Scala IDE for Eclipse的下载、安装和WordCount的初步使用(本地模式和集群模式)
包括:
Scala IDE for Eclipse的下载
Scala IDE for Eclipse的安装
本地模式或集群模式
我们知道,对于开发而言,IDE是有很多个选择的版本。如我们大部分人经常用的是如下。

而我们知道,对于spark的scala开发啊,有为其专门设计的eclipse,Scala IDE for Eclipse

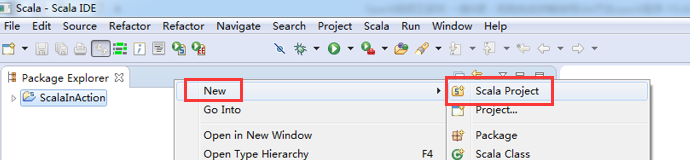
1、Scala IDE for Eclipse的下载


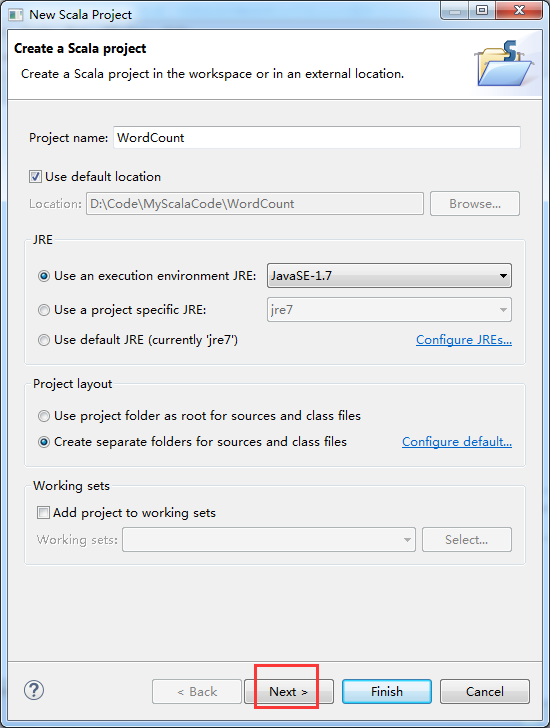
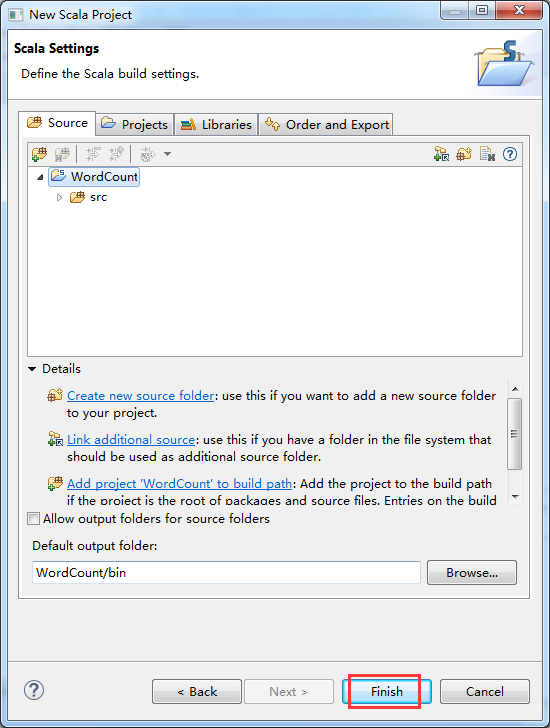
2、Scala IDE for Eclipse的安装
进行解压
3、Scala IDE for Eclipse的WordCount的初步使用
在这之前,先在本地里安装好java和scala
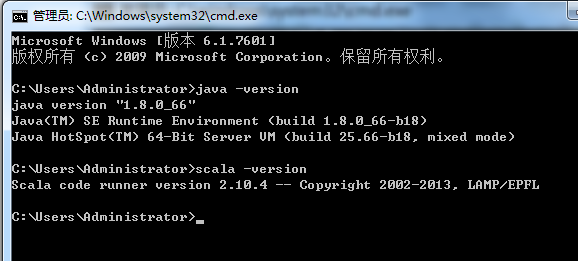

默认竟然变成了scala 2.11.8去了
这一定要换!
Scala2.11.8(默认的版本) --------> scala2.10.4(我们的版本)
第一步:修改依赖的scala版本,从scala2.11.*,至scala2.10.*。

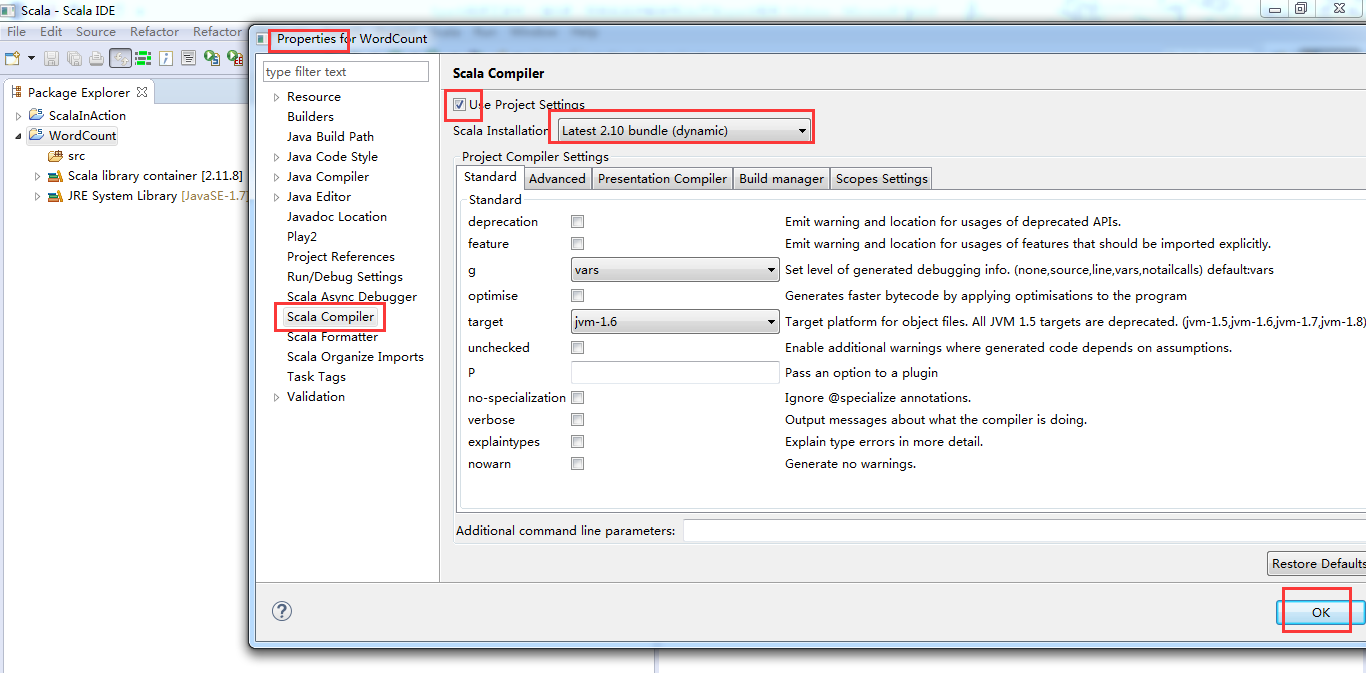

这里是兼容版本,没问题。Scala2.10.6和我们的scala2.10.4没关系!!!
第二步:加入spark的jar文件依赖
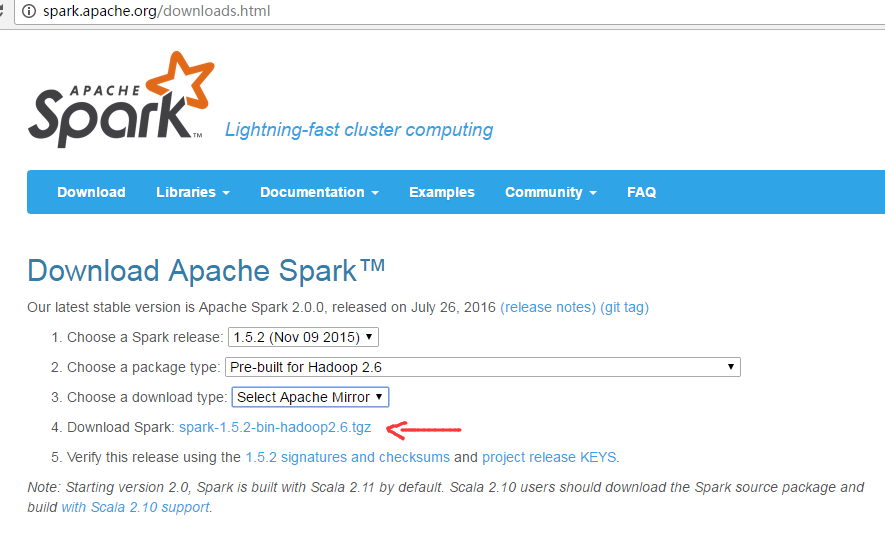
http://spark.apache.org/downloads.html
我这里,以spark-1.5.2-bin-hadoop2.6.tgz为例,其他版本都是类似的,很简单!
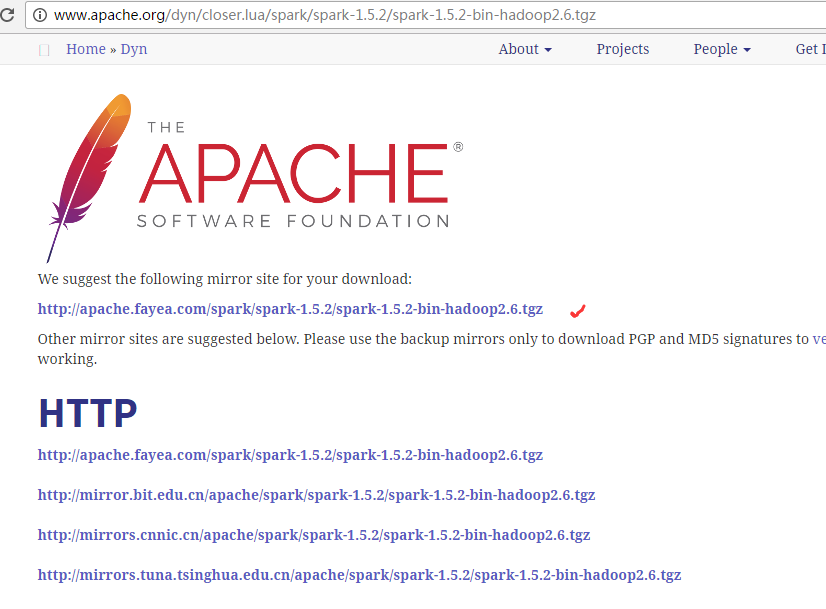
http://www.apache.org/dyn/closer.lua/spark/spark-1.5.2/spark-1.5.2-bin-hadoop2.6.tgz


