[Reinforcement Learning] 马尔可夫决策过程
在介绍马尔可夫决策过程之前,我们先介绍下情节性任务和连续性任务以及马尔可夫性。
情节性任务 vs. 连续任务
- 情节性任务(Episodic Tasks),所有的任务可以被可以分解成一系列情节,可以看作为有限步骤的任务。
- 连续任务(Continuing Tasks),所有的任务不能分解,可以看作为无限步骤任务。
马尔可夫性
引用维基百科对马尔可夫性的定义:
马尔可夫性:当一个随机过程在给定现在状态及所有过去状态情况下,其未来状态的条件概率分布仅依赖于当前状态。
用数学形式表示如下:
A state \(S_t\) is Markov if and only if
\[P[S_{t+1}|S_t] = P[S_{t+1}|S_1, ..., S_t]\]
马尔可夫过程
马尔可夫过程即为具有马尔可夫性的过程,即过程的条件概率仅仅与系统的当前状态相关,而与它的过去历史或未来状态都是独立、不相关的。
马尔可夫奖赏过程
马尔可夫奖赏过程(Markov Reward Process,MRP)是带有奖赏值的马尔可夫过程,其可以用一个四元组表示 \(<S, P, R, \gamma>\)。
- \(S\) 为有限的状态集合;
- \(P\) 为状态转移矩阵,\(P_{ss^{'}} = P[S_{t+1} = s^{'}|S_t = s]\);
- \(R\) 是奖赏函数;
- \(\gamma\) 为折扣因子(discount factor),其中 \(\gamma \in [0, 1]\)
奖赏函数
在 \(t\) 时刻的奖赏值 \(G_t\):
\[G_t = R_{t+1} + \gamma R_{t+2} + ... = \sum_{k=0}^{\infty}\gamma^{k}R_{t+k+1}\]
Why Discount
关于Return的计算为什么需要 \(\gamma\) 折扣系数。David Silver 给出了下面几条的解释:
- 数学表达的方便
- 避免陷入无限循环
- 远期利益具有一定的不确定性
- 在金融学上,立即的回报相对于延迟的回报能够获得更多的利益
- 符合人类更看重眼前利益的特点
价值函数
状态 \(s\) 的长期价值函数表示为:
\[v(s) = E[G_t | S_t = s] \]
Bellman Equation for MRPs
\[
\begin{align}
v(s)
&= E[G_t|S_t=s]\\
&= E[R_{t+1} + \gamma R_{t+2} + ... | S_t = s]\\
&= E[R_{t+1} + \gamma (R_{t+2} + \gamma R_{t+3} ... ) | S_t = s]\\
&= E[R_{t+1} + \gamma G_{t+1} | S_t = s]\\
&= E[R_{t+1} + \gamma v(s_{t+1}) | S_t = s]
\end{align}
\]
下图为MRP的 backup tree 示意图:
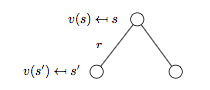
注:backup tree 中的白色圆圈代表状态,黑色圆点对应动作。
根据上图可以进一步得到:
\[v(s) = R_s + \gamma \sum_{s' \in S}P_{ss'}v(s')\]
马尔可夫决策过程
马尔可夫决策过程(Markov Decision Process,MDP)是带有决策的MRP,其可以由一个五元组构成 \(<S, A, P, R, \gamma>\)。
- \(S\) 为有限的状态集合;
- \(A\) 为有限的动作集合;
- \(P\) 为状态转移矩阵,\(P_{ss^{'}}^{a} = P[S_{t+1} = s^{'}|S_t = s,A_t=a]\);
- \(R\) 是奖赏函数;
- \(\gamma\) 为折扣因子(discount factor),其中 \(\gamma \in [0, 1]\)
我们讨论的MDP一般指有限(离散)马尔可夫决策过程。
策略
策略(Policy)是给定状态下的动作概率分布,即:
\[\pi(a|s) = P[A_t = a|S_t = a]\]
状态价值函数 & 最优状态价值函数
给定策略 \(\pi\) 下状态 \(s\) 的状态价值函数(State-Value Function)\(v_{\pi}(s)\):
\[v_{\pi}(s) = E_{\pi}[G_t|S_t = s]\]
状态 \(s\) 的最优状态价值函数(The Optimal State-Value Function)\(v_{*}(s)\):
\[v_{*}(s) = \max_{\pi}v_{\pi}(s)\]
动作价值函数 & 最优动作价值函数
给定策略 \(\pi\),状态 \(s\),采取动作 \(a\) 的动作价值函数(Action-Value Function)\(q_{\pi}(s, a)\):
\[q_{\pi}(s, a) = E_{\pi}[G_t|S_t = s, A_t = a]\]
状态 \(s\) 下采取动作 \(a\) 的最优动作价值函数(The Optimal Action-Value Function)\(q_{*}(s, a)\):
\[q_{*}(s, a) = \max_{\pi}q_{\pi}(s, a)\]
最优策略
如果策略 \(\pi\) 优于策略 \(\pi^{'}\):
\[\pi \ge \pi^{'} \text{ if } v_{\pi}(s) \ge v_{\pi^{'}}(s), \forall{s}\]
最优策略 \(v_{*}\) 满足:
- \(v_{*} \ge \pi, \forall{\pi}\)
- \(v_{\pi_{*}}(s) = v_{*}(s)\)
- \(q_{\pi_{*}}(s, a) = q_{*}(s, a)\)
如何找到最优策略?
