利用python设计PDF报告,jinja2,whtmltopdf,matplotlib,pandas
转自:https://foofish.net/python-crawler-html2pdf.html
工具准备
弄清楚了网站的基本结构后就可以开始准备爬虫所依赖的工具包了。requests、beautifulsoup 是爬虫两大神器,reuqests 用于网络请求,beautifusoup 用于操作 html 数据。有了这两把梭子,干起活来利索,scrapy 这样的爬虫框架我们就不用了,小程序派上它有点杀鸡用牛刀的意思。此外,既然是把 html 文件转为 pdf,那么也要有相应的库支持, wkhtmltopdf 就是一个非常好的工具,它可以用适用于多平台的 html 到 pdf 的转换,pdfkit 是 wkhtmltopdf 的Python封装包。首先安装好下面的依赖包,接着安装 wkhtmltopdf
pip install requests
pip install beautifulsoup4
pip install pdfkit
安装 wkhtmltopdf
Windows平台直接在 wkhtmltopdf 官网下载稳定版的进行安装,安装完成之后把该程序的执行路径加入到系统环境 $PATH 变量中,否则 pdfkit 找不到 wkhtmltopdf 就出现错误 “No wkhtmltopdf executable found”。Ubuntu 和 CentOS 可以直接用命令行进行安装
$ sudo apt-get install wkhtmltopdf # ubuntu
$ sudo yum intsall wkhtmltopdf # centos
爬虫实现
一切准备就绪后就可以上代码了,不过写代码之前还是先整理一下思绪。程序的目的是要把所有 URL 对应的 html 正文部分保存到本地,然后利用 pdfkit 把这些文件转换成一个 pdf 文件。我们把任务拆分一下,首先是把某一个 URL 对应的 html 正文保存到本地,然后找到所有的 URL 执行相同的操作。
用 Chrome 浏览器找到页面正文部分的标签,按 F12 找到正文对应的 div 标签: <div class="x-wiki-content">,该 div 是网页的正文内容。用 requests 把整个页面加载到本地后,就可以使用 beautifulsoup 操作 HTML 的 dom 元素 来提取正文内容了。
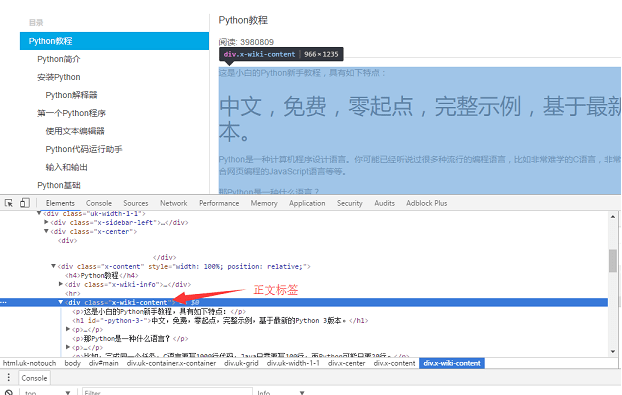
具体的实现代码如下:用 soup.find_all 函数找到正文标签,然后把正文部分的内容保存到 a.html 文件中。
def parse_url_to_html(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
body = soup.find_all(class_="x-wiki-content")[0]
html = str(body)
with open("a.html", 'wb') as f:
f.write(html)
第二步就是把页面左侧所有 URL 解析出来。采用同样的方式,找到 左侧菜单标签 <ul class="uk-nav uk-nav-side">
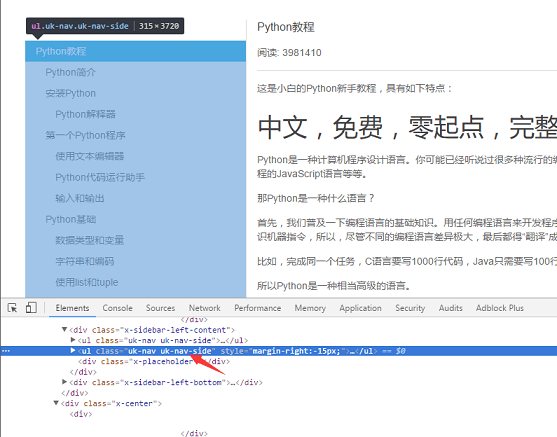
具体代码实现逻辑:因为页面上有两个uk-nav uk-nav-side的 class 属性,而真正的目录列表是第二个。所有的 url 获取了,url 转 html 的函数在第一步也写好了。
def get_url_list():
"""
获取所有URL目录列表
"""