第三步:找到spark依赖的jar文件,并导入到Scala IDE for Eclipse的jar依赖中

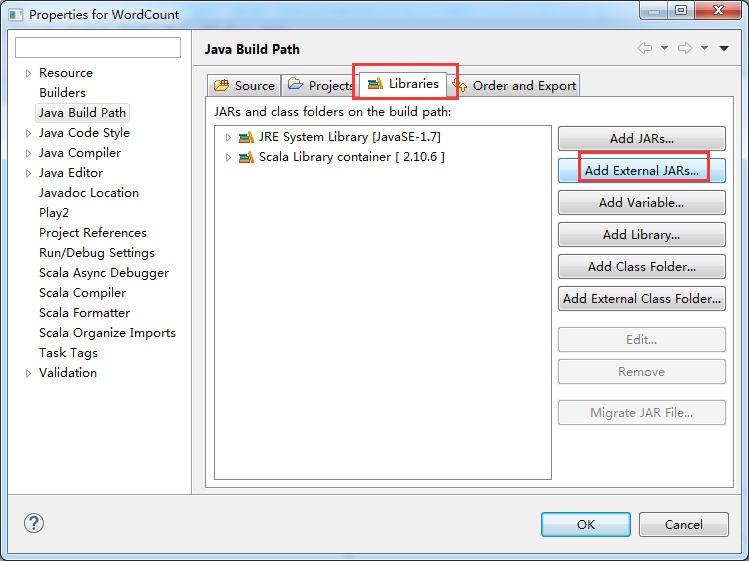
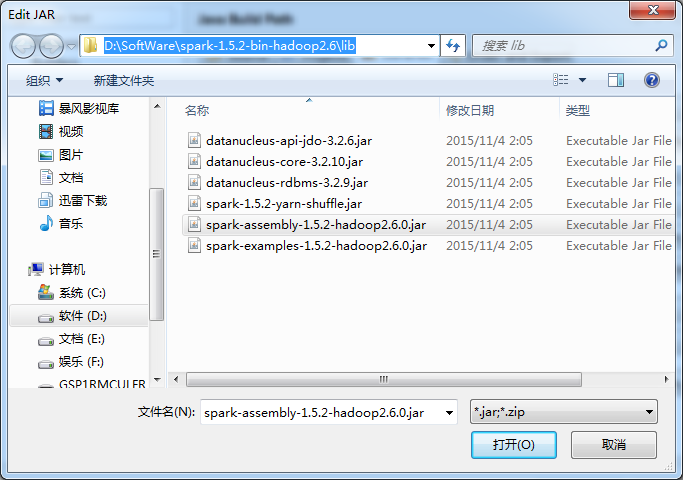
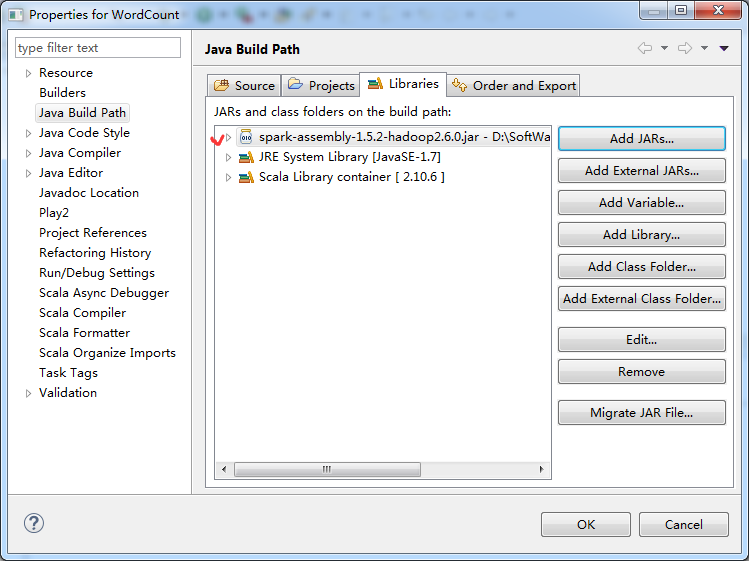
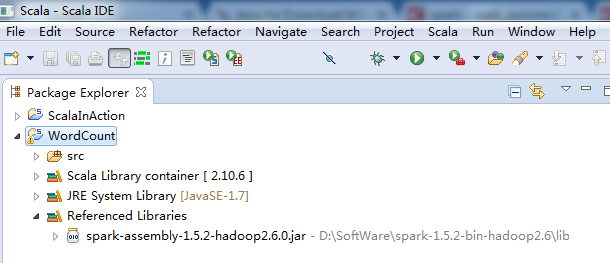
添加Spark的jar依赖spark-1.5.2-bin-hadoop2.6.tgz里的lib目录下的spark-assembly-1.5.2-hadoop2.6.0.jar
第四步:在src下,建立spark工程包

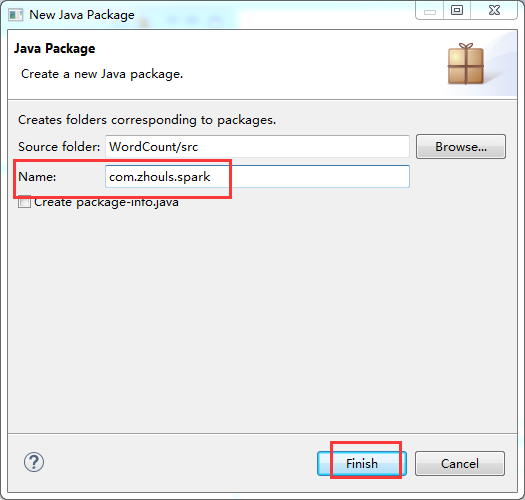

第五步:创建scala入口类
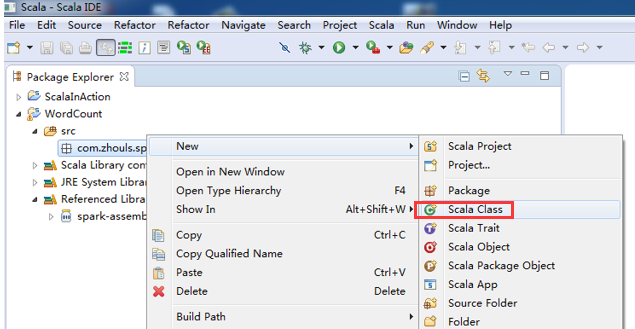
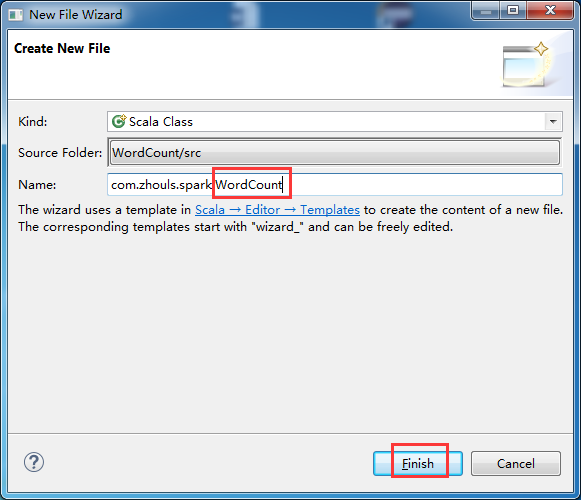
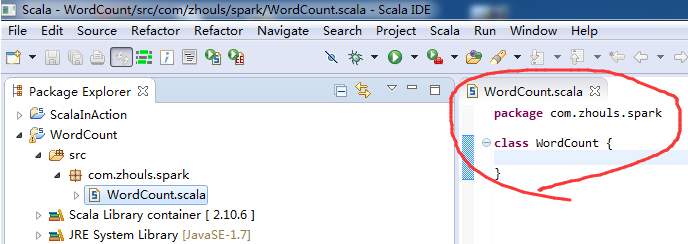
定义main方法
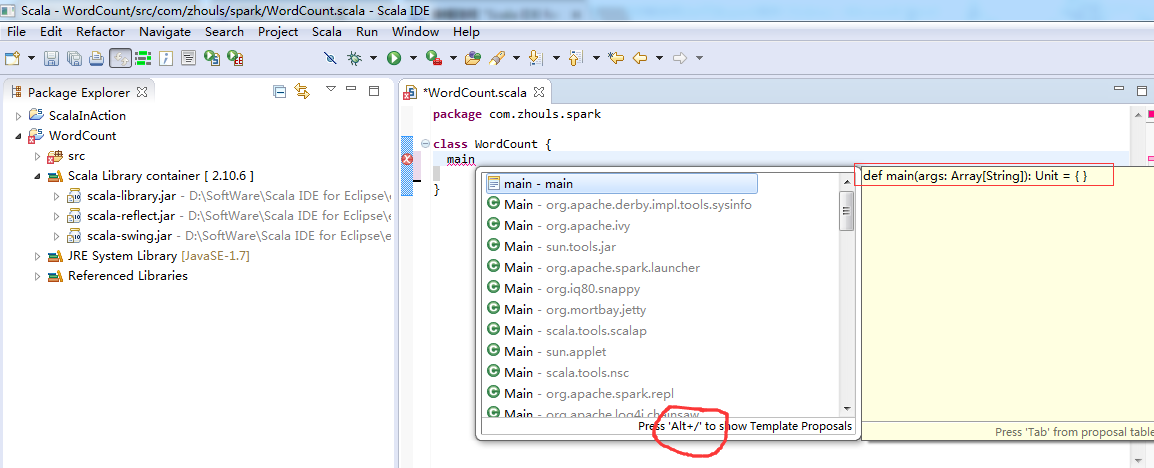

