机器学习-KNN分类器
K-近邻(k-Nearest Neighbors,KNN)的原理
通过测量不同特征值之间的距离来衡量相似度的方法进行分类。
KNN算法过程
训练样本集:样本集中每个特征值都已经做好类别标签;
测试样本: 测试样本中每个特征值都没有类别标签;
算法过程: 计算测试样本中特征值与训练样本集中的每个特征值之间的距离,提取与训练样本集中的特征值距离最近的前K个样本,然后选取出现次数最多的类别标签,作为测试样本的类别标签。
度量特征值之间距离的方法
(1) 欧氏距离
可称为L2范数:
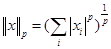
其中p=2,则特征向量a=(a1,a2,…,am)和特征向量b=( b1,b2,…,bm)之间的距离为
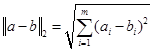
又称欧式距离。
例如二维平面上的两点a(x1, y1)和b(x2, y2)之间的欧式距离:
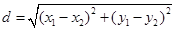
d值越小,表明特征值之间距离越小,两个特征越相似。
(2) 夹角余弦
特征向量a=(a1,a2,…,am)和特征向量b=(
b1,b2,…,bm)之间的夹角余弦为:
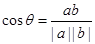
cos值越大,表明特征值之间距离越小,两个特征越相似。
一个简单的例子
Python代码示例:
# coding: utf-8
# 作者:tany 博客:http://www.cnblogs.com/tan-v/
from numpy import *
import operator
import matplotlib.pyplot as plt def createDataSet(): # 生成训练集
group = array([[1.0, 1.1], [0.9, 1.3], [ 0, 0.1], [0.1, 0.2]])
labels = ['A', 'A', 'B', 'B']
return group, labels def showDataSet(dataSet, labels): # 显示训练集
fig = plt.figure()
ax = fig.add_subplot(111)
index = 0
for point in dataSet:
if labels[index] == 'A':
ax.scatter(point[0], point[1], c='blue')
ax.annotate("A", xy = (point[0], point[1]))
else:
ax.scatter(point[0], point[1], c='red')
ax.annotate("B", xy = (point[0], point[1]))
index += 1
plt.show() def eulerDist(inXmat, dataSet): # 使用欧式距离
diffMat = inXmat - dataSet # 输入向量分别与样本中其他的向量之差
sqDiffMat = diffMat**2 # 差值求平方
sqDistances = sqDiffMat.sum(axis=1) # axis=1将一个矩阵的每一行向量相加, 将差值相加
dist = sqDistances**0.5 # 开方
return dist def cosDist(inXmat, dataSet): # 使用夹角余弦
m = shape(inXmat)[0]
dist = zeros((m)) # 与训练集中每一个特征求距离
for i in range(m):
cos = dot(inXmat[i,:], dataSet[i,:])/(linalg.norm(inXmat[i,:])*linalg.norm(dataSet[i,:])) # 求余弦值
dist[i] = cos
return dist def KNNclassify(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0] # 行数
inXmat = tile(inX, (dataSetSize, 1)) # tile(A,reps)若reps为一个元组(m,n),则构造一个m行n列的数组,其中每个元素均为A,
# 目的是求inX分别与其他dataSet的数据间的距离
distance = eulerDist(inXmat, dataSet) # 使用欧式距离度量向量间距离
sortedDistIndicies = distance.argsort() # 对一个数组进行升序排列,结果返回的就是a中所有元素排序后各个元素在a中之前的下标 #distance = cosDist(inXmat, dataSet) # 使用夹角余弦度量向量间距离
#sortedDistIndicies = argsort(-distance) # 降序排列 classcount = {} # 字典 for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classcount[voteIlabel] = classcount.get(voteIlabel,0) + 1 # dict.get(key, default=None) key:字典中要查找的键。
# default -- 如果指定键的值不存在时,返回该默认值。 # classcount.iteritems()返回一个迭代器。返回一个可以调用的对象(可以从操作对象中提取item)
# operator.itemgetter函数获取的不是值,而是定义了一个函数。获取对象的第1个域的值在这里使用字典中的值进行从小到大进行排序
# sorted(iterable, cmp, key, reverse),iterable指定要排序的list或者iterable,
# cmp为函数,指定排序时进行比较的函数,可以指定一个函数或者lambda函数
# key为函数,指定取待排序元素的哪一项进行排序
# reverse默认为false(升序排列),定义为True时将按降序排列。
sortedClassCount = sorted(classcount.iteritems(), key=operator.itemgetter(1), reverse=True) return sortedClassCount[0][0] dataSet, labels = createDataSet(); # 生成训练集
showDataSet(dataSet,labels) # 显示训练集
inX = array([1, 1]) # 输入一个测试样本
classLabel = KNNclassify(inX, dataSet, labels, 3) # 使用KNN进行分类
print classLabel # 输入分类之后所属的标签
执行结果:
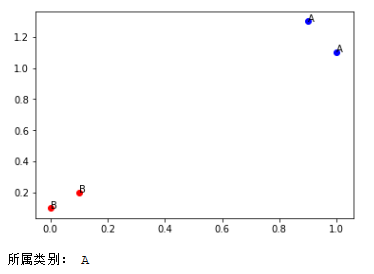
-tany 2017年10月4日 中秋 于杭州
人工智能从入门到专家教程资料:https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.38270209gU11fS&id=562189023765
机器学习-KNN分类器的更多相关文章
- 股票价格涨跌预测—基于KNN分类器
code{white-space: pre;} pre:not([class]) { background-color: white; }if (window.hljs && docu ...
