Titanic数据分析
一.材料准备
https://www.kaggle.com/c/titanic-gettingStarted/
二.提出问题
生存率和哪些因素有关(性别,年龄,是否有伴侣,票价,舱位等级,包间,出发地点)
1.乘客的年龄和票价的分布
2.样本生存的几率是多少
3.乘客的性别比例
4.乘客的舱位分布
5.性别和生还有没有关系
6.舱位等级和生还有没有关系
7.年龄和生还有没有关系
8.出发地点和生存率有没有关系
9.票价和生还有没有关系
10.有陪伴的乘客的生还几率是否更高
三.编写代码和做出图形来验证所提出的的问题
1.加载数据
%pylab inline
%matplotlib inline
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
titanic_data = pd.read_csv('titanic-data.csv')
titanic_data.info()
结论:Age,Embarked这两列需要进行数据清洗,因为Cabin列缺失的数据太多所以不能作为分析的依据
2.自定义函数分析数据
#统计变量和生存率的关系,如果需要使用堆栈图更清晰的展示数据,stacked的值设置为True,为False默认展示该变量下的生存率
def visualize_survival(feature,stacked=False):
if stacked:
survived_rate = titanic_data.groupby([feature,'Survived'])['Survived'].count().unstack().plot(kind='bar',stacked='True')
else:
survived_rate = (titanic_data.groupby([feature]).sum()/titanic_data.groupby([feature]).count())['Survived']
survived_rate.plot(kind='bar')
plt.title(feature + ' V.S. Survival')
#比较单个变量之间的关系,feature表示要分析的列,args表示x轴的名称
def visualize_column(feature,*args):
fig,ax=plt.subplots(figsize=(7,5))
titanic_data[feature].value_counts().plot(kind='bar')
for i in range(len(args)):
ax.set_xticklabels((args[i]),rotation='horizontal')
ax.set_title('bar of ' + feature)
3.分析乘客年龄和票价分布
fig,axes=plt.subplots(2,1,figsize=(15,5))
titanic_data['Age'].hist(ax=axes[0]) #年龄分布
axes[0].set_title('plot of age')
titanic_data['Fare'].hist(ax=axes[1]) #票价分布
axes[1].set_title('plot of fare')
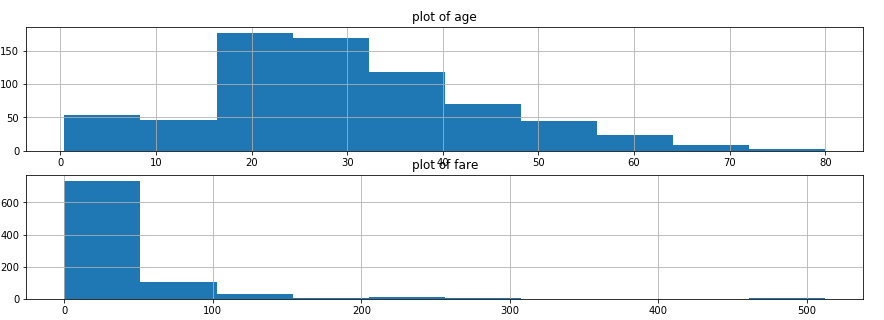
结论:
1.大部分乘客的年龄在20到40岁之间
2.票价在主要分布在(0,100)美元之间
4.样本的生存几率
survived_rate = float(titanic_data['Survived'].sum())/titanic_data['Survived'].count()
print survived_rate
by_survived = titanic_data.groupby(['Survived'])['Survived'].count()
plt.pie(by_survived,labels=['Non-Survived','Survived'],autopct='%1.0f%%')
plt.title('Pie Chart Of Surviveness for Surviveness of Passengers')

结论:整体的存活率约等于0.384,不超过40%的存活率
5.乘客的性别比例
visualize_column('Sex',('Male','Female'))

结论:大部分的乘客是男性,男性比女性多50%
6.乘客的舱位分布
visualize_column('Pclass',('Class 3','Class 2','Class 1'))
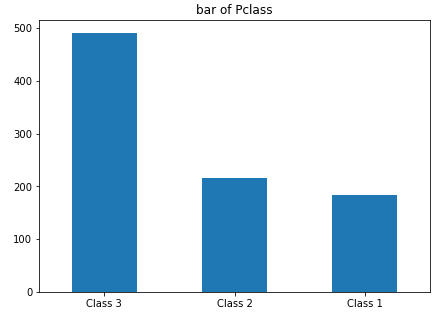
结论:三等舱的工人和奴隶占绝大多数,大约是一二等舱的总和
7.性别和生还的关系
visualize_survival('Sex',True)

结论:女性的生还人数远远超过男性
8.舱位等级和生还的关系
visualize_survival('Pclass',True)

结论:1等舱生还的几率超过50%,2等舱的生还几率接近50%,而三等舱获救的可能性最低,证实了事故发生时三等舱被第一时间锁死
9.年龄和生还的关系
首先年龄这一列存在多个空值,要进行数据的清洗,利用非空的年龄字段计算出平均年龄来填充到空值字段,其次分段是在(0,80]之间,所以以10年作为分段点可以更直观的看出年龄和生存率的关联
titanic_data.Age.fillna(titanic_data.Age.mean(),inplace=True) #使用均值来填充Age中的空值
ages = np.arange(0,90,10) #年龄分段
titanic_data['age_cut'] = pd.cut(titanic_data.Age,ages)
visualize_survival('age_cut',True)

