Numpy 系列(十一)- genfromtxt函数
官方文档
Enthought offical tutorial: numpy.genfromtxt
A very common file format for data file is comma-separated values (CSV), or related formats such as TSV (tab-separated values). To read data from such files into Numpy arrays we can use the numpy.genfromtxt function.
案例说明
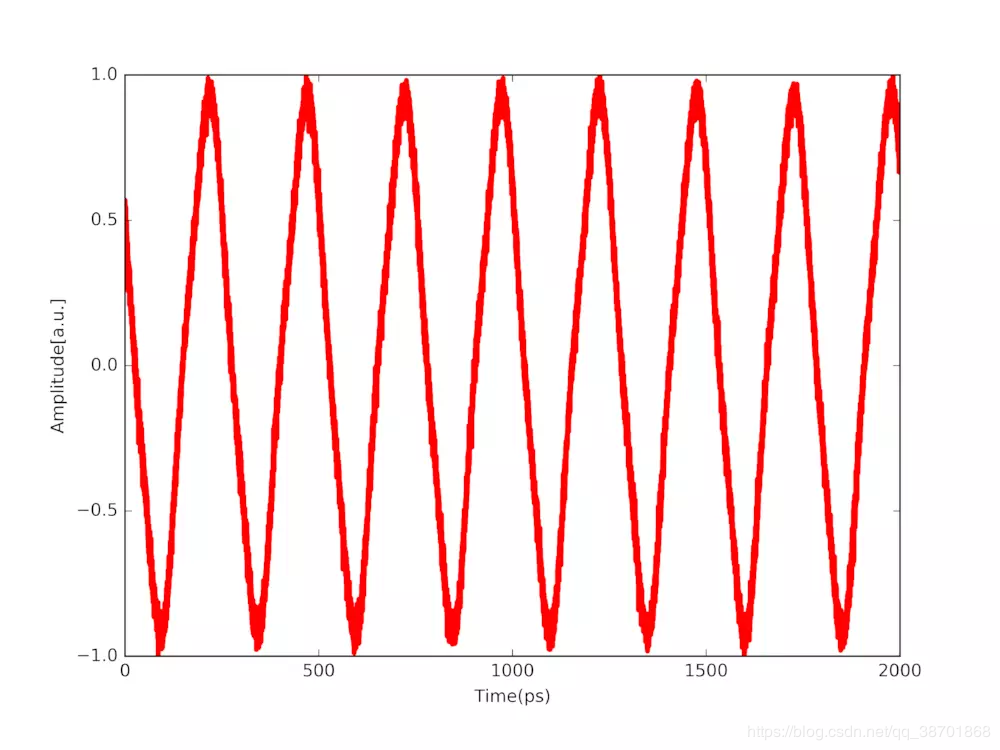
我们以数字示波器采集的实验产生的三角波 (triangular waveform) 为例,它是包含数据信息的表头,以 .txt 格式存储的文本文件。
Type: raw
Points: 16200
Count: 1
...
X Units: second
Y Units: Volt
XY Data:
2.4000000E-008, 1.4349E-002
2.4000123E-008, 1.6005E-002
2.4000247E-008, 1.5455E-002
2.4000370E-008, 1.5702E-002
2.4000494E-008, 1.5147E-002
...
之前,在Python科学计算——File I/O中提到了两种方法读取上述的数据,它们共同点是将数据存储在列表中,正如开头所说,列表在处理大量数据时是非常缓慢的。那么,我们就来看一看 numpy.genfromtxt 如何大显身手。
代码示例
为了得到我们需要的有用数据,我们有两个硬的要求: (1) 跳过表头信息;(2) 区分横纵坐标。
import numpy as np
data = np.genfromtxt('waveform.txt',delimiter=',',skip_header=18)
**delimiter: the str used to separate data. 横纵坐标以 ',' 分割,因此给 delimiter 传入 ','。skip_header: ** the number of lines to skip at the beginning of the file. 有用数据是从19行开始的,因此给 skip_header 传入 18。
print(data[0:3,0], data[0:3,1])
因为读入的是二维数据,因此利用 numpy 二维数据的切片方式 (Index slicing) 输出各自的前三个数据验证是否读取正确:
[ 2.40000000e-08 2.40001230e-08 2.40002470e-08]
[ 0.014349 0.016005 0.015455]
对数据进行归一化处理后,调用 Matplotlib 画图命令,就可得到图像如下:
import matplotlib.pyplot as plt
fig, axes = plt.subplots(figsize=(8,6))
axes.plot(x, y, 'r', linewidth=3)
axes.set_xlabel('Time(ps)')
axes.set_ylabel('Amplitude[a.u.]')
