Spark环境搭建(六)-----------sprk源码编译
想要搭建自己的Hadoop和spark集群,尤其是在生产环境中,下载官网提供的安装包远远不够的,必须要自己源码编译spark才行。
环境准备:
1,Maven环境搭建,版本Apache Maven 3.3.9,jar包管理工具;
2,JDK环境搭建,版本1.7.0_51,hadoop由Java编写;
3 ,Scala 环境搭建,版本 2.11.8,spark是scala编写的;
4 ,spark 源码包,从官网选择

编译前准备:
0,Maven ,JDK,Scala解压安装,并加入到环境变量中
1,wget 源码到~/source 并且 tar -zxvf spark-2.1.0.tgz
2 , 加入cdh仓库,在spark-2.1.0/pom.xml
<repository>
<id>cloudera-releases</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
编译:
1) 根据自己的机器实际情况,合理的分配内存给JVM, 通过命令:export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=512m"
2) 在spark-2.1.0/下通过命令:
./dev/make-distribution.sh --name 2.6.0-cdh5.7.0 --tgz -Pyarn -Phadoop-2.6 -Phive -Phive-thriftserver -Dhadoop.version=2.6.0-cdh5.7.0
或者通过mvn方式直接编译(maven编译完成没有一个大的完整的包使用)
./build/mvn -Pyarn -Phadoop-2.6 -Dhadoop.version=2.6.0-cdh5.7.0 -Phive -Phive-thriftserver -DskipTests clean package
这个编译过程大约两个小时,更网速有关,有的Jar包需要翻墙下载,所有时间教长
编译完成会在spark-2.1.0/下产生一个spark-2.1.0-bin-2.6.0-cdh5.7.0.tgz包,将它解压,加入到环境变量就算结束了。
解读编译命令:
./build/mvn -Pyarn -Phadoop-2.6 -Dhadoop.version=2.6.0 -DskipTests clean package
1) -Dhadoop.version=2.6.0
在编译命令上在外部指定(修改)<hadoop.version>2.2.0</hadoop.version> 默认的2.2.0 改为2.6.0
在spark根目录下的pom.xml文件中,部分源码如下,可以看出默认的hadoop版本是2.2.0
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF8</project.reporting.outputEncoding>
<java.version>1.7</java.version>
<maven.version>3.3.9</maven.version>
<sbt.project.name>spark</sbt.project.name>
<slf4j.version>1.7.16</slf4j.version>
<log4j.version>1.2.17</log4j.version>
<hadoop.version>2.2.0</hadoop.version>
<protobuf.version>2.5.0</protobuf.version>
<yarn.version>${hadoop.version}</yarn.version>
<flume.version>1.6.0</flume.version>
<zookeeper.version>3.4.5</zookeeper.version>
<curator.version>2.4.0</curator.version>
<hive.group>org.spark-project.hive</hive.group>
<!-- Version used in Maven Hive dependency -->
<hive.version>1.2.1.spark2</hive.version>
<!-- Version used for internal directory structure -->
<hive.version.short>1.2.1</hive.version.short>
<derby.version>10.12.1.1</derby.version>
<parquet.version>1.8.1</parquet.version>
<hive.parquet.version>1.6.0</hive.parquet.version>
<jetty.version>9.2.16.v20160414</jetty.version>
<javaxservlet.version>3.1.0</javaxservlet.version>
</properties>
2) -Phadoop-2.6