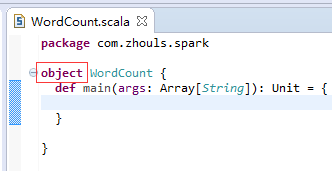
第六步:把class变成object,并编写main入口方法。
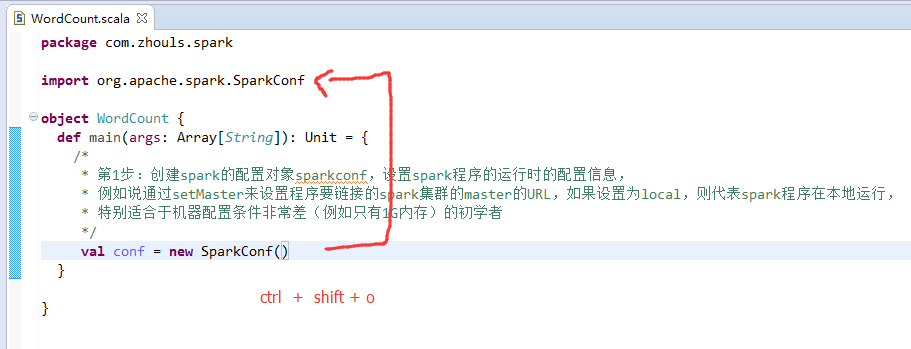
本地模式
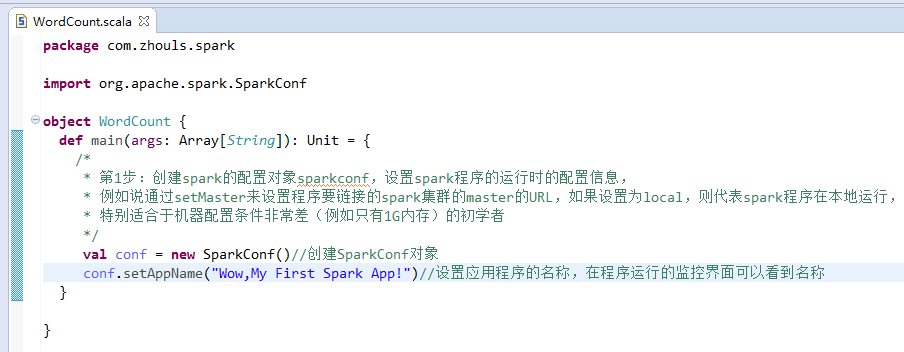
第1步