fig.savefig("triangular.png", dpi=600)
补充
numpy.genformtxt( ) 函数提供了众多的入参,实现不同格式数据的读取,详情可参考:numpy.genfromtxt
此外,numpy 中还提供了将数据存储为 CSV 格式的函数 numpy.savetxt( ),详情可参考:numpy.savetxt
Stay hungry, Stay foolish. -- Steve Jobs
定义输入
genfromtxt的唯一强制参数是数据的源。它可以是字符串,字符串列表或生成器。如果提供了单个字符串,则假定它是本地或远程文件或具有read方法的打开的类文件对象的名称,例如文件或StringIO.StringIO对象。如果提供了字符串列表或返回字符串的生成器,则每个字符串在文件中被视为一行。当传递远程文件的URL时,文件将自动下载到当前目录并打开。
识别的文件类型是文本文件和归档。目前,该函数识别gzip和bz2(bzip2)归档。归档的类型从文件的扩展名确定:如果文件名以'.gz'结尾,则需要一个gzip归档;如果以'bz2'结尾,则假设存在一个bzip2档案。
将行拆分为列
delimiter 参数
一旦文件被定义并打开阅读,genfromtxt将每个非空行拆分为一个字符串序列。刚刚跳过空行或注释行。delimiter关键字用于定义拆分应如何进行。
通常,单个字符标记列之间的间隔。例如,逗号分隔文件(CSV)使用逗号(,)或分号(;)作为分隔符:
import numpy as np
from io import BytesIO data = b"1, 2, 3\n4, 5, 6"
np.genfromtxt(BytesIO(data), delimiter=",")
Out[334]:
array([[1., 2., 3.],
[4., 5., 6.]])
另一个常见的分隔符是"\t",表格字符。但是,我们不限于单个字符,任何字符串都会做。默认情况下,genfromtxt假定delimiter=None,表示该行沿白色空格(包括制表符)分割,并且连续的空格被视为单个白色空格。
或者,我们可能处理固定宽度的文件,其中列被定义为给定数量的字符。在这种情况下,我们需要将delimiter设置为单个整数(如果所有列具有相同的大小)或整数序列(如果列可以具有不同的大小):
data = b"1, 2, 3\n4, 5, 6"
np.genfromtxt(BytesIO(data), delimiter=",")
Out[334]:
array([[1., 2., 3.],
[4., 5., 6.]])
data = b" 1 2 3\n 4 5 67\n890123 4"
np.genfromtxt(BytesIO(data), delimiter=3)
Out[336]:
array([[ 1., 2., 3.],
[ 4., 5., 67.],
[890., 123., 4.]])
data = B"123456789\n 4 7 9\n 4567 9"
np.genfromtxt(BytesIO(data), delimiter=(4, 3, 2))
Out[338]:
array([[1234., 567., 89.],
[ 4., 7., 9.],
[ 4., 567., 9.]])
autostrip参数
默认情况下,当一行被分解为一系列字符串时,各个条目不会被删除前导或尾随的空格。通过将可选参数autostrip设置为True的值,可以覆盖此行为:
data = b"1, abc , 2\n 3, xxx, 4"
np.genfromtxt(BytesIO(data), delimiter=",", dtype="|S5")
Out[340]:
array([[b'1', b' abc ', b' 2'],
[b'3', b' xxx', b' 4']], dtype='|S5')
np.genfromtxt(BytesIO(data), delimiter=",", dtype="|S5", autostrip=True)
Out[341]:
array([[b'1', b'abc', b'2'],
[b'3', b'xxx', b'4']], dtype='|S5')
omments参数
可选参数comments用于定义标记注释开始的字符串。默认情况下,genfromtxt假设为comments='#'。注释标记可以出现在该行的任何地方。忽略注释标记后的任何字符:
data = b"""#
# Skip me !
# Skip me too !
1, 2
3, 4
5, 6 #This is the third line of the data
7, 8
# And here comes the last line
9, 0
"""
np.genfromtxt(BytesIO(data), comments="#", delimiter=",")
Out[345]:
array([[1., 2.],
[3., 4.],
[5., 6.],
[7., 8.],
[9., 0.]])
