Java Web乱码原因与解决
一、了解编码常识:
1、ASCII 码
众所周知,这是最简单的编码。它总共可以表示128个字符,0~31是控制字符如换行、回车、删
除等,32~126是打印字符,可以通过键盘输入并且能够显示出来的。
2、ISO-8859-1
它是基于ASCII码基础上扩展的,它总共能表示256个字符,涵盖了大多数西欧语言字符。详见
ISO-8859-1 编码 该编码不支持中文,举个中文编码栗子:
字符串“I am 君山”用 ISO-8859-1 编码,下面是编码结果:
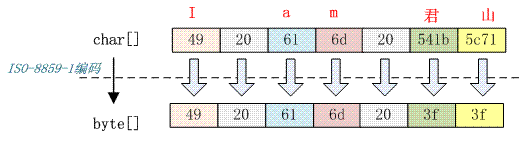
由于ISO-8859-1 是单字节编码且不支持中文,直接将中文字符转成‘3f’, 3f也就是常见的"?"字符
3、GB2312
它是双字节编码,共包含6763个汉字。
4、GBK
汉字内码扩展规范,是基于GB2312上拓展的,加入了更多的汉字,能表示21003个汉字。它的编码
是和GB2312兼容的。也就是说用GB2312编码的汉字可以用GBK来解码,并且不会乱码。倒过来就不完
全可以了,因为GB2312描述的汉字比GBK少。
5、UTF-16
UTF-16是基于Unicode上定义的, 用两个字节来表示Unicode的转换格式,它采用定长的表示方法,
即不能什么字符都可以用两个字节表示。两个字节是16个bit,所以就做UTF-16。(Unicode 囊括了世界
上所有语言,所有语言均可通过Unicode来相互翻译,详解Unicode 编码)
6、UTF-8
由于UTF-16统一采用两个字节来表示一个字符, 有很多字符用一个字节表示即可。所以存储空间放
大了一倍,还会增加网络传输的流量,所以推出了UTF-8。 UTF-8采用了一种变长技术,每个编码区域有
不同的字码长度。
通过上面介绍和对比,对于中文字符的处理我想UTF-8是最理想的中文编码。
二、常见乱码问题分析
1、中文变成看不懂的字符
如果一串中文字符变成了一串看不懂的字符如:"Ì Ô £ ¡Î Ò Ï²»¶ £ ¡",这种情况通常是编码
字符集与解码时所用的字符集不一致所造成的。比如使用GBK编码,如果使用ISO-8859-1解码
的话结果就是这样。
2、一个汉字变成了一个问号
如果编码和解码的字符集都是一致的,那么可以确定该字符编码不支持中文,例如:ISO-8859-1
3、一个汉字变成了两个问号
中文经过多次编码且其中有一次编码或者解码使用了不支持中文的字符集
三、Servlet相关的几种乱码
1、浏览器调用jsp,html等页面中文显示乱码
此情况需满足两个要求:
(1)文件本身是以utf-8编辑保存的(myEclipse中在properties中鼠标右键选择utf-8)
(2)浏览器用utf-8解析:
(手动)==> 在浏览器中右键选择编码格式为utf-8
