[大数据面试题]hadoop核心知识点
* 面试答案为LZ所写,如需转载请注明出处,谢谢。
* 这里不涉及HiveSQL和HBase操作的笔试题,这些东西另有总结。
1.MR意义。
MR是一个用于处理大数据的分布式离线计算框架,它采用”分而治之“的思想。
在分布式计算中,将分布式存储、分布式计算、负载均衡等复杂问题高度抽象成map和reduce两个过程。
MR存在的意义在于它使得计算更廉价,大规模数据计算不再需要高级商用机器。
其次是这个软件的现成实现可以把程序员的精力集中在业务开发上,节省开发时间。
2.简述MR过程。

MapReduce是一种应用于大数据离线处理的分布式计算模型。
MR过程分为 Split 、map 、Suffle、reduce 过程。
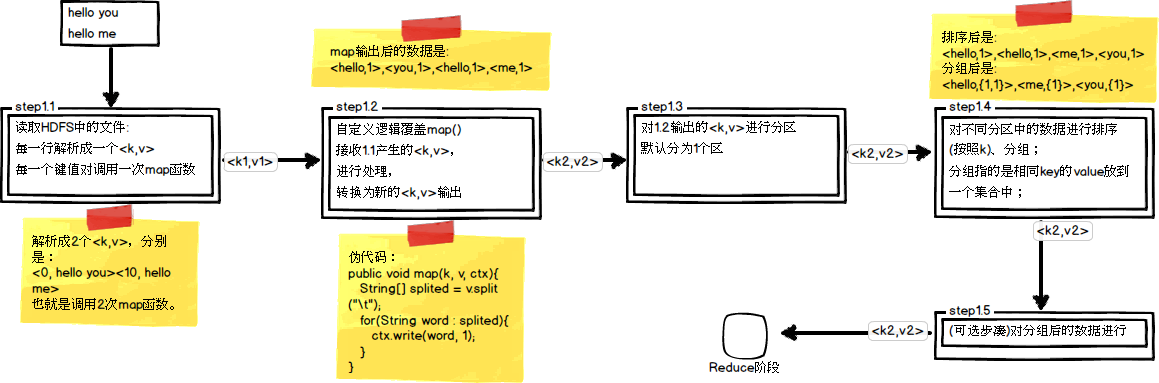
此图转载至: https://blog.csdn.net/asn_forever/article/details/81233547
split - 默认按行将文件进行切割,文本文件切割后为<beginNum,row>.
map - 将切割后的值映射成KV对。
partition - 对KV对集合进行分区,默认是使用hash partitioner.
group - 每个分区内按照Key进行排序,按Key进行group 。输出的 Key-ValueList 的集合作为reduce阶段的输入。
reduce - 对Key-ValueList 进行聚合。
另说一点感悟:
关于shuffle过程,我们其实很好理解。一般处理大数据集的二次排序问题,
都是采用 "散列 + Sort" 的思路,位列便于reduce计算,还需要进行一个grouping过程。
3.hadoop和spark的都是并行计算,那么他们有什么相同和区别?
先说一说区别: 1.内存/磁盘运算 2.计算模型
首先,两者的一个显著不同就是Spark是基于内存计算的,存取数据比Hadoop的MapReduce快很多。
其次,hadoop基于MapReduce计算模型,Spark采用的是基于DAG的计算模型,MapReduce的处理过程具有一定时序性的约束,而Spark可以达到高度并行。
相同:
本质上,Spark和Hadoop都是采用MapReduce模型进行计算的。
4.Kafka集群规模,消费速度?