可以通过最大化 \(q_{*}(s, a)\) 来找到最优策略:
\[
v_{*}(a|s) =
\begin{cases}
& 1 \text{ if } a=\arg\max_{a \in A}q_{*}(s,a)\\
& 0 \text{ otherwise }
\end{cases}
\]
对于MDP而言总存在一个确定的最优策略,而且一旦我们获得了\(q_{*}(s,a)\),我们就能立即找到最优策略。
Bellman Expectation Equation for MDPs
我们先看下状态价值函数 \(v^{\pi}\)。
状态 \(s\) 对应的 backup tree 如下图所示:

根据上图可得:
\[v_{\pi}(s) = \sum_{a \in A}\pi(a|s)q_{\pi}(s, a) \qquad (1)\]
再来看动作价值函数 \(q_{\pi}(s, a)\)。
状态 \(s\),动作 \(a\) 对应的 backup tree 如下图所示:
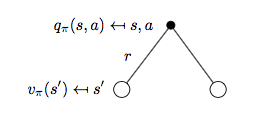
因此可得:
\[q_{\pi}(s,a)=R_s^a + \gamma \sum_{s'\in S}P_{ss'}^a v_{\pi}(s') \qquad (2)\]
进一步细分 backup tree 再来看 \(v^{\pi}\) 与 \(q_{\pi}(s, a)\) 对应的表示形式。
细分状态 \(s\) 对应的 backup tree 如下图所示:
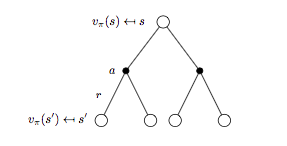
将式子(2)代入式子(1)可以进一步得到 \(v_{\pi}(s)\) 的贝尔曼期望方程:
\[v_{\pi}(s) = \sum_{a \in A} \pi(a | s) \Bigl( R_s^a + \gamma \sum_{s'\in S}P_{ss'}^a v_{\pi}(s') \Bigr) \qquad (3)\]
细分状态 \(s\),动作 \(a\) 对应的 backup tree 如下图所示:
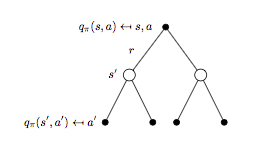
将式子(1)代入式子(2)可以得到 \(q_{\pi}(s,a)\) 的贝尔曼期望方程:
\[q_{\pi}(s,a)=R_s^a + \gamma \sum_{s'\in S}P_{ss'}^a \Bigl(\sum_{a' \in A}\pi(a'|s')q_{\pi}(s', a') \Bigr) \qquad (4)\]
Bellman Optimality Equation for MDPs
同样我们先看 \(v_{*}(s)\):
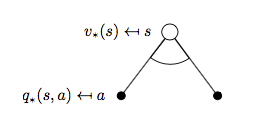
对应可以写出公式:
\[v_{*}(s) = \max_{a}q_{*}(s, a) \qquad (5)\]
再来看\(q_{*}(s, a)\):
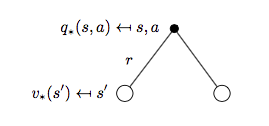
对应公式为:
\[q_{*}(s, a) = R_s^a + \gamma \sum_{s'\in S}P_{ss'}^a v_{*}(s') \qquad (6)\]
同样的套路获取 \(v_{*}(s)\) 对应的 backup tree 以及贝尔曼最优方程:
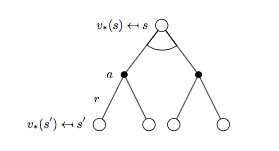
贝尔曼最优方程:
\[v_{*}(s) = \max_{a} \Bigl( R_s^a + \gamma \sum_{s'\in S}P_{ss'}^a v_{*}(s') \Bigr) \qquad (7)\]
\(q_{*}(s, a)\) 对应的 backup tree 以及贝尔曼最优方程:
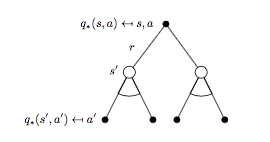
对应的贝尔曼最优方程:
\[R_s^a + \gamma \sum_{s'\in S}P_{ss'}^a\max_{a}q_{*}(s, a) \qquad (8)\]
贝尔曼最优方程特点
- 非线性(non-linear)
- 通常情况下没有解析解(no closed form solution)
贝尔曼最优方程解法
- Value Iteration
- Policy Iteration
- Sarsa
- Q-Learning
MDPs的相关扩展问题
- 无限MDPs/连续MDPs
- 部分可观测的MDPs
- Reward无折扣因子形式的MDPs/平均Reward形式的MDPs
Reference
[1] 维基百科-马尔可夫性
[2] Reinforcement Learning: An Introduction, Richard S. Sutton and Andrew G. Barto, 2018
[3] David Silver's Homepage
[Reinforcement Learning] 马尔可夫决策过程的更多相关文章
- David Silver强化学习Lecture2:马尔可夫决策过程
课件:Lecture 2: Markov Decision Processes 视频:David Silver深度强化学习第2课 - 简介 (中文字幕) 马尔可夫过程 马尔可夫决策过程简介 马尔可夫决 ...