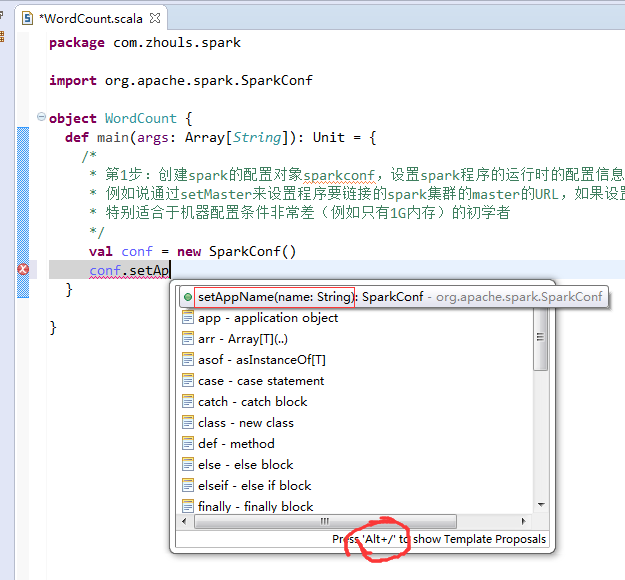



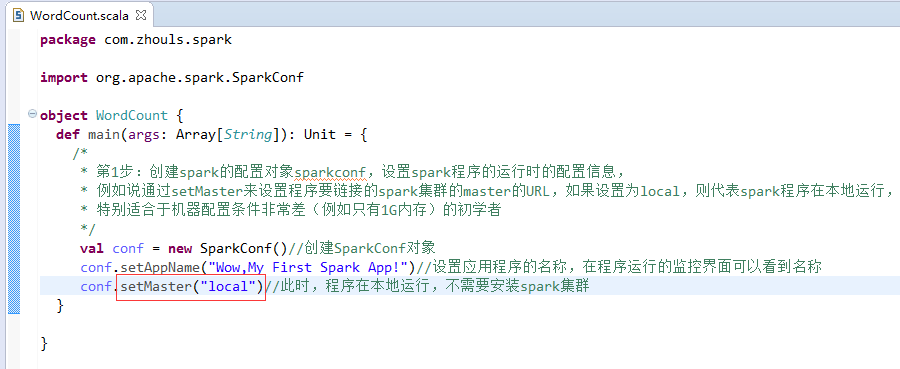
第2步

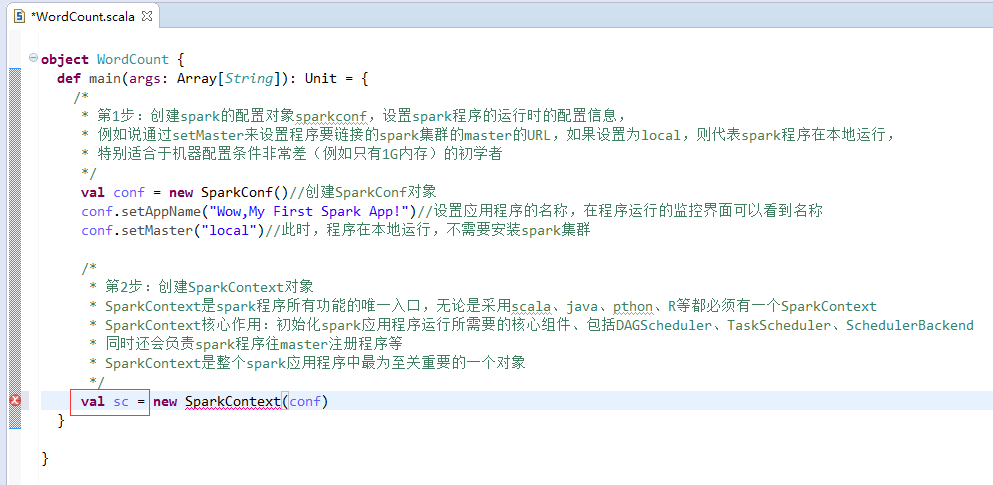

第3步
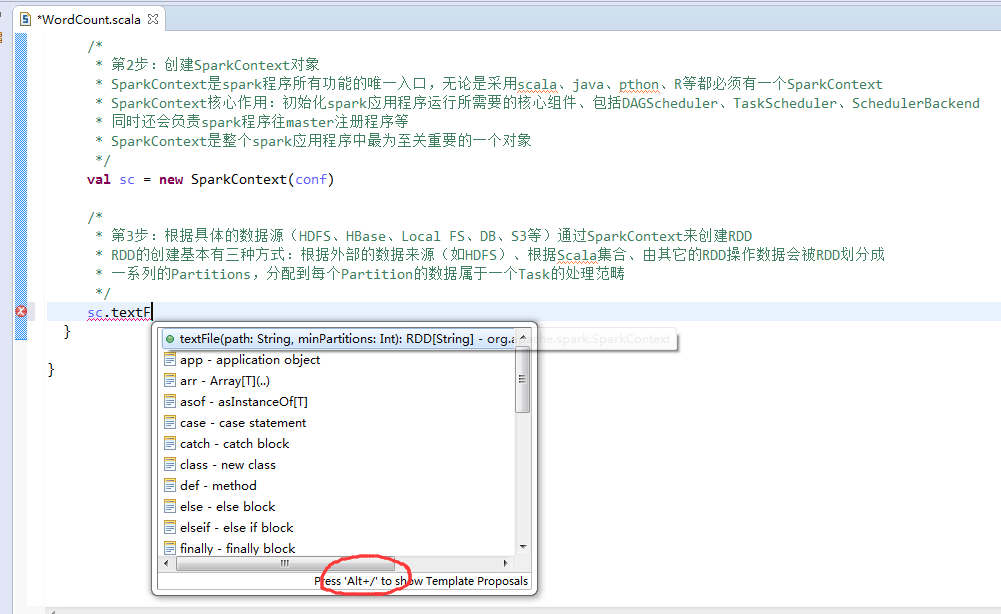

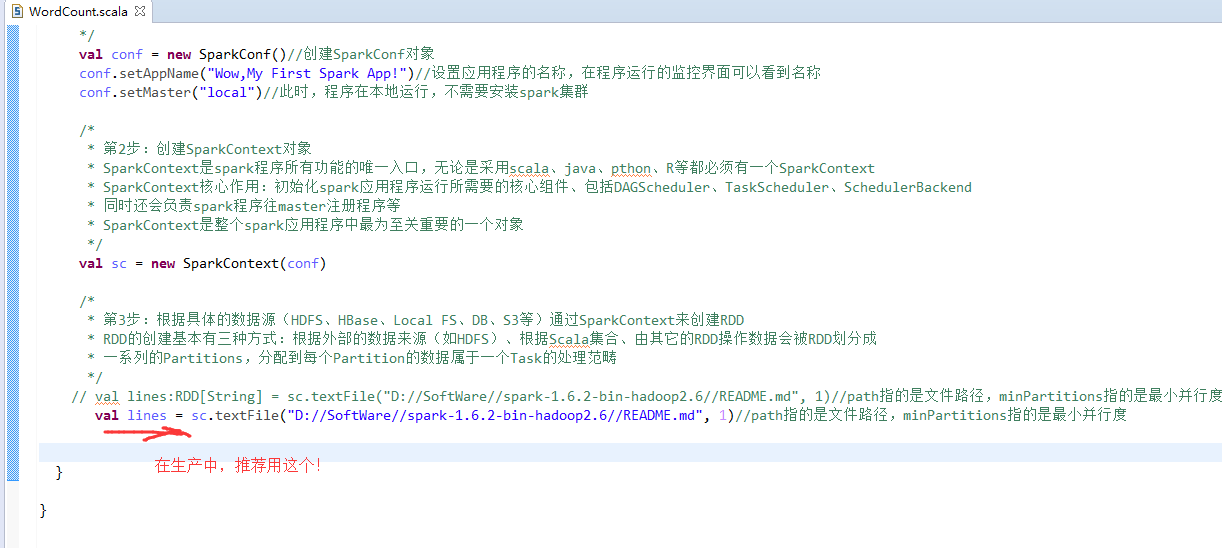
第4步
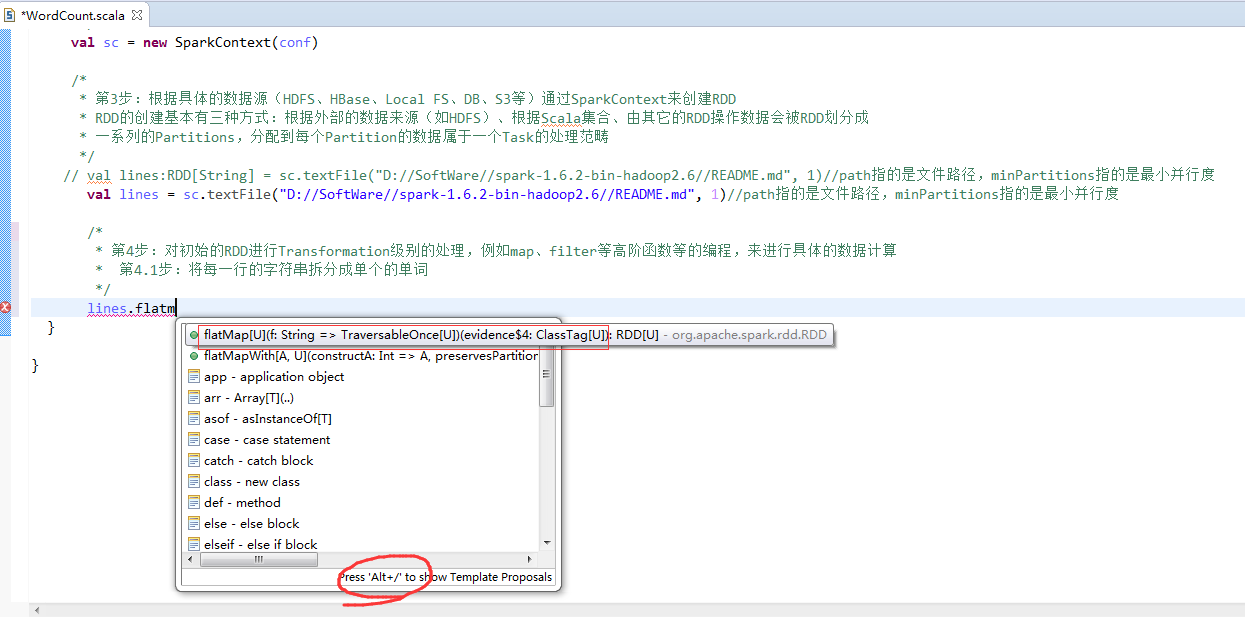
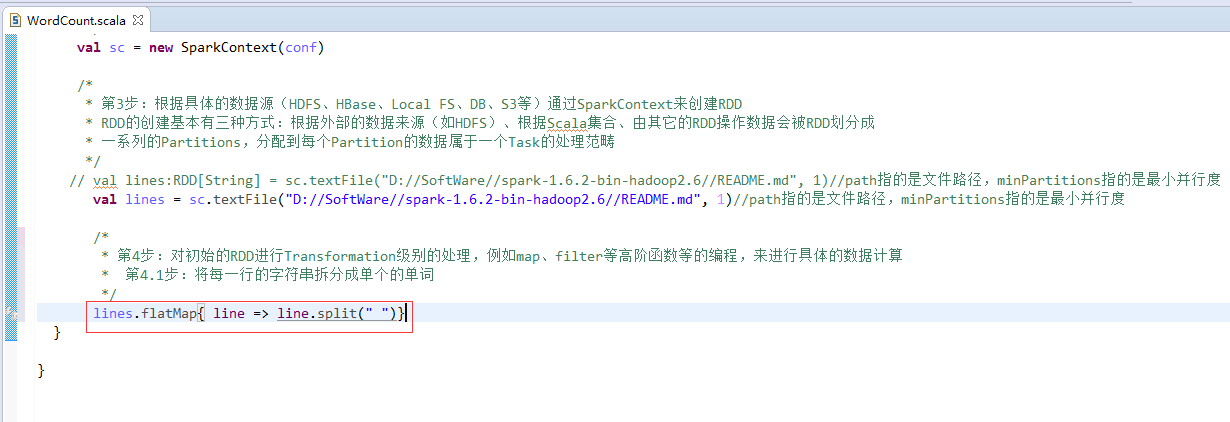
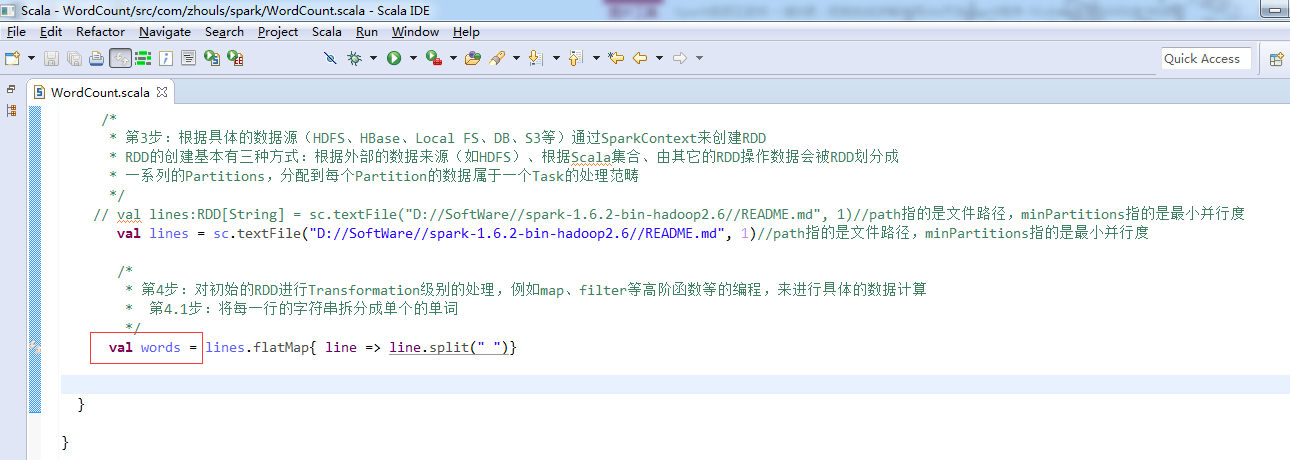


