MySQL 大数据量使用limit分页,随着页码的增大,查询效率越低下。
数据表结构
CREATE TABLE `ad_keyword` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`plan_goods_id` int(11) DEFAULT NULL,
`impr_num` int(11) DEFAULT NULL,
`click_num` int(11) DEFAULT NULL,
`total_spend` int(11) DEFAULT NULL,
`pay_gmv` int(11) DEFAULT NULL,
`orders_num` int(11) DEFAULT NULL,
`roi` double DEFAULT NULL,
`clk_rate` double DEFAULT NULL,
`word` varchar(200) DEFAULT NULL,
`date` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `word_index` (`word`),
KEY `date_index` (`date`),
KEY `ad_id_index` (`plan_goods_id`)
) ENGINE=InnoDB AUTO_INCREMENT=127133688 DEFAULT CHARSET=utf8;
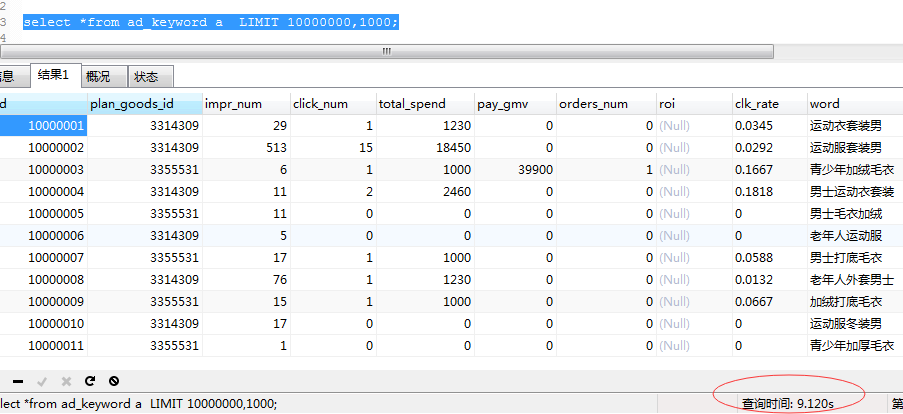
select *from ad_keyword a LIMIT 10000000,1000;
数据库表中数据大概为1.2亿,每次查询都要花上10多秒。而且分页大小是1000.
优化后:
select *from ad_keyword a JOIN (select id from ad_keyword LIMIT 10000000,1000) b on a.id=b.id ;
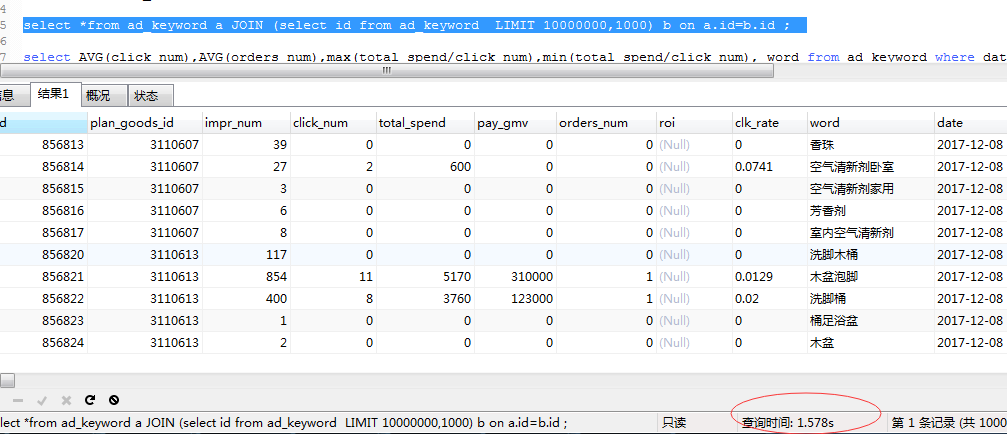
从中我们也能总结出两件事情:
1)limit语句的查询时间与起始记录的位置成正比
2)mysql的limit语句是很方便,但是对记录很多的表并不适合直接使用。
2. 对limit分页问题的性能优化方法
利用表的覆盖索引来加速分页查询
我们都知道,利用了索引查询的语句中如果只包含了那个索引列(覆盖索引),那么这种情况会查询很快。
因为利用索引查找有优化算法,且数据就在查询索引上面,不用再去找相关的数据地址了,这样节省了很多时间。另外Mysql中也有相关的索引缓存,在并发高的时候利用缓存就效果更好了。
在我们的例子中,我们知道id字段是主键,自然就包含了默认的主键索引。
这次我们之间查询最后一页的数据(利用覆盖索引,只包含id列)只用了1.57秒。
MySQL 大数据量使用limit分页,随着页码的增大,查询效率越低下。的更多相关文章
- mysql大数据量使用limit分页,随着页码的增大,查询效率越低下
1. 直接用limit start, count分页语句, 也是我程序中用的方法: select * from product limit start, count当起始页较小时,查询没有性能问题 ...