- 【udacity】机器学习-knn最近邻算法
Evernote Export 1.基于实例的学习介绍 不同级别的学习,去除所有的数据点(xi,yi),然后放入一个数据库中,下次直接提取数据 但是这样的实现方法将不能进行泛化,这种方式只能简单的 ...
- 【cs231n作业笔记】一:KNN分类器
安装anaconda,下载assignment作业代码 作业代码数据集等2018版基于python3.6 下载提取码4put 本课程内容参考: cs231n官方笔记地址 贺完结!CS231n官方笔记授 ...
- 机器学习-KNN算法详解与实战
最邻近规则分类(K-Nearest Neighbor)KNN算法 1.综述 1.1 Cover和Hart在1968年提出了最初的邻近算法 1.2 分类(classification)算法 1.3 输入 ...
- [机器学习] ——KNN K-最邻近算法
KNN分类算法,是理论上比较成熟的方法,也是最简单的机器学习算法之一. 该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别 ...
- 机器学习——kNN(2)示例:改进约会网站的配对效果
=================================版权声明================================= 版权声明:原创文章 禁止转载 请通过右侧公告中的“联系邮 ...
- 机器学习——kNN(1)基本原理
=================================版权声明================================= 版权声明:原创文章 禁止转载 请通过右侧公告中的“联系邮 ...
- 机器学习--kNN算法识别手写字母
本文主要是用kNN算法对字母图片进行特征提取,分类识别.内容如下: kNN算法及相关Python模块介绍 对字母图片进行特征提取 kNN算法实现 kNN算法分析 一.kNN算法介绍 K近邻(kNN,k ...
- 机器学习-kNN
基于Peter Harrington所著<Machine Learning in Action> kNN,即k-NearestNeighbor算法,是一种最简单的分类算法,拿这个当机器学习 ...
随机推荐
- [2013-01-15]The Little Schemer 学习笔记
<The Little Schemer> FP编程.lisp入门必备 这书貌似没中文版: 有英文pdf版:完整版下载链接 英文不好的,被前几页噎住的,可以先到这里看翻译好的前言部分 看完人 ...
- spring mvc:exclude-mapping错误提示
今天搭建一个java web项目时,增加了一个登录的拦截器,主要功能就是未登录的用户无法访问系统的任何页面. 先说明下我的web项目springmvc的版本以及刚开始配置的拦截器: springmvc ...
- OpenID Connect:OAuth 2.0协议之上的简单身份层
OpenID Connect是什么?OpenID Connect(目前版本是1.0)是OAuth 2.0协议(可参考本人此篇:OAuth 2.0 / RCF6749 协议解读)之上的简单身份层,用 A ...
- Microsoft Dynamics 365 之 味全食品 项目分享和Customer Engagement新特性分享
味全食品 Dynamics 365项目: 在企业门户和电子商务等新营销模式频出的今天,零售业需要利用统一的管理平台管理日益庞大的客户及销售数据,整合线上线下的零售业务,从采购.仓储.生产.配送到销售. ...
- 对Java的数据类型和运算符的理解
我知道千里之行始于足下,包含着对编程的兴趣,希望能够在这个平台上记录下我学习过程中的点点滴滴! Java的基本构造 标识符和关键字 标识符规则 标识符就是用于给程序中变量,类.方法命名的符号 1.标识 ...
- ES6块级作用域
块级作用域的优点 避免变量冲突,比如程序中加载了多个第三方库的时候,如果没有妥善地将内部私有函数或变量隐藏起来,就很容易引发变量冲突: 可以方便的进行模块管理: 利于内存回收:(块级作用域里声明的变量 ...
- c++ Lambda函数学习
或许,Lambda 表达式算得上是 C++ 11 新增特性中最激动人心的一个.这个全新的特性听起来很深奥,但却是很多其他语言早已提供(比如 C#)或者即将提供(比如 Java)的.简而言之,Lambd ...
- Beta版本冲刺计划及安排(附七天冲刺的博客链接)
Beta版本冲刺计划及安排(附七天冲刺的博客链接) 新增组员 本次换人加入我们团队的新成员是原"爸爸说的都队"的队长念其锋同学,经过我们小组严格的两轮面试,他从几个同样前来面试的同 ...
- 团队作业4——第一次项目冲刺(Alpha版本)第一天 and 第二天
第一天冲刺 一.Daily Scrum Meeting照片 二.每个人的工作 1.今天计划完成的任务 徐璨 申悦:查找关于安卓开发资料,环境搭建 连永刚 林方言:设计项目所要实现的功能,并对功能进行详 ...
- 联想G50-70安装SSD及WIN10教程
借着双11的东风,果断入手SSD120G和4G内存条1枚.经过近一周的安装与试运行,笔者实现了SSD+HDD双硬盘+WIN10系统.目前运行体验非常好,开机时间9秒,软件运行也非常流畅.在折腾的过程中 ...