Python3语法详解
一.下载安装
1.1Python下载
Python官网:https://www.python.org/
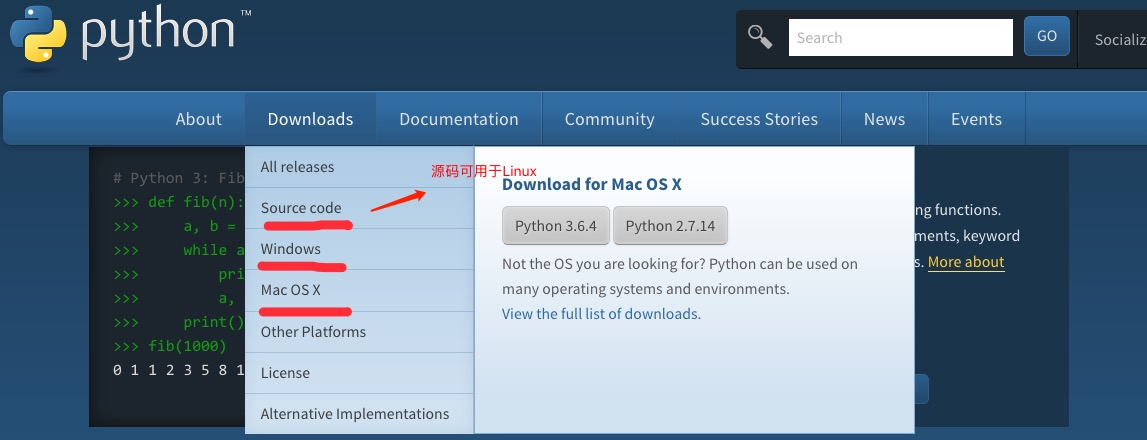
1.2Python安装
1.2.1 Linux 平台安装
以下为在Unix & Linux 平台上安装 Python 的简单步骤:
- 打开WEB浏览器访问https://www.python.org/downloads/source/
- 选择适用于Unix/Linux的源码压缩包。
- 下载及解压压缩包。
- 如果你需要自定义一些选项修改Modules/Setup
- 执行 ./configure 脚本
- make
- make install
执行以上操作后,Python会安装在 /usr/local/bin 目录中,Python库安装在/usr/local/lib/pythonXX,XX为你使用的Python的版本号。
1.2.2 Window 平台安装
以下为在 Window 平台上安装 Python 的简单步骤:
- 打开 WEB 浏览器访问https://www.python.org/downloads/windows/
- 在下载列表中选择Window平台安装包,包格式为:python-XYZ.msi 文件 , XYZ 为你要安装的版本号。
- 要使用安装程序 python-XYZ.msi, Windows系统必须支持Microsoft Installer 2.0搭配使用。只要保存安装文件到本地计算机,然后运行它,看看你的机器支持MSI。Windows XP和更高版本已经有MSI,很多老机器也可以安装MSI。
- 下载后,双击下载包,进入Python安装向导,安装非常简单,你只需要使用默认的设置一直点击"下一步"直到安装完成即可。
1.2.3 环境变量配置
在 Unix/Linux 设置环境变量
- 在 csh shell: 输入
setenv PATH "$PATH:/usr/local/bin/python"
, 按下"Enter"。
- 在 bash shell (Linux): 输入
export PATH="$PATH:/usr/local/bin/python"
,按下"Enter"。
- 在 sh 或者 ksh shell: 输入
PATH="$PATH:/usr/local/bin/python"
, 按下"Enter"。
注意: /usr/local/bin/python 是 Python 的安装目录。
在 Windows 设置环境变量
在环境变量中添加Python目录:
在命令提示框中(cmd) : 输入
path=%path%;C:\Python
按下"Enter"。
注意: C:\Python 是Python的安装目录。
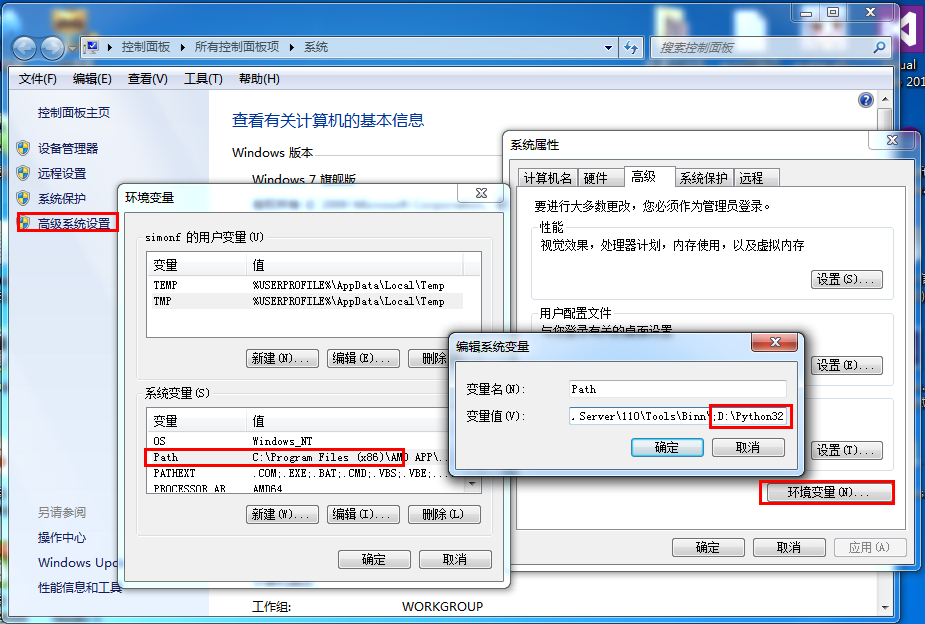
也可以通过以下方式设置:
- 右键点击"计算机",然后点击"属性"
- 然后点击"高级系统设置"
- 选择"系统变量"窗口下面的"Path",双击即可!
- 然后在"Path"行,添加python安装路径即可(我的D:\Python32),所以在后面,添加该路径即可。 ps:记住,路径直接用分号";"隔开!
- 最后设置成功以后,在cmd命令行,输入命令"python",就可以有相关显示。