- 【cs229-Lecture16】马尔可夫决策过程
之前讲了监督学习和无监督学习,今天主要讲“强化学习”. 马尔科夫决策过程:Markov Decision Process(MDP) 价值函数:value function 值迭代:value iter ...
- 【RL系列】马尔可夫决策过程——状态价值评价与动作价值评价
请先阅读上两篇文章: [RL系列]马尔可夫决策过程中状态价值函数的一般形式 [RL系列]马尔可夫决策过程与动态编程 状态价值函数,顾名思义,就是用于状态价值评价(SVE)的.典型的问题有“格子世界(G ...
- 【RL系列】马尔可夫决策过程——Jack‘s Car Rental
本篇请结合课本Reinforcement Learning: An Introduction学习 Jack's Car Rental是一个经典的应用马尔可夫决策过程的问题,翻译过来,我们就直接叫它“租 ...
- 转:增强学习(二)----- 马尔可夫决策过程MDP
1. 马尔可夫模型的几类子模型 大家应该还记得马尔科夫链(Markov Chain),了解机器学习的也都知道隐马尔可夫模型(Hidden Markov Model,HMM).它们具有的一个共同性质就是 ...
- 增强学习(二)----- 马尔可夫决策过程MDP
1. 马尔可夫模型的几类子模型 大家应该还记得马尔科夫链(Markov Chain),了解机器学习的也都知道隐马尔可夫模型(Hidden Markov Model,HMM).它们具有的一个共同性质就是 ...
- 强化学习-MDP(马尔可夫决策过程)算法原理
1. 前言 前面的强化学习基础知识介绍了强化学习中的一些基本元素和整体概念.今天讲解强化学习里面最最基础的MDP(马尔可夫决策过程). 2. MDP定义 MDP是当前强化学习理论推导的基石,通过这套框 ...
- 【RL系列】马尔可夫决策过程中状态价值函数的一般形式
请先阅读上一篇文章:[RL系列]马尔可夫决策过程与动态编程 在上一篇文章里,主要讨论了马尔可夫决策过程模型的来源和基本思想,并以MAB问题为例简单的介绍了动态编程的基本方法.虽然上一篇文章中的马尔可夫 ...
- 马尔可夫决策过程MDP
1. 马尔可夫模型的几类子模型 马尔科夫链(Markov Chain),了解机器学习的也都知道隐马尔可夫模型(Hidden Markov Model,HMM).它们具有的一个共同性质就是马尔可夫性(无 ...
随机推荐
- django 问题综合
orm部分 本篇文章我会持续更新,把开发中遇到的一切orm相关的问题都放在这里 mysql索引报错 使用django 的orm,数据库用的mysql,在使用makemigrations和migrate ...
- 【转】网页禁止后退键BackSpace的JavaScript实现(兼容IE、Chrome、Firefox、Opera)
var forbidBackSpace = function (e) { // 获取event对象 var ev = e || window.event; // 获取事件源 var obj = ev. ...
- 黑阔主流攻防之不合理的cookie验证方式
最近博主没事干中(ZIZUOZISHOU),于是拿起某校的习题研究一番,名字很6,叫做黑阔主流攻防习题 虚拟机环境经过一番折腾,配置好后,打开目标地址:192.168.5.155 如图所示 这里看出题 ...
- Raneto部署知识库平台&支持中文搜索
目录 环境 更新软件包 部署 Raneto 知识库平台 安装 Node 环境 安装 node 管理工具 查看 node 列表 安装需要的Node版本 使用 淘宝NPM源 git 使用代理设置,大陆地区 ...
- Shell 全局变量、环境变量和局部变量
Shell 变量的作用域(Scope),就是 Shell 变量的有效范围(可以使用的范围). 在不同的作用域中,同名的变量不会相互干涉,就好像 A 班有个叫小明的同学,B 班也有个叫小明的同学,虽然他 ...
- python 操作Excel文件
1 安装xlrd.xlwt.xlutils cmd下输入: pip install xlrd #读取excel pip install xlwt #写入excel pi ...
- leetcode 678. Valid Parenthesis String
678. Valid Parenthesis String Medium Given a string containing only three types of characters: '(', ...
- 接口Set
Set接口简介 java.util.Set 接口和 java.util.List 接口一样,同样继承自 Collection 接口,它与 Collection 接口中的方法基本一致,并没有对 Coll ...
- java中String的final类原因
public final class String implements java.io.Serializable, Comparable<String>, CharSequence { ...
- VS编程,C#串口通讯,通过串口读取数据的一种方法
一.可能需要的软件:1.虚拟串口vspd(Virtual Serial Port Driver,用来在电脑上虚拟出一对串口,模拟通讯. 2.友善串口调试助手,用来发送.读取数据. 二.思路1.查询本机 ...