Python一维数据分析
1.Numpy数组
numpy的数组只能存放同一种数据类型,使用的方式和Python列表类似
1.1 声明:
import numpy as np
countries = np.array([
'Afghanistan', 'Albania', 'Algeria', 'Angola', 'Argentina',
'Armenia', 'Australia', 'Austria', 'Azerbaijan', 'Bahamas',
'Bahrain', 'Bangladesh', 'Barbados', 'Belarus', 'Belgium',
'Belize', 'Benin', 'Bhutan', 'Bolivia',
'Bosnia and Herzegovina'
])
employment = np.array([
55.70000076, 51.40000153, 50.5 , 75.69999695,
58.40000153, 40.09999847, 61.5 , 57.09999847,
60.90000153, 66.59999847, 60.40000153, 68.09999847,
66.90000153, 53.40000153, 48.59999847, 56.79999924,
71.59999847, 58.40000153, 70.40000153, 41.20000076
])
1.2 获取&切片
print countries[0]
print countries[3] print countries[0:3]
print countries[3:]
print countries[17]
print countries[:]
1.3 for循环
for i in range(len(countries)):
country = countries[i]
country_employeement = employment[i]
print 'Country {} has employeement {}'.format(country,country_employeement)
1.4 数据类型
print countries.dtype
print employment.dtype
print np.array([0, 1, 2, 3]).dtype
print np.array([1.0, 1.5, 2.0, 2.5]).dtype
print np.array([True, False, True]).dtype
print np.array(['AL', 'AK', 'AZ', 'AR', 'CA']).dtype
1.5 计算统计值
print employment.mean()
print employment.std()
print employment.max()
print employment.min()
1.6 获取具有最多就业率的国家
def max_employeement(countries,employment):
i = employment.argmax()
return (countries[i],employment[i])
1.7 numpy向量与向量运算
#1.两个numpy向量的数值运算
a=np.array([1,2,3,4])
b=np.array([1,2,1,2]) #依次相加,符合线性代数的向量加法
print a+b
print a-b
print a*b
print a/b
print a**b
1.8 向量与值的运算
#符合线性代数的运算规则
a=np.array([1,2,3,4])
b=2
print a+b
print a-b
print a*b
print a/b
print a**b
1.9 向量的逻辑运算
a=np.array([True,True,False,False])
b=np.array([True,False,True,False]) #每一个值依次比较
print a&b
print a|b
print ~a print a&True
print a&False print a|True
print b|False
1.10 向量之间的比较
a = np.array([1, 2, 3, 4, 5])
b = np.array([5, 4, 3, 2, 1])
#每一个值依次比较
print a > b
print a >= b
print a < b
print a <= b
print a == b
print a != b
1.11 向量和数值比较
a=np.array([1,2,3,4])
b=2
#a向量的每一个值都和b比较,返回True or False
print a > b
print a >= b
print a < b
print a <= b
print a == b
print a != b
1.12 向量之间可以直接进行相加在进行别的运算
female_completion = np.array([
97.35583, 104.62379, 103.02998, 95.14321, 103.69019,
98.49185, 100.88828, 95.43974, 92.11484, 91.54804,
95.98029, 98.22902, 96.12179, 119.28105, 97.84627,
29.07386, 38.41644, 90.70509, 51.7478 , 95.45072
]) # Male school completion rate in 2007 for those 20 countries
male_completion = np.array([
95.47622, 100.66476, 99.7926 , 91.48936, 103.22096,
97.80458, 103.81398, 88.11736, 93.55611, 87.76347,
102.45714, 98.73953, 92.22388, 115.3892 , 98.70502,
37.00692, 45.39401, 91.22084, 62.42028, 90.66958
]) #求和取出两个向量的总体的均值
def overall_completion_rate(female_completion, male_completion):
return (female_completion+male_completion)/2
1.13 获取特定值的标准差
country_name = 'United States'
def standardize_data(values):
#直接将一组数据进行加工,得出一组结果集
standardized_values = (values-values.mean())/values.std()
return standardized_values
1.14 numpy的索引向量
a=np.array([1,2,3,4])
b=np.array([True,True,False,False]) #返回b中为True的索引所对应的值
print a[b]
print a[np.array([True,False,True,False])]
1.15 numpy索引向量可以支持表达式
a=np.array([1,2,3,2,1])
b=(a>=2) print a[b]
#返回boolen向量
print a[a>=2]
1.16 numpy可返回索引向量
a = np.array([1,2,3,4,5])
b = np.array([1,2,3,2,1])
#返回索引向量
print b == 2
print a[b==2]
1.17 计算每周学习时间的平均数
time_spent = np.array([
12.89697233, 0. , 64.55043217, 0. ,
24.2315615 , 39.991625 , 0. , 0. ,
147.20683783, 0. , 0. , 0. ,
45.18261617, 157.60454283, 133.2434615 , 52.85000767,
0. , 54.9204785 , 26.78142417, 0.
