R语言网络爬虫学习 基于rvest包
R语言网络爬虫学习 基于rvest包
龙君蛋君;2015年3月26日
1.背景介绍:
前几天看到有人写了一篇用R爬虫的文章,感兴趣,于是自己学习了。好吧,其实我和那篇文章R语言爬虫初尝试-基于RVEST包学习 的主人认识~
2.知识引用与学习:
3.rvest + CSS Selector 网页数据抓取的最佳选择
3.正文:
第一个爬虫是爬取了戴申大牛在科学网博客的一些基本信息,戴申大牛看到这篇文章不要打我啊~我只是爬取了博文的几个字段,求饶恕~
library(rvest)
library(sqldf)
library(gsubfn)
library(proto)
#creat a function
extrafun <- function(i,non_pn_url){
url <- paste0(non_pn_url,i)
web <- html(url)
papername<- web %>% html_nodes("dl.bbda dt.xs2 a") %>% html_text()%>% .[c(seq(2,20,2))] %>% as.character()
paperlink<-gsub("\\?source\\=search","",web %>% html_nodes("dl.bbda dt.xs2 a") %>% html_attr("href"))%>% .[c(seq(2,20,2))]
paperlink <- paste0("http://blog.sciencenet.cn/",paperlink) %>% as.character()
posttime <- web %>% html_nodes("dl.bbda dd span.xg1") %>% html_text() %>% as.Date()#这里取每篇文章的发布时间
count_of_read <- web %>% html_nodes("dl.bbda dd.xg1 a") %>% html_text()
count_of_read <- as.data.frame(count_of_read)
count_of_read <- sqldf("select * from count_of_read where count_of_read like '%次阅读'")
data.frame(papername,posttime,count_of_read,paperlink)
}
#crawl data
final <- data.frame()
url <- 'http://blog.sciencenet.cn/home.php?mod=space&uid=556556&do=blog&view=me&page='
for(i in 1:40){
extrafun(i,url)
final <- rbind(final,extrafun(i,url))
}
> dim(final)
[1] 400 4
> head(final)
papername
1 此均值非彼均值
2 [转载]孔丘、孔子、孔老二,它究竟是一只什么鸟?
3 大数据分析之——k-means聚类中的坑
4 大数据分析之——足彩数据趴取
5 [转载]老王这次要摊事了,当年他主管的部门是事被重新抖出来。
6 [转载]党卫军是这样抓人的。
posttime count_of_read
1 2015-03-08 216 次阅读
2 2015-02-10 190 次阅读
3 2015-01-18 380 次阅读
4 2015-01-10 437 次阅读
5 2015-01-05 480 次阅读
6 2015-01-05 398 次阅读
paperlink
1 http://blog.sciencenet.cn/blog-556556-872813.html
2 http://blog.sciencenet.cn/blog-556556-866932.html
3 http://blog.sciencenet.cn/blog-556556-860647.html
4 http://blog.sciencenet.cn/blog-556556-858171.html
5 http://blog.sciencenet.cn/blog-556556-856705.html
6 http://blog.sciencenet.cn/blog-556556-856640.html
抓取的数据不能直接用作分析,于是导出到Excel,对数据做了一些处理,然后绘制了一张图。
write.table(final,"final.csv",fileEncoding="GB2312")
#抓取的数据需要在Excel进一步加工,加工后读取进来,进一步做分析
a <- read.table("dai_shen_blog_0326.csv",header=TRUE,sep=";",fileEncoding="GB2312")#Mac OS 环境下,要sep=";"
a$posttime <- as.Date(a$posttime)
a$paperlink <- as.character(a$paperlink)
a$papername <- as.character(a$papername)
a$count_of_read_NO. <- as.numeric(a$count_of_read_NO.)