注意
这种行为有一个显着的例外:如果可选参数names=True,则将首先检查第一条注释的行的名称。
忽略某些行或某些列
skip_header 和 skip_footer 参数
文件中头的存在可能阻碍数据处理。在这种情况下,我们需要使用skip_header可选参数。此参数的值必须是对应于在执行任何其他操作之前在文件开头处跳过的行数的整数。类似地,我们可以使用skip_footer属性并赋予n的值来跳过文件的最后n行:
>>> data = "\n".join(str(i) for i in range(10))
>>> np.genfromtxt(BytesIO(data.encode()))
array([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])
>>> np.genfromtxt(BytesIO(data.encode()),
... skip_header=3, skip_footer=5)
array([ 3., 4.])
默认情况下,skip_header=0和skip_footer=0,表示不跳过任何行。
usecols 参数
在某些情况下,我们对数据的所有列不感兴趣,但只对其中的几个列感兴趣。我们可以使用usecols参数选择要导入哪些列。此参数接受单个整数或对应于要导入的列的索引的整数序列。记住,按照惯例,第一列的索引为0。负整数的行为与常规Python负指数相同。
例如,如果我们只想导入第一列和最后一列,可以使用usecols =(0, -1):
>>> data = b"1 2 3\n4 5 6"
>>> np.genfromtxt(BytesIO(data), usecols=(0, -1))
array([[ 1., 3.],
[ 4., 6.]])
如果列具有名称,我们还可以通过将其名称作为字符串序列或逗号分隔字符串的形式,将其名称指定给usecols参数来选择要导入的列:
>>> data = b"1 2 3\n4 5 6"
>>> np.genfromtxt(BytesIO(data),
... names="a, b, c", usecols=("a", "c"))
array([(1.0, 3.0), (4.0, 6.0)],
dtype=[('a', '<f8'), ('c', '<f8')])
>>> np.genfromtxt(BytesIO(data),
... names="a, b, c", usecols=("a, c"))
array([(1.0, 3.0), (4.0, 6.0)],
dtype=[('a', '<f8'), ('c', '<f8')])
选择数据类型
控制如何将从文件中读取的字符串序列转换为其他类型的主要方法是设置dtype参数。此参数的可接受值为:
单个类型,例如
dtype=float。除非已使用names参数将名称与每个列相关联(参见下文),否则输出将为具有给定dtype的2D。请注意,dtype=float是genfromtxt的默认值。类型序列,例如
dtype =(int, float, float)。逗号分隔的字符串,例如
dtype="i4,f8,|S3"。具有两个键
'names'和'formats'的字典。元组的序列
(名称, 类型),例如dtype = [('A', t4 > int), ('B', float)]。现有的
numpy.dtype对象。特殊值
None。在这种情况下,列的类型将从数据本身确定(见下文)。
在所有情况下,但第一个,输出将是具有结构化dtype的1D数组。此dtype具有与序列中的项目一样多的字段。字段名称使用names关键字定义。
当dtype=None时,每个列的类型从其数据中迭代确定。我们首先检查字符串是否可以转换为布尔值(即,如果字符串在小写字符串中匹配true或false);那么它是否可以转换为整数,然后到一个float,然后到一个复杂,最终到一个字符串。可以通过修改StringConverter类的默认映射器来更改此行为。
为方便起见,提供了选项dtype=None。但是,它明显慢于明确设置dtype。
设置 names
names 参数
处理表格数据时的一种自然方法是为每个列分配一个名称。第一种可能性是使用显式结构化dtype,如前所述:
>>> data = BytesIO(b"1 2 3\n 4 5 6")
>>> np.genfromtxt(data, dtype=[(_, int) for _ in "abc"])
array([(1, 2, 3), (4, 5, 6)],
dtype=[('a', '<i8'), ('b', '<i8'), ('c', '<i8')])
另一个更简单的可能性是使用names关键字与一系列字符串或逗号分隔的字符串:
>>> data = BytesIO(b"1 2 3\n 4 5 6")
>>> np.genfromtxt(data, names="A, B, C")
array([(1.0, 2.0, 3.0), (4.0, 5.0, 6.0)],
dtype=[('A', '<f8'), ('B', '<f8'), ('C', '<f8')])
在上面的示例中,我们使用了默认情况下,dtype=float的事实。通过给出一系列名称,我们将输出强制为结构化的dtype。
我们有时可能需要从数据本身定义列名称。在这种情况下,我们必须使用值True的names关键字。然后将从第一行(在skip_header之后)读取名称,即使行被注释掉:
>>> data = BytesIO(b"So it goes\n#a b c\n1 2 3\n 4 5 6")