(智能)==> 在文件中写入如: <meta name="content-type" content="text/html; charset=UTF-8"> 通过<meta>标签模拟response头,起到告诉浏览器用utf-8的编码解析
(智能)==> response.setContentType("text/html;charset=UTF-8");起到告诉浏览器用utf-8的编码解析
常用:
<meta name="content-type" content="text/html; charset=UTF-8">或<meta charset="utf-8">
<%@ pageEncoding="utf-8"%>
<?xml encoding="UTF-8"?>
2、通过浏览器调用servlet,页面显示乱码。
Servlet乱码分为request乱码和response乱码;
(1)response乱码问题
解决方法:
在网上很有效的解决方法是添加:
response.setCharacterEncoding("UTF-8");
解决不了,后来又搜到一条解决方法是:
response.setContentType("text/html;charset=utf-8");或者 response.setHeader("content-type","text/html;charset=UTF-8");告诉浏览器用utf-8解析。(setHeader是HttpServletResponse的方法。如果想在拦截器Filter中设置字符编码,则无此方法,因为Filter的doFilter方法的参数类型是ServletResponse)
两句都填上,后来终于解决了这个问题;
其实我们应该思考一下本质:
response.setContentType("text/html;charset=UTF-8"); 目的是为了控制浏览器的行为,即控制浏览器用UTF-8进行解码;
response.setCharacterEncoding("UTF-8");目的是用于response.getWriter()输出的字符流的乱码问题。如果是response.getOutputStream()是不需要此种解决方案的,因为这句话的意思是为了将response对象中的数据以UTF-8解码后的字节流发向浏览器;
==> 情况一:
问题代码如【引入】的例子
我们这里先来说明一下错误的原因,下图是显示乱码的流程图:
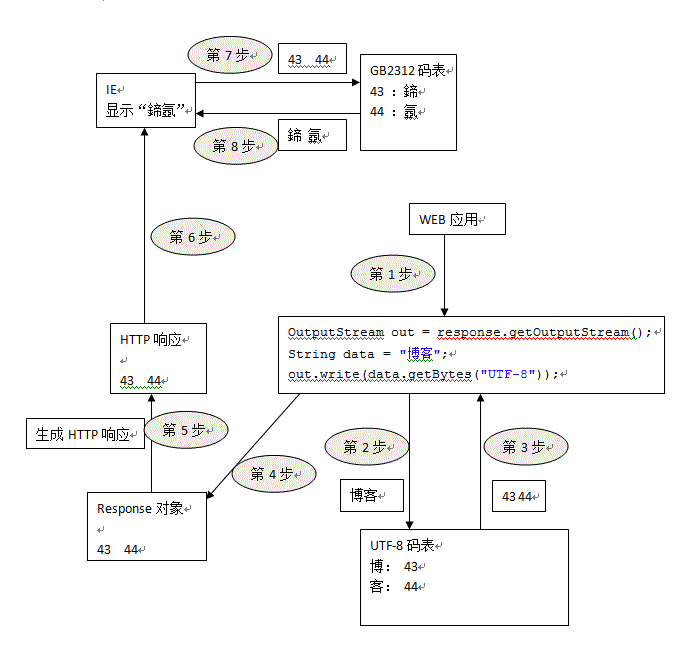
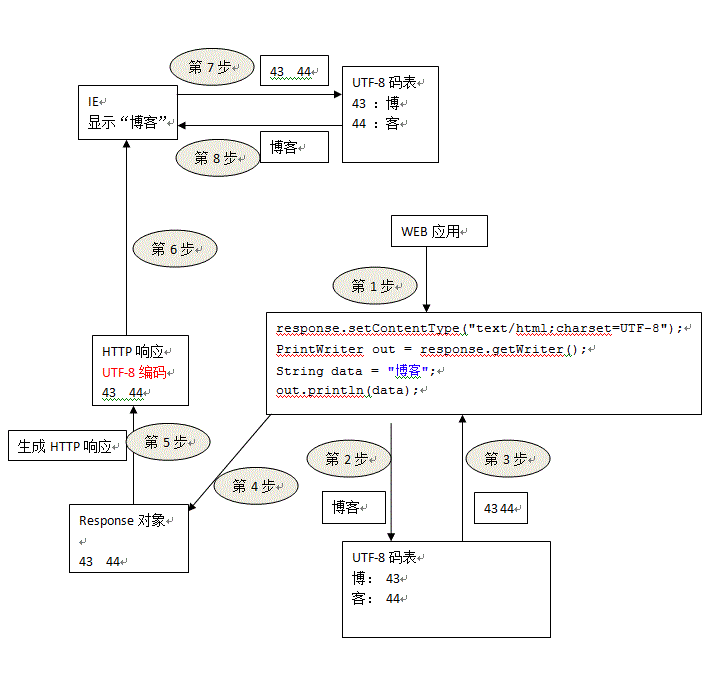
解决方案流程图:
==>情况二:
问题代码如下
- protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
- PrintWriter out = response.getWriter();
- String data = "博客";
- out.println(data);
- }
浏览器输出的结果为: ??
