day-3 python多线程编程知识点汇总
python语言以容易入门,适合应用开发,编程简洁,第三方库多等等诸多优点,并吸引广大编程爱好者。但是也存在一个被熟知的性能瓶颈:python解释器引入GIL锁以后,多CPU场景下,也不再是并行方式运行,甚至比串行性能更差。注定这门语言在某些方面是有天花板的,对于一些并行要求高的系统,python可能不再成为首选,甚至是完全不考虑。但是事情也并不是绝对悲观的,我们已经看到有一大批人正在致力优化这个特性,新版本较老版本也有了一定改进,一些核心模块我们也可以选用其它模块开发等等措施。
1、python多线程编程
threading是python实现多线程编程的常用库,有两种方式可以实现多线程:1、调用库接口传入功能函数和参数执行;2、自定义线程类继承threading.Thread,然后重写__init__和run方法。
1、调用库接口传入功能函数和参数执行
import threading
import queue
import time '''
实现功能:定义一个FIFO的queue,10个元素,3个线程同时来获取
''' # 初始化FIFO队列
q = queue.Queue()
for i in range(10):
q.put(i)
print("%s : Init queue,size:%d"%(time.ctime(),q.qsize())) # 线程功能函数,获取队列数据
def run(q,threadid):
is_empty = False
while not is_empty:
if not q.empty():
data = q.get()
print("Thread %d get:%d"%(threadid,data))
time.sleep(1)
else:
is_empty = True # 定义线程列表
thread_handler_lists = []
# 初始化线程
for i in range(3):
thread = threading.Thread(target=run,args = (q,i))
thread.start()
thread_handler_lists.append(thread)
# 等待线程执行完毕
for thread_handler in thread_handler_lists:
thread_handler.join() print("%s : End of progress"%(time.ctime()))
2、自定义线程类继承threading.Thread,然后重写__init__和run方法
和其它语言一样,为了保证多线程间数据一致性,threading库自带锁功能,涉及3个接口:
thread_lock = threading.Lock() 创建一个锁对象
thread_lock.acquire() 获取锁
thread_lock.release() 释放锁
注意:由于python模块queue已经实现多线程安全,实际编码中,不再需要进行锁的操作,此处只是进行编程演示。
import threading
import queue
import time '''
实现功能:定义一个FIFO的queue,10个元素,3个线程同时来获取
queue线程安全的队列,因此不需要加
thread_lock.acquire()
thread_lock.release() ''' # 自定义一个线程类,继承threading.Thread,重写__init__和run方法即可
class MyThread(threading.Thread):
def __init__(self,threadid,name,q):
threading.Thread.__init__(self)
self.threadid = threadid
self.name = name
self.q =q
print("%s : Init %s success."%(time.ctime(),self.name)) def run(self):
is_empty = False
while not is_empty:
thread_lock.acquire()
if not q.empty():
data = self.q.get()
print("Thread %d get:%d"%(self.threadid,data))
time.sleep(1)
thread_lock.release()
else:
is_empty = True
thread_lock.release() # 定义一个锁
thread_lock = threading.Lock()
# 定义一个FIFO队列
q = queue.Queue()
# 定义线程列表
thread_name_list = ["Thread-1","Thread-2","Thread-3"]
thread_handler_lists = [] # 初始化队列
thread_lock.acquire()
for i in range(10):
q.put(i)
thread_lock.release()
print("%s : Init queue,size:%d"%(time.ctime(),q.qsize())) # 初始化线程
thread_id = 1
for thread_name in thread_name_list:
thread = MyThread(thread_id,thread_name,q)
thread.start()
thread_handler_lists.append(thread)
thread_id += 1 # 等待线程执行完毕
for thread_handler in thread_handler_lists:
thread_handler.join() print("%s : End of progress"%(time.ctime()))
另外多线程还涉及事件和信号量,很简单,就不再贴代码了
用threading.Event 实现线程间通信,使用threading.Event可以使一个线程等待其他线程的通知,我们把这个Event传递到线程对象中,
涉及接口:set()、isSet()、Event()、clear()
