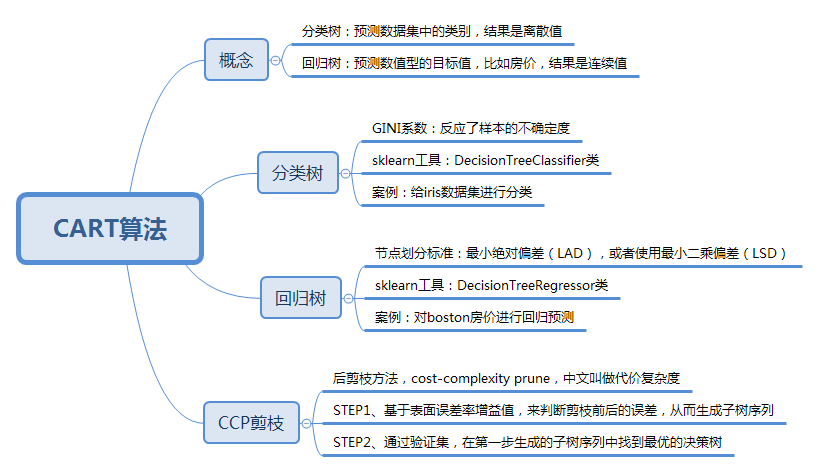
python数据分析算法(决策树2)CART算法
CART(Classification And Regression Tree),分类回归树,,决策树可以分为ID3算法,C4.5算法,和CART算法。ID3算法,C4.5算法可以生成二叉树或者多叉树,CART只支持二叉树,既可支持分类树,又可以作为回归树。
分类树: 基于数据判断某物或者某人的某种属性(个人理解)可以处理离散数据,就是有限的数据,输出样本的类别
回归树: 给定了数据,预测具体事物的某个值;可以对连续型的数据进行预测,也就是数据在某个区间内都有取值的可能,它输出的是一个数值
CART 分类树的工作流程
CART和C4.5算法类似,知识属性选择的指标采用的是基尼系数,基尼系数本身反应了样本的不确定度,当基尼系数越小的时候,说明样本之间的差异性小,不确定度低。分类的过程是一个不确定度降低的过程,即纯度提升的过程,所以构造分类树的时候会基于基尼系数最小的属性作为划分。
了解基尼系数:
假设t为节点,那么该节点的GINI系数的计算公式为:
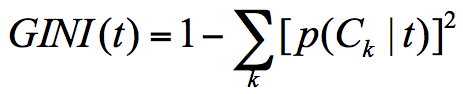
p(Ck|t) 表示t属性类别Ck的概率,节点t的基尼系数为1减去各个分类Ck概率平方和
例如集合1: 6个人去游泳, 那么p(Ck|t)=1,因此 GINI(t) = 1-1 =0
集合2 : 3个人去游泳,3个人不去,那么p(C1k|t) = 0.5 ,p(C2k|t) = 0.5
得出,集合1样本基尼系数最小,样本最稳定,2的样本不稳定性大

该公式表示节点D的基尼系数等于子节点D1,D2的归一化基尼系数之和
使用CART算法创建分类树
iris是sklearn 自带IRIS(鸢尾花)数据集sklearn中的来对特征处理功能进行说明包含4个特征(Sepal.Length(花萼长度)、Sepal.Width(花萼宽度)、Petal.Length(花瓣长度)、Petal.Width(花瓣宽度)),特征值都为正浮点数,单位为厘米
目标值为鸢尾花的分类(Iris Setosa(山鸢尾)、Iris Versicolour(杂色鸢尾),Iris Virginica(维吉尼亚鸢尾))
1 # encoding=utf-8
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
# 准备数据集
iris=load_iris()
# 获取特征集和分类标识
features = iris.data
labels = iris.target
# 随机抽取 33% 的数据作为测试集,其余为训练集 使用sklearn.model_selection train_test_split 训练
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.33, random_state=0)
# 创建 CART 分类树
clf = DecisionTreeClassifier(criterion='gini')
# 拟合构造 CART 分类树
clf = clf.fit(train_features, train_labels)
# 用 CART 分类树做预测 得到预测结果
test_predict = clf.predict(test_features)
# 预测结果与测试集结果作比对
score = accuracy_score(test_labels, test_predict)
print("CART 分类树准确率 %.4lf" % score)
CART 分类树准确率 0.9600
train_test_split 可以把数据集抽取一部分作为测试集,就可以德奥训练集和测试集
14 初始化一棵cart树,16 训练集的特征值和分类表示作为参数进行拟合得到cart分类树
cart回归树的工作流程
cart回归树划分数据集的过程和分类树的过程是一样的,回归树得到的预测结果是连续值,评判不纯度的指标不同,分类树采用的是基尼系数,回归树需要根据样本的离散程度来评价 不纯度
样本离散程度计算方式,每个样本值到均值的差值,可以去差值的绝对值,或者方差
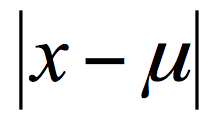