response = requests.get("http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000")
soup = BeautifulSoup(response.content, "html.parser")
menu_tag = soup.find_all(class_="uk-nav uk-nav-side")[1]
urls = []
for li in menu_tag.find_all("li"):
url = "http://www.liaoxuefeng.com" + li.a.get('href')
urls.append(url)
return urls
最后一步就是把 html 转换成pdf文件了。转换成 pdf 文件非常简单,因为 pdfkit 把所有的逻辑都封装好了,你只需要调用函数 pdfkit.from_file
def save_pdf(htmls):
"""
把所有html文件转换成pdf文件
"""
options = {
'page-size': 'Letter',
'encoding': "UTF-8",
'custom-header': [
('Accept-Encoding', 'gzip')
]
}
pdfkit.from_file(htmls, file_name, options=options)
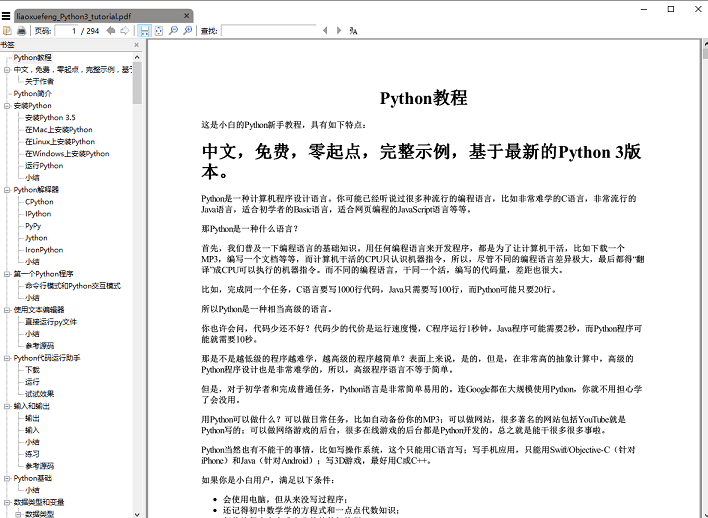
执行 save_pdf 函数,电子书 pdf 文件就生成了,效果图:
总结
原文总结1:总共代码量加起来不到50行,不过,且慢,其实上面给出的代码省略了一些细节,比如,如何获取文章的标题,正文内容的 img 标签使用的是相对路径,如果要想在 pdf 中正常显示图片就需要将相对路径改为绝对路径,还有保存下来的 html 临时文件都要删除,完整代码放在github上。
我的总结:此方法可以用于利用python脚本加上html模板jinja2库生产批量的pdf报告,将变量渲染到html模板中,生产html文件,将排版好的html文件利用pdfkit或者命令行模式的htmltopdf可以直接生成pdf文件,同时可以利用python调用打印机接口,或者acrobat接口打印或者预览pdf,并且加上tkinter等库生产UI界面,给客户展示一个完整的报告打印预览界面。
利用python设计PDF报告,jinja2,whtmltopdf,matplotlib,pandas的更多相关文章
- 利用PYTHON设计计算器功能
通过利用PYTHON 设计处理计算器的功能如: 1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 ))- (-4*3 ...
- 利用Python将PDF文档转为MP3音频
1. 转语音工具 微信读书有一个功能,可以将书里的文字转换为音频,而且声音优化的不错,比传统的机械朗读听起来舒服很多. 记得之前看到过Python有一个工具包,可以将文字转换为语音,支持英文和中文,而 ...
- python生成pdf报告、python实现html转换为pdf报告
1.先说下html转换为pdf:其实支持直接生成,有三个函数pdfkit.f 安装python包:pip Install pdfkit 系统安装wkhtmltopdf:参考 https://githu ...
- 参考《利用Python进行数据分析(第二版)》高清中文PDF+高清英文PDF+源代码
第2版针对Python 3.6进行全面修订和更新,涵盖新版的pandas.NumPy.IPython和Jupyter,并增加大量实际案例,可以帮助高效解决一系列数据分析问题. 第2版中的主要更新了Py ...