>>> np.genfromtxt(data, skip_header=1, names=True)
array([(1.0, 2.0, 3.0), (4.0, 5.0, 6.0)],
dtype=[('a', '<f8'), ('b', '<f8'), ('c', '<f8')])
names的默认值为None。如果我们为关键字赋予任何其他值,新名称将覆盖我们可能已使用dtype定义的字段名称:
>>> data = BytesIO(b"1 2 3\n 4 5 6")
>>> ndtype=[('a',int), ('b', float), ('c', int)]
>>> names = ["A", "B", "C"]
>>> np.genfromtxt(data, names=names, dtype=ndtype)
array([(1, 2.0, 3), (4, 5.0, 6)],
dtype=[('A', '<i8'), ('B', '<f8'), ('C', '<i8')])
defaultfmt 参数
If names=None but a structured dtype is expected, names are defined with the standard NumPy default of "f%i", yielding names like f0, f1 and so forth:
>>> data = BytesIO(b"1 2 3\n 4 5 6")
>>> np.genfromtxt(data, dtype=(int, float, int))
array([(1, 2.0, 3), (4, 5.0, 6)],
dtype=[('f0', '<i8'), ('f1', '<f8'), ('f2', '<i8')])
同样,如果我们没有给出足够的名称来匹配dtype的长度,那么将使用此默认模板定义缺少的名称:
>>> data = BytesIO(b"1 2 3\n 4 5 6")
>>> np.genfromtxt(data, dtype=(int, float, int), names="a")
array([(1, 2.0, 3), (4, 5.0, 6)],
dtype=[('a', '<i8'), ('f0', '<f8'), ('f1', '<i8')])
我们可以使用defaultfmt参数覆盖此默认值,它采用任何格式字符串:
>>> data = BytesIO(b"1 2 3\n 4 5 6")
>>> np.genfromtxt(data, dtype=(int, float, int), defaultfmt="var_%02i")
array([(1, 2.0, 3), (4, 5.0, 6)],
dtype=[('var_00', '<i8'), ('var_01', '<f8'), ('var_02', '<i8')])
注意
我们需要记住,defaultfmt仅在预期某些名称但未定义时使用。
Validating names
具有结构化dtype的NumPy数组也可以视为recarray,其中可以像访问属性一样访问字段。因此,我们可能需要确保字段名称不包含任何空格或无效字符,或者不符合标准属性的名称(例如size或shape),这将会混淆解释器。genfromtxt接受三个可选参数,对名称提供更精细的控制:
deletechars
提供一个字符串,组合必须从名称中删除的所有字符。默认情况下,无效字符为
〜!@#$%^&amp; *() - = +〜\ |]} [{';: /?.& &lt;。excludelist提供要排除的名称列表,例如
return,file,print...如果输入名称之一是此列表的一部分,将在其后面添加下划线字符('_')。case_sensitive
是否名称应区分大小写(case_sensitive=True),转换为大写(case_sensitive=False或case_sensitive='upper')或小写(case_sensitive='lower')。
转换调整
converters 参数
通常,定义一个dtype足以定义如何转换字符串序列。然而,有时可能需要一些额外的控制。例如,我们可能要确保格式YYYY/MM/DD的日期被转换为datetime对象,或者像xx%已正确转换为0到1之间的浮点值。在这种情况下,我们应该使用converters参数定义转换函数。
此参数的值通常是具有列索引或列名作为键和转换函数作为值的字典。这些转换函数可以是实际函数或lambda函数。在任何情况下,他们应该只接受一个字符串作为输入,只输出所需类型的一个元素。
在以下示例中,第二列从表示百分比的字符串转换为0到1之间的浮点数:
>>> convertfunc = lambda x: float(x.strip(b"%")))/100.
>>> data = b"1, 2.3%, 45.\n6, 78.9%, 0"
>>> names = ("i", "p", "n")
>>> # General case .....
>>> np.genfromtxt(BytesIO(data), delimiter=",", names=names)
array([(1.0, nan, 45.0), (6.0, nan, 0.0)],
dtype=[('i', '<f8'), ('p', '<f8'), ('n', '<f8')])
我们需要记住,默认情况下,dtype=float。因此,对于第二列期望浮点数。但是,字符串'2.3%'和' 78.9% >无法转换为浮点数,我们最终改为使用np.nan。让我们现在使用转换器:
>>> # Converted case ...
