hbase rowkey 的设计
什么是rowkey
Hbase是一个分布式的、面向列的数据库,它和一般关系型数据库的最大区别是:HBase很适合于存储非结构化的数据,还有就是它基于列的而不是基于行的模式.
Hbase是采用K,V存储的,那Rowkey就是KeyValue的Key了,Rowkey也是一段二进制码流,最大长度为64KB,内容可以由使用的用户自定义。数据加载时,一般也是根据Rowkey的二进制序由小到大进行的。
HBase是根据Rowkey来进行检索的,系统通过找到某个Rowkey (或者某个 Rowkey 范围)所在的Region,然后将查询数据的请求路由到该Region获取数据。HBase的检索支持3种方式:
1 通过单个Rowkey访问,即按照某个Rowkey键值进行get操作,这样获取唯一一条记录;
2 通过Rowkey的range进行scan,即通过设置startRowKey和endRowKey,在这个范围内进行扫描。这样可以按指定的条件获取一批记录;
3全表扫描,即直接扫描整张表中所有行记录。
HBASE按单个Rowkey检索的效率是很高的,耗时在1毫秒以下,每秒钟可获取1000~2000条记录,不过非key列的查询很慢。
我们常说看一张 HBase 表设计的好不好,就看它的 RowKey 设计的好不好。可见 RowKey 在 HBase 中的地位。那么 RowKey 到底是什么?RowKey 的特点如下:
类似于 MySQL、Oracle中的主键,用于标示唯一的行;
完全是由用户指定的一串不重复的字符串;
HBase 中的数据永远是根据 Rowkey 的字典排序来排序的。
RowKey的作用
1读写数据时通过 RowKey 找到对应的 Region;
2 MemStore 中的数据按 RowKey 字典顺序排序;
3 HFile 中的数据按 RowKey 字典顺序排序。
Rowkey对查询的影响
如果我们的 RowKey 设计为 uid+phone+name,那么这种设计可以很好的支持以下的场景:
uid = 111 AND phone = 123 AND name = zs
uid = 111 AND phone = 123
uid = 111 AND phone = 12?
uid = 111
难以支持的场景:
phone = 123 AND name = zs
phone = 123
name = zs
Rowkey对Region划分影响
HBase 表的数据是按照 Rowkey 来分散到不同 Region,不合理的 Rowkey 设计会导致热点问题。热点问题是大量的 Client 直接访问集群的一个或极少数个节点,而集群中的其他节点却处于相对空闲状态。
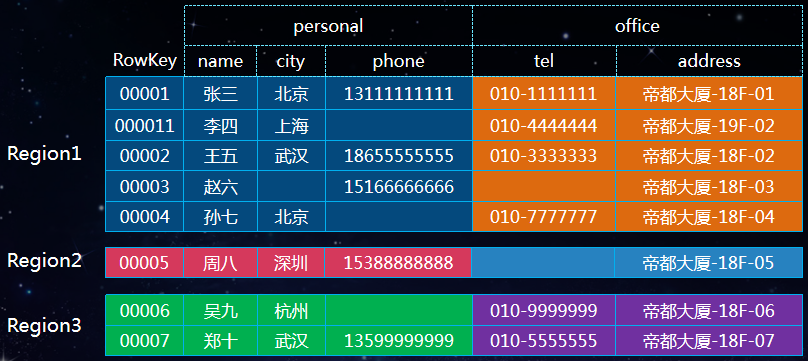
如上图,Region1 上的数据是 Region 2 的5倍,这样会导致 Region1 的访问频率比较高,进而影响这个 Region 所在机器的其他 Region。
RowKey设计技巧
我们如何避免上面说到的热点问题呢?这就是这章节谈到的三种方法。
一.避免热点的方法 - Salting
这里的加盐不是密码学中的加盐,而是在rowkey 的前面增加随机数。具体就是给 rowkey 分配一个随机前缀 以使得它和之前排序不同。分配的前缀种类数量应该和你想使数据分散到不同的 region 的数量一致。 如果你有一些 热点 rowkey 反复出现在其他分布均匀的 rwokey 中,加盐是很有用的。考虑下面的例子:它将写请求分散到多个 RegionServers,但是对读造成了一些负面影响。
假如你有下列 rowkey,你表中每一个 region 对应字母表中每一个字母。 以 'a' 开头是同一个region, 'b'开头的是同一个region。在表中,所有以 'f'开头的都在同一个 region, 它们的 rowkey 像下面这样:
|
foo0001 foo0002 foo0003 foo0004 |
现在,假如你需要将上面这个 region 分散到 4个 region。你可以用4个不同的盐:'a', 'b', 'c', 'd'.在这个方案下,每一个字母前缀都会在不同的 region 中。加盐之后,你有了下面的 rowkey:
|
a-foo0003 b-foo0001 c-foo0004 d-foo0002 |
所以,你可以向4个不同的 region 写。理论上说,如果这四个 Region 存放在不同的机器上,经过加盐之后你将拥有之前4倍的吞吐量。
现在,如果再增加一行,它将随机分配a,b,c,d中的一个作为前缀,并以一个现有行作为尾部结束:
|
a-foo0003 b-foo0001 c-foo0003 c-foo0004 d-foo0002 |
因为分配是随机的,所以如果你想要以字典序取回数据,你需要做更多工作。加盐这种方式增加了写时的吞吐量,但是当读时有了额外代价。
二.避免热点的方法 - Hashing