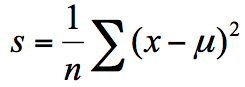 方差为每个样本值减去样本均值的平方和除以样本可数
方差为每个样本值减去样本均值的平方和除以样本可数
最小绝对偏差(LAD) 最小二乘偏差
如何使用CART回归树做预测
这里使用sklearn字典的博士度房价数据集,该数据集给出了影响房价的一些指标,比如犯罪了房产税等,最后给出了房价
# encoding=utf-8
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.metrics import r2_score,mean_absolute_error,mean_squared_error
from sklearn.tree import DecisionTreeRegressor
# 准备数据集
boston=load_boston()
# 探索数据
print(boston.feature_names)
# 获取特征集和房价
features = boston.data
prices = boston.target
# 随机抽取 33% 的数据作为测试集,其余为训练集
train_features, test_features, train_price, test_price = train_test_split(features, prices, test_size=0.33)
# 创建 CART 回归树
dtr=DecisionTreeRegressor()
# 拟合构造 CART 回归树
dtr.fit(train_features, train_price)
# 预测测试集中的房价
predict_price = dtr.predict(test_features)
# 测试集的结果评价
print('回归树二乘偏差均值:', mean_squared_error(test_price, predict_price))
print('回归树绝对值偏差均值:', mean_absolute_error(test_price, predict_price))
['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO'
'B' 'LSTAT']
回归树二乘偏差均值: 32.065568862275455
回归树绝对值偏差均值 3.2892215568862277
cart决策树的剪枝
cart决策树剪枝采用的是CCP方法,一种后剪枝的方法,cost-complexity prune 中文:代价复杂度,这种剪枝用到一个指标 叫做 节点的表面误差率增益值,以此作为剪枝前后误差的定义
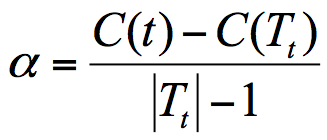 Tt 代表以t为根节点的子树,C(Tt)表示节点t的子树没被裁剪时子树Tt的误差,C(t)表示节点t的子树被剪枝后节点t的误差,|Tt|代子树Tt的叶子树,剪枝后,T的叶子树减一
Tt 代表以t为根节点的子树,C(Tt)表示节点t的子树没被裁剪时子树Tt的误差,C(t)表示节点t的子树被剪枝后节点t的误差,|Tt|代子树Tt的叶子树,剪枝后,T的叶子树减一
所以节点的表面误差率增益值 等于 节点t的子树被剪枝后的误差变化除以 减掉的叶子数量
因此希望剪枝前后误差最小,所以我们要寻找就是最小α值对应的节点,把它减掉。生成第一个子树,重复上面过程继续剪枝,知直到最后为根节点,即为最后一个子树
得到剪枝后的子树集合后,我们需要采用验证集对所有子树的误差计算一遍,可以计算每个子树的基尼指数或平房误差,去最小的那棵树
python数据分析算法(决策树2)CART算法的更多相关文章
- 决策树2 -- CART算法
声明: 1,本篇为个人对<2012.李航.统计学习方法.pdf>的学习总结.不得用作商用,欢迎转载,但请注明出处(即:本帖地址). 2,因为本人在学习初始时有非常多数学知识都已忘记.所以为 ...
- 决策树之CART算法
顾名思义,CART算法(classification and regression tree)分类和回归算法,是一种应用广泛的决策树学习方法,既然是一种决策树学习方法,必然也满足决策树的几大步骤,即: ...