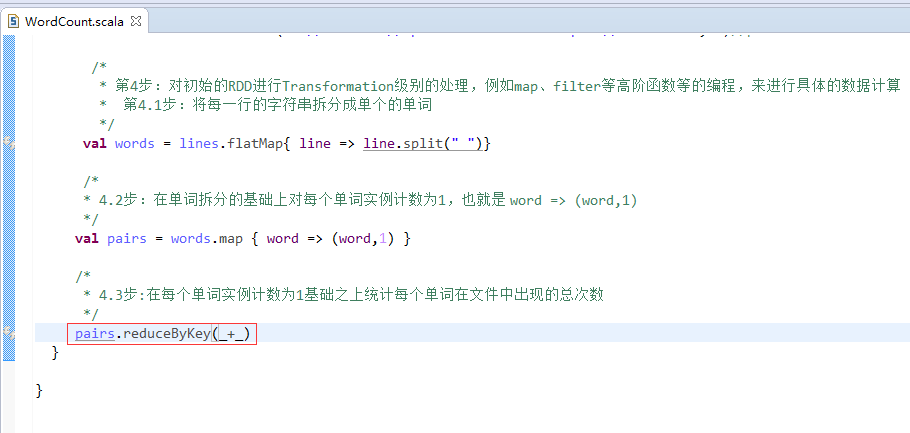
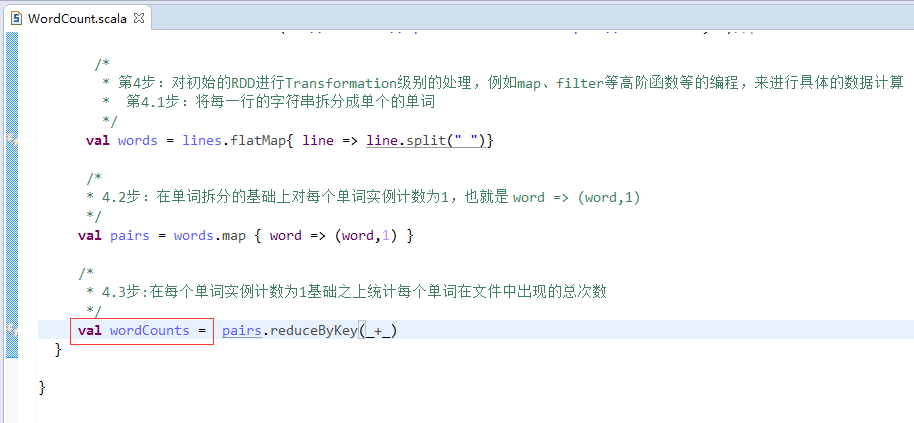
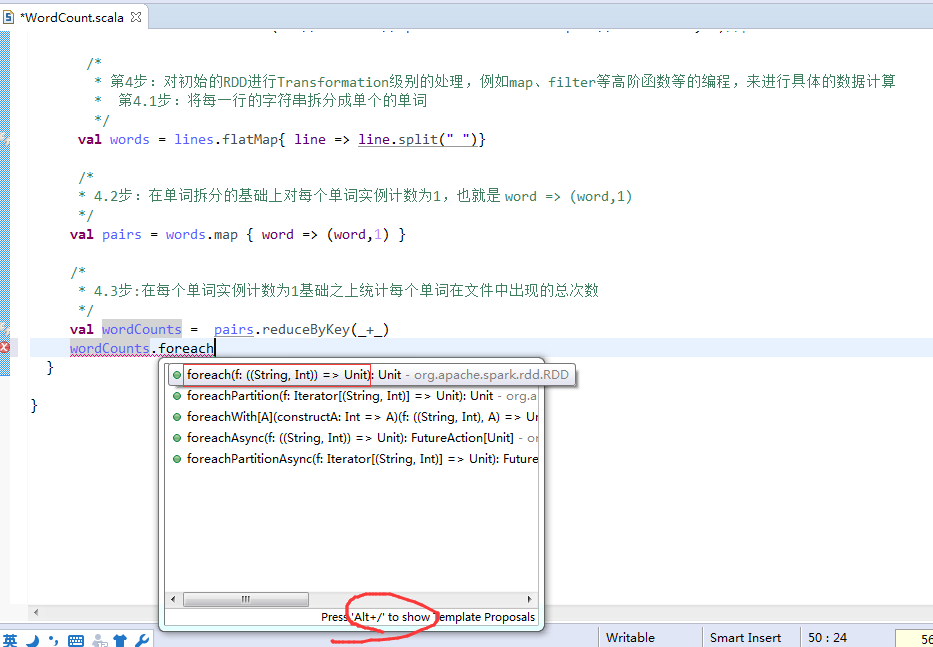
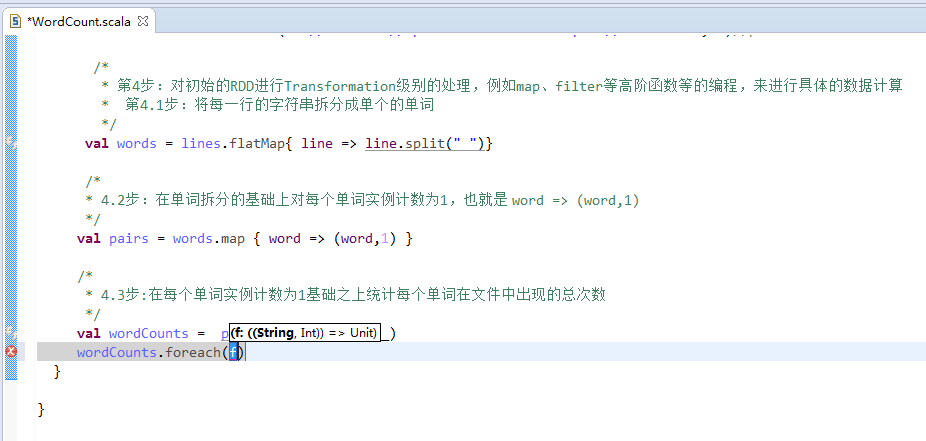
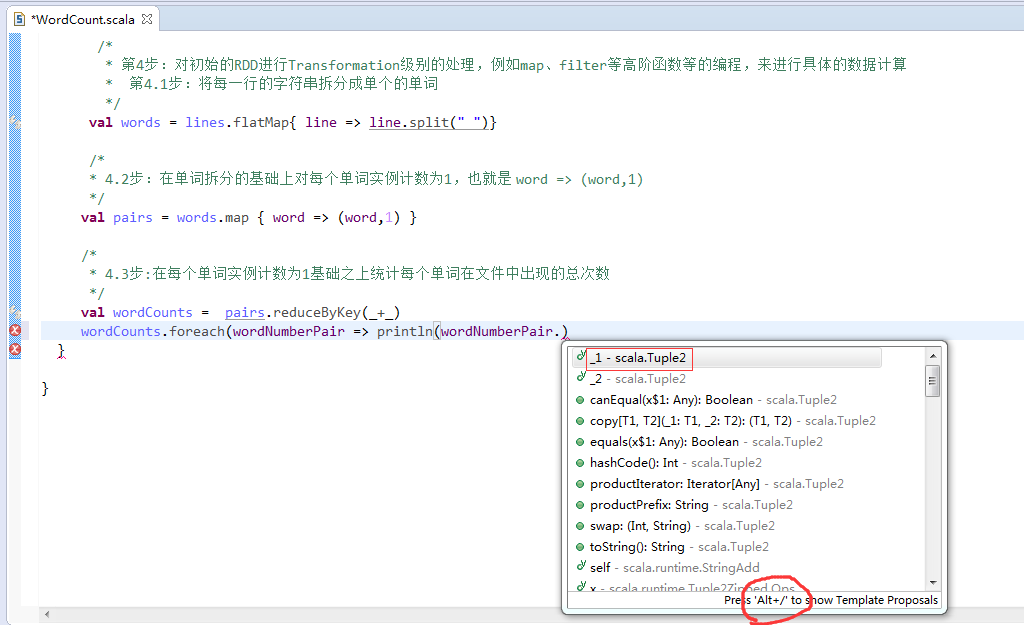
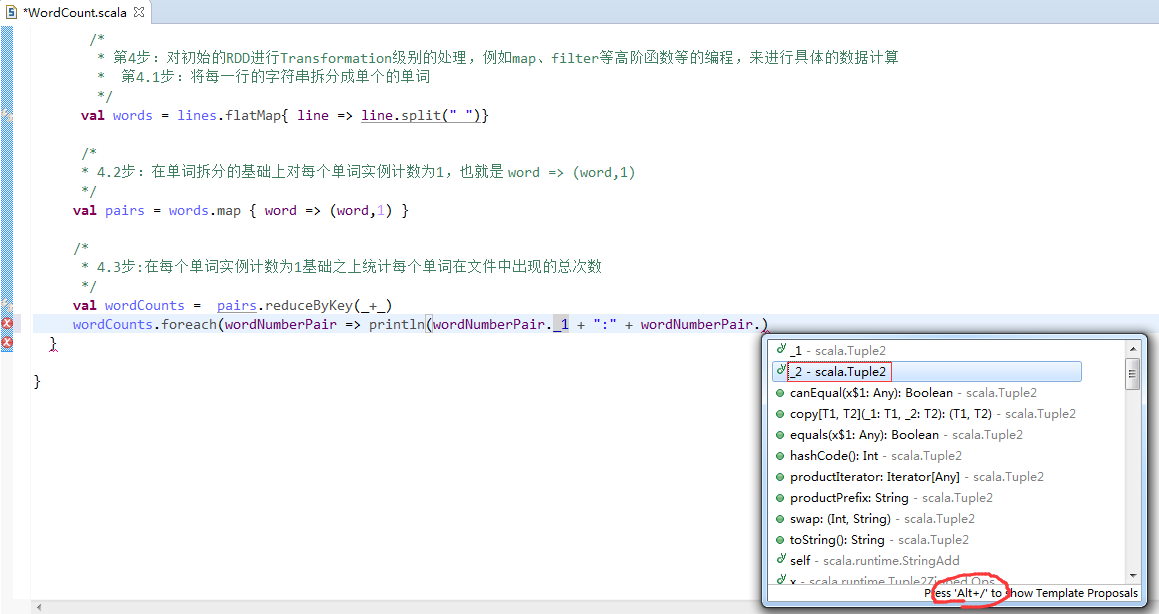
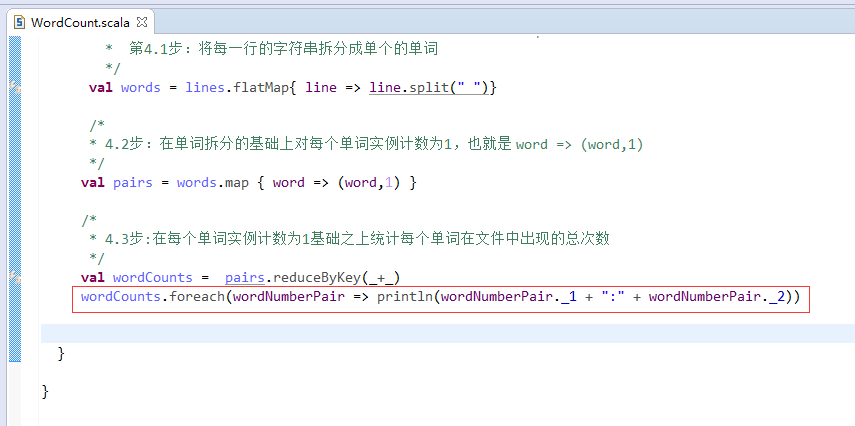
第5步

第6步
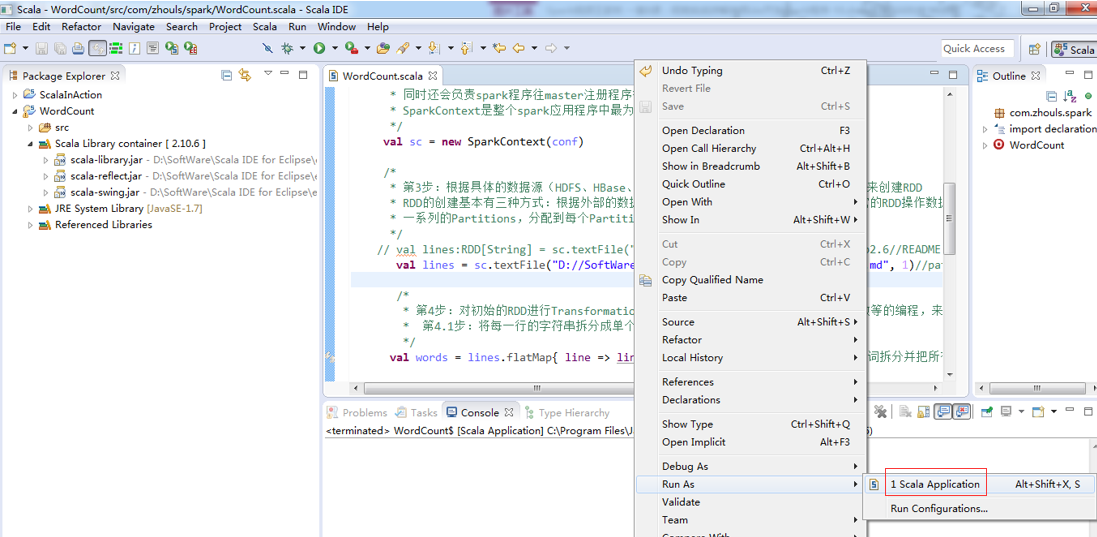
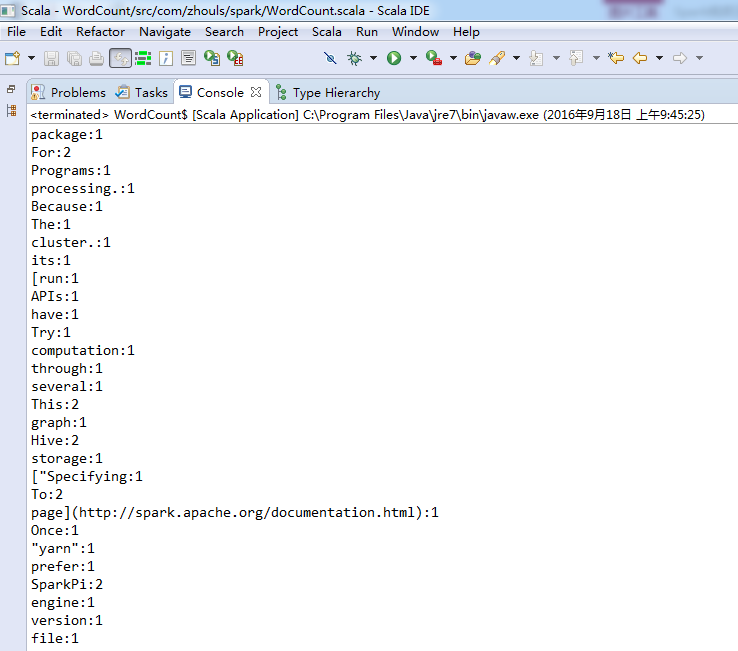
集群模式
这里,学会巧,复制粘贴,WordCount.scala 为 WordCount_Clutser.scala。