library(ggplot2)
qplot(posttime,count_of_read_NO.,data=a,geom="point",colour=repost,size=6)
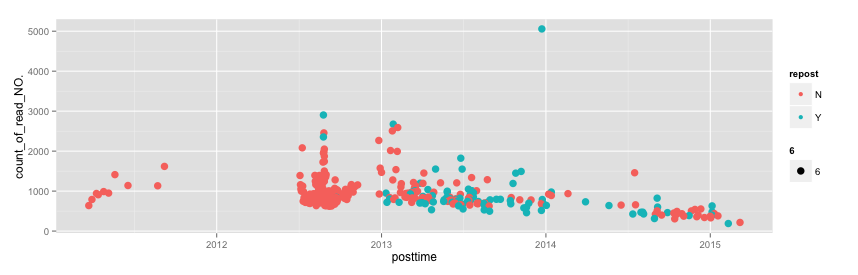
这张图说明了什么呢??
a).戴大牛在2012年上半年没写文章也没有转载文章(不知道发生了什么,难道是忘记博客登录密码了,哈哈~有可能),但下半年原创文章数量是最多的,数量占life time约1/3;
b).在2013年一整年,文章数量上半年明显多余下半年,全年文章总数量占life time约2/5,且原创和转载各半;
c).在2014年中,上半年文章数量明显少于下半年,转载和原创各半。
第二个爬虫是爬取了NBA2014-2015常规赛技术统计排行 - 得分榜
#Crawl NBA player statistics from sina
#web http://nba.sports.sina.com.cn/playerstats.php?s=0&e=49&key=1&t=1
library(rvest)
library(stringr)
library(sqldf)
rm(NBAdata)
start <- seq(0,250,50)
end <- seq(49,299,50)
getdata <- function(i){
url <- paste0('http://nba.sports.sina.com.cn/playerstats.php?s=',start[i],'&e=',end[i],'&key=1&t=1')
rank <- url %>% html_session() %>% html_nodes("table") %>% .[[2]] %>% html_nodes("td:nth-child(1)") %>% html_text()%>%.[-1]%>%as.numeric()
player <- url %>% html_session() %>% html_nodes("table") %>% .[[2]] %>% html_nodes("td:nth-child(2)") %>% html_text()%>%.[-1]%>%str_sub(9,100)%>%as.character()
team <- url %>% html_session() %>% html_nodes("table") %>% .[[2]] %>% html_nodes("td:nth-child(3)") %>% html_text()%>%.[-1]%>%str_sub(9,100)%>%as.character()
avg_score <- url %>% html_session() %>% html_nodes("table") %>% .[[2]] %>% html_nodes("td:nth-child(4)") %>% html_text()%>%.[-1]
total_score <- url %>% html_session() %>% html_nodes("table") %>% .[[2]] %>% html_nodes("td:nth-child(5)") %>% html_text()%>%.[-1]
total_shoot <- url %>% html_session() %>% html_nodes("table") %>% .[[2]] %>% html_nodes("td:nth-child(6)") %>% html_text()%>%.[-1]
three_point <- url %>% html_session() %>% html_nodes("table") %>% .[[2]] %>% html_nodes("td:nth-child(7)") %>% html_text()%>%.[-1]
punish_point <- url %>% html_session() %>% html_nodes("table") %>% .[[2]] %>% html_nodes("td:nth-child(8)") %>% html_text()%>%.[-1]
avg_time <- url %>% html_session() %>% html_nodes("table") %>% .[[2]] %>% html_nodes("td:nth-child(9)") %>% html_text()%>%.[-1]
total_involve <- url %>% html_session() %>% html_nodes("table") %>% .[[2]] %>% html_nodes("td:nth-child(10)") %>% html_text()%>%.[-1]
data.frame(rank,player,team,avg_score,total_score,total_shoot,three_point,punish_point,avg_time,total_involve) } NBAdata <- data.frame()
for(i in 1:6){
NBAdata <- rbind(NBAdata,getdata(i))
}