如果在主机执行IO密集型任务的时候再执行这种类型的程序时,计算机就有很大可能会宕机。
这时候就可以为这段程序添加一个计数器功能,来限制一个时间点内的线程数量。
涉及接口:threading.Semaphore(5)、acquire()、release()
2、python多线程机制分析
讨论前,我们先梳理几个概念:
并行和并发
并发的关键是你有处理多个任务的能力,不一定要同时。而并行的关键是你有同时处理多个任务的能力。我认为它们最关键的点就是:是否是『同时』,或者说并行是并发的子集。
GIL
GIL:全局解释锁,python解释器级别的锁,为了保证程序本身运行正常,例如python的自动垃圾回收机制,在我们程序运行的同时,也在进行垃圾清理工作。
下图试图模拟A进程中3个线程的执行情况:
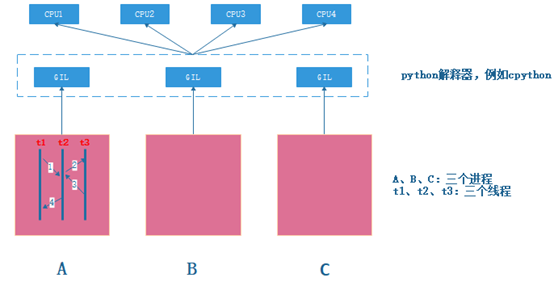
1、 t1、t2、t3线程处于就绪状态,同时向python解释器获取GIL锁
2、 假设t1获取到GIL锁,被python分配给任意CPU执行,处于运行状态
3、 Python基于某种调度方式(例如pcode),会让t1释放GIL锁,重新处于就绪状态
4、 重复1步骤,假设这时t2获取到GIL锁,运行过程同上,被python分配给任意CPU执行,处于运行状态,Python基于某种调度方式(例如pcode),会让t2释放GIL锁,重新处于就绪状态
5、 最后可以推得t1、t2、t3按如下1、2、3、4方式串行运行
因此,尽管t1、t2、t3为三个线程,理论上可以并行运行,但实际上python解释器引入GIL锁以后,多CPU场景下,也不再是并行方式运行,甚至比串行性能更差,下面我们做个测试:
我们写两个计算函数,测试单线程和多线程的时间开销,代码如下:
import threading
import time # 定义两个计算量大的函数
def sum():
sum = 0
for i in range(100000000):
sum += i def mul():
sum = 0
for i in range(10000000):
sum *= i # 单线程时间测试
starttime = time.time()
sum()
mul()
endtime = time.time()
period = endtime - starttime
print("The single thread cost:%d"%(period)) # 多线程时间测试
starttime = time.time()
l = []
t1 = threading.Thread(target = sum)
t2 = threading.Thread(target = sum)
l.append(t1)
l.append(t2)
for i in l:
i.start()
for i in l:
i.join()
endtime = time.time()
period = endtime - starttime
print("The mutiple thread cost:%d"%(period)) print("End of program.")
测试发现,多线程的时间开销居然比单线程还要大:

这个结果有点让人不可接受,那有没有办法优化?答案是有的,比如把多线程变成多进程,但是考虑到进程开销问题,实际编程中,不能开过多进程,下面是多进程测试代码:
'''
程序欲实现功能:定义1个CPU占用高函数,测试Python多进程执行效率
''' import multiprocessing
import time
def mul():
sum = 0
for i in range(1000000000):
sum *= i if __name__ == "__main__":
start_time = time.time() # 执行两个函数
mul()
mul() end_time = time.time()
print("single proccess cost : %d" % (end_time - start_time)) start_time = time.time() #定义两个进程
l = []
p1 = multiprocessing.Process(target = mul)
p1.start()
l.append(p1)
p2 = multiprocessing.Process(target = mul)
p2.start()
l.append(p2) #等待进程执行完毕
for p_list in l:
p_list.join() end_time = time.time()
print("Mutiple proccess cost : %d"%(end_time - start_time))
实际测试结果:
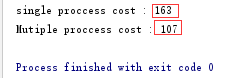
测试结果显示:单进程串行执行需要163秒,而双进程执行只需要107秒,显然执行效率更高。
另外进程+协程也可以提高一定性能,这里暂时不再深入分析。
有兴趣可以继续阅读下链接博客:http://cenalulu.github.io/python/gil-in-python/
day-3 python多线程编程知识点汇总的更多相关文章
- day-4 python多进程编程知识点汇总
1. python多进程简介 由于Python设计的限制(我说的是咱们常用的CPython).最多只能用满1个CPU核心.Python提供了非常好用的多进程包multiprocessing,他提供了一 ...
- python多线程编程
Python多线程编程中常用方法: 1.join()方法:如果一个线程或者在函数执行的过程中调用另一个线程,并且希望待其完成操作后才能执行,那么在调用线程的时就可以使用被调线程的join方法join( ...
- 关于python多线程编程中join()和setDaemon()的一点儿探究
关于python多线程编程中join()和setDaemon()的用法,这两天我看网上的资料看得头晕脑涨也没看懂,干脆就做一个实验来看看吧. 首先是编写实验的基础代码,创建一个名为MyThread的 ...