]) # Days to cancel for 20 students
days_to_cancel = np.array([
4, 5, 37, 3, 12, 4, 35, 38, 5, 37, 3, 3, 68,
38, 98, 2, 249, 2, 127, 35
]) #计算出每周学习时间的平均数
def mean_time_for_paid_students(time_spent, days_to_cancel):
return time_spent[days_to_cancel>=7].mean()
2.Pandas数组
pandas数组是在numpy的数组上做了一次封装,可以支持更多的统计分析功能,而且也具有和Python字典类似的功能,key的值可以是任意类型
2.1 pandas数组常用功能
import pandas as pd
life_expectancy_values = [74.7, 75. , 83.4, 57.6, 74.6, 75.4, 72.3, 81.5, 80.2,
70.3, 72.1, 76.4, 68.1, 75.2, 69.8, 79.4, 70.8, 62.7,
67.3, 70.6] gdp_values = [ 1681.61390973, 2155.48523109, 21495.80508273, 562.98768478,
13495.1274663 , 9388.68852258, 1424.19056199, 24765.54890176,
27036.48733192, 1945.63754911, 21721.61840978, 13373.21993972,
483.97086804, 9783.98417323, 2253.46411147, 25034.66692293,
3680.91642923, 366.04496652, 1175.92638695, 1132.21387981] #转换成pandas数组
life_expectancy = pd.Series(life_expectancy_values)
gdp = pd.Series(gdp_values) #切片
print life_expectancy[0]
print gdp[3:6] #循环
for country_life_expectancy in life_expectancy:
print 'Examining life expectancy {} '.format(country_life_expectancy) #统计函数
print life_expectancy.mean()
print life_expectancy.std()
print gdp.max()
print gdp.sum()
2.2 pandas数组向量运算
a = pd.Series([1, 2, 3, 4])
b = pd.Series([1, 2, 1, 2]) print a+b
print a*2
print a>=3
print a[a>=3]
2.3 获取寿命和gdp的关系
#获取gdp和寿命的关系
def variable_correlation(variable1, variable2):
#获取所有超过平均值和小于平均值的v1和v2
both_above = (variable1>variable1.mean()) & (variable2>variable2.mean())
both_below = (variable1<variable1.mean()) & (variable2<variable2.mean())
#获取处于同向的数据
is_same_direction = both_above|both_below
#统计出True的值
num_same_direction = is_same_direction.sum()
num_different_direction = len(variable1)-num_same_direction
return (num_same_direction,num_different_direction)
说明:大部分数据的方向相同,说明两个变量是正相关的(一个值较大,另一个值也大)
如果第一个数字较小,第二个数字较大,说明变量是负相关的
如果两个变量的值相等说明.这两个变量无关
2.4 pandas数组索引访问
countries = [
'Afghanistan', 'Albania', 'Algeria', 'Angola',
'Argentina', 'Armenia', 'Australia', 'Austria',
'Azerbaijan', 'Bahamas', 'Bahrain', 'Bangladesh',
'Barbados', 'Belarus', 'Belgium', 'Belize',
'Benin', 'Bhutan', 'Bolivia', 'Bosnia and Herzegovina',
] employment_values = [
55.70000076, 51.40000153, 50.5 , 75.69999695,
58.40000153, 40.09999847, 61.5 , 57.09999847,
60.90000153, 66.59999847, 60.40000153, 68.09999847,
66.90000153, 53.40000153, 48.59999847, 56.79999924,
71.59999847, 58.40000153, 70.40000153, 41.20000076,
] #转换成pandas数组,值为employment,索引是countries
employment = pd.Series(employment_values,index=countries) #找出工资最高的国家
def max_employment(employment):
#获取empolyment中最大的索引,然后根据索引取值
max_country = employment.argmax()