在源码pom.xml中,通过外部指定的<profile>的id来选择编译时所用到的<profile>
源码中,-Phadoop-2.6来选择id为hadoop-2.6的<profile>作为编译条件
<profile>
<id>hadoop-2.2</id>
<!-- SPARK-7249: Default hadoop profile. Uses global properties. -->
</profile> <profile>
<id>hadoop-2.3</id>
<properties>
<hadoop.version>2.3.0</hadoop.version>
<jets3t.version>0.9.3</jets3t.version>
</properties>
</profile> <profile>
<id>hadoop-2.4</id>
<properties>
<hadoop.version>2.4.1</hadoop.version>
<jets3t.version>0.9.3</jets3t.version>
</properties>
</profile> <profile>
<id>hadoop-2.6</id>
<properties>
<hadoop.version>2.6.4</hadoop.version>
<jets3t.version>0.9.3</jets3t.version>
<zookeeper.version>3.4.6</zookeeper.version>
<curator.version>2.6.0</curator.version>
</properties>
</profile> <profile>
<id>hadoop-2.7</id>
<properties>
<hadoop.version>2.7.3</hadoop.version>
<jets3t.version>0.9.3</jets3t.version>
<zookeeper.version>3.4.6</zookeeper.version>
3) -Phive -Phive-thriftserver和-Pyarn,同上面选择hadoop的profile一样,编译时加上对hive和yarn的支持
4) -DskipTests clean package 编译过程中,跳过测试,实例包等,不进行编译;
./dev/make-distribution.sh  --name 2.6.0-cdh5.7.0 --tgz -Pyarn -Phadoop-2.6 -Phive -Phive-thriftserver -Dhadoop.version=2.6.0-cdh5.7.0
--name 2.6.0-cdh5.7.0 --tgz -Pyarn -Phadoop-2.6 -Phive -Phive-thriftserver -Dhadoop.version=2.6.0-cdh5.7.0
1)./dev/make-distribution.sh 通过在dev下的make-distribution.sh编译
2)--name 2.6.0-cdh5.7.0 --tgz 编译后打成一个名为spark-2.1.0-bin-2.6.0-cdh5.7.0.tgz 的tgz包
2)-Pyarn -Phadoop-2.6 -Phive -Phive-thriftserver 同maven一样,通过id选择<profile>中的内容,进而支持某个模块
3)-Dhadoop.version=2.6.0-cdh5.7.0 指定hadoop的版本
make-distribution.sh源码阅读
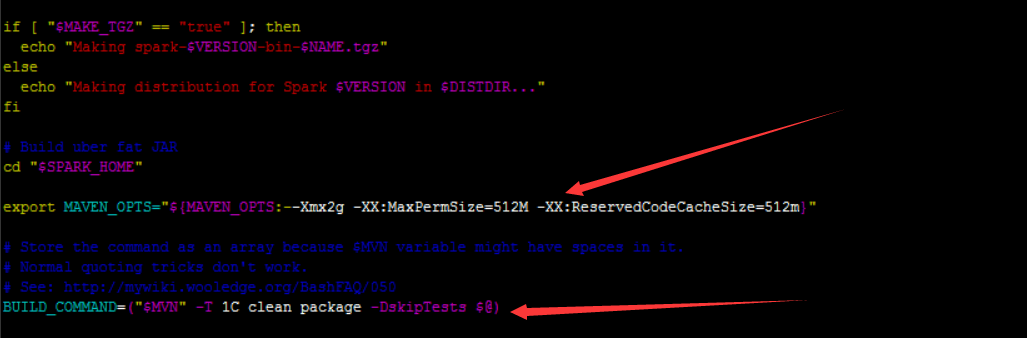
在上图中可以看出,编译脚本已经加入export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=512m",并且加入了跳过检测包的语句

--mvn 后面添加在编译mvn时选择的版本和<profile>

打包命令,以及报名的命名规则
到此,spark源码记录完毕。
Spark环境搭建(六)-----------sprk源码编译的更多相关文章
- Hive On Spark环境搭建
Spark源码编译与环境搭建 Note that you must have a version of Spark which does not include the Hive jars; Spar ...
- Ubantu16.04进行Android 8.0源码编译
参考这篇博客 经过测试,8.0源码下载及编译之后,占用100多G的硬盘空间,尽量给ubantu系统多留一些硬盘空间,如果后续需要在编译好的源码上进行开发,需要预留更多的控件,为了防止后续出现文件权限问 ...
- 保姆级教程——Ubuntu16.04 Server下深度学习环境搭建:安装CUDA8.0,cuDNN6.0,Bazel0.5.4,源码编译安装TensorFlow1.4.0(GPU版)
写在前面 本文叙述了在Ubuntu16.04 Server下安装CUDA8.0,cuDNN6.0以及源码编译安装TensorFlow1.4.0(GPU版)的亲身经历,包括遇到的问题及解决办法,也有一些 ...