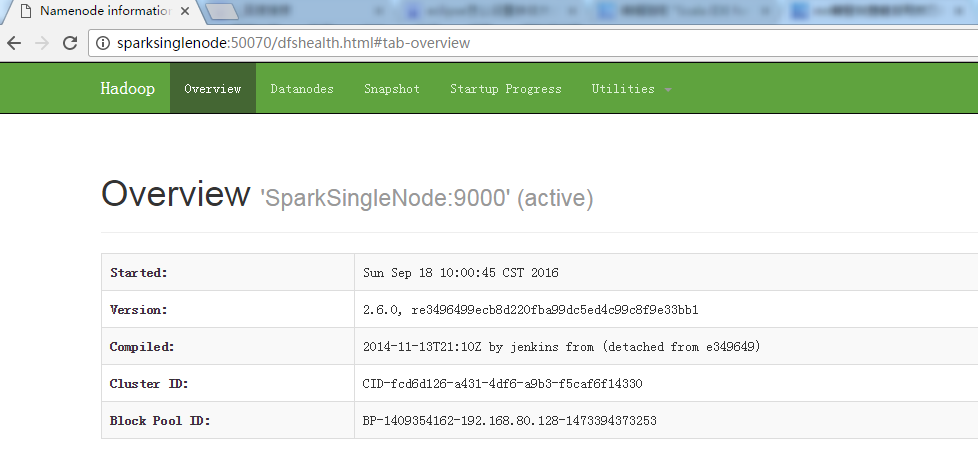
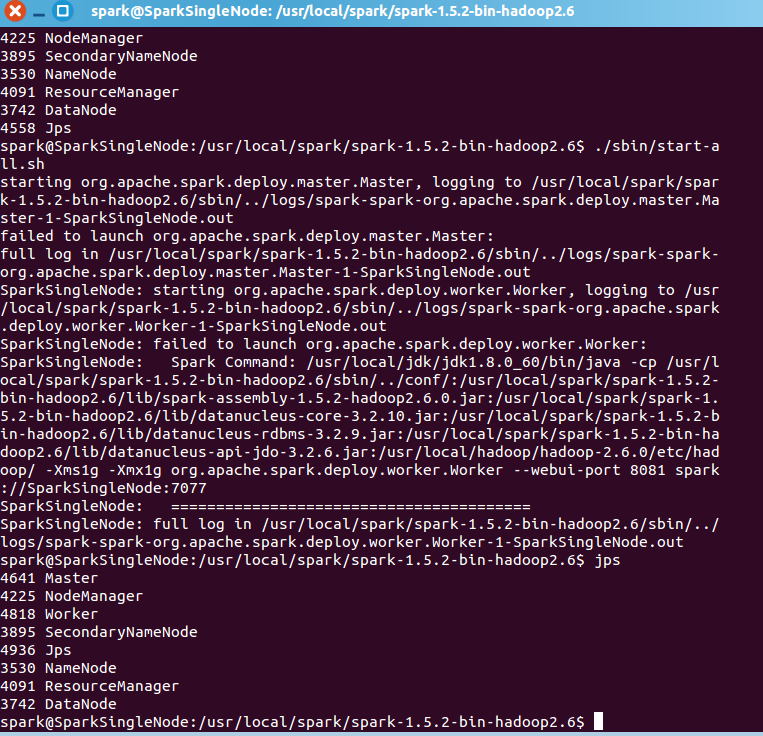
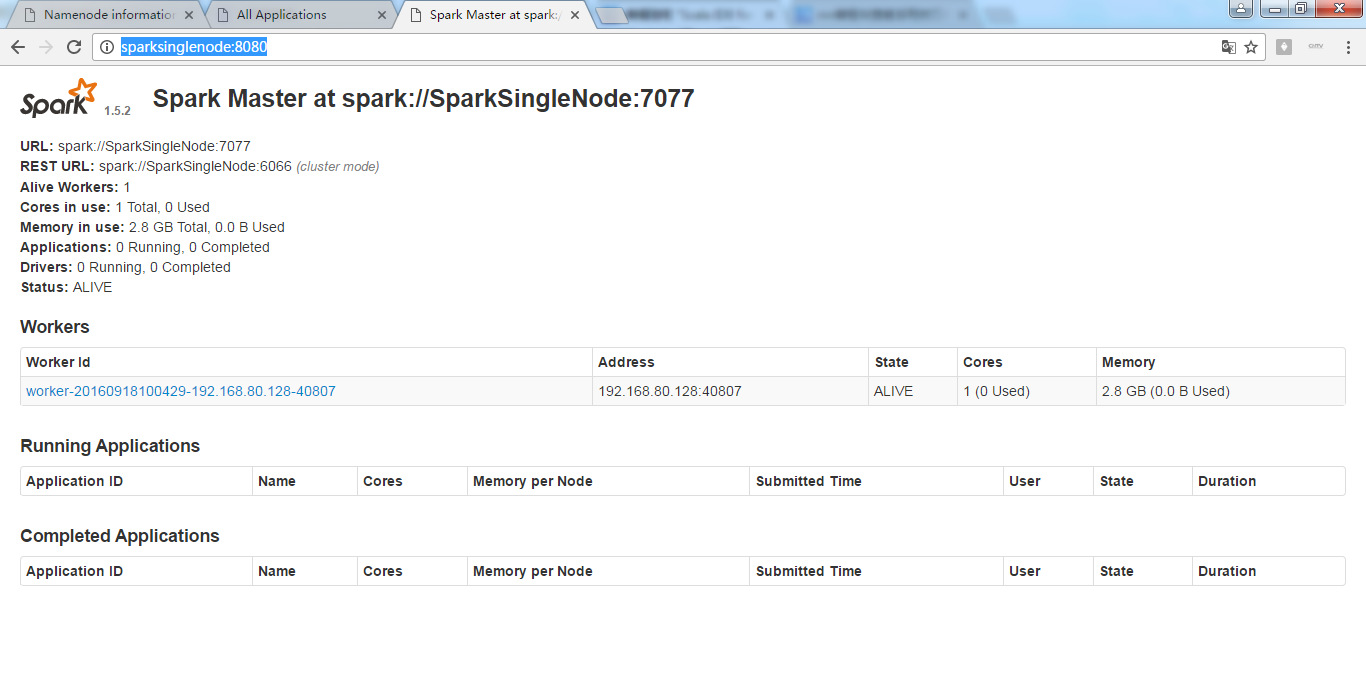
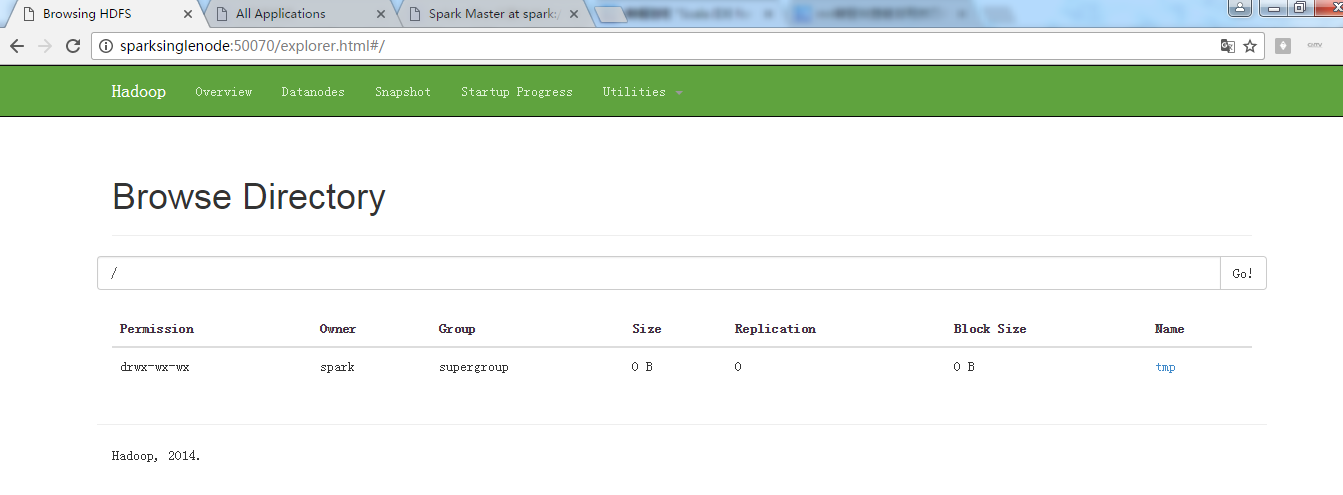
现在呢,来从Linux里,拷贝文件到hadoop集群里
即,将
/usr/local/spark/spark-1.5.2-bin-hadoop2.6/README.md 到 / 或 hdfs://SparkSingleNode:9000
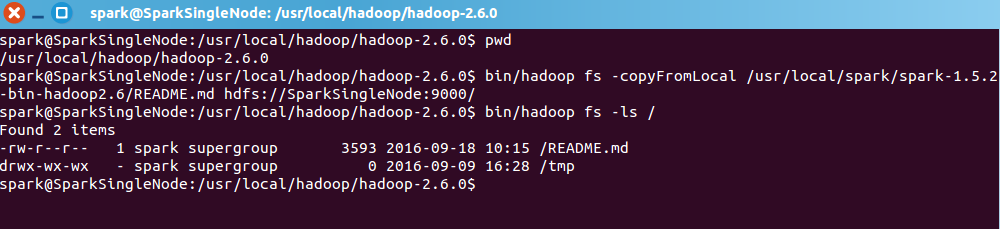
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$ pwd
/usr/local/hadoop/hadoop-2.6.0
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$ bin/hadoop fs -copyFromLocal /usr/local/spark/spark-1.5.2-bin-hadoop2.6/README.md hdfs://SparkSingleNode:9000/
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$ bin/hadoop fs -ls /
Found 2 items
-rw-r--r-- 1 spark supergroup 3593 2016-09-18 10:15 /README.md
drwx-wx-wx - spark supergroup 0 2016-09-09 16:28 /tmp
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$


