强化学习(十七) 基于模型的强化学习与Dyna算法框架
在前面我们讨论了基于价值的强化学习(Value Based RL)和基于策略的强化学习模型(Policy Based RL),本篇我们讨论最后一种强化学习流派,基于模型的强化学习(Model Based RL),以及基于模型的强化学习算法框架Dyna。
本篇主要参考了UCL强化学习课程的第8讲和Dyna-2的论文。
1. 基于模型的强化学习简介
基于价值的强化学习模型和基于策略的强化学习模型都不是基于模型的,它们从价值函数,策略函数中直接去学习,不用学习环境的状态转化概率模型,即在状态$s$下采取动作$a$,转到下一个状态$s'$的概率$P_{ss'}^a$。
而基于模型的强化学习则会尝试从环境的模型去学习,一般是下面两个相互独立的模型:一个是状态转化预测模型,输入当前状态$s$和动作$a$,预测下一个状态$s'$。另一个是奖励预测模型,输入当前状态$s$和动作$a$,预测环境的奖励$r$。即模型可以描述为下面两个式子:$$S_{t+1} \sim P(S_{t+1}|S_t,A_t)$$$$R_{t+1} \sim R(R_{t+1}|S_t,A_t)$$
如果模型$P,R$可以准确的描述真正的环境的转化模型,那么我们就可以基于模型来预测,当有一个新的状态$S$和动作$A$到来时,我们可以直接基于模型预测得到新的状态和动作奖励,不需要和环境交互。当然如果我们的模型不好,那么基于模型预测的新状态和动作奖励可能错的离谱。
从上面的描述我们可以看出基于模型的强化学习和不基于模型的强化学习的主要区别:即基于模型的强化学习是从模型中学习,而不基于模型的强化学习是从和环境交互的经历去学习。
下面这张图描述了基于模型的强化学习的思路:
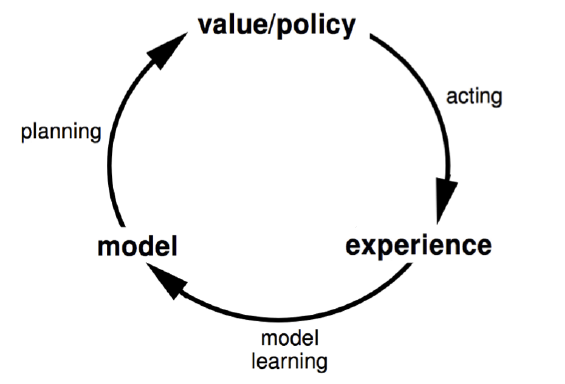
2. 基于模型的强化学习算法训练流程
这里我们看看基于模型的强化学习算法训练流程,其流程和我们监督学习算法是非常类似的。
假设训练数据是若干组这样的经历:$$S_1,A_1,R_2,S_2,A_2,R_2,...,S_T$$
对于每组经历,我们可以将其转化为$T-1$组训练样本,即:$$S_1,A_1 \to S_2,\;S_1,A_1 \to R_2$$$$S_2,A_2 \to S_3,\;S_2,A_2 \to R_3$$$$......$$$$S_{T-1},A_{T-1} \to S_T,\;S_{T_1},A_{T-1} \to R_T$$
右边的训练样本一起组成了一个分类模型或密度估计模型,输入状态和动作,输出下一个状态。 右边的训练样本一起组成了一个回归模型训练集,输入状态和动作,输出动作奖励值。
至此我们的强化学习求解过程和传统的监督学习算法没有太多区别了,可以使用传统的监督学习算法来求解这两个模型。
当然还可以更简单,即通过对训练样本进行查表法进行统计,直接得到$P(S_{t+1}|S_t,A_t)$的概率和$R(R_{t+1}|S_t,A_t)$的平均值,这样就可以直接预测。比使用模型更简单。
此外,还有其他的方法可以用来得到$P(S_{t+1}|S_t,A_t)$和$R(R_{t+1}|S_t,A_t)$,这个我们后面再讲。
虽然基于模型的强化学习思路很清晰,而且还有不要和环境持续交互优化的优点,但是用于实际产品还是有很多差距的。主要是我们的模型绝大多数时候不能准确的描述真正的环境的转化模型,那么使用基于模型的强化学习算法得到的解大多数时候也不是很实用。那么是不是基于模型的强化学习就不能用了呢?也不是,我们可以将基于模型的强化学习和不基于模型的强化学习集合起来,取长补短,这样做最常见的就是Dyna算法框架。
3. Dyna算法框架
Dyna算法框架并不是一个具体的强化学习算法,而是一类算法框架的总称。Dyna将基于模型的强化学习和不基于模型的强化学习集合起来,既从模型中学习,也从和环境交互的经历去学习,从而更新价值函数和(或)策略函数。如果用和第一节类似的图,可以表示如下图,和第一节的图相比,多了一个“Direct RL“的箭头,这正是不基于模型的强化学习的思路。
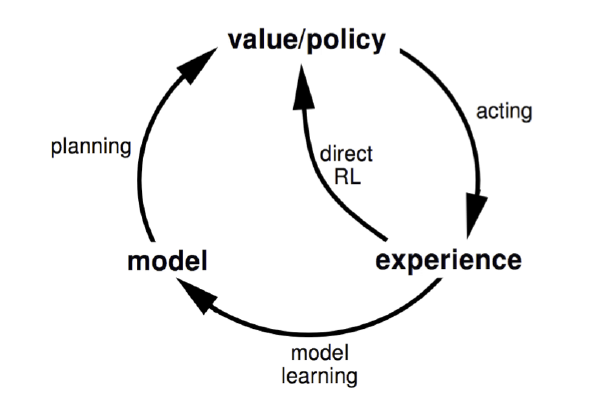
Dyna算法框架和不同的具体的不基于模型的强化学习一起,可以得到具体的不同算法。如果我们使用基于价值函数的Q-Learning,那么我们就得到了Dyna-Q算法。我们基于Dyna-Q来看看Dyna算法框架的一般流程.
