[数据分析工具] Pandas 功能介绍(一)
- 如果你在使用 Pandas(Python Data Analysis Library) 的话,下面介绍的对你一定会有帮助的。
- DataFrame:行列数据,类似 Excel 的 sheet,或关系型数据库的表
- series:单列数据
- axis:0:行,1:列
- shape:DataFrame的行列数,(行数,列数)
1. 加载 CSV
- 直接加载
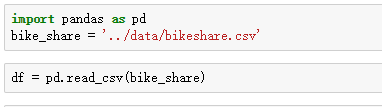
- 无参数加载
- 无参数加载

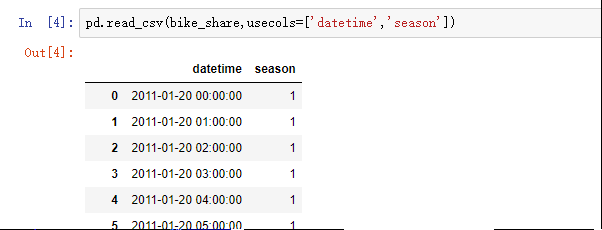
- 选择特定列加载

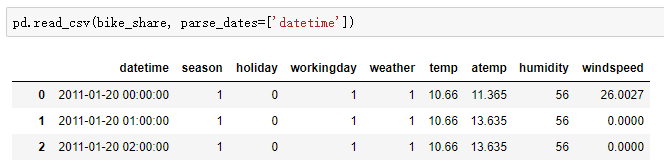
- 时间转换加载

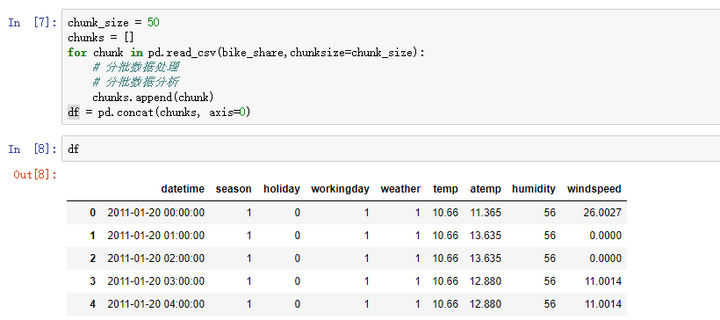
- 分批加载

2. 浏览 DataFrame 数据
- df.head(n):浏览数据的前 n 行,默认 5 行
- df.tail(n):浏览数据的末尾 n 行,默认 5 行
- df.sample(n):随机浏览 n 行数据,默认 5 行
- df.shape:tuple 类型的数据行列数,(行数,列数)
- df.describe():计算评估数据的趋势
- df.info():内存和数据类型
3. 在 DataFrame 中增加列
- 简单方式
df['new_column'] = 1
- 计算方式
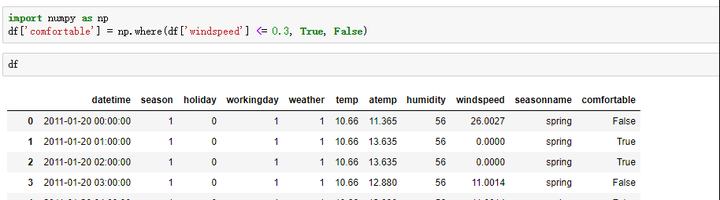
- 条件方式

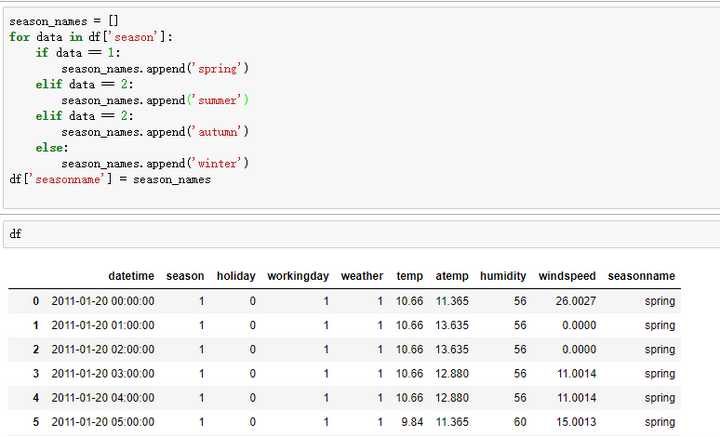
- 循环方式

4. 选择指定单元格
- loc 根据标签选取loc
- iloc 根据索引选取
- 选取行数据
- df.loc[[行索引数组]],df.iloc[[行索引数组]]

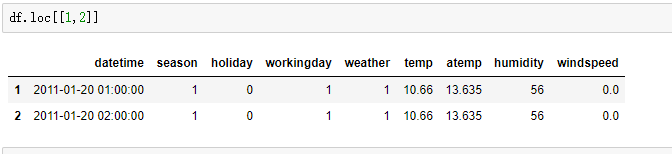
- 索引开始位置:闭区间
- 索引结束位置:开区间
- loc 和 iloc 选取整列数据的时候,看上去与 df[列名数组] 的方式一致,但是其实前者返回的仍然是 DataFrame,后者返回的是 Series