- CentOS6.5下搭建LAMP环境(源码编译方式)
CentOS 6.5安装配置LAMP服务器(Apache+PHP5+MySQL) 学习PHP脚本编程语言之前,必须先搭建并熟悉开发环境,开发环境有很多种,例如LAMP ,WAMP,MAMP等.这里我介 ...
- ffmpeg源码编译环境搭建
ffmpeg是视频开发最常用到的开源软件,FFmpeg功能强大,用途广泛,提供几乎所有你能够想到的与视频开发相关的操作,许多商业软件都以ffmpeg为基础进行开发定制. FFmpeg: FFmpeg ...
- 源码编译搭建LNMP环境
LNMP源码编译 1.LNMP介绍 LNMP=Linux Nginx Mysql PHP Nginx ("engine x") 是一个高性能的 HTTP 和 反向代理 服务器.Ng ...
- 搭建LNAMP环境(二)- 源码安装Nginx1.10
上一篇:搭建LNAMP环境(一)- 源码安装MySQL5.6 1.yum安装编译nginx需要的包 yum -y install pcre pcre-devel zlib zlib-devel ope ...
- 搭建LNAMP环境(一)- 源码安装MySQL5.6
1.yum安装编译mysql需要的包 yum -y install gcc-c++ make cmake bison-devel ncurses-devel perl 2.为mysql创建一个新的用户 ...
- 搭建LNAMP环境(三)- 源码安装Apache2.4
上一篇:搭建LNAMP环境(二)- 源码安装Nginx1.10 1.yum安装编译apache需要的包(如果已经安装,可跳过此步骤) yum -y install pcre pcre-devel zl ...
随机推荐
- Thunk
Thunk https://en.wikipedia.org/wiki/Thunk In computer programming, a thunk is a subroutine used to i ...
- iTOP-4418开发板所用核心板研发7寸/10.1寸安卓触控一体机
iTOP-4418开发板所用核心板研发7寸/10.1寸安卓触控一体机 作为重中之重的电源管理选型,经多方对比测试最终选用AXP228,并得到原厂肯定 预留锂电池接口,内置充放电电路及电量计,可轻松搞定 ...
- JAVA进阶18
间歇性混吃等死,持续性踌躇满志系列-------------第18天 1.飞机游戏小项目 ①创建窗口 package cn.xfj.game; import javax.swing.*; import ...
- Linux环境 tp5.1 Could not open input file: think
服务器命令行执行:php /项目目录/think queue:listen 报如下错误 初步分析是 queue:listen 在代码中要重启一个work进程,用到了think ,导致找不到该文件的路 ...
- C#创建控制台项目引用Topshelf的方式,部署windows服务。
上一篇是直接创建windows service服务来处理需求.调试可能会麻烦一点.把里面的逻辑写好了.然后受大神指点,用Topshelf会更好一些. 来公司面试的时候问我,为什么要用stringbui ...
- C语言尝试在不同源文件中调用程序段
基于Visual Studio 2015 将下面两个cpp文件置于同一源文件目录下即可 源.cpp #include <stdio.h> int main() { extern int s ...
- java--序列化和反序列化
一.序列化 java序列化的过程是把对象转换为字节序列的过程 序列化的两种用途: 1)把对象的字节序列永久保存大搜硬盘上,通常存放到一个文件中 2)在网络上传送对象的字节序列 jdk中的序列化API: ...
- Linux禁止ping、开启ping设置
Linux默认是允许Ping响应的,系统是否允许Ping由2个因素决定的:A.内核参数,B.防火墙,需要2个因素同时允许才能允许Ping,2个因素有任意一个禁Ping就无法Ping. 具体的配置方法如 ...
- 消息队列(MQ)
1. 分类: 获取消息方式:A. push(推)方式:优点——可以尽可能快地将消息发送给消费者,缺点——如果消费者处理能力跟不上,消费者的缓冲区可能会溢出: B. pull(拉)方式:优点—— ...
- centos防火墙控制与转发端口
一.使用防火墙 systemctl控制防火墙 systemctl status/start/stop/restart firewalld 如开启防火墙: $ systemctl start firew ...