结论:婴儿的生存比例较高,其次(20,40)岁之间的成年人生存所占比例较高,50岁以上老人和10岁左右的儿童少年生存率偏低
10.出发地点和生存率的关系
发现有个上船地点是空值,要进行数据的清洗,因为空值的票价接近于瑟堡的中位数,所以以C填充空值
titanic_data.Embarked[titanic_data.Embarked.isnull()]
print titanic_data[titanic_data['Embarked'].isin(['S','C','Q'])==False]
titanic1 = titanic_data[titanic_data['Pclass']==1]
ax=sns.boxplot(titanic1.Embarked,titanic1.Fare)
plt.plot((-100,100),(80,80),'r-')
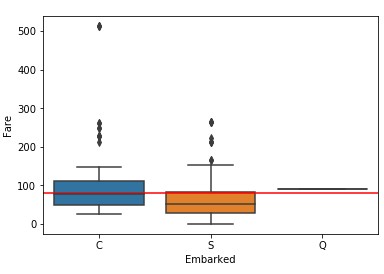
做出结论图形
titanic_data.Embarked=titanic_data.Embarked.fillna('C')
visualize_survival('Embarked')
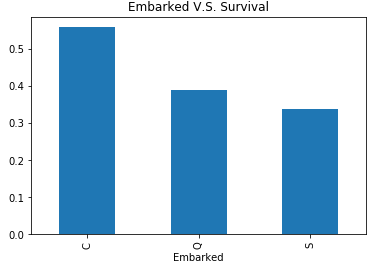
结论:从瑟堡,皇后镇,南安普顿的上船的生存率依次下降
11.票价和生存率的关系
根据问题1的分析可得出票价的分段在(0,500]美金之间,但是根据数据分组来看票价有异常值,如果票价大于100美金则为异常值,需要舍弃否则会影响统计结果的表达,
fares = np.arange(0,600,50) #划分票价区间
fares_cut = pd.cut(titanic_data.Fare,fares)
fares_cut_group = titanic_data.groupby(fares_cut)
fares_cut_group.count().PassengerId #获取异常数据
titanic_data.Fare.sort_values(ascending=False).head() #查看异常数据
#进行IQR运算找出异常数据
q75,q25 = np.percentile(titanic_data.Fare,[75,25])
iqr = q75-q25
print q75+iqr*3 #确定异常数据的值
结论:超过100.27美金的票价都是异常值,在接下来的分析中要舍弃
重新进行票价的统计分区,做出图形
fares_count = titanic_data.Fare[titanic_data.Fare<100.27] #舍弃异常数据
fares_count_range = np.arange(0,110,10) #重新计算票价区间
titanic_data['new_fare'] = pd.cut(titanic_data.Fare,fares_count_range)
visualize_survival('new_fare')
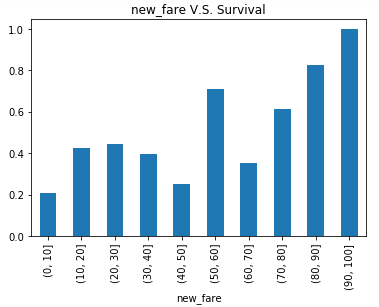
结论:总体来说票价越高生还的几率越大
12.有陪伴的乘客的生还几率是否更高
#通过SibSp+Parch总体计算出陪伴的生还率
titanic_data['family_member'] = titanic_data.SibSp+titanic_data.Parch
visualize_survival('family_member')
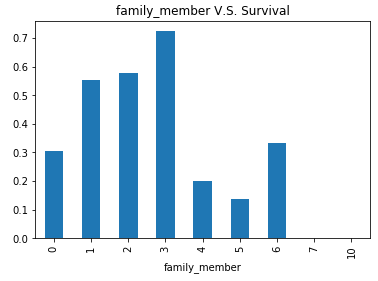
结论:当有1,2个家庭成员结伴出行的时候,生存率较高,但不是主要提高生存的途径
四.总结:
由上述一系列图表可知
1.样本整体的存活率大约为39%
2.性别是影响生存率的最主要的因素
3.票价和舱位是影响生存率的第二要因
4.年龄和生存率没有太大的关系
5.上船地点和是否家人结伴略微地影响了生存率
五.分析限制讨论:
1.此样本并非是泰坦尼克号全部乘客的数据,据了解,泰坦尼克号一共有2224名乘客,本数据一共是891名乘客,如果是891名乘客根据是从2224名乘客中随机选出,根据中心极限定理,该样本足够大,分析结论具有代表性,如果不是随机抽取,那么分析的结果就不可靠
2.可能还有其他影响生存的情况,比如国籍是否影响生存率,是否会游泳会不会影响生存率,不同的职业会不会影响生存率
Titanic数据分析的更多相关文章
- kaggle数据挖掘竞赛初步--Titanic<原始数据分析&缺失值处理>
Titanic是kaggle上的一道just for fun的题,没有奖金,但是数据整洁,拿来练手最好不过啦. 这道题给的数据是泰坦尼克号上的乘客的信息,预测乘客是否幸存.这是个二元分类的机器学习问题 ...
- kaggle数据挖掘竞赛初步--Titanic<随机森林&特征重要性>
完整代码: https://github.com/cindycindyhi/kaggle-Titanic 特征工程系列: Titanic系列之原始数据分析和数据处理 Titanic系列之数据变换 Ti ...
- kaggle数据挖掘竞赛初步--Titanic<派生属性&维归约>