原因:"博客"首先被封装在response对象中,因为IE和WEB服务器之间不能传输文本,然后就通过ISO-8859-1进行编码,但是ISO-8859-1中没有“博客”的编码,因此输出“??”表示没有编码;
错误代码流程图:

而解决方案是:response.setCharacterEncoding("GB2312"); 设置response使用的码表
解决方案流程图:
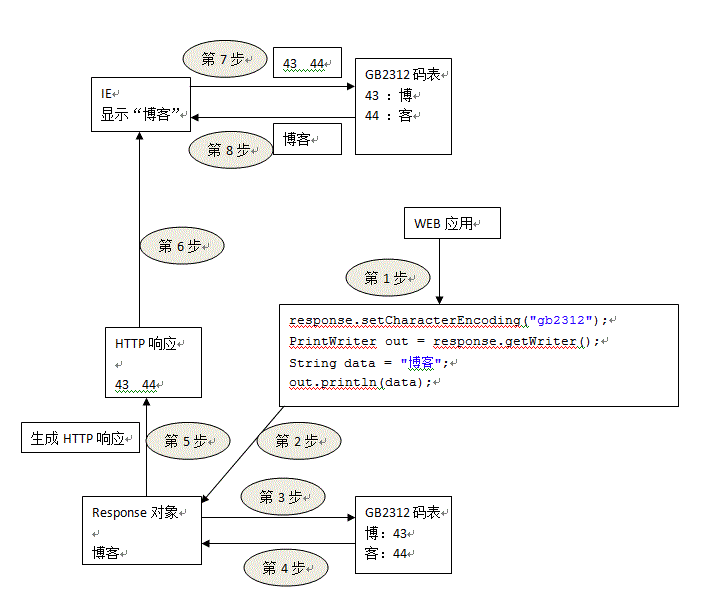
(2)request乱码问题
错误原因:
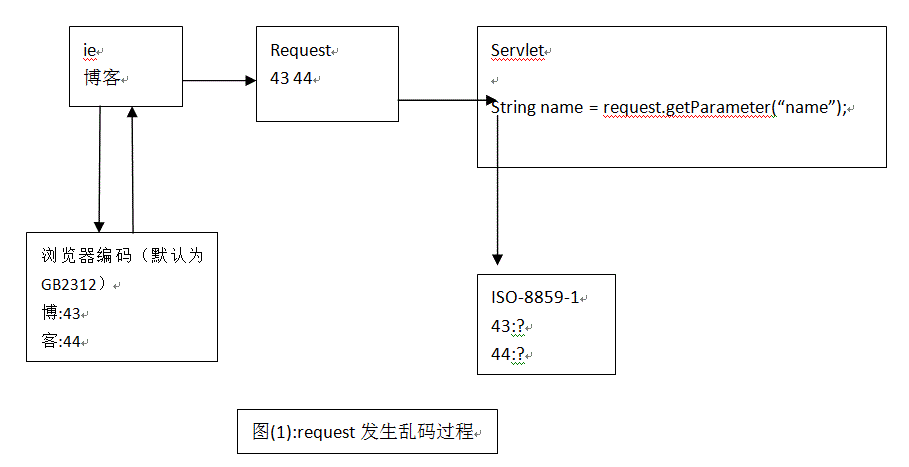
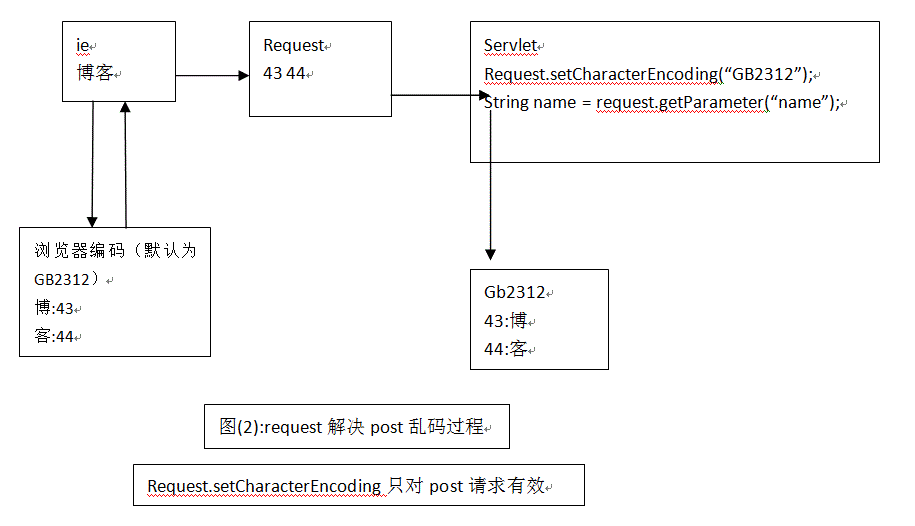
解决方案:
==>GET请求(URI方式传递参数乱码):
如:<a href="/webproject/display.jsp?username=张三&password=123">显示用户名和密码</a>
解决方法:问题本质是get方式传递的参数内容默认编码方式问ISO8859-1,而且使用request.setCharacterEncoding("utf-8")也无法解决问题。
法一:要解决这个问题,修改tomcat服务器的配置文件。修改tomcat目录下的conf/server.xml文件的第43行:
修改前内容:
<Connector port="8080" protocol="HTTP/1.1"
maxThreads="150" connectionTimeout="200000"
redirecPort="8443"/>
修改后内容:
<Connector port="8080" protocol="HTTP/1.1"
maxThreads="150" connectionTimeout="200000"
redirecPort="8443" URIEncoding="utf-8"/>
法二:String usernameString = new String(username.getBytes("ISO-8859-1"),"UTF-8"); (如下图)
法三:URL转换

3、调用数据库出现乱码
安装数据的时候选择UTF-8
四、JSP相关乱码解决方案(部分已经在上面介绍了)
问题描述:通过jsp,html,或servlet中的表单元素把参数提交给对应的jsp或者servlet时,在接收的jsp或servlet中接收到的参数中文显示乱码。
例如:
提交jsp代码如下:
<%@ page language="java" pageEncoding="utf-8"%>
<html>
<head>
<title>输入表单</title>
</head>
<body>