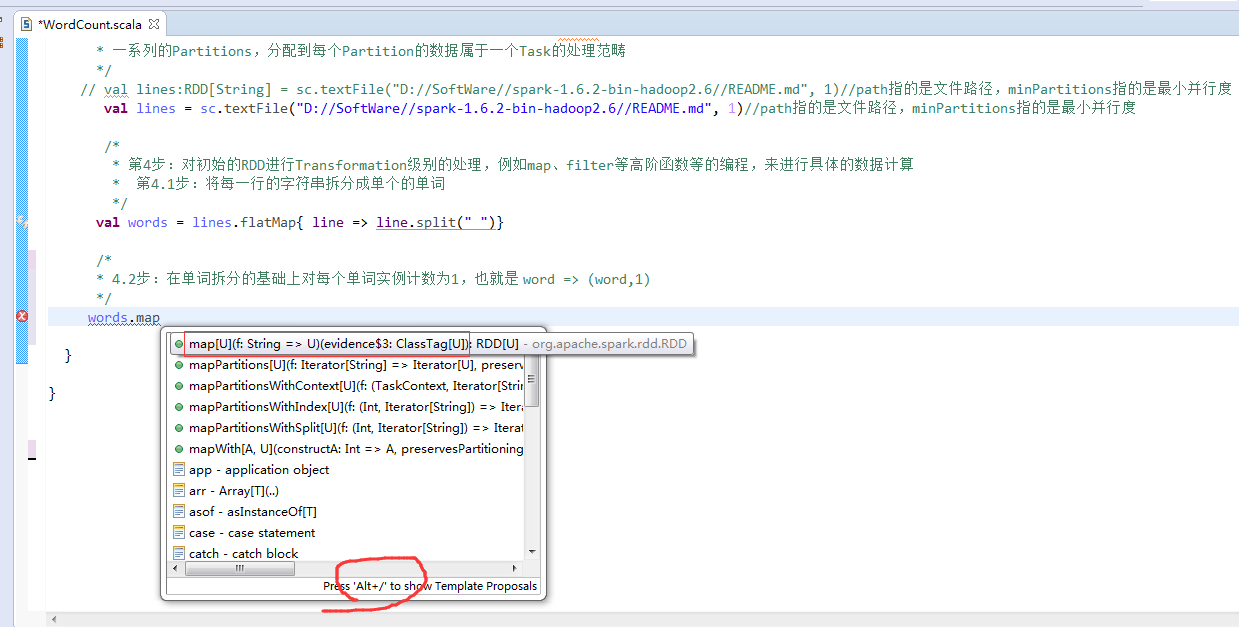
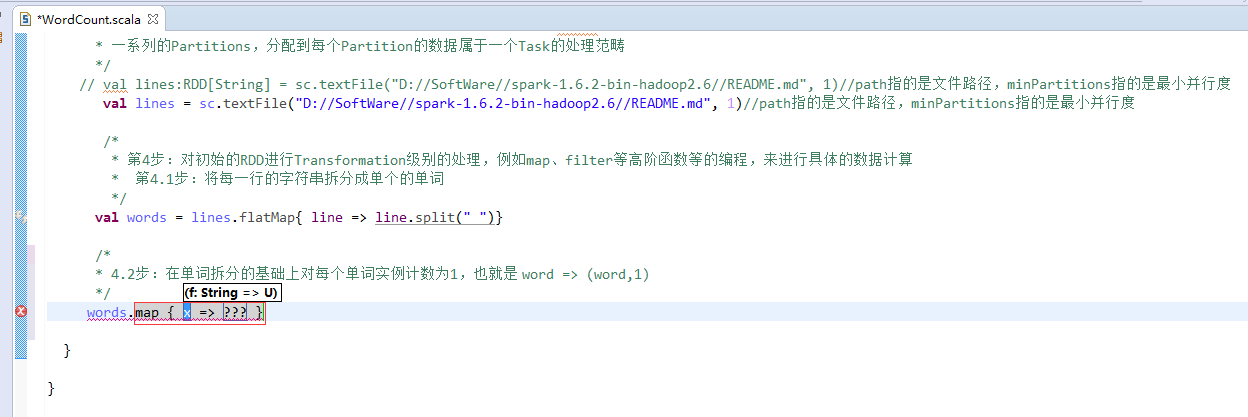
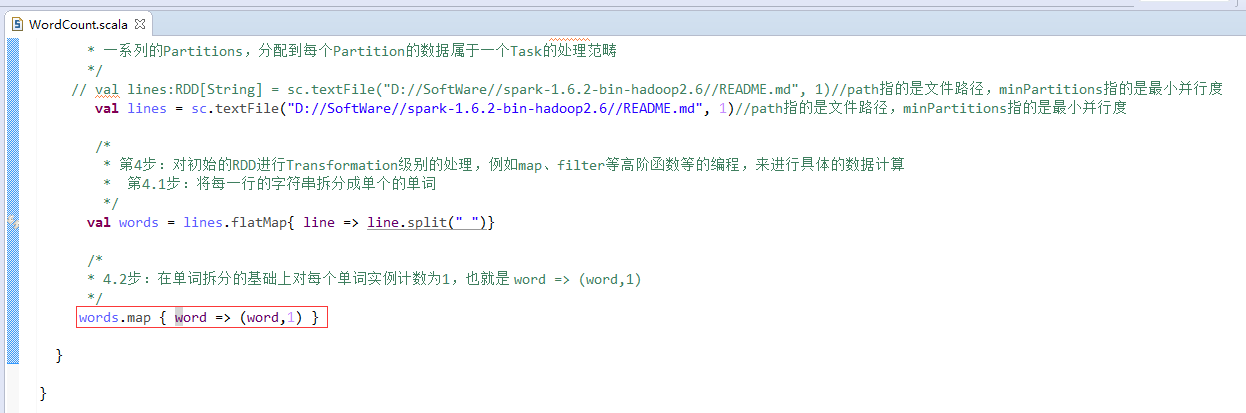
// val lines:RDD[String] = sc.textFile("D://SoftWare//spark-1.6.2-bin-hadoop2.6//README.md", 1)//path指的是文件路径,minPartitions指的是最小并行度
// val lines = sc.textFile("D://SoftWare//spark-1.6.2-bin-hadoop2.6//README.md", 1)//path指的是文件路径,minPartitions指的是最小并行度
// val lines = sc.textFile("hdfs://SparkSingleNode:9000/README.md", 1)//没必要会感知上下文
// val lines = sc.textFile("/README.md", 1)//path指的是文件路径,minPartitions指的是最小并行度
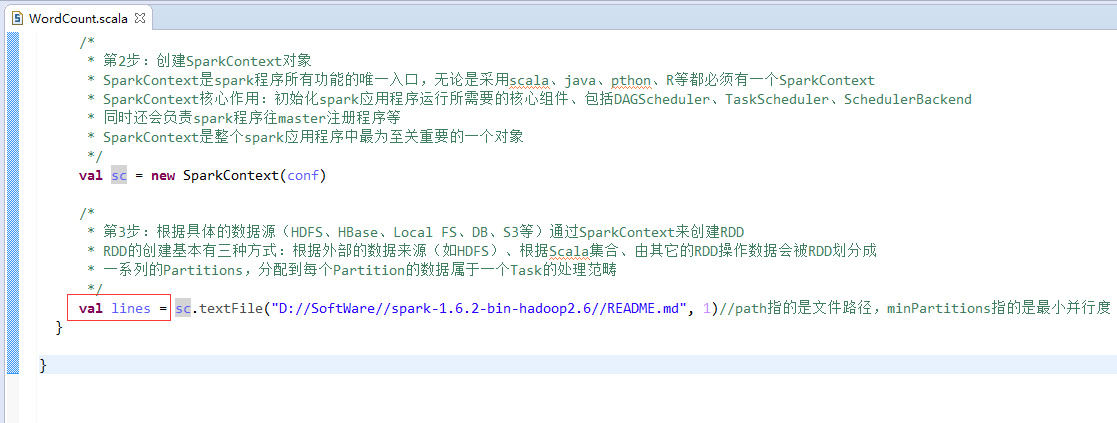
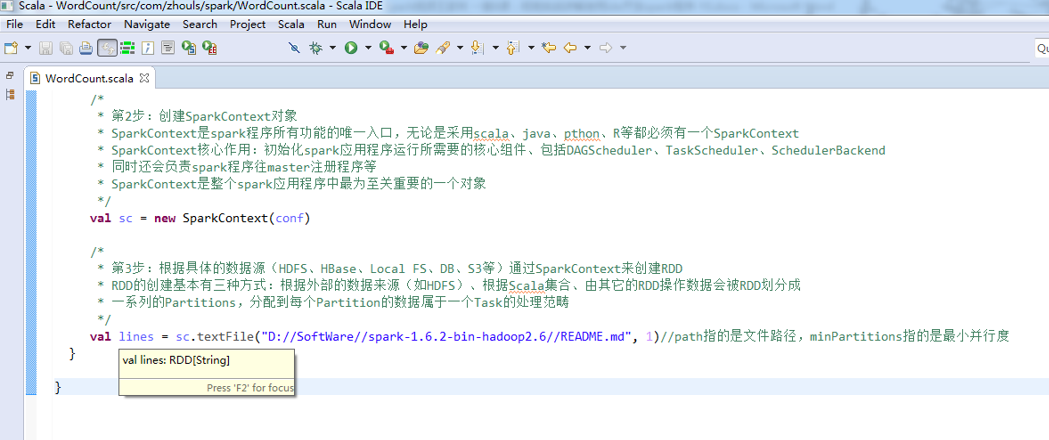
val lines = sc.textFile("/README.md")//为什么,这里不写并行度了呢?因为,hdfs会有一个默认的
如,我们的这里/里,有188个文件,每个文件小于128M。
所以,会有128个小集合。
当然,若是大于的话,我们可以人为干预,如3等
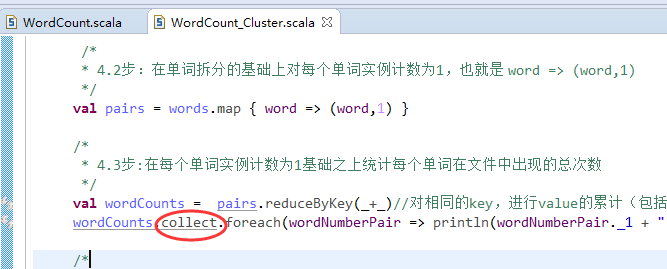
做好程序修改之后,
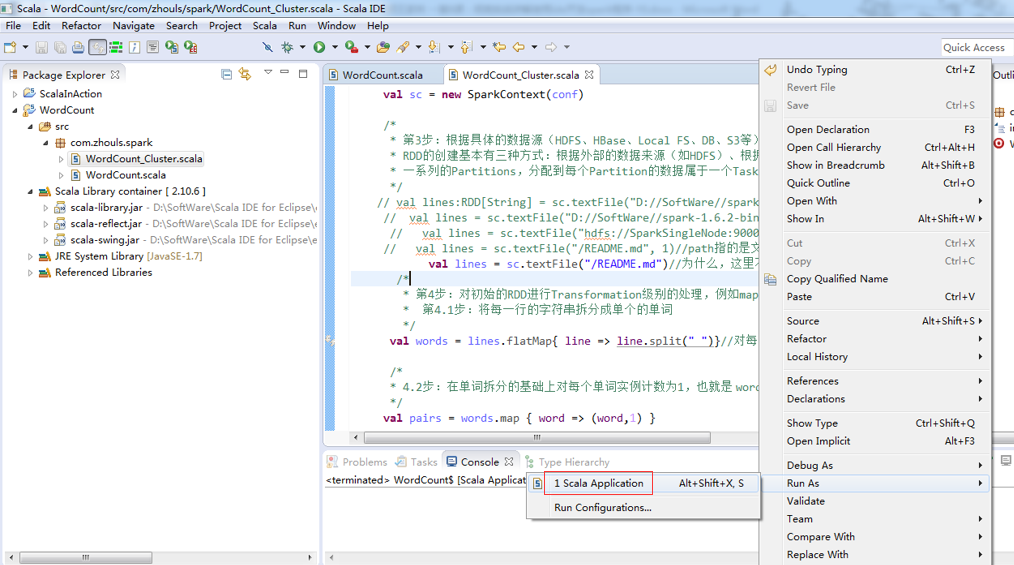

