的基石,不好的聚集索引设计不光是增加查询的执行时间,而且是一个瀑布性的影响:
- 增加硬盘空间,和选择的数据列的大小有直接关系
- 效率低下的IO,也许会产生更多的数据页,或者发生随机性的数据页切换等
- 索引碎片的增加
- ......
如何选择表的聚集索引
一般可以优先参考如下因素:
- 列数据宽度要小或者叫窄列,比如int就只有4字节,这个宽度越小越好,因为可以在同样的空间中存储更多的索引数据
- 唯一性,虽然聚集索引并没强制要求列字段是唯一的,但在系统内部会在具备有重复值的列上增加一个标识位来区分,实际内部还是唯一的,所以尽量选择重复值很少最好是没有重复值的列,因为SQL Sever要额外的去维护这些标识
- 静态的,不易更改的列,很少发生变更最好是从不修改这列的值,因为它也许会引起数据的移动
- 递增性的,用来避免索引碎片,这样SQL Server每次在插入数据的时候都会将新记录追加在最新一条记录的后面,不会因此影响之前插入的数据顺序。
窄列
创建如下表,为了测试只包含两个字段,一个在类型为Int的Id上创建聚集索引,一个在类型为uniqueindentifier的Code上创建聚集索引,且为唯一聚集索引。
CREATE TABLE dbo.NarrowStudent
(
Id INT IDENTITY(1, 1) , -- unique
Code UNIQUEIDENTIFIER -- unique ) ; CREATE UNIQUE CLUSTERED INDEX PK_NarrowStudent_Id
ON NarrowStudent(Id)
CREATE TABLE dbo.Student
(
Id INT IDENTITY(1, 1) , -- unique
Code UNIQUEIDENTIFIER -- unique ) ; CREATE UNIQUE CLUSTERED INDEX PK_Student_Code
ON Student(Code)
再分别插入一条数据:
INSERT INTO dbo.NarrowStudent
( Code )
VALUES ( NEWID() -- Code - uniqueidentifier
) INSERT INTO dbo.Student
( Code )
VALUES ( NEWID() -- Code - uniqueidentifier