一般中小型公司为10个节点上下,消费速度为20M左右。
5.HDFS上传文件的流程。
假设上传256M的文件。
1)由客户端向NameNode节点发出“上传文件”的请求,NameNode向Client返回可以存数据的DataNode信息,这里遵循机架感知策略
2)客户端首先对文件分块,Hdp1为64M/块,Hdp2为128M/块,假设使用Hdp2,则分为两块
3)依据可用DataNode信息,将数据流式的发送给DataNode,同时会复制到其他机器以满足副本数配置
4)DataNode向Client/NameNode通知“数据块传输完毕”,直到所有数据块传输完毕,DataNode向NameNode报告。
6.了解ZooKeeper吗?介绍一下它,它的选举机制和搭建也要介绍到。
1)ZooKeeper是一个分布式的协调服务,它广泛应用于数据的发布订阅、命名服务、配置中心、分布式锁、集群管理、选主与服务发现等等。这不仅得益于ZK类文件系统的数据模型和基于Watcher机制的分布式事件通知,也得益于ZK特殊的高容错数据一致性协议。
2)Hadoop生态系统的软件的搭建一般都有固定的流程。
首先,配置环境变量。我会配置一个<SOFTWARE>_HOME以便于进入,有些软件例如Hdp和Zk、Spark在软件的使用当中就会使用到HADOOP_HOME、ZOOKEEPER_HOME、SPARK_HOME这些环境变量。
其次,修改配置文件。配置文件的格式一般以xml或者.properties文件为主。有一些主机会配置slaves,还有xxx.config/xxx.cfg文件,本质就是变量的赋值。
在ZK中,一般首先需要配置slaves(从机节点)以及dataDir还有server的位置。
对于dataDir,需要创建并放入一个myid,其中存放本机ZK节点的序号X
server.X=host:port1:port2 其中port1指的是内部选举用的端口,port2是指ZK通信端口
7.ZK如何实现分布式锁?
可以参考我的另一篇: https://www.cnblogs.com/yosql473/p/10766149.html
8.ZK如何实现单机多节点?
三个配置文件 zoo1.cfg zoo2.cfg zoo3.cfg 对应三个数据目录
然会分别启动
9.端口问题:你简历中软件的默认端口是什么:
tomcat 8080 hadoop: hdfs 50070 yarn 8088
mysql: 3306 mongodb: 27017 redis:6379
spark:7077 sparkUI:8080 zookeeper: 2181 stormUI:8081
kafka(broker):9092 hbaseUI 1.0以前:60010 以后:16010
10.说一下你对hadoop生态圈的认识。
hadoop生态圈基于hdfs大数据的存储方案,提供了全栈的大数据处理方案,例如离线批处理为MapReduce以及Hive完成,当然这个过程需要调度Oozie。实时交互由HBase以及Impala(正在孵化中)完成。流计算由Storm完成。除此之外提供了Sqoop转库工具、Flume大吞吐量的采集工具以及分布式协调服务ZK、Kafka分布式MQ、Hue图形化查询器等软件,除此之外还提供了Mahout机器学习引擎。spark计算引擎的出现导致spark生态圈的出现,其中只是一些三大业务场景中spark计算引擎的使用,批处理由Spark本身的Core就可以完成、实时交互由Spark SQL进行查询、流计算由Spark Streaming进行完成。除此之外还提供了MLib、GraphX这些计算工具方便进行计算。
11.说一下你对yarn的理解。
TODO
12.数据的来源方式。
1)来源于日志:
日志分为系统日志、服务器日志以及应用日志,系统日志包括软件系统的日志、数据库日志、操作系统日志、中间件日志、容器日志等。
服务器日志为Apache、Nginx、tomcat或IIS产生的日志。
应用日志包括行为日志、用户日志。
这些日志可以通过flume采集、从日志系统获取,或者日志系统和数据分析平台统一从Kafka中获取。
2)来源于行为:
当行为产生时,我们可以通过前端埋点的方式直接发往大数据业务系统。
3)来源于采集:
我们可以通过爬虫分布式的采集数据或者提取API获得数据并发往大数据业务系统。
13.Kafka是怎么设计的?
1)如果我们想设计一个消息中间件,我们首先需要有一个队列,而且需要这个队列中的数据能够被顺序消费,因此每条数据都有index,在Kafka中也会保存一个offset偏移量,方便续读取
这样的系统至少有两个问题: 1.单队列吞吐量低 2.单队列中存放了各色业务的数据
2)为解决上面两个问题,我们首先需要用多队列解决吞吐量的问题,然后抽象出topic,以便将不同的业务数据存放在不同的topic当中,每个topic对应一条逻辑队列。
这样结合一下,一个topic就有一条逻辑队列,逻辑队列又会被拆成多条物理队列,方便并发访问。
这样的中间件解决了两个问题。但是仍然有问题. 中间件宕了怎么办?依然有可用性的问题,因此我们必须考虑数据备用节点和备份的问题。
3)Kafka采用Broker集群,借用ZK管理,解决数据备用节点的问题。数据备份还是采用多副本的机制
总结一下,Kafka采用的机制与HDFS有些类似,它采用的是分布式分块冗余存储,一个topic对应一条逻辑队列,这条逻辑队列会被分成多个分区,多个分区分布式冗余的存储在多个Broker节点之上。
为了防止节点宕机,Kafka采用 分布式存储 、 持久化数据 、 冗余存储 机制来避免数据断流和丢失。

[大数据面试题]hadoop核心知识点的更多相关文章
- [大数据面试题]storm核心知识点
1.storm基本架构 storm的主从分别为Nimbus.Supervisor,工作进程为Worker. 2.计算模型 Storm的计算模型分为Spout和Bolt,Spout作为管口.Bolt作为 ...