Python 环境变量
下面几个重要的环境变量,它应用于Python:
| 变量名 | 描述 |
|---|---|
| PYTHONPATH | PYTHONPATH是Python搜索路径,默认我们import的模块都会从PYTHONPATH里面寻找。 |
| PYTHONSTARTUP | Python启动后,先寻找PYTHONSTARTUP环境变量,然后执行此变量指定的文件中的代码。 |
| PYTHONCASEOK | 加入PYTHONCASEOK的环境变量, 就会使python导入模块的时候不区分大小写. |
| PYTHONHOME | 另一种模块搜索路径。它通常内嵌于的PYTHONSTARTUP或PYTHONPATH目录中,使得两个模块库更容易切换。 |
1.2.4 运行Python
有三种方式可以运行Python:
1、交互式解释器:
你可以通过命令行窗口进入python并开在交互式解释器中开始编写Python代码。
你可以在Unix,DOS或任何其他提供了命令行或者shell的系统进行python编码工作。
或者
C:>python # Windows/DOS
以下为Python命令行参数:
| 选项 | 描述 |
|---|---|
| -d | 在解析时显示调试信息 |
| -O | 生成优化代码 ( .pyo 文件 ) |
| -S | 启动时不引入查找Python路径的位置 |
| -V | 输出Python版本号 |
| -X | 从 1.6版本之后基于内建的异常(仅仅用于字符串)已过时。 |
| -c cmd | 执行 Python 脚本,并将运行结果作为 cmd 字符串。 |
| file | 在给定的python文件执行python脚本。 |
2、命令行脚本
在你的应用程序中通过引入解释器可以在命令行中执行Python脚本,如下所示:
或者
C:>python script.py # Windows/DOS
注意:在执行脚本时,请检查脚本是否有可执行权限。
3、集成开发环境(IDE:Integrated Development Environment): PyCharm
PyCharm 是由 JetBrains 打造的一款 Python IDE,支持 macOS、 Windows、 Linux 系统。
PyCharm 功能 : 调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制……
PyCharm 下载地址 : https://www.jetbrains.com/pycharm/download/
PyCharm 安装地址:http://www.runoob.com/w3cnote/pycharm-windows-install.html

继续下一章之前,请确保您的环境已搭建成功。如果你不能够建立正确的环境,那么你就可以从您的系统管理员的帮助。
二.使用Python解释器
2.1调用解释器
Python解释器通常安装/usr/local/bin/python3.6 在那些可用的机器上; 放入/usr/local/binUnix shell的搜索路径可以通过输入命令来启动它:
python3.6
到了shell。[1]由于选择解释器所在的目录是一个安装选项,其他地方也是可能的; 请咨询您当地的Python大师或系统管理员。(例如,/usr/local/python是一个受欢迎的替代位置。)