)
看下行大小:
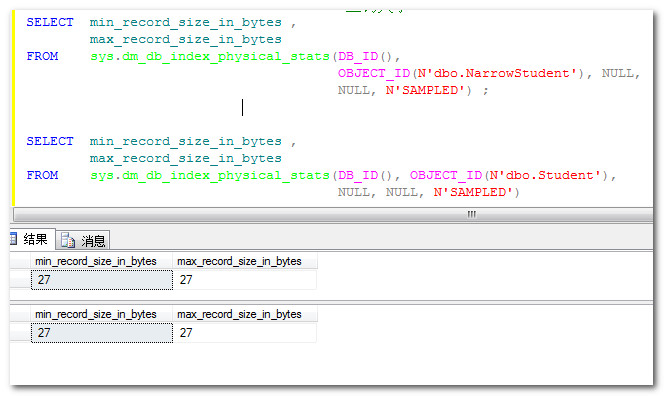
注意为什么宽度为27而不是20呢(Id类型为int,占用4字节,Code为Guid占用16字节),这是SQL Sever内部为了维护可空值或者是可变长值而预留7位空间。
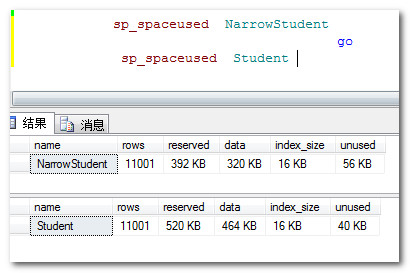
我们再多插入些数据来做对比,插入的脚本就贴了,然后我们看下两表所占用的空间对比:采用了int做为主键的表数据占用为320K,选用Guid为主键的表占用为464K,明显较int要费磁盘空间。
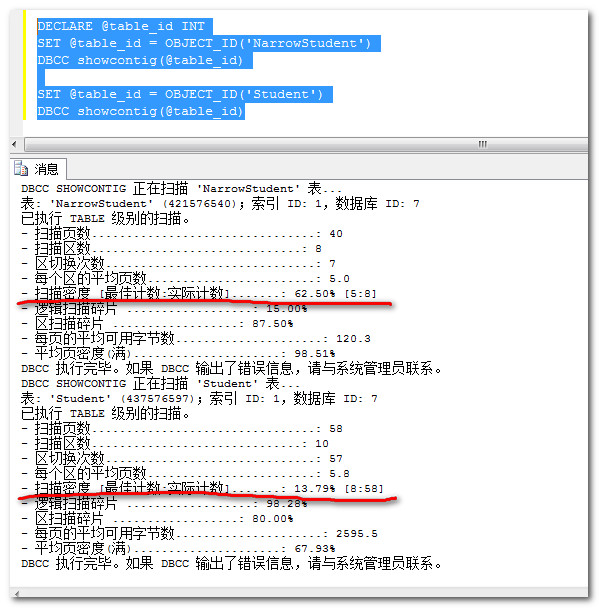
索引健康情况
下图中红线部分有一个非常重要的参数:扫描密度,明显可以看出在连续对表进行数据插入后,int自增性为主键的索引密度比Guid为主键的索引密度要大的多。这说明前者产生的索引碎片更低。
聚集索引对非聚集索引的影响
两者最大的区别在于聚集索引的叶级存储了数据本身,但非聚集索引叶结点不存在数据记录,只是一个指向聚集索引的指针,这就意味着在非聚集索引的所有级别中都包含了聚集索引的指针,聚集索引的大小会直接影响非聚集索引的大小。
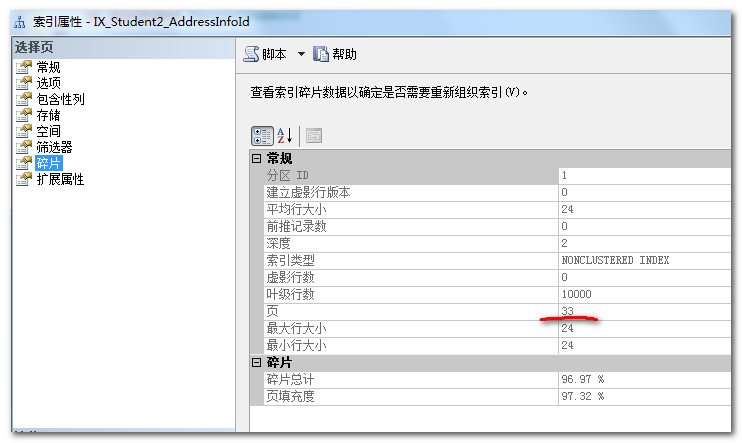
为上面两个表,增加一个AddressInfo的字段,且创建非聚集索引,这里为了测试的有效性,不要使用如下语句添加列之后做测试,因为后期表结构的变更会引起比较明显的数据分页情况,建议创建新表来测试,下面对比在两个表中,字段类型以及值者相同以及表数据条数一样的情况下非聚集索引的大小情况,结论是在其它条件都相同的情况下,谁的主键大谁占用的索引空间就更大。
主键为int的非聚集索引
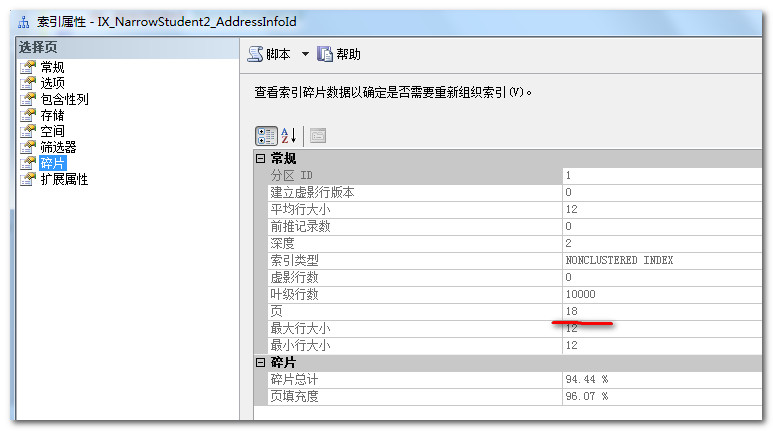
主键为Guid的非聚集索引
唯一性
上面提到过聚集索引可以选择具有重复值的列,但在内部会维护一个类型为uniqueifier的字段,长度为4字节,同时还会需要维护可变长列,同样会占用4字节,所以SQL Server会使每行的大小增加8字节,数据类似如下表格:
| Id | First Name | uniqueifier |
| 1 | Tom | NULL |
| 2 | Tom | 1 |