<form id="inputForm" name="inputForm" method="post" action="display.jsp">
用户名:<input type="text" name="username"/><br/>
密 码 :<input type="password" name="password"/><br/>
<input type="submit" name="submit" value="提交"/>
</form>
</body>
</html>
接收参数的jsp代码如下:
<% @ page language="java" pageEncoding="utf-8"%>
<html>
<head>
<tilte>接收表单</title>
</head>
<body>
<% 在这里插入
request.setCharacterEncoding("utf-8");
%>
用户名:<%=request.getParameter("username")%><br/>
密 码:<%=request.getParameter("password")%><br/>
</body>
</html>
解决方法:在接收post提交的参数前,使用request.setCharacterEncoding("utf-8")设定接收参数的内容格式为utf-8编码。见接收表单中的插入内容即可。当然这种乱码问题最好使用中文过滤器的方法最好。
五、properties文件乱码
问题描述:在使用一些类库或者框架时,为了实现页面内容国际化,需要编写对应的properties文件。而properties文件中的中文内容在显示的时候也会出现乱码。
解决方法:这个乱码问题可以通过jdk中的native2ascii工具解决。使用如下命令:
native2ascii -encoding utf-8 display.properties display_zh_CN.properties
出现乱码问题的原因是因为java编译器只能处理Latin-1或unicode编码的字符文件。
Java Web乱码原因与解决的更多相关文章
- Java Web乱码分析及解决方式(一)——GET请求乱码
引言: 在进行Web開始时.乱码是我们最常常遇到也是最主要的问题.有经验的程序员非常easy能解决,刚開始学习的人则easy被泥潭困住. 并且非常多时候.我们即使攻克了乱码问题也是不明就里.往 ...
- Java Web乱码分析及解决方式(二)——POST请求乱码
引言 GET请求的本质表现是将请求參数放在URL地址栏中.form表单的Method为GET的情况.參数会被浏览器默认编码,所以乱码处理方案是一样的. 对于POST请求乱码.解决起来要比GET简单.我 ...