在Windows机器上,通常会放置Python安装 C:\Python36,但是在运行安装程序时可以更改此设置。要将此目录添加到路径,可以在DOS框中的命令提示符中键入以下命令:
set path=%path%;C:\python36
在主提示符下键入文件结束字符(Control-D在Unix上,Control-Z在Windows上)会导致解释器以零退出状态退出。如果这不起作用,您可以通过键入以下命令退出解释器:quit()。
解释器的行编辑功能包括支持readline的系统上的交互式编辑,历史替换和代码完成。也许最快的检查是否支持命令行编辑是输入 Control-P你得到的第一个Python提示。如果发出哔哔声,则可以进行命令行编辑; 有关键的介绍,请参阅附录交互式输入编辑和历史替换。如果没有发生任何事情,或者是否^P回显,则命令行编辑不可用; 你只能使用退格键从当前行中删除字符。
解释器的操作有点像Unix shell:当使用连接到tty设备的标准输入调用时,它以交互方式读取和执行命令; 当使用文件名参数或文件作为标准输入调用时,它会从该文件中读取并执行脚本。
启动解释器的第二种方法是执行命令中的语句,类似于shell的 选项。由于Python语句通常包含空格或shell特有的其他字符,因此通常建议使用单引号引用 命令。python -c command [arg] ...-c
一些Python模块也可用作脚本。可以使用这些来调用它们 ,它执行模块的源文件,就像在命令行中拼写出它的全名一样。python -m module [arg] ...
使用脚本文件时,有时可以运行脚本并在之后进入交互模式。这可以通过-i 在脚本之前传递来完成。
命令行和环境中描述了所有命令行选项。
2.1.1 参数传递
当解释器知道时,脚本名称和其后的附加参数将变为字符串列表并分配给模块中的argv 变量sys。您可以通过执行来访问此列表。清单的长度至少为一; 当没有给出脚本和参数时,是一个空字符串。当脚本名称为 (表示标准输入)时,设置为。使用 命令时,设置为。使用 模块时, 将其设置为所定位模块的全名。命令或模块之后找到 的选项不会被Python解释器的选项处理使用,而是留在import syssys.argv[0]'-'sys.argv[0]'-'-c sys.argv[0]'-c'-m sys.argv[0]-c -m sys.argv 用于处理的命令或模块。
2.1.2 交互模式
当从tty读取命令时,解释器被称为处于交互模式。在这种模式下,它会提示下一个带有主要提示的命令,通常是三个大于号(>>>); 对于连续行,它会提示辅助提示,默认为三个点(...)。在打印第一个提示之前,解释程序会打印一条欢迎消息,说明其版本号和版权声明:
$ python3.6
Python 3.6 (default, Sep 16 2015, 09:25:04)
[GCC 4.8.2] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
进入多线构造时需要延续线。举个例子,看看这个if声明:
>>> the_world_is_flat = True
>>> if the_world_is_flat:
... print("Be careful not to fall off!")