| 3 | Andy | Null |
关键字第一次出现时,uniqueifier赋值为NULL,当第二次出现时,就开始计数累加。赋值为NULL时占用0字节,可从如一图得到结果:
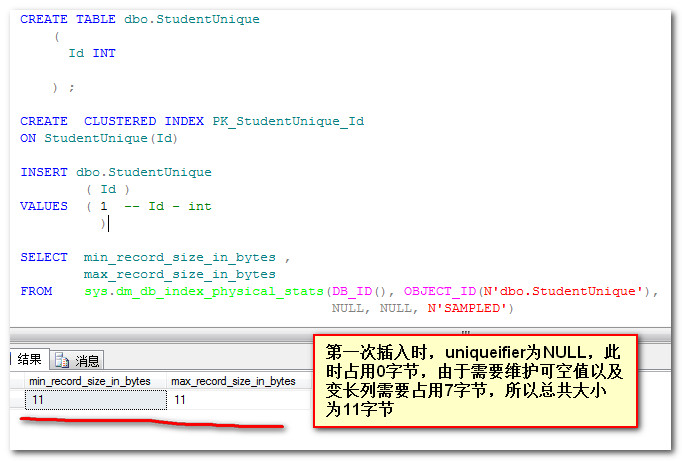
再插入一条重复数据之后再查看行大小,由11字节变成19字节了,这多出来的8字节,就是当uniqueifier值不等于空之后的结果。
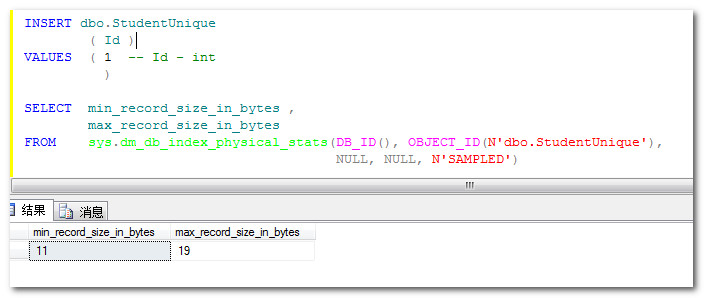
这里列一个场景:如果选择一个时间字段做为主键的话,此时瞬间批量插入多条数据,那么时间在某一批数据中都是相同的,这时就需要频繁维护uniqueifier。重复的数据越多,后续索引的命中就会越困难,同时由于行大小变大会降低磁盘空间的应用,从而降低IO性能。
这篇内容比较长,先讲其中的窄列以及唯一性这两原则吧,这只是从性能角度来区分,没有涉及具体业务,所以并不是说一定要按此标准来选择聚集索引,后面再分析其它的几条规则。
SQL索引学习-聚集索引的更多相关文章
- SQL查询优化:详解SQL Server非聚集索引(转载)
本文是转载,原文地址 http://tech.it168.com/a2011/1228/1295/000001295176.shtml 在SQL SERVER中,非聚集索引其实可以看作是一个含有聚集索 ...
- T-SQL查询高级--理解SQL SERVER中非聚集索引的覆盖,连接,交叉和过滤
写在前面:这是第一篇T-SQL查询高级系列文章.但是T-SQL查询进阶系列还远远没有写完.这个主题放到高级我想是因为这个主题需要一些进阶的知识作为基础..如果文章中有错误的地方请不吝指正.本篇文章 ...
- SQL SERVER 索引之聚集索引和非聚集索引的描述
索引是与表或视图关联的磁盘上结构,可以加快从表或视图中检索行的速度. 索引包含由表或视图中的一列或多列生成的键. 这些键存储在一个结构(B 树)中,使 SQL Server 可以快速有效地查找与键值关 ...
- SQL SERVER 聚集索引 非聚集索引 区别
转自http://blog.csdn.net/single_wolf_wolf/article/details/52915862 一.理解索引的结构 索引在数据库中的作用类似于目录在书籍中的作用,用来 ...