- python 多线程编程
这篇文章写的很棒http://blog.csdn.net/bravezhe/article/details/8585437 使用threading模块实现多线程编程一[综述] Python这门解释性语 ...
- python多线程编程—同步原语入门(锁Lock、信号量(Bounded)Semaphore)
摘录python核心编程 一般的,多线程代码中,总有一些特定的函数或者代码块不希望(或不应该)被多个线程同时执行(比如两个线程运行的顺序发生变化,就可能造成代码的执行轨迹或者行为不相同,或者产生不一致 ...
- 线程和Python—Python多线程编程
线程和Python 本节主要记录如何在 Python 中使用线程,其中包括全局解释器锁对线程的限制和对应的学习脚本. 全局解释器锁 Python 代码的执行是由 Python 虚拟机(又叫解释器主循环 ...
- python并发编程知识点总结
1.到底什么是线程?什么是进程? Python自己没有这玩意,Python中调用的操作系统的线程和进程. 2.Python多线程情况下: 计算密集型操作:效率低,Python内置的一个全局解释器锁,锁 ...
- python多线程编程(3): 使用互斥锁同步线程
问题的提出 上一节的例子中,每个线程互相独立,相互之间没有任何关系.现在假设这样一个例子:有一个全局的计数num,每个线程获取这个全局的计数,根据num进行一些处理,然后将num加1.很容易写出这样的 ...
- python多线程编程-queue模块和生产者-消费者问题
摘录python核心编程 本例中演示生产者-消费者模型:商品或服务的生产者生产商品,然后将其放到类似队列的数据结构中.生产商品中的时间是不确定的,同样消费者消费商品的时间也是不确定的. 使用queue ...
随机推荐
- 【Luogu3807】【模板】卢卡斯定理(数论)
题目描述 给定\(n,m,p(1≤n,m,p≤10^5)\) 求 \(C_{n+m}^m mod p\) 保证\(P\)为\(prime\) \(C\)表示组合数. 一个测试点内包含多组数据. 输入输 ...
- [清华集训]小 Y 和恐怖的奴隶主
题面在这里 题意 有一个\(Boss\)和他血量为\(m\)的随从奴隶主,每当奴隶主受到攻击且不死,并且\(Boss\)的随从个数\(<k\)时,就会新召唤一个血量为\(m\)的奴隶主.每次攻击 ...
- 清橙A1202&Bzoj2201:彩色圆环
因为Bzoj是权限题,所以可以去清橙做一下 Sol 突然考了一道这样的题,考场上强行\(yy\)出来了 win下评测Long double爆零TAT 首先肯定是破环为链变成序列问题辣 那么就要求第一个 ...
- [USACO07NOV]Cow Relays
map+floyed+矩阵乘法(倍增floyed) # include <stdio.h> # include <stdlib.h> # include <iostrea ...
- win10怎么安装JDK8,配置JDK8的环境变量
win10怎么安装JDK8,配置JDK8的环境变量 本文详细说明怎么在win10上安装JDK8,方便小伙伴们快速学会安装与配置JDK. 工具/原料 windows10 jdk-8u51-windows ...
- 锐动视频SDK在金融业务加密双录管理系统通用解决方案
为了更好地保障消费者的合法权益,银监会和保监会提出了要求,在银行.保险从业人员销售理财产品或代理其他机构销售产品时,同期进行录音录像,确保销售人员按程序.按规定介绍产品,以便购买者更清楚地了解产品的性 ...
- linux下 mysql5.7.20安装(精华)
在linux 系统中mysql配置文件的读取顺序为: /etc/my.cnf /etc/mysql/my.cnf /usr/local/mysql/etc/my.cnf ~/.my.cnf 第一步 创 ...
- 在 WinForm 中 如何实现 加载等待功能
1,需要一个动态的londing文件:在项目中我们新建一个文件夹来存放它: 2,在需要出现londing状态的窗体上加上一个Panel: 黄色区域是Panel,灰色的是需要被加载的区域.当需要触发lo ...
- Java基于自定义注解的面向切面的实现
目的:实现在任何想要切的地方添加一个注解就能实现面向切面编程 自定义注解类 @Target({ElementType.PARAMETER, ElementType.METHOD}) @Retentio ...
- Mac安装pycharm 的下载链接和破解方法
PyCharm是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试.语法高亮.Project管理.代码跳转.智能提示.自动完成.单元测试.版本控制 ...