- mysql大数据量下的分页
mysql大数据量使用limit分页,随着页码的增大,查询效率越低下. 测试实验 1. 直接用limit start, count分页语句, 也是我程序中用的方法: select * from p ...
- mysql大数据量之limit优化
背景:当数据库里面的数据达到几百万条上千万条的时候,如果要分页的时候(不过一般分页不会有这么多),如果业务要求这么做那我们需要如何解决呢?我用的本地一个自己生产的一张表有五百多万的表,来进行测试,表名 ...
- MySQL大数据量分页查询
mysql大数据量使用limit分页,随着页码的增大,查询效率越低下. 测试实验 1. 直接用limit start, count分页语句, 也是我程序中用的方法: select * from p ...
- 【1】MySQL大数据量分页查询方法及其优化
---方法1: 直接使用数据库提供的SQL语句---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N---适应场景: 适用于数据量较少的情况(元组百/千 ...
- MySQL大数据量分页查询方法及其优化
MySQL大数据量分页查询方法及其优化 ---方法1: 直接使用数据库提供的SQL语句---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N---适 ...
- MySQL大数据量分页性能优化
mysql大数据量使用limit分页,随着页码的增大,查询效率越低下. 测试实验 1. 直接用limit start, count分页语句, 也是我程序中用的方法: select * from p ...
- MySQL 大数据量快速插入方法和语句优化
MySQL大数据量快速插入方法和语句优化是本文我们主要要介绍的内容,接下来我们就来一一介绍,希望能够让您有所收获! INSERT语句的速度 插入一个记录需要的时间由下列因素组成,其中的数字表示大约比例 ...
- Mysql 大数据量导入程序
Mysql 大数据量导入程序<?xml:namespace prefix = o ns = "urn:schemas-microsoft-com:office:office" ...
随机推荐
- Android 6.0 7.0 8.0 一个简单的app内更新版本-okgo app版本更新
登陆时splash初始页调用接口检查app版本.如有更新,使用okGo的文件下载,保存到指定位置,调用Android安装apk. <!-- Android 8.0 (Android O)为了针对 ...
- 翻译:GLSL的顶点位移贴图
翻译:GLSL的顶点位移贴图 翻译自: Vertex Displacement Mapping using GLSL 译者: FreeBlues 说明: 之所以选择这篇文档, 是因为现在但凡提到位移贴 ...
- java Apache common-io 讲解
Apache common-io用户指南 用户指南 Commons-io 包含utility classes,endian classes,line iterator,file filters,fil ...
- jmeter编写beanshell及内置方法的使用
(一)BeanShell简介 BeanShell是一个小型嵌入式Java源代码解释器,具有对象脚本语言特性,能够动态地执行标准JAVA语法,并利用在JavaScript和Perl中常见的的松散类型.命 ...
- IOC轻量级框架之Autofac
http://www.cnblogs.com/WeiGe/p/3871451.html http://www.cnblogs.com/hkncd/archive/2012/11/21/2780041. ...
- vue 2.0使用笔记
assets被排除在热重载监听目录之外,一些公共样式文件最好不要放在这个目录 webpack默认没有装less-loader,要.vue文件中使用less,需要npm install less les ...
- nginx 跨域配置
server { listen 80; server_name b.com; location /{ if ( $http_referer ~* (a.com|b.com|c.com) ) { Acc ...
- 【疑点】<p></p>标签为什么不能包含块级标签?还有哪些特殊的HTML标签?
最近,在码代码的时候,就是下面的这段代码,我犯了一个很不起眼,但犯了就致命的BUG. <body> <p> <ol> <li>Hello</li& ...
- 关于注入抽象类报could not autowire field的问题
昨天工作中遇到了一个很奇葩的问题,之前一直都没考虑过抽象类这块,一直用的注入接口实现类: 先看下错误: 因为在类中注入了一个抽象类,之前只有一个继承子类,所以没问题,这里要说一下抽象类的实例化: 抽象 ...
- 采用dlopen、dlsym、dlclose加载动态链接库【总结】【转】
转自:https://www.cnblogs.com/Anker/p/3746802.html 1.前言 为了使程序方便扩展,具备通用性,可以采用插件形式.采用异步事件驱动模型,保证主程序逻辑不变,将 ...