- SQL Serever学习16——索引,触发器,数据库维护
sqlserver2014数据库应用技术 <清华大学出版社> 索引 这是一个很重要的概念,我们知道数据在计算机中其实是分页存储的,就像是单词存在字典中一样 数据库索引可以帮助我们快速定位数 ...
- SQL Server的聚集索引和非聚集索引
微软的SQL SERVER提供了两种索引:聚集索引(clustered index,也称聚类索引.簇集索引)和非聚集索引(nonclustered index,也称非聚类索引.非簇集索引)…… (一) ...
- SQL点点滴滴_聚集索引设计指南-转载
聚集索引基于数据行的键值在表内排序和存储这些数据行, 每个表只能有一个聚集索引, 因为数据行本身只能按一个顺序存储. 有关聚集索引体系结构的详细信息, 请参阅 聚集索引结构. 每个表几乎都对列定义聚集 ...
- 聚集索引、非聚集索引、聚集索引组织表、堆组织表、Mysql/PostgreSQL对比、联合主键/自增长、InnoDB/MyISAM(引擎方面另开一篇)
参考了多篇文章,分别记录,如下. 下面是第一篇的总结 http://www.jb51.net/article/76007.htm: 在MySQL中,InnoDB引擎表是(聚集)索引组织表(cluste ...
- MYSQL的全表扫描,主键索引(聚集索引、第一索引),非主键索引(非聚集索引、第二索引),覆盖索引四种不同查询的分析
文章出处:http://inter12.iteye.com/blog/1430144 MYSQL的全表扫描,主键索引(聚集索引.第一索引),非主键索引(非聚集索引.第二索引),覆盖索引四种不同查询的分 ...
随机推荐
- [PaPaPa][需求说明书][V0.3]
PaPaPa软件需求说明书V0.3 前 言 不好意思,本文是没有前言的. 别说是前言了,其实关于界面的内容我也是不打算写!! 因为我知道你们想要的界面是这样的: 再不济也应该是这样的: 但是我 ...
- JAVA笔记 之 Thread线程
线程是一个程序的多个执行路径,执行调度的单位,依托于进程存在. 线程不仅可以共享进程的内存,而且还拥有一个属于自己的内存空间,这段内存空间也叫做线程栈,是在建立线程时由系统分配的,主要用来保存线程内部 ...
- offsetof的使用
#include <stddef.h> #define offsetof ( TYPE, m) (size_t )&reinterpret_cast< const vol ...
- 重构第1天:封装集合(Encapsulate Collection)
理解:封装集合就是把集合进行封装,只提供调用者所需要的功能行借口,保证集合的安全性. 详解:在大多的时候,我们没有必要把所有的操作暴露给调用者,只需要把调用者需要的相关操作暴露给他,这种情况中下我们就 ...
- 理解RxJava:(四)Reactive Android
在前三部分,我在通用层面介绍了RxJava的工作原理.但是作为一个Android开发者,如何在工作中使用它呢?下面是一些给Android开发者的RxJava的具体应用. RxAndroid RxAnd ...
- iBatis.Net(C#)系列Demo源码
iBatis.Net(C#)系列一:简介及运行环境源码 [下载] iBatis.Net(C#)系列二:SQL数据映射源码 [下载] iBatis.Net(C#)系列三:数据库查询源码 [下载]
- ubuntu安装php mcrypt扩展
1.安装扩展 sudo apt-get install php5-mcrypt 2.添加扩展配置文件 apt-get没有在/etc/php5/cli/conf.d/和/etc/php5/fpm/con ...
- Nginx 单机百万QPS环境搭建
一.背景 最近公司在做一些物联网产品,物物通信用的是MQTT协议,内部权限与内部关系等业务逻辑准备用HTTP实现.leader要求在本地测试中要模拟出百万用户同时在线的需求.虽然该产品最后不一定有这么 ...
- Linux下U盘变成只读
今天用Ubuntu给同学拷贝数据的时候,突然其中一个文件夹U盘就不能复制和删除了.再windows7下可以删除除修改的那个文件夹之外的数据,但修改的那个文件夹死活删除不掉,只读属性也去不掉.再Ubun ...
- AssetBundle系列——场景资源之解包(二)
本篇接着上一篇继续和大家分享场景资源这一主题,主要包括两个方面: (1)加载场景 场景异步加载的代码比较简单,如下所示: private IEnumerator LoadLevelCoroutine( ...