HDU4920-Matrix multiplication-矩阵乘法 51nod-1137 矩阵乘法
Matrix multiplication
Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others)
Total Submission(s): 5236 Accepted Submission(s): 2009
bobo hates big integers. So you are only asked to find the result modulo 3.
The first line contains n (1≤n≤800). Each of the following n lines contain n integers -- the description of the matrix A. The j-th integer in the i-th line equals Aij. The next n lines describe the matrix B in similar format (0≤Aij,Bij≤109).
Print n lines. Each of them contain n integers -- the matrix A×B in similar format.
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cstdlib>
#include<string.h>
#include<set>
#include<vector>
#include<queue>
#include<stack>
#include<map>
#include<cmath>
using namespace std; int a[][],b[][],c[][]; int main(){
int n;
while(~scanf("%d",&n)){
for(int i=;i<n;i++)
for(int j=;j<n;j++){
scanf("%d",&a[i][j]);
a[i][j]%=;
c[i][j]=;
}
for(int i=;i<n;i++)
for(int j=;j<n;j++){
scanf("%d",&b[i][j]);
b[i][j]%=;
}
for(int i=;i<n;i++)
for(int j=;j<n;j++){
if(!a[i][j])continue;//判断优化
for(int k=;k<n;k++)
c[i][k]=c[i][k]+a[i][j]*b[j][k];
}
for(int i=;i<n;i++){
for(int j=;j<n;j++)
if(j==n-)printf("%d\n",c[i][j]%);
else printf("%d ",c[i][j]%);
}
}
return ;
}
看其他题解
这个题有两种解法,一种是先对矩阵进行%3,
然后在3次方循环里判断如果元素如果是0,则continue不进行乘积的累加的结果。能起到优化的作用。
还有一种就是对矩阵进行某一个进行转置后,再进行两个矩阵的乘积累加。也能起到优化。
代码:
#include<iostream>
#include<cstring>
#include<cmath>
#include<cstdio>
#include<algorithm>
using namespace std;
int a[][],b[][],c[][]; int main(){
int n;
while(~scanf("%d",&n)){
for(int i=;i<n;i++)
for(int j=;j<n;j++){
scanf("%d",&a[i][j]);
a[i][j]%=;
c[i][j]=;
}
for(int i=;i<n;i++)
for(int j=;j<n;j++){
scanf("%d",&b[i][j]);
b[i][j]%=;
}
for(int i=;i<n;i++)
for(int j=;j<n;j++)
swap(b[i][j],b[j][i]);//转置优化
for(int i=;i<n;i++)
for(int j=;j<n;j++){
//if(!a[i][j])continue;
for(int k=;k<n;k++)
c[i][k]=c[i][k]+a[i][j]*b[j][k];
}
for(int i=;i<n;i++){
for(int j=;j<n;j++)
if(j==n-)printf("%d\n",c[i][j]%);
else printf("%d ",c[i][j]%);
}
}
return ;
}
用转置的话,也可以继续用3次方循环里判断元素是否为0,continue来优化。
直接判断的优化,时间跑1279MS,用转置不用判断是1653MS,用转置也用判断是1482MS,emnnnn。。。
for(int i=;i<n;i++)
for(int j=;j<n;j++){
for(int k=;k<n;k++)
c[i][k]=c[i][k]+a[i][j]*b[j][k];
}
如果是按这种循环写,不管有没有在3次方循环里判断元素是否为0,或者不管有没有转置,都不会超时!!!