NBAdata <- sqldf("select distinct * from NBAdata")
write.table(NBAdata,"NBAdata.csv",sep=",",fileEncoding="GB2312")
> head(NBAdata)
rank player team avg_score total_score
1 1 拉塞尔-威斯布鲁克 雷霆 27.3 1556
2 2 詹姆斯-哈登 火箭 27.1 1900
3 3 勒布朗-詹姆斯 骑士 25.8 1600
4 4 安东尼-戴维斯 鹈鹕 24.6 1403
5 5 德马库斯-考辛斯 国王 23.8 1308
6 6 斯蒂芬-库里 勇士 23.4 1618
total_shoot three_point punish_point avg_time
1 42.7% 30.1% 84.6% 33.8
2 44% 36.8% 86.6% 36.8
3 49.2% 35.4% 71.9% 36.2
4 54.5% 10% 81.4% 36.2
5 46.5% 28.6% 80.2% 33.7
6 47.9% 42.2% 91.4% 32.9
total_involve
1 57
2 70
3 62
4 57
5 55
6 69
发现NBA2014-2015常规赛技术统计排行 - 得分榜 有两个错误。
a).排名第50的NBA球星缺失。
b).数据有大量重复,初次爬取,有510条记录,最后发现原来这个数据统计本身就有很多重复,于是用SQL去重,得到270条记录。
4.总结:
a).SelectorGadget 真的很好用,但是貌似这个插件要翻墙才能安装成功。SelectorGadget结合Google Chrome 使用,查找html_nodes 非常方便。
b).下次爬,要学尾巴同学,爬一些招聘网站的数据,给自己以后找工作做个参考嘛。
以上。
--------------------------------------------------------------------------------
以下内容修改于2015-04-01
今天闲来无事,浏览戴申同学的一篇博文
http://blog.sciencenet.cn/blog-556556-848696.html
发现自己之前对于 NBA2014-2015常规赛技术统计排行 - 得分榜 这个爬虫写的极为失败,特做出以下更新:
library(rvest)
library(stringr)
library(sqldf)
start <- seq(0,250,50)
end <- seq(49,299,50)
getdata <- function(i){
url <- paste0('http://nba.sports.sina.com.cn/playerstats.php?s=',start[i],'&e=',end[i],'&key=1&t=1')
dat <- url %>% html() %>% html_nodes("table")%>%.[[2]]%>%html_table(head=TRUE)
data.frame(dat)
}
NBAdata <- data.frame()
for(i in 1:6){
NBAdata <- rbind(NBAdata,getdata(i))
}
NBAdata <- sqldf("select distinct * from NBAdata")
dim(NBAdata)
write.table(NBAdata,"NBAdata.csv",sep=",",fileEncoding="GB2312")
> head(NBAdata)
排名 球员 球队 场均得分 得分总数 投篮命中率
1 1 拉塞尔-威斯布鲁克 雷霆 27.6 1626 42.5%
2 2 詹姆斯-哈登 火箭 27.2 1988 43.8%
3 3 勒布朗-詹姆斯 骑士 25.7 1644 48.9%
4 4 安东尼-戴维斯 鹈鹕 24.7 1455 54.1%
5 5 德马库斯-考辛斯 国王 24.1 1347 46.8%
6 6 斯蒂芬-库里 勇士 23.7 1708 48.3%
三分命中率 罚篮命中率 场均时间 参赛场次
1 29.7% 84.6% 34.0 59
2 36.9% 86.6% 36.9 73
3 35.3% 71.7% 36.3 64
4 10% 81.2% 36.3 59
5 28.6% 79.7% 33.9 56
6 43.4% 91.8% 32.9 72
总结:网页中若有table,则可以直接读取,然后用html_table(),可以直接转化为table,十分方便。
R语言网络爬虫学习 基于rvest包的更多相关文章
- 用R语言 画条形图(基于ggplot2包)
1.用qplot(x,data=data,geom.=”bar”,weight=y)+scale_y_continuous("y")画出y关于x的条形. 图中提示binwidth这 ...
- R语言爬虫初尝试-基于RVEST包学习
注意:这文章是2月份写的,拉勾网早改版了,代码已经失效了,大家意思意思就好,主要看代码的使用方法吧.. 最近一直在用且有维护的另一个爬虫是KINDLE 特价书爬虫,blog地址见此: http://w ...