>>> np.genfromtxt(BytesIO(data), delimiter=",", names=names,
... converters={1: convertfunc})
array([(1.0, 0.023, 45.0), (6.0, 0.78900000000000003, 0.0)],
dtype=[('i', '<f8'), ('p', '<f8'), ('n', '<f8')])
使用第二列的名称("p")作为键而不是索引(1)可以获得相同的结果:
>>> # Using a name for the converter ...
>>> np.genfromtxt(BytesIO(data), delimiter=",", names=names,
... converters={"p": convertfunc})
array([(1.0, 0.023, 45.0), (6.0, 0.78900000000000003, 0.0)],
dtype=[('i', '<f8'), ('p', '<f8'), ('n', '<f8')])
转换器还可用于为缺少的条目提供默认值。在以下示例中,转换器convert将剥离的字符串转换为相应的浮点型或如果字符串为空,转换为-999。我们需要从空格中显式删除字符串,因为它不是默认做的:
>>> data = b"1, , 3\n 4, 5, 6"
>>> convert = lambda x: float(x.strip() or -999)
>>> np.genfromtxt(BytesIO(data), delimiter=",",
... converters={1: convert})
array([[ 1., -999., 3.],
[ 4., 5., 6.]])
使用 missing 和 filling values
在我们尝试导入的数据集中可能会丢失某些条目。在前面的示例中,我们使用转换器将空字符串转换为浮点数。然而,用户定义的转换器可能迅速地变得难以管理。
genfromtxt函数提供了另外两个补充机制:missing_values参数用于识别丢失的数据,第二个参数filling_values这些丢失的数据。
missing_values
默认情况下,任何空字符串都标记为缺少。我们还可以考虑更复杂的字符串,例如"N/A"或"???"以表示丢失或无效的数据。missing_values参数接受三种类型的值:
一个字符串或逗号分隔的字符串
此字符串将用作所有列的缺少数据的标记
字符串序列
在这种情况下,每个项目按顺序与列相关联。
一本字典
字典的值是字符串或字符串序列。相应的键可以是列索引(整数)或列名(字符串)。此外,特殊键None可用于定义适用于所有列的默认值。
filling_values
我们知道如何识别丢失的数据,但我们仍然需要为这些丢失的条目提供一个值。默认情况下,此值根据此表从预期的dtype确定:
预期类型
默认
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
我们可以使用filling_values可选参数对缺失值的转换进行更精细的控制。像missing_values一样,此参数接受不同类型的值:
单个值
这将是所有列的默认值
一个值序列
每个条目将是相应列的默认值
一本字典
每个键可以是列索引或列名,并且相应的值应该是单个对象。我们可以使用特殊键None为所有列定义默认值。
在下面的例子中,我们假设缺少的值在第一列中用"N/A"标记,"???"在第三列。我们希望将这些缺失值转换为0,如果它们出现在第一列和第二列中,则转换为-999,如果它们出现在最后一列中:
>>> data = b"N/A, 2, 3\n4, ,???"
>>> kwargs = dict(delimiter=",",
... dtype=int,
... names="a,b,c",
... missing_values={0:"N/A", 'b':" ", 2:"???"},
... filling_values={0:0, 'b':0, 2:-999})
>>> np.genfromtxt(BytesIO(data), **kwargs)
array([(0, 2, 3), (4, 0, -999)],
dtype=[('a', '<i8'), ('b', '<i8'), ('c', '<i8')])
usemask
我们还可能希望通过构造布尔掩码来跟踪丢失数据的出现,其中缺少数据的True条目,否则False。为此,我们只需要将可选参数usemask设置为True(默认值为False)。输出数组将是MaskedArray。
Shortcut functions
除了genfromtxt,numpy.lib.io模块提供了从genfromtxt派生的几个方便函数。这些函数的工作方式与原始函数相同,但它们具有不同的默认值。
ndfromtxt
- 始终设置
usemask=False。输出始终为标准numpy.ndarray。
mafromtxt
- 始终设置
usemask=True。输出始终为MaskedArray
recfromtxt
- 返回标准
numpy.recarray(ifusemask=False)或MaskedRecords数组(如果usemaske=True。默认dtype为dtype=None,表示每个列的类型将自动确定。
recfromcsv
- 类似于
recfromtxt,但使用默认的delimiter=","。
Numpy 系列(十一)- genfromtxt函数的更多相关文章
- Numpy函数学习--genfromtxt函数
genfromtxt函数 今天学习时遇到了genfromtxt函数 world_alcohol = numpy.genfromtxt("world_alcohol.txt",del ...