- 利用 Python 尝试采用面向对象的设计方法计算图形面积及周长
利用 Python 尝试采用面向对象的设计方法.(1)设计一个基类 Shape:包含两个成员函数:def cal_area(): 计算并返回该图形的面积,保留两位小数:def cal_perimete ...
- 《基于Python的GMSSL实现》课程设计个人报告
<基于Python的GMSSL实现>课程设计个人报告 一.基本信息 姓名:刘津甫 学号:20165234 题目:GMSSL基于python的实现 指导老师:娄嘉鹏 完成时间:2019年5月 ...
- 利用python第三方库提取PDF文件的表格内容
小爬最近接到一个棘手任务:需要提取手机话费电子发票PDF文件中的数据.接到这个任务的第一时间,小爬决定搜集各个地区各个时间段的电子发票文件,看看其中的差异点.粗略统计下来,PDF文件的表格框架是统一的 ...
- Python程序设计实验报告四:循环结构程序设计(设计型实验)
安徽工程大学 Python程序设计 实验报告 班级 物流191 姓名 姚彩琴 学号3190505129 成绩 日期 2020.4.8 指导老师 修宇 [实验名称 ...
- 利用python进行数据分析PDF高清完整版免费下载|百度云盘|Python基础教程免费电子书
点击获取提取码:hi2j 内容简介 [名人推荐] "科学计算和数据分析社区已经等待这本书很多年了:大量具体的实践建议,以及大量综合应用方法.本书在未来几年里肯定会成为Python领域中技术计 ...
随机推荐
- python cookbook第三版学习笔记十二:类和对象(三)创建新的类或实例属性
先介绍几个类中的应用__getattr__,__setattr__,__get__,__set__,__getattribute__,. __getattr__:当在类中找不到attribute的时候 ...
- redis分布式锁和消息队列
最近博主在看redis的时候发现了两种redis使用方式,与之前redis作为缓存不同,利用的是redis可设置key的有效时间和redis的BRPOP命令. 分布式锁 由于目前一些编程语言,如PHP ...
- CC攻击网站和游戏如何针对性预防?
1:CC攻击原理 CC = Challenge Collapsar,其前身名为Fatboy攻击,是利用不断对网站发送连接请求致 使形成拒绝服务的目的, CC攻击是DDOS(分布式拒绝服务)的一种,相比 ...
- struts加载spring
为了在Struts中加载Spring context,需要在struts-config.xml文件中加入如下部分: <struts-config> <plug-in classNam ...
- MQ通道搭建以及连通性检查
场景:项目开发中使用的mq中间件一直不太熟悉,遇到问题就需要问人,公司的同事也不怎么爱搭理,弄的好受伤!不熟悉的时候只是感觉好难,逼的没办法,好好研究下,发现里面的过程也没想象中的难, 经过一番研究, ...
- (转)JAVA反射机制理解
JAVA反射机制: 通俗地说,反射机制就是可以把一个类,类的成员(函数,属性),当成一个对象来操作,希望读者能理解,也就是说,类,类的成员,我们在运行的时候还可以动态地去操作他们. 理论的东东太多也没 ...
- Java之IO流补充
IO流例子 package com.hanqi.maya.util; import java.io.BufferedReader; import java.io.BufferedWriter; imp ...
- 蓝桥杯比赛关于 BFS 算法总结方法以及套路分析
首先我们来看几道java A组的题目,都是同一年的哦!!! 搭积木 小明最近喜欢搭数字积木,一共有10块积木,每个积木上有一个数字,0~9. 搭积木规则:每个积木放到其它两个积木的上面,并且一定比下面 ...
- 【RegExp】JavaScript中正则表达式判断匹配规则以及常用方法
字符串是编程时涉及到的最多的一种数据结构,对字符串进行操作的需求几乎无处不在. 正则表达式是一种用来匹配字符串的强有力的武器.它的设计思想是用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符 ...
- [js高手之路] es6系列教程 - var, let, const详解
function show( flag ){ console.log( a ); if( flag ){ var a = 'ghostwu'; return a; } else { console.l ...