max_value = employment.loc[max_country]
return (max_country,max_value)
2.5 去除NaN值
#会根据关键字来赋值而不是位置来赋值,和python的关键字参数同理
s1=pd.Series([1,2,3,4],index=['a','b','c','d'])
s2=pd.Series([10,20,30,40],index=['a','b','c','d'])
print s1+s2 s1=pd.Series([1,2,3,4],index=['a','b','c','d'])
s2=pd.Series([10,20,30,40],index=['b','d','a','c'])
print s1+s2
#此时由于关键字参数缺失,会出现NaN值的情况
s1=pd.Series([1,2,3,4],index=['a','b','c','d'])
s2=pd.Series([10,20,30,40],index=['c','d','e','f'])
print s1+s2 s1=pd.Series([1,2,3,4],index=['a','b','c','d'])
s2=pd.Series([10,20,30,40],index=['e','f','g','h'])
print s1+s2 #直接填充默认值来处理NaN值,这样NaN值会显示原来的值
s1.add(s2,fill_value=0)
2.6 自定义方法,可以执行pandas中没有的逻辑
#自定义方法apply
names = pd.Series([
'Andre Agassi',
'Barry Bonds',
'Christopher Columbus',
'Daniel Defoe',
'Emilio Estevez',
'Fred Flintstone',
'Greta Garbo',
'Humbert Humbert',
'Ivan Ilych',
'James Joyce',
'Keira Knightley',
'Lois Lane',
'Mike Myers',
'Nick Nolte',
'Ozzy Osbourne',
'Pablo Picasso',
'Quirinus Quirrell',
'Rachael Ray',
'Susan Sarandon',
'Tina Turner',
'Ugueth Urbina',
'Vince Vaughn',
'Woodrow Wilson',
'Yoji Yamada',
'Zinedine Zidane'
])
#将姓名翻转
def reverse_name(name):
split_name = name.split(' ')
first_name = split_name[0]
last_name = split_name[1]
return last_name + ', ' +first_name #直接通过apply即可调用
def reverse_names(names):
return names.apply(reverse_name)
2.7 使用pandas画图
%pylab inline
#读取csv文件
employment = pd.read_csv('employment-above-15.csv',index_col='Country')
#根据index获取value
employment_us = employment.loc['United States']
#画散点图
employment_us.plot()
3 注意事项:
在numpy数组中,要注意+=,和+的区别
3.1 +=
+=是在原有的数组上进行修改,因为a,b共享一块内存,所以a修改会导致b也修改
import numpy as np
a = np.array([1,2,3,4])
b = a
a+=np.array([1,1,1,1])
print b #因为a,b用的是同一块内存,当a的值改变b的值就会改变
#2,3,4,5

3.2 +
+表示a数组重新开辟了一块内存空间存放新的数组,本质上a,b是占用两个不同的内存空间
import numpy as np
a = np.array([1,2,3,4])
b=a
a = a + np.array([1,1,1,1])
print b #此时a,b用的是两块独立的内存空间,所以b的值还是1,2,3,4

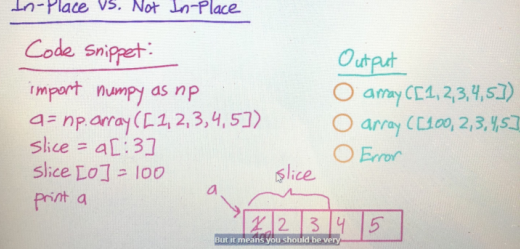
3.3 切片
切片出来的子集是原先数组的视图,与原数组共享一块内存空间,所以会连带修改
import numpy as np
a = np.array([1,2,3,4,5])
slice = a[:3]
slice[0] = 100
print slice #因为切片出来的数据还是原先数据的镜像,所以一旦修改原数据也会修改
#100,2,3
Python一维数据分析的更多相关文章
- 利用Python进行数据分析(5) NumPy基础: ndarray索引和切片
概念理解 索引即通过一个无符号整数值获取数组里的值. 切片即对数组里某个片段的描述. 一维数组 一维数组的索引 一维数组的索引和Python列表的功能类似: 一维数组的切片 一维数组的切片语法格式为a ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- 利用python进行数据分析之绘图和可视化
matplotlib API入门 使用matplotlib的办法最常用的方式是pylab的ipython,pylab模式还会向ipython引入一大堆模块和函数提供一种更接近与matlab的界面,ma ...
- 利用Python进行数据分析——Numpy基础:数组和矢量计算
利用Python进行数据分析--Numpy基础:数组和矢量计算 ndarry,一个具有矢量运算和复杂广播能力快速节省空间的多维数组 对整组数据进行快速运算的标准数学函数,无需for-loop 用于读写 ...