Hashing 的原理是计算 RowKey 的 hash 值,然后取 hash 的部分字符串和原来的 RowKey 进行拼接。这里说的 hash 包含 MD5、sha1、sha256或sha512等算法。比如我们有如下的 RowKey:
|
foo0001 foo0002 foo0003 foo0004 |
我们使用 md5 计算这些 RowKey 的 hash 值,然后取前 6 位和原来的 RowKey 拼接得到新的 RowKey:
|
95f18cfoo0001 6ccc20foo0002 b61d00foo0003 1a7475foo0004 |
优缺点:可以一定程度打散整个数据集,但是不利于 Scan;比如我们使用 md5 算法,来计算Rowkey的md5值,然后截取前几位的字符串。subString(MD5(设备ID), 0, x) + 设备ID,其中x一般取5或6。
三.避免热点的方法 - Reversing
Reversing 的原理是反转一段固定长度或者全部的键。比如我们有以下 URL ,并作为 RowKey:
|
flink.xiguage.com www.xiguage.com carbondata.xiguage.com def.xiguage.com |
这些 URL 其实属于同一个域名,但是由于前面不一样,导致数据不在一起存放。我们可以对其进行反转,如下:
|
moc.egaugix.knilf moc.egaugix.www moc.egaugix.atadnobrac moc.egaugix.fed |
经过这个之后,这些 URL 的数据就可以放一起了。
RowKey的长度
RowKey 可以是任意的字符串,最大长度64KB(因为 Rowlength 占2字节)。建议越短越好,原因如下:
数据的持久化文件HFile中是按照KeyValue存储的,如果rowkey过长,比如超过100字节,1000w行数据,光rowkey就要占用100*1000w=10亿个字节,将近1G数据,这样会极大影响HFile的存储效率;
MemStore将缓存部分数据到内存,如果rowkey字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率;
目前操作系统都是64位系统,内存8字节对齐,控制在16个字节,8字节的整数倍利用了操作系统的最佳特性。
RowKey 设计案例剖析
交易类表 Rowkey 设计
1.查询某个卖家某段时间内的交易记录
sellerId + timestamp + orderId
2.查询某个买家某段时间内的交易记录
buyerId + timestamp +orderId
3.根据订单号查询
orderNo
4.如果某个商家卖了很多商品,可以如下设计 Rowkey 实现快速搜索
salt + sellerId + timestamp 其中,salt 是随机数。
可以支持的场景:
全表 Scan
按照 sellerId 查询
按照 sellerId + timestamp 查询
金融风控 Rowkey 设计
查询某个用户的用户画像数据
prefix + uid
prefix + idcard
prefix + tele
其中 prefix = substr(md5(uid),0 ,x), x 取 5-6。uid、idcard以及 tele 分别表示用户唯一标识符、身份证、手机号码。
车联网 Rowkey 设计
查询某辆车在某个时间范围的交易记录
carId + timestamp
某批次的车太多,造成热点
prefix + carId + timestamp 其中 prefix = substr(md5(uid),0 ,x)
查询最近的数据
查询用户最新的操作记录或者查询用户某段时间的操作记录,RowKey 设计如下:
uid + Long.Max_Value - timestamp
支持的场景
查询用户最新的操作记录
Scan [uid] startRow [uid][000000000000] stopRow [uid][Long.Max_Value - timestamp]
查询用户某段时间的操作记录
Scan [uid] startRow [uid][Long.Max_Value – startTime] stopRow [uid][Long.Max_Value - endTime]
如果 RowKey 无法满足我们的需求,可以尝试二级索引。Phoenix、Solr 以及 ElasticSearch 都可以用于构建二级索引。
hbase rowkey 的设计的更多相关文章
- HBase RowKey与索引设计
1. HBase的存储形式 hbase的内部使用KeyValue的形式存储,其key时rowKey:family:column:logTime,value是其存储的内容. 其在region内大多以升序 ...
- HBase(九)HBase表以及Rowkey的设计
一 命名空间 1 命名空间的结构 1) Table:表,所有的表都是命名空间的成员,即表必属于某个命名空间,如果没有指定, 则在 default 默认的命名空间中. 2) RegionServer g ...