...
Be careful not to fall off!
有关交互模式的更多信息,请参阅交互模式。
2.2 解释器及其环境
2.2.1 源代码编码
默认情况下,Python源文件被视为以UTF-8编码。在该编码中,世界上大多数语言的字符可以在字符串文字,标识符和注释中同时使用 - 尽管标准库仅使用ASCII字符作为标识符,这是任何可移植代码都应遵循的约定。要正确显示所有这些字符,编辑器必须识别文件是UTF-8,并且必须使用支持文件中所有字符的字体。
要声明非默认编码,应添加一个特殊注释行作为文件的第一行。语法如下:
# -*- coding: encoding -*-
其中encoding是codecsPython支持的有效编码之一。
例如,要声明要使用Windows-1252编码,源代码文件的第一行应为:
# -*- coding: cp1252 -*-
第一行规则的一个例外是源代码以UNIX“shebang”行开头 。在这种情况下,应将编码声明添加为文件的第二行。例如:
#!/usr/bin/env python3
# -*- coding: cp1252 -*-
三. Python的非正式介绍
在以下示例中,输入和输出通过是否存在提示来区分(>>>和...):要重复示例,必须在提示符后出现提示时出现提示; 从解释器输出不以提示开头的行。请注意,示例中一行上的辅助提示意味着您必须键入一个空行; 这用于结束多行命令。
本手册中的许多示例,即使是在交互式提示符下输入的示例,都包含注释。Python中的注释以哈希字符开头 #,并延伸到物理行的末尾。注释可能出现在行的开头或跟随空格或代码,但不在字符串文字中。字符串文字中的哈希字符只是一个哈希字符。由于注释是为了澄清代码而不是由Python解释,因此在键入示例时可能会省略它们。
一些例子:
# this is the first comment
spam = 1 # and this is the second comment
# ... and now a third!
text = "# This is not a comment because it's inside quotes."
3.1 使用Python作为计算器
让我们尝试一些简单的Python命令。启动解释器并等待主要提示符>>>。(不应该花很长时间。)
3.1.1 数字
解释器充当一个简单的计算器:您可以在其上键入表达式,它将写入值。表达式语法是直接的:运营商+,-,*和/工作就像在大多数其他语言(例如,C或Pascal); 括号(())可用于分组。例如:
>>> 2 + 2
4
>>> 50 - 5*6
20
>>> (50 - 5*6) / 4
5.0
>>> 8 / 5 # division always returns a floating point number
1.6
的整数(例如2,4,20)具有类型int,具有小数部分(例如,那些5.0,1.6)具有类型 float。我们将在本教程后面看到有关数值类型的更多信息。
Division(/)总是返回一个浮点数。要进行分区并获得整数结果(丢弃任何小数结果),您可以使用// 运算符; 计算你可以使用的余数%:
>>> 17 / 3 # classic division returns a float
5.666666666666667
>>>
>>> 17 // 3 # floor division discards the fractional part
5
>>> 17 % 3 # the % operator returns the remainder of the division
2
>>> 5 * 3 + 2 # result * divisor + remainder
17
使用Python,可以使用**运算符来计算幂[1]:
>>> 5 ** 2 # 5 squared
25
>>> 2 ** 7 # 2 to the power of 7
128
等号(=)用于为变量赋值。之后,在下一个交互式提示之前不会显示任何结果:
>>> width = 20
>>> height = 5 * 9
>>> width * height
900
如果变量没有“定义”(赋值),尝试使用它会给你一个错误:
>>> n # try to access an undefined variable
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'n' is not defined
浮点数完全支持; 具有混合类型操作数的运算符将整数操作数转换为浮点数:
>>> 4 * 3.75 - 1
14.0
在交互模式下,最后打印的表达式将分配给变量 _。这意味着当您使用Python作为桌面计算器时,继续计算会更容易一些,例如:
>>> tax = 12.5 / 100
>>> price = 100