完整代码: https://github.com/cindycindyhi/kaggle-Titanic 特征工程系列: Titanic系列之原始数据分析和数据处理 Titanic系列之数据变换 Ti ...
- kaggle数据挖掘竞赛初步--Titanic<数据变换>
完整代码: https://github.com/cindycindyhi/kaggle-Titanic 特征工程系列: Titanic系列之原始数据分析和数据处理 Titanic系列之数据变换 Ti ...
- 数据分析神器Colab的初探
为什么要使用Colab 使用过Jupyter(参看<「极客时间」带来的社区价值思考>章节:社区交流的基建设施)的朋友,一定会醉心于它干净简洁的设计,以及在"摆脱Python命令行 ...
- kaggle入门项目:Titanic存亡预测(二)数据处理
原kaggle比赛地址:https://www.kaggle.com/c/titanic 原kernel地址:A Data Science Framework: To Achieve 99% Accu ...
- kaggle入门项目:Titanic存亡预测 (一)比赛简介
自从入了数据挖掘的坑,就在不停的看视频刷书,但是总觉得实在太过抽象,在结束了coursera上Andrew Ng 教授的机器学习课程还有刷完一整本集体智慧编程后更加迷茫了,所以需要一个实践项目来扎实之 ...
- 数据分析——pandas
简介 import pandas as pd # 在数据挖掘前一个数据分析.筛选.清理的多功能工具 ''' pandas 可以读入excel.csv等文件:可以创建Series序列,DataFrame ...
- 机器学习案例学习【每周一例】之 Titanic: Machine Learning from Disaster
下面一文章就总结几点关键: 1.要学会观察,尤其是输入数据的特征提取时,看各输入数据和输出的关系,用绘图看! 2.训练后,看测试数据和训练数据误差,确定是否过拟合还是欠拟合: 3.欠拟合的话,说明模 ...
随机推荐
- python科学计算之numpy
1.np.logspace(start,stop,num): 函数表示的意思是;在(start,stop)间生成等比数列num个 eg: import numpy as np print np.log ...
- NPOI操作Excel 踩坑记
1 读取Excel并修改单元格 a.一定不能一边读数据,一边修改单元格,否则读出来的数据可能不准 b.注意写文件的模式,不然修改后的文件,打开会报错. c.清空单元格的数据,可以调用SetCellTy ...
- CSS3让长单词与URL地址自动换行——word-wrap属性
div{ word-wrap:break-word; } word-wrap属性可以使用的属性值为normal与break-word两个.使用normal属性值时浏览器默认处理,只在半角空格或者连字符 ...
- 教你如何解决Sublime Text 3使用中出现的中文乱码问题
Sublime Text 3 是一个非常不错的源代码及文本编辑器,但是不支持GB2312和GBK编码在很多情况下会非常麻烦. 不过Sublime Package Control所提供的插件可以让Sub ...
- JavaScript八张思维导图—字符串用法
JS基本概念 JS操作符 JS基本语句 JS数组用法 Date用法 JS字符串用法 JS编程风格 JS编程实践 不知不觉做前端已经五年多了,无论是从最初的jQuery还是现在火热的Angular,Vu ...
- mysql中使用show table status 查看表信息
学习标签: mysql 本文导读:在使用mysql数据库时,经常需要对mysql进行维护,查询每个库.每个表的具体使用情况,Mysql数据库可以通过执行SHOW TABLE STATUS命令来获取每个 ...
- html dl dt dd标签元素语法结构与使用
dl dt dd认识及dl dt dd使用方法 标签用于定义列表类型标签. dl dt dd目录 dl dt dd介绍 结构语法 dl dt dd案例 dl dt dd总结 一.dl dt dd认识 ...
- Java中的SerialVersionUID
Java中的SerialVersionUID 序列化及SergalVersionUID困扰着许多Java开发人员.我经常会看到这样的问题,什么是SerialVersionUID,如果实现了Serial ...
- UWP: 实现 UWP 应用自启动
在上一篇文章中,我们实现了使用命令行来启动 UWP 应用,在这一篇文章中,我们会实现 UWP 应用自启用的实现,也即开机后或用户登陆后,应用自己启动.这些特性原来都是 Win32 程序所具备的,UWP ...
- linux 从softnet_stat查看内核丢包信息
1.从系统整体来考虑,通过netstat 查看: [root@localhost net]# netstat -s |grep drop 3168 outgoing packets dropped 1 ...