我这里啊,遇到如上的错误。
http://blog.csdn.net/weipanp/article/details/42713121
(3)Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(II[BI[BIILjava/lang/String;JZ)V
at org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(Native Method)
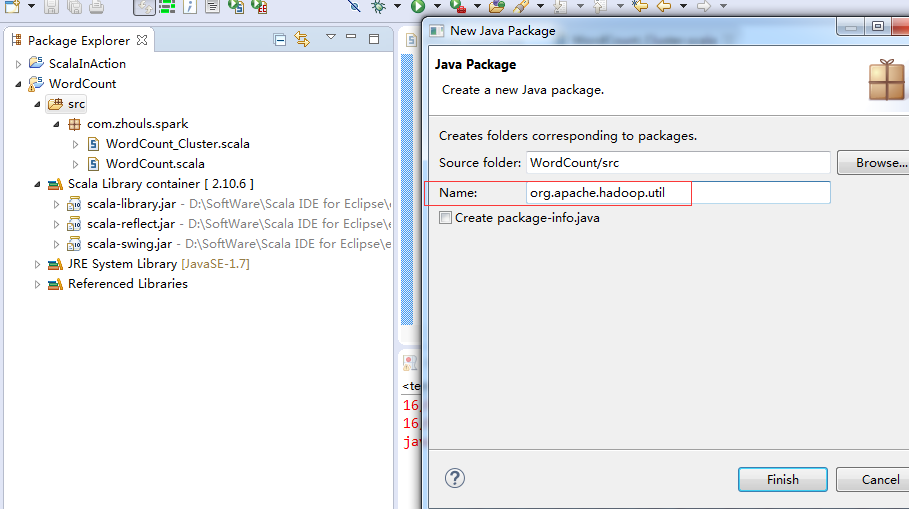
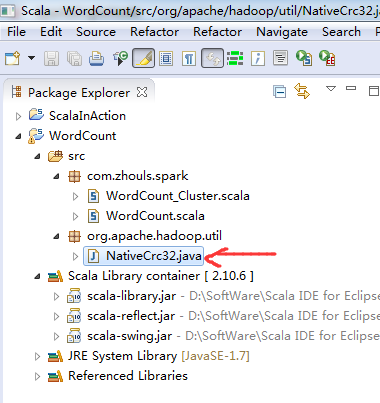
修复方法:在hadoop2.6源码里找到NativeCrc32.java,创建与源码一样的包名,拷贝NativeCrc32.java到该包工程目录下。


hadoop-2.6.0-src/hadoop-common-project/hadoop-common/src/main/java/org/apache/hadoop/util/NativeCrc32.java


以及,缺少hadoop.dll,注意是64位的。放到hadoop-2.6.0下的bin目录下
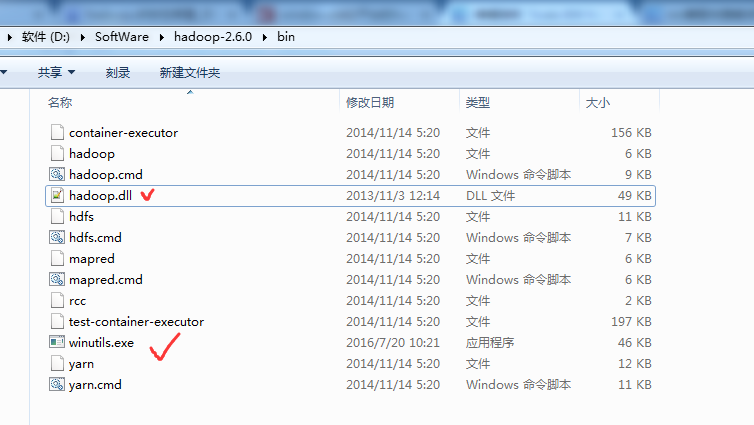
玩玩spark-1.5.2-bin-hadoop2.6.tgz

继续,,,出现了一些问题!
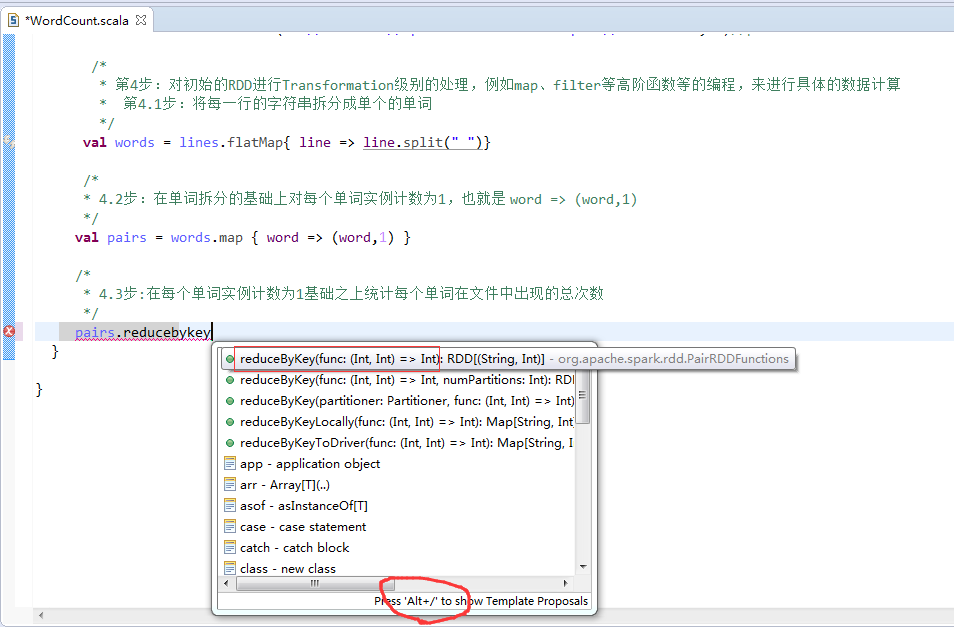
其实啊,在集群里,模板就是如下
val file = spark.textFile("hdfs://...”)
val counts = file.flatMap("line => line.spilt(" "))
.map(word => (word,1))
.reduceByKey(_+_)
counts.saveAsTextFile("hdfs://...”)
Scala IDE for Eclipse的下载、安装和WordCount的初步使用(本地模式和集群模式)的更多相关文章
- Eclipse的下载、安装和WordCount的初步使用(本地模式和集群模式)
包括: Eclipse的下载 Eclipse的安装 Eclipse的使用 本地模式或集群模式 Scala IDE for Eclipse的下载.安装和WordCount的初步使用(本地模式和集群 ...
- IntelliJ IDEA的下载、安装和WordCount的初步使用(本地模式和集群模式)
包括: IntelliJ IDEA的下载 IntelliJ IDEA的安装 IntelliJ IDEA中的scala插件安装 用SBT方式来创建工程 或 选择Scala方式来创建工程 本地模式或集群 ...
- IntelliJ IDEA(Ultimate版本)的下载、安装和WordCount的初步使用(本地模式和集群模式)
不多说,直接上干货! IntelliJ IDEA号称当前Java开发效率最高的IDE工具.IntelliJ IDEA有两个版本:社区版(Community)和旗舰版(Ultimate).社区版时免费的 ...
- IntelliJ IDEA(Community版本)的下载、安装和WordCount的初步使用(本地模式和集群模式)
不多说,直接上干货! 对于初学者来说,建议你先玩玩这个免费的社区版,但是,一段时间,还是去玩专业版吧,这个很简单哈,学聪明点,去搞到途径激活!可以看我的博客. 包括: IntelliJ IDEA(Co ...
- Centos7安装Nacos单机模式以及集群模式(包含nignx安装以及实现集群)的相关配置
Nacos 致力于帮助您发现.配置和管理微服务.Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现.服务配置.服务元数据及流量管理. Nacos支持三种部署模式 单机模式 - 用于测试 ...
- 5.Zookeeper的两种安装和配置(Windows):单机模式与集群模式
转自:https://blog.csdn.net/a906998248/article/details/50815031
- CentOS6.5下如何正确下载、安装Intellij IDEA、Scala、Scala-intellij-bin插件、Scala IDE for Eclipse助推大数据开发(图文详解)
不多说,直接上干货! 第一步:卸载CentOS中自带openjdk Centos 6.5下的OPENJDK卸载和SUN的JDK安装.环境变量配置 第二步:安装Intellij IDEA 若是3节点 ...
- scala IDE for Eclipse开发Spark程序
1.开发环境准备 scala IDE for Eclipse:版本(4.6.1) 官网下载:http://scala-ide.org/download/sdk.html 百度云盘下载:链接:http: ...
- Spark Tachyon编译部署(含单机和集群模式安装)
Tachyon编译部署 编译Tachyon 单机部署Tachyon 集群模式部署Tachyon 1.Tachyon编译部署 Tachyon目前的最新发布版为0.7.1,其官方网址为http://tac ...
随机推荐
- 一步步学习ASP.NET MVC3 (11)——@Ajax,JavaScriptResult(2)
请注明转载地址:http://www.cnblogs.com/arhat 今天在补一章吧,由于明天的事可能比较多,老魏可能顾不上了,所以今天就再加把劲在写一章吧.否则对不起大家了,大家看的比较快,可是 ...
- 获取iOS设备型号的方法总结
三种常用的办法获取iOS设备的型号: 1. [UIDevice currentDevice].model (推荐): 2. uname(struct utsname *name) ,使用此函数需要#i ...
- Linux开启服务器问题(李蕾问题)
每次启动192.168.1.223服务器时,都要执行这个命令! #:service iptables stop
- python 统计单词个数
根据一篇英文文章统计其中单词出现最多的10个单词. # -*- coding: utf-8 -*-import urllib2import refrom collections import Coun ...
- YARN加载本地库抛出Unable to load native-hadoop library解决办法
YARN加载本地库抛出Unable to load native-hadoop library解决办法 用官方的Hadoop 2.1.0-beta安装后,每次hadoop命令进去都会抛出这样一个War ...
- Oracle中的触发器
创建触发器的语法: Create trigger 触发器的名字 after insert/update/delete/(select是没有触发器的) on 表名字 declare begin dbms ...
- hdu 3487
splay #include<cstdio> #include<cstring> #include<iostream> #include<algorithm& ...
- easyui源码翻译1.32--Layout(布局)
前言 使用$.fn.layout.defaults重写默认值对象.下载该插件翻译源码 布局容器有5个区域:北.南.东.西和中间.中间区域面板是必须的,边缘的面板都是可选的.每个边缘区域面板都可以通过拖 ...
- 【Linux安全】文件或目录权限设置
实例演示: 要求:新建文件夹,名称为secure,要求改文件夹只能被创建者deadmin以及与deadmin同组用户进行读.写.执行的权限, 其他用户均只有读的权限. 查看 一下secure原本的权限 ...
- Dagger 2: Step To Step
文/iamwent(简书作者)原文链接:http://www.jianshu.com/p/7505d92d7748著作权归作者所有,转载请联系作者获得授权,并标注“简书作者”. 假设你已经了解 依赖注 ...