然后就是还发现了一个问题,如果三层循环里面写的是c[i][j]的循环会超时的。
for(int i=;i<n;i++)
for(int j=;j<n;j++){
for(int k=;k<n;k++)
c[i][j]=c[i][j]+a[i][k]*b[k][j];
}
这个题简直有毒啊。
不管是直接判断优化还是转置优化,还是转置+判断优化,都是超时。
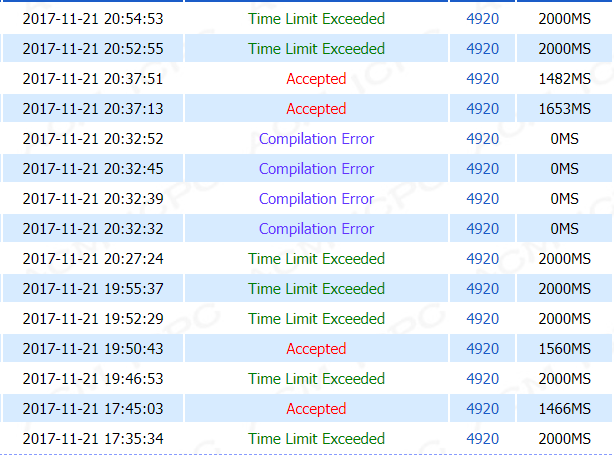
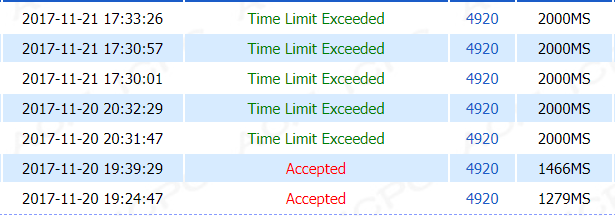
在经过这么多次智障操作之后(之后又交了一发,一共23次),并且在记录了循环的次数之后!!!
我发现。。。
int num=;
for(int i=;i<n;i++)
for(int j=;j<n;j++){
//if(!a[i][j])continue;
for(int k=;k<n;k++){
c[i][k]=c[i][k]+a[i][j]*b[j][k];
num++;
}
}
在都不经过优化的情况下,num的次数都是一样的,两个循环的次数都是一样的。
为什么一个可以过,一个就超时呢???(所有的都测过了_(:з」∠)_ )
未解之谜啊啊啊啊啊啊啊啊啊啊啊啊啊啊_(:з」∠)_
玩不了玩不了。。。
由于C与C++的二维数组是以行为主序存储的。
因此矩阵a的行数据元素是连续存储的,而矩阵b的列数据元素是不连续存储的(N*1的矩阵除外),
为了在矩阵相乘时对矩阵b也连续读取数据,根据局部性原理对矩阵b进行转置。
然而并没有什么用,在不转置的情况下,c[i][k]的是两个按行的,c[i][j]是一个按行的。c[i][k]比c[i][j]快我可以理解。但是!!!
转置之后,c[i][k]是两个按列的,c[i][j]是一个按行的,按道理应该是c[i][j]的快啊,但是为什么还是c[i][k]]快啊。
啊啊啊啊啊啊啊,玩不了玩不了。
HDU4920-Matrix multiplication-矩阵乘法 51nod-1137 矩阵乘法的更多相关文章
- hdu4920 Matrix multiplication 模3矩阵乘法
hdu4920 Matrix multiplication Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 131072/131072 ...
- 51nod 1137.矩阵乘法-矩阵乘法
1137 矩阵乘法 基准时间限制:1 秒 空间限制:131072 KB 分值: 0 难度:基础题 给出2个N * N的矩阵M1和M2,输出2个矩阵相乘后的结果. Input 第1行:1个数N, ...
- 51nod 1137 矩阵乘法【矩阵】
1137 矩阵乘法 基准时间限制:1 秒 空间限制:131072 KB 分值: 0 难度:基础题 收藏 关注 给出2个N * N的矩阵M1和M2,输出2个矩阵相乘后的结果. Input 第1行 ...
- HDU-4920 Matrix multiplication
矩阵相乘,采用一行的去访问,比采用一列访问时间更短,根据数组是一行去储存的.神奇小代码. Matrix multiplication Time Limit: 4000/2000 MS (Java/Ot ...