- Hbase rowkey设计一
转自 http://blog.csdn.net/lifuxiangcaohui/article/details/40621067 hbase所谓的三维有序存储的三维是指:rowkey(行主键),col ...
- Hbase Rowkey设计
转自:http://www.bcmeng.com/hbase-rowkey/ 建立Schema Hbase 模式建立或更新可以通过 Hbase shell 工具或者使用Hbase Java API 中 ...
- HBase总结(十八)Hbase rowkey设计一
hbase所谓的三维有序存储的三维是指:rowkey(行主键),column key(columnFamily+qualifier),timestamp(时间戳)三部分组成的三维有序存储. 1.row ...
- 【HBase】快速了解上手rowKey的设计技巧
目录 为什么要设计rowKey 三大原则 长度原则 散列原则 唯一原则 热点问题的解决 加盐 哈希 反转 时间戳反转 为什么要设计rowKey 首先要弄明白一点,Regions的分区就是根据数据的ro ...
- 【转】HBase原理和设计
简介 HBase —— Hadoop Database的简称,Google BigTable的另一种开源实现方式,从问世之初,就为了解决用大量廉价的机器高速存取海量数据.实现数据分布式存储提供可靠的方 ...
- HBase原理和设计
转载 2016年1月10日:http://www.sysdb.cn/index.php/2016/01/10/hbase_principle/ 简介 架构 数据组织 原理 RS定位 region写入 ...
- HBase原理、设计与优化实践
转自:http://www.open-open.com/lib/view/open1449891885004.html 1.HBase 简介 HBase —— Hadoop Database的简称,G ...
随机推荐
- VS2017中使用组合项目_windows服务+winform管理_项目发布_测试服务器部署
前言:作为一名C#开发人员,避免不了常和windows服务以及winform项目打交道,本人公司对服务的管理也是用到了这2个项目的组合方式进行:因为服务项目是无法直接安装到计算器中,需要使用命令借助微 ...
- 关于Mybatis的一些随笔
Mapper.xml头文件 <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http:/ ...
- 前端基础之--css中可被继承和不可被继承的属性
一.无继承性的属性 1.display:规定元素应该生成的框的类型 2.文本属性:vertical-align:垂直文本对齐 text-decoration:规定添加到文本的装饰 text-shado ...
- golang 变量定义
package main import "fmt" var luckyNum = 6 var luckyStr = "love" //myNum := 6 // ...
- Windows-删除Windows Server backup卷影副本
现有环境中有一台Windows Server做过定期备份计划,时间太久未做清理操作,收到磁盘报警邮件后需要及时释放该空间,具体操作步骤如下: 当前备份计划信息如下: 清理步骤如下: 1.以管理身份运行 ...
- python+selenium 自动化测试实战
一.前言: 之前的文章说过, 要写一篇自动化实战的文章, 这段时间比较忙再加回家过11一直没有更新博客,今天整理一下实战项目的代码共大家学习.(注:项目是针对我们公司内部系统的测试,只能内部网络访问, ...
- kali linux中的yum、rpm常见的问题
事件起因:今天我在kali里面使用yum命令来部署Linux环境时,出现了错误: bash:yum command not found,然后就百度,找到一片好的文章,链接:http://www.pia ...
- docker 备注
1.docker 安装 #安装环境为centos yum -y install docker service docker start #测试是否安装成功,可执行命令 docker run hello ...
- 数组for循环查找范围
数组for循环查找范围,如果是判读是否在键值之间,如$array[$i],那么接邻的元素不能用$array[$i+1]或者$array[$i-1]只能用$array[$i++]
- PHP全栈学习笔记7
图形图像处理技术,gd库的强大支持,PHP的图像可以是PHP的强项,PHP图形化类库,jpgraph是一款非常好用的强大的图形处理工具. 在PHP中加载GD库 gd官方网址下载: http://www ...