- R语言︱H2o深度学习的一些R语言实践——H2o包
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- R语言H2o包的几个应用案例 笔者寄语:受启发 ...
- 13. Go 语言网络爬虫
Go 语言网络爬虫 本章将完整地展示一个应用程序的设计.编写和简单试用的全过程,从而把前面讲到的所有 Go 知识贯穿起来.在这个过程中,加深对这些知识的记忆和理解,以及再次说明怎样把它们用到实处.由本 ...
- R语言书籍的学习路线图
现在对R感兴趣的人越来越多,很多人都想快速的掌握R语言,然而,由于目前大部分高校都没有开设R语言课程,这就导致很多人不知道如何着手学习R语言. 对于初学R语言的人,最常见的方式是:遇到不会的地方,就跑 ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
- 碎片︱R语言与深度学习
笔者:受alphago影响,想看看深度学习,但是其在R语言中的应用包可谓少之又少,更多的是在matlab和python中或者是调用.整理一下目前我看到的R语言的材料: ---------------- ...
- R语言与机器学习学习笔记
人工神经网络(ANN),简称神经网络,是一种模仿生物神经网络的结构和功能的数学模型或计算模型.神经网络由大量的人工神经元联结进行计算.大多数情况下人工神经网络能在外界信息的基础上改变内部结构,是一种自 ...
- R语言与显著性检验学习笔记
R语言与显著性检验学习笔记 一.何为显著性检验 显著性检验的思想十分的简单,就是认为小概率事件不可能发生.虽然概率论中我们一直强调小概率事件必然发生,但显著性检验还是相信了小概率事件在我做的这一次检验 ...
随机推荐
- equals和等号的区别
如果是基本类型,等号比较的是数值.如果是引用类型,等号比较的是地址.而equals如果没有重写的话默认比较的是地址,可以重写equals来自定义比较两个对象的逻辑.
- javasript数据类型以及如何判断数据类型
在javascript里面一共有5种基本的数据类型,分别是:Number,String,Boolean,Null,Undefined7种引用类型,分别是:Object类型,Array类型,Date类型 ...
- shell代码模板
批量ssh登录机器 #site_search_hosts 10.4.16.205,10.4.20.87,10.4.20.88,10.4.20.89,10.4.20.90,10.4.20.92,10.4 ...
- Technical Committee Weekly Meeting 2016.06.21
Meeting time: 2016.June.21 1:00~2:00 Chairperson: Thierry Carrez Meeting summary: 1.Add current hou ...
- gcc标准,c++中的inline
1. GCC的inlinegcc对C语言的inline做了自己的扩展,其行为与C99标准中的inline有较大的不同. 1.1. static inlineGCC的static inline定义很容易 ...
- Dedecms当前位置(面包屑导航)的处理
一.修改{dede:field name='position'/}的文字间隔符,官方默认的是> 在include/typelink.class.php第101行左右将>修改为你想要的符号即 ...
- HDU 4578——Transformation——————【线段树区间操作、确定操作顺序】
Transformation Time Limit: 15000/8000 MS (Java/Others) Memory Limit: 65535/65536 K (Java/Others)T ...
- JQuery 的跨域方法 可跨任意网站
JS的跨域问题,很多人在网上找其解决方法,教其用IFRAME去解决的文章很多,真有那么复杂吗?其实很简单的,如果你用JQUERY,一个GETJSON方法就搞定了,而且是一行代码搞定. 下面开始贴出方法 ...
- Unity C# 关于Attribute的使用
最近在研究Attribute,感觉挺好玩,搜到一篇不错的文章,分享给大家 原文:未知?找到后补上! 举两个例子,在变量上使用[SerializeFiled]属性,可以强制让变量进行序列化,可以在Uni ...
- c#获取目录
获取程序目录 string s = System.IO.Directory.GetCurrentDirectory(); Console.WriteLine(s);// C:\Users\r-\doc ...