- 《机器学习实战》学习笔记第九章 —— 决策树之CART算法
相关博文: <机器学习实战>学习笔记第三章 —— 决策树 主要内容: 一.CART算法简介 二.分类树 三.回归树 四.构建回归树 五.回归树的剪枝 六.模型树 七.树回归与标准回归的比较 ...
- 简单易学的机器学习算法——决策树之ID3算法
一.决策树分类算法概述 决策树算法是从数据的属性(或者特征)出发,以属性作为基础,划分不同的类.例如对于如下数据集 (数据集) 其中,第一列和第二列为属性(特征),最后一列为类别标签,1表示是 ...
- 02-23 决策树CART算法
目录 决策树CART算法 一.决策树CART算法学习目标 二.决策树CART算法详解 2.1 基尼指数和熵 2.2 CART算法对连续值特征的处理 2.3 CART算法对离散值特征的处理 2.4 CA ...
- 机器学习——十大数据挖掘之一的决策树CART算法
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第23篇文章,我们今天分享的内容是十大数据挖掘算法之一的CART算法. CART算法全称是Classification ...
- 决策树-预测隐形眼镜类型 (ID3算法,C4.5算法,CART算法,GINI指数,剪枝,随机森林)
1. 1.问题的引入 2.一个实例 3.基本概念 4.ID3 5.C4.5 6.CART 7.随机森林 2. 我们应该设计什么的算法,使得计算机对贷款申请人员的申请信息自动进行分类,以决定能否贷款? ...
- 决策树模型 ID3/C4.5/CART算法比较
决策树模型在监督学习中非常常见,可用于分类(二分类.多分类)和回归.虽然将多棵弱决策树的Bagging.Random Forest.Boosting等tree ensembel 模型更为常见,但是“完 ...
- 机器学习技法-决策树和CART分类回归树构建算法
课程地址:https://class.coursera.org/ntumltwo-002/lecture 重要!重要!重要~ 一.决策树(Decision Tree).口袋(Bagging),自适应增 ...
随机推荐
- Lua中的一些库(1)
[数学库] 数学库(math)由一组标准的数学函数构成.这里主要介绍几个常用的函数,其它的大家可以自行百度解决. 三角函数(sin,cos,tan……)所有的三角函数都使用弧度单位,可以用函数deg( ...
- 038_nginx backlog配置
一. backlog=number sets the backlog parameter in the listen() call that limits the maximum length for ...
- Django 序列化-token
幂等性 幂等性:多次操作的结果和一次操作的结果是一样的 ,put请求是幂等的 post请求不是幂等的 序列化组件 全局和局部钩子函数 异常信息抛出过程 认证 路由里的,login.as_view() ...
- 命令制作Mac系统U盘启动
命令 sudo /Applications/Install\ macOS\ Mojave.app/Contents/Resources/createinstallmedia --volume /Vol ...
- linux磁盘阵列 逻辑卷管理器
Difficult doesn't mean impossible.It simply meansthat you have to work hard.困难并不代表不可能,它仅仅意味着你必须努力奋斗. ...
- RSF 分布式 RPC 服务框架的分层设计
RSF 是个什么东西? 一个高可用.高性能.轻量级的分布式服务框架.支持容灾.负载均衡.集群.一个典型的应用场景是,将同一个服务部署在多个Server上提供 request.response 消息通知 ...
- 阿里云centos7成功安装和启动nginx,但是外网访问不了的解决方案
问题环境: 阿里云centos7.4.1708 问题描述:成功配置,启动成功,外网访问不了 解决方案: 经过查阅文档,去阿里云后台查看,原来是新购的服务器都加入和实例安全组. (OMG)立即去配置.加 ...
- ECMAScript6 - 2.变量的解构赋值
1.数组解构赋值 1.1.基本用法 // (1)对数组变量赋值 let [foo, [[bar], baz]] = [1, [[2], 3]]; foo; // 1 bar; // 2 baz; // ...
- python---二叉树遍历
重学. # coding = utf-8 # 二叉树遍历 class Node: """节点类""" def __init__(self, ...
- SQL Server 中执行Shell脚本计算本地文件的内容大小
SQL Server 数据库中除了能执行基本的SQL语句外,也可以执行Shell脚本.默认安装后,SQL中的Shell脚本的功能是关闭的,需要手动打开, 执行以下脚本即可打开该功能. -- 允许配置高 ...