4. Dyna-Q算法流程
这里我们给出基于价值函数的Dyna-Q算法的概要流程。假设模型使用的是查表法。
1. 初始化任意一个状态$s$,和任意一个动作$a$对应的状态价值$Q(s,a)$, 初始化奖励模型$R(s,a)$和状态模型$P(s,a)$
2. for i=1 to 最大迭代次数T:
a) S $\gets$ current state
b) A $\gets$ $\epsilon-greedy(S,Q)$
c) 执行动作$A$,得到新状态$S'$和奖励$R$
d) 使用Q-Learning更新价值函数:$Q(S,A) =Q(S,A) + \alpha[R +\gamma\max_aQ(S',a) -Q(S,A)]$
e) 使用$S,A,S'$更新状态模型$P(s,a)$,使用$S,A,R$更新状态模型$R(s,a)$
f) for j=1 to 最大次数n:
i) 随机选择一个之前出现过的状态$S$, 在状态$S$上出现过的动作中随机选择一个动作$A$
ii) 基于模型$P(S,A)$得到$S'$, 基于模型$R(S,A)$得到$R$
iii) 使用Q-Learning更新价值函数:$Q(S,A) =Q(S,A) + \alpha[R +\gamma\max_aQ(S',a) -Q(S,A)]$
从上面的流程可以看出,Dyna框架在每个迭代轮中,会先和环境交互,并更新价值函数和(或)策略函数,接着进行n次模型的预测,同样更新价值函数和(或)策略函数。这样同时利用上了和环境交互的经历以及模型的预测。
5. Dyna-2算法框架
在Dyna算法框架的基础上后来又发展出了Dyna-2算法框架。和Dyna相比,Dyna-2将和和环境交互的经历以及模型的预测这两部分使用进行了分离。还是以Q函数为例,Dyna-2将记忆分为永久性记忆(permanent memory)和瞬时记忆(transient memory), 其中永久性记忆利用实际的经验来更新,瞬时记忆利用模型模拟经验来更新。
永久性记忆的Q函数定义为:$$Q(S,A) = \phi(S,A)^T\theta$$
瞬时记忆的Q函数定义为:$$Q'(S,A) = \overline{\phi}(S,A)^T\overline{\theta }$$
组合起来后记忆的Q函数定义为:$$\overline{Q}(S,A) = \phi(S,A)^T\theta + \overline{\phi}(S,A)^T\overline{\theta }$$
Dyna-2的基本思想是在选择实际的执行动作前,智能体先执行一遍从当前状态开始的基于模型的模拟,该模拟将仿真完整的轨迹,以便评估当前的动作值函数。智能体会根据模拟得到的动作值函数加上实际经验得到的值函数共同选择实际要执行的动作。价值函数的更新方式类似于$SARSA(\lambda)$
以下是Dyna-2的算法流程:

6. 基于模型的强化学习总结
基于模型的强化学习一般不单独使用,而是和不基于模型的强化学习结合起来,因此使用Dyna算法框架是常用的做法。对于模型部分,我们可以用查表法和监督学习法等方法,预测或者采样得到模拟的经历。而对于非模型部分,使用前面的Q-Learning系列的价值函数近似,或者基于Actor-Critic的策略函数的近似都是可以的。
除了Dyna算法框架,我们还可以使用基于模拟的搜索(simulation-based search)来结合基于模型的强化学习和不基于模型的强化学习,并求解问题。这部分我们在后面再讨论。
(欢迎转载,转载请注明出处。欢迎沟通交流: liujianping-ok@163.com)
强化学习(十七) 基于模型的强化学习与Dyna算法框架的更多相关文章
- 强化学习之五:基于模型的强化学习(Model-based RL)
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- 伯克利、OpenAI等提出基于模型的元策略优化强化学习
基于模型的强化学习方法数据效率高,前景可观.本文提出了一种基于模型的元策略强化学习方法,实践证明,该方法比以前基于模型的方法更能够应对模型缺陷,还能取得与无模型方法相近的性能. 引言 强化学习领域近期 ...