- 利用Python进行数据分析
最近在阅读<利用Python进行数据分析>,本篇博文作为读书笔记 ,记录一下阅读书签和实践心得. 准备工作 python环境配置好了,可以参见我之前的博文<基于Python的数据分析 ...
- 利用python进行数据分析——(一)库的学习
总结一下自己对python常用包:Numpy,Pandas,Matplotlib,Scipy,Scikit-learn 一. Numpy: 标准安装的Python中用列表(list)保存一组值,可以用 ...
- 利用python进行数据分析之pandas入门
转自https://zhuanlan.zhihu.com/p/26100976 目录: 5.1 pandas 的数据结构介绍5.1.1 Series5.1.2 DataFrame5.1.3索引对象5. ...
- 利用python进行数据分析--(阅读笔记一)
以此记录阅读和学习<利用Python进行数据分析>这本书中的觉得重要的点! 第一章:准备工作 1.一组新闻文章可以被处理为一张词频表,这张词频表可以用于情感分析. 2.大多数软件是由两部分 ...
- 《利用Python进行数据分析·第2版》第四章 Numpy基础:数组和矢量计算
<利用Python进行数据分析·第2版>第四章 Numpy基础:数组和矢量计算 numpy高效处理大数组的数据原因: numpy是在一个连续的内存块中存储数据,独立于其他python内置对 ...
随机推荐
- FileDetector-基于java开发的照片整理工具
1. 项目背景 开发这个功能的主要原因如下: 1. 大学期间拍摄了约50G的照片,照片很多 2. 存放不规范,导致同一张照片出现在不同的文件夹内,可读性差,无法形成记忆线. 3. 重复存放过多,很多照 ...
- JavaScript--我发现,原来你是这样的JS(基础概念--躯壳,不妨从中文角度看js)
介绍 这是红宝书(JavaScript高级程序设计 3版)的读书笔记第二篇(基础概念--躯壳篇),有着部分第三章的知识内容,当然其中还有我个人的理解.红宝书这本书可以说是难啃的,要看完不容易,挺厚的, ...
- memcached常用命令
详见:http://blog.yemou.net/article/query/info/tytfjhfascvhzxcyt104 一.Memcache面向对象的常用接口包括:Memcache::con ...
- 开始学习.net的第二天
今天由于原因上午没上课.下午去了学的.net的表格. <body></body><img src="../temp/新建文件夹/64aab4ae3e632dbc ...
- 网络编程:基于C语言的简易代理服务器实现(proxylab)
本文记录了一个基于c socket的简易代理服务器的实现.(CS:APP lab 10 proxy lab) 本代理服务器支持keep-alive连接,将访问记录保存在log文件. Github: h ...
- JavaScript 中运算优先级问题
优先级引发的问题 这篇文章对 JavaScript 中的运算符进行小结,很多人对运算符优先级这一知识点都是一带而过.这就导致在写一些比较奇葩的 js 代码,你并不知道它的输出是啥,下面举一个例子,这也 ...
- 【2017集美大学1412软工实践_助教博客】团队作业8——第二次项目冲刺(Beta阶段)
题目 团队作业8: http://www.cnblogs.com/happyzm/p/6856179.html 团队作业8-1 beta冲刺计划 团队 新加入的成员,担当的角色,技术特点 下一阶段需要 ...
- [2017BUAA软工助教]评论汇总
一 邹欣 周筠 飞龙 二 学校 课程 教师 助教1 助教2 助教3 福州 软件工程1715K 柯逍 谢涛 软件工程1715Z 张栋 刘乾 汪培侨 软件工程1715W 汪璟玢 曾逸群 卞倩虹 李娟 集美 ...
- 201521123034《Java程序设计》第六周学习总结
1. 本周学习总结 1.1 面向对象学习暂告一段落,请使用思维导图,以封装.继承.多态为核心概念画一张思维导图,对面向对象思想进行一个总结. 注1:关键词与内容不求多,但概念之间的联系要清晰,内容覆盖 ...
- 201521123034 《Java程序设计》第五周学习总结
1. 本周学习总结 1.1 尝试使用思维导图总结有关多态与接口的知识点. 2. 书面作业 作业参考文件下载 代码阅读:Child压缩包内源代码 1.1 com.parent包中Child.java文件 ...