- 大数据时代之hadoop(五):hadoop 分布式计算框架(MapReduce)
大数据时代之hadoop(一):hadoop安装 大数据时代之hadoop(二):hadoop脚本解析 大数据时代之hadoop(三):hadoop数据流(生命周期) 大数据时代之hadoop(四): ...
- 大数据测试之初识Hadoop
大数据测试之初识Hadoop POPTEST老李认为测试开发工程师是面向测试的开发,也就是说,写代码就是为完成测试任务服务的,写自动化测试(性能自动化,功能自动化,安全自动化,接口自动化等等)的cas ...
- 一篇了解大数据架构及Hadoop生态圈
一篇了解大数据架构及Hadoop生态圈 阅读建议,有一定基础的阅读顺序为1,2,3,4节,没有基础的阅读顺序为2,3,4,1节. 第一节 集群规划 大数据集群规划(以CDH集群为例),参考链接: ht ...
- 有必要了解的大数据知识(一) Hadoop
前言 之前工作中,有接触到大数据的需求,虽然当时我们体系有专门的大数据部门,但是由于当时我们中台重构,整个体系的开发量巨大,共用一个大数据部门,人手已经忙不过来,没法办,为了赶时间,我自己负责的系统的 ...
- 有必要了解的大数据知识(二) Hadoop
前言 接上文,复习整理大数据相关知识点,这章节从MapReduce开始... MapReduce介绍 MapReduce思想在生活中处处可见.或多或少都曾接触过这种思想.MapReduce的思想核心是 ...
- ASP.NET + SqlSever 大数据解决方案 PK HADOOP
半个月前看到博客园有人说.NET不行那篇文章,我只想说你们有时间去抱怨不如多写些实在的东西. 1.SQLSERVER优点和缺点? 优点:支持索引.事务.安全性以及容错性高 缺点:数据量达到100万以 ...
- 【大数据】了解Hadoop框架的基础知识
介绍 此Refcard提供了Apache Hadoop,这是最流行的软件框架,可使用简单的高级编程模型实现大型数据集的分布式存储和处理.我们将介绍Hadoop最重要的概念,描述其架构,指导您如何开始使 ...
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
随机推荐
- IconFont --阿里巴巴矢量库
超多的图标网站,可自己设置颜色,然后下载. IconFont --阿里巴巴矢量库
- Redis详解与常见问题解决方案
Redis简介 redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合).zset(sor ...
- 《高性能Mysql》解读---Mysql的事务和多版本并发
1.base:ACID属性,并发控制 2.MySql事务的隔离级别有哪些,含义是什么? 3.锁知多少,读锁,写锁,排他锁,共享锁,间隙锁,乐观锁,悲观锁. 4.Mysql的事务与锁有什么关联?MySq ...
- CentOS 7 内核优化
[root@DaMoWang ~]# vim /etc/sysctl.conf #关闭ipv6 net.ipv6.conf.all.disable_ipv6 = net.ipv6.conf.def ...
- web攻击之xss(一)
1,xss简介 跨站脚本攻击(Cross Site Scripting),为了不和层叠样式表(Cascading Style Sheets, CSS)的缩写混淆,故将跨站脚本攻击缩写为XSS.恶意攻击 ...
- Angular4 websocket通讯
- 【DOM练习】百度历史搜索栏
HTML: <!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <t ...
- Linux实战
1.root用户无法删除文件 [root@VM_0_9_centos .ssh]# lsattr authorized_keys ----i----------- authorized_keys ls ...
- 继承 派生 super()经典类 新式类
'''1什么是继承? 继承一种新建类的方式,在python中支持一个儿子继承多个爹 新建的类称为子类的或者派生类 父类有可以称为基类或者超类 子类会‘遗传’父类的属性 2 为什么要用继承 减少代码冗余 ...
- JZ2440学习笔记之链接文件lds
如果在Linux环境下用arm-linux-gcc来编译arm程序,需要编写链接文件lds: 1. 运行地址=链接地址,表示代码在SDRAM中执行的地址,如果程序中有对某部分代码执行过搬运,需要在ld ...