- 51nod 1137 矩阵乘法
基本的矩阵乘法 中间for(int j=0;i<n;i++) //这里写错了 应该是j<n 晚上果然 效率不行 等会早点儿睡 //矩阵乘法 就是 两个矩阵 第一个矩阵的列 等与 第 ...
- HDU4920 Matrix multiplication 矩阵
不要问窝 为什么过了> < 窝也不造为什么就过了 说是%3变成稀疏矩阵 可是随便YY个案例都会超时.. . 看来数据是随机的诶 #include <stdio.h> #incl ...
- 【bitset】hdu4920 Matrix multiplication
先把两个矩阵全都mod3. S[i][j][k]表示第i(0/1)个矩阵的行/列的第k位是不是j(1/2). 然后如果某两个矩乘对应位上为1.1,乘出来是1: 1.2:2: 2.1:2: 2.2:1. ...
- 矩阵乘法 --- hdu 4920 : Matrix multiplication
Matrix multiplication Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/ ...
- hdu 4920 Matrix multiplication(矩阵乘法)2014多培训学校5现场
Matrix multiplication Time ...
- 数学(矩阵乘法,随机化算法):POJ 3318 Matrix Multiplication
Matrix Multiplication Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 17783 Accepted: ...
随机推荐
- JDBC 程序实例小练习
JDBC 程序实例问题 编程实现如下功能:在数据库中建立一个表,表名为student,其结构为学号.姓名.性别.年龄.英语.JavaSE程序设计.初级日语.总分,在表中输入多条记录. 学生的总分信息, ...
- xamarin android alertdialog详解
说明一下:学习xamarin android一段时间,准备写一些xamarin android相关的例子,alertdialog也是使用的非常多得空间之一,非常感谢鸟巢上的小猪,我也是看着他写的教程学 ...
- ValueError: too many values to unpack (expected 2)
记录下总是码错的地方 for key,value in final_table:#final_table is a dict 然后报错 File "./count_co_Mty_read_n ...
- Adb+.net 实现微信跳一跳自动化
第一次用adb,一开始只是想试试看能不能解析出,没有看网上的现有解析方式. 需要安卓机开启usb 调试+电脑运行.打开跳一跳的界面 点击程序 [开始]按钮即可开始,别的按钮都是调试用的 主要流程是用a ...
- ABP架构学习系列二:ABP中配置的注册和初始化
一.手工搭建平台 1.创建项目 创建MVC5项目,手动引入Abp.Abp.Web.Abp.Web.Mvc.Abp.Web.Api 使用nuget添加Newtonsoft.Json.Castle.Cor ...
- Micro Templating源码分析
关于模板,写页面的人们其实一直在用,asp.net , jsp , php, nodejs等等都有他的存在,当然那是服务端的模板. 前端模板,作为前端人员肯定是多少有接触的,Handlebars.js ...
- css实现椭圆、半椭圆
一.自适应的椭圆 1. 椭圆 css .ellipse{ width: 250px; height: 150px; margin: 50px; background: #FFD900; border- ...
- Android WebView存在跨域访问漏洞(CNVD-2017-36682)介绍及解决
Android WebView存在跨域访问漏洞(CNVD-2017-36682).攻击者利用该漏洞,可远程获取用户隐私数据(包括手机应用数据.照片.文档等敏感信息),还可窃取用户登录凭证,在受害者毫无 ...
- Linux 配置163yum源epel 源
今天一个小伙伴询问博主,想换个163源(阿里源.亚马逊应该都是一样,博主没有一一验证)怎么换!博主当然兴致勃勃的准备好了指点小伙伴...但是,你没猜错,打脸了.而且最后还是和小伙伴一起配置好的,所以就 ...
- mp3格式转wav格式 附完整C++算法实现代码
近期偶然间看到一个开源项目minimp3 Minimalistic MP3 decoder single header library 项目地址: https://github.com/lieff/m ...