[数据分析工具] Pandas 功能介绍(一)的更多相关文章
- [数据分析工具] Pandas 功能介绍(二)
条件过滤 我们需要看第一季度的数据是怎样的,就需要使用条件过滤 体感的舒适适湿度是40-70,我们试着过滤出体感舒适湿度的数据 最后整合上面两种条件,在一季度体感湿度比较舒适的数据 列排序 数据按照某 ...
- pt-query-digest工具的功能介绍了:
Ok,可以查看 pt-query-digest工具的功能介绍了: [root@472322 percona-toolkit-2.2.5]# pt-query-digest --help pt-quer ...
- 数据分析工具Pandas
参考学习资料:http://pandas.pydata.org 1.什么是Pandas? Pandas的名称来自于面板数据(panel data)和Python数据分析(data analys ...
- 数据分析工具pandas简介
什么是Pandas? Pandas的名称来自于面板数据(panel data)和Python数据分析(data analysis). Pandas是一个强大的分析结构化数据的工具集,基于NumPy构建 ...
- python数据分析工具 | pandas
pandas是python下强大的数据分析和探索工具,是的python在处理数据时非常快速.简单.它是构建在numpy之上的,包含丰富的数据处理函数,支持时间序列分析功能,支持灵活处理缺失数据. pa ...
- python数据分析工具——Pandas、StatsModels、Scikit-Learn
Pandas Pandas是 Python下最强大的数据分析和探索工具.它包含高级的数据结构和精巧的工具,使得在 Python中处理数据非常快速和简单. Pandas构建在 Numpy之上,它使得以 ...
- 浏览器开发者工具----F12 功能介绍
笔者技巧: 看了些其它回答,有些是用来扒图片的,有些是写爬虫的(这个不要看Elements,因为浏览器会对一些不符合规范的标签做补全或者其它处理,最好是Ctrl+U). 图片的话就不要看Network ...
- 用python做数据分析4|pandas库介绍之DataFrame基本操作
原文地址 怎样删除list中空字符? 最简单的方法:new_list = [ x for x in li if x != '' ] 今天是5.1号. 这一部分主要学习pandas中基于前面两种数据结构 ...
- 机器学习(4):数据分析的工具-pandas的使用
前面几节说一些沉闷的概念,你若看了估计已经心生厌倦,我也是.所以,找到了一个理由来说一个有兴趣的话题,就是数据分析.是什么理由呢?就是,机器学习的处理过程中,数据分析是经常出现的操作.就算机器对大量样 ...
随机推荐
- Linux第五节随笔 /file / vim / suid /sgid sbit
三期第四讲1.查询文件类型与文件位置命令 file 作用:查看文件类型(linux下的文件类型不以后缀名区分) 语法举例: [root@web01 ~]# file passwd passwd: AS ...
- mkdir 命令详解
rmdir <man.linuxde.net> 作用: rmdir 命令用来创建目录,该命令创建由dirname 命名的目录.如果在目录名的前面没有添加任何路径名,则在当前目录下创建由d ...
- 我的第一个python web开发框架(19)——产品发布相关事项
好不容易小白将系统开发完成,对于发布到服务器端并没有什么经验,于是在下班后又找到老菜. 小白:老大,不好意思又要麻烦你了,项目已经弄完,但要发布上线我还一头雾水,有空帮我讲解一下吗? 老菜:嗯,系统上 ...
- touch事件应用
js的touch事件,一般用于移动端的触屏滑动: $(function(){ document.addEventListener("touchmove", _touch, fals ...
- jquery通过ajax查询数据动态添加到select
function addSelectData() { //select的id为selectId //清空select中的数据 $("#selectId").empty(); $.a ...
- 在IIS使用localDB
项目使用localdb来作为本机测试数据库,发布到本机IIS后项目却链接不到数据库,查看windows日志为如下错误 "无法获取本地应用程序数据路径.很可能是因为未加载用户配置文件.如果在 ...
- SCOI 2010 序列操作
题目描述 lxhgww最近收到了一个01序列,序列里面包含了n个数,这些数要么是0,要么是1,现在对于这个序列有五种变换操作和询问操作: 0 a b 把[a, b]区间内的所有数全变成0 1 a b ...
- chrome调试工具高级不完整使用指南(基础篇)
一.前言 本文记录的是作者在工作上面对chrome的一些使用和情况的分析分享,内容仅代表个人的观点.转发请注明出处(http://www.cnblogs.com/st-leslie/),谢谢合作 二. ...
- LNMP架构之搭建wordpress博客网站
系统环境版本 [root@db02 ~]# cat /etc/redhat-release CentOS release 6.9 (Final) [root@db02 ~]# uname -a Lin ...
- Xposed hook布局类资源文件的获取
如题,可以hook状态栏,为系统状态栏添加一个TextView @Override public void handleInitPackageResources(XC_InitPackageResou ...