- ICML 2018 | 从强化学习到生成模型:40篇值得一读的论文
https://blog.csdn.net/y80gDg1/article/details/81463731 感谢阅读腾讯AI Lab微信号第34篇文章.当地时间 7 月 10-15 日,第 35 届 ...
- 时间序列深度学习:seq2seq 模型预测太阳黑子
目录 时间序列深度学习:seq2seq 模型预测太阳黑子 学习路线 商业中的时间序列深度学习 商业中应用时间序列深度学习 深度学习时间序列预测:使用 keras 预测太阳黑子 递归神经网络 设置.预处 ...
- 聚类:层次聚类、基于划分的聚类(k-means)、基于密度的聚类、基于模型的聚类
一.层次聚类 1.层次聚类的原理及分类 1)层次法(Hierarchicalmethods)先计算样本之间的距离.每次将距离最近的点合并到同一个类.然后,再计算类与类之间的距离,将距离最近的类合并为一 ...
- 基于Matlab的MMSE的语音增强算法的研究
本课题隶属于学校的创新性课题研究项目.2012年就已经做完了,今天一并拿来发表. 目录: --基于谱减法的语音信号增强算法..................................... ...
- 基于模糊Choquet积分的目标检测算法
本文根据论文:Fuzzy Integral for Moving Object Detection-FUZZ-IEEE_2008的内容及自己的理解而成,如果想了解更多细节,请参考原文.在背景建模中,我 ...
- 强化学习之 免模型学习(model-free based learning)
强化学习之 免模型学习(model-free based learning) ------ 蒙特卡罗强化学习 与 时序查分学习 ------ 部分节选自周志华老师的教材<机器学习> 由于现 ...
- ML.NET 示例:图像分类模型训练-首选API(基于原生TensorFlow迁移学习)
ML.NET 版本 API 类型 状态 应用程序类型 数据类型 场景 机器学习任务 算法 Microsoft.ML 1.5.0 动态API 最新 控制台应用程序和Web应用程序 图片文件 图像分类 基 ...
随机推荐
- Hi,这有一份风控体系建设干货
互联网.移动互联网.云计算.大数据.人工智能.物联网.区块链等技术已经在人类经济生活中扮演越来越重要的角色,技术给人类带来各种便利的同时,很多企业也饱受"硬币"另一面的伤害,并且形 ...
- Java学习导航
由于最近在系统的重新学习Java,为了便于日后复习,给个人博客中Java内容做一个目录. Java基础:Java虚拟机(JVM) Java基础:内存模型 Java基础:JVM垃圾回收算法 Java基础 ...
- Java RandomAccessFile用法 【转】
RandomAccessFile源地址:http://blog.csdn.net/akon_vm/article/details/7429245 RandomAccessFile是用来访问那些保存数据 ...
- 【转】javascript 浮点数运算问题
大多数语言在处理浮点数的时候都会遇到精度问题,但是在JS里似乎特别严重,来看一个例子 alert(45.6*13); 结果居然是592.800000000001,当然加法之类的也会有这个问题 那这是j ...
- Python Cook函数笔记 【第一章】
2017年4月28日 19:29:52 解压赋值给多个变量 可迭代的对象(list,tuple,string,文件对象,迭代器,生成器等),都可以进行解压赋值给多个对象. #!/usr/bin/env ...
- Python_FTP通讯软件
ftpServer.py import socket import threading import os import struct #用户账号.密码.主目录 #也可以把这些信息存放到数据库中 us ...
- CAS与OAuth2的区别
CAS与OAuth2的区别 一. CAS的单点登录时保障客户端的用户资源的安全 . OAuth2则是保障服务端的用户资源的安全 . 二. CAS客户端要获取的最终信息是,这个用户到底有没有权限访问我( ...
- Spring @Conditional注解的使用
Spring Boot的强大之处在于使用了Spring 4框架的新特性:@Conditional注释,此注释使得只有在特定条件满足时才启用一些配置. 下面来介绍如何使用Condition 首先写一个类 ...
- zabbix监控mysql性能
使用zabbix监控mysql的三种方式 1.只是安装agent 2.启用模板监控 3.启用自定义脚本的模板监控 zabbix中默认有mysql的监控模板.默认已经在zabbix2.2及以上的版本中. ...
- HTTP协议GET HEAD简单介绍
一.HTTP协议简介 超文本传输协议(Hypertext Transfer Protocol,简称HTTP)是应用层协议,自 1990 年起,HTTP 就已经被应用于 WWW 全球信息服务系统. HT ...