- SQL Server 2008空间数据应用系列十一:提取MapInfo地图数据中的空间数据解决方案
原文:SQL Server 2008空间数据应用系列十一:提取MapInfo地图数据中的空间数据解决方案 友情提示,您阅读本篇博文的先决条件如下: 1.本文示例基于Microsoft SQL Serv ...
- 深入理解javascript函数系列第一篇——函数概述
× 目录 [1]定义 [2]返回值 [3]调用 前面的话 函数对任何一门语言来说都是一个核心的概念.通过函数可以封装任意多条语句,而且可以在任何地方.任何时候调用执行.在javascript里,函数即 ...
- 深入理解javascript函数系列第二篇——函数参数
× 目录 [1]arguments [2]内部属性 [3]函数重载[4]参数传递 前面的话 javascript函数的参数与大多数其他语言的函数的参数有所不同.函数不介意传递进来多少个参数,也不在乎传 ...
- SSE 系列内置函数中的 shuffle 函数
SSE 系列内置函数中的 shuffle 函数 邮箱: quarrying@qq.com 博客: http://www.cnblogs.com/quarryman/ 发布时间: 2017年04月18日 ...
- java基础解析系列(十一)---equals、==和hashcode方法
java基础解析系列(十一)---equals.==和hashcode方法 目录 java基础解析系列(一)---String.StringBuffer.StringBuilder java基础解析系 ...
- 数据分析与展示——NumPy数据存取与函数
NumPy库入门 NumPy数据存取和函数 数据的CSV文件存取 CSV文件 CSV(Comma-Separated Value,逗号分隔值)是一种常见的文件格式,用来存储批量数据. np.savet ...
- 操作 numpy 数组的常用函数
操作 numpy 数组的常用函数 where 使用 where 函数能将索引掩码转换成索引位置: indices = where(mask) indices => (array([11, 12, ...
- SQL语句(十一)函数查询
(十一)函数查询 1. 聚合函数 对一组值进行计算,得到一个返回值 SUM(), 求和 AVG(), 求平均 MIN(), 求最小 MAX(), 求最大 COUNT(), 计数,即个数 --例1 求所 ...
随机推荐
- Docker: 构建Nginx,PHP,Tomcat基础镜像
Usage: docker build [OPTIONS] PATH | URL | - [flags] Options: -t, --tag list # 镜像名称 -f, --file strin ...
- 《精通Spring+4.x++企业应用开发实战》读后感
引言 还记得大三时上培训班的是时候,当时的培训老师说自己是本地讲解spring最好的讲师,但是后来等我实习了看了<Spring 3.x 企业应用开发实战>以及后续版本<精通Sprin ...
- Django contenttypes 组件
contenttypes组件 介绍 Django包含一个contenttypes应用程序(app),可以跟踪Django项目中安装的所有模型(Model),提供用于处理模型的高级通用接口. Conte ...
- web框架开发-Django的Forms组件
校验字段功能 针对一个实例:用户注册. 模型:models.py class UserInfo(models.Model): name=models.CharField(max_length=32) ...
- NSSM安装服务
NSSM是一个服务封装程序,它可以将普通exe程序封装成服务,使之像windows服务一样运行.同类型的工具还有微软自己的srvany,不过nssm更加简单易用,并且功能强大.它的特点如下: 支持普通 ...
- SkylineGlobe 7.0.1 & 7.0.2版本Web开发 如何实现对三维模型和地形的剖切展示
现在很多三维项目中,不仅仅要用到三维地形,正射影像和矢量数据,还会融合到各种三维模型,包括传统的3DMax手工建模,BIM,倾斜摄影自动建模,激光点云模型,三维地质体模型等等. 三维平台首先要做的是把 ...
- plsql连接数据库出现乱码
在windows中创 建一个名为"NLS_LANG"的系统环境变量,设置其值为"SIMPLIFIED CHINESE_CHINA.ZHS16GBK", sele ...
- pyspider安装出现问题参考
File "c:\users\13733\appdata\local\programs\python\python37\lib\site-packages\pyspider\run.py&q ...
- SqlServer如何判断字段中是否含有汉字?
--/* --unicode编码范围: --汉字:[0x4e00,0x9fa5](或十进制[19968,40869]) --数字:[0x30,0x39](或十进制[48, 57]) --小写字母:[0 ...
- echo与print,var_dump()和print_r()的区别
1.echo 和 print 的区别 共同点:首先echo 和 print 都不是严格意义上的函数,他们都是 语言结构;他们都只能输出 字符串,整型跟int型浮点型数据.不能打印复合型和资源型数据: ...