- Java ConcurrentModificationException异常原因和解决方法
Java ConcurrentModificationException异常原因和解决方法 在前面一篇文章中提到,对Vector.ArrayList在迭代的时候如果同时对其进行修改就会抛出java.u ...
- Java并发编程:Java ConcurrentModificationException异常原因和解决方法
Java ConcurrentModificationException异常原因和解决方法 在前面一篇文章中提到,对Vector.ArrayList在迭代的时候如果同时对其进行修改就会抛出java.u ...
- 【转】Java ConcurrentModificationException异常原因和解决方法
原文网址:http://www.cnblogs.com/dolphin0520/p/3933551.html Java ConcurrentModificationException异常原因和解决方法 ...
- 9、Java ConcurrentModificationException异常原因和解决方法
Java ConcurrentModificationException异常原因和解决方法 在前面一篇文章中提到,对Vector.ArrayList在迭代的时候如果同时对其进行修改就会抛出java.u ...
- (转)Java ConcurrentModificationException异常原因和解决方法
转载自:http://www.cnblogs.com/dolphin0520/p/3933551.html 在前面一篇文章中提到,对Vector.ArrayList在迭代的时候如果同时对其进行修改就会 ...
- Java ConcurrentModificationException异常原因和解决方法(转)
摘自:http://www.cnblogs.com/dolphin0520/p/3933551.html#undefined 在前面一篇文章中提到,对Vector.ArrayList在迭代的时候如果同 ...
- Java WEB 乱码解决大全
来自 http://ligure.iteye.com/blog/ 中文乱码:在以后学习过程中全部采用UTF-8 1.文件的乱码 1.1.项目文本文件默认编码: [右击项目]->[P ...
随机推荐
- 折腾Java设计模式之状态模式
原文地址 折腾Java设计模式之状态模式 状态模式 在状态模式(State Pattern)中,类的行为是基于它的状态改变的.这种类型的设计模式属于行为型模式.在状态模式中,我们创建表示各种状态的对象 ...
- 005. [转] SSH端口转发
玩转SSH端口转发 SSH有三种端口转发模式,本地端口转发(Local Port Forwarding),远程端口转发(Remote Port Forwarding)以及动态端口转发(Dynamic ...
- socket字符流循环截取
场景:socket 客户端将一个单向链表序列化后发送给服务端,服务端将之解析,重新构建单向链表. Client.cpp //遍历链表,填充到缓冲区 ]) { ListNode* tmp = p; // ...
- Windows Server(r12) - 配置 MySQL 远程访问
Windows Server(r12) - 配置 MySQL 远程访问 工作主要为两部分, 一部分是 Windows 防火墙, 一部分是 MySQL 自身 Windows 端口远程访问 其实就是在 W ...
- iis问题
1.8.5版本的iis配置完成,不能打开网页显示503.原因是应用程序池,加载用户配置文件失败,然后应用程序池关闭了.关闭它就可以正常打开了. server2008,打不开网页,打开url显示目录的原 ...
- 百度地图引用时 报出A Parser-blocking, cross site (i.e. different eTLD+1) script
页面引入百度地图api时 chrome控制台报出警示问题 A Parser-blocking, cross site (i.e. different eTLD+1) script, http://ap ...
- Oracle知识点总结2
1.聚合函数:也叫分组函数. 常用聚合函数:返回的都是NUMBER类型的值. 注:避免使用 COUNT(*) ,而使用 COUNT(ROWID) 2.分组统计:group by 字段名 having ...
- background问题
1.如果是小图的背景图 background: url("@{images-dir}/homepage/our_pro_2x.png") no-repeat 0 0; backgr ...
- js 秒数格式化
function formatSeconds(value) { var theTime = parseInt(value);// 秒 var theTime1 = 0;// 分 var theTime ...
- 利用Sonar定制自定义扫描规则
上有3种方法可以自定义soanr的代码校验规则: 直接在sonar的web接口中增加XPath规则: 通过插件的功能来增加自定义规则,比如checkstyle,pmd等插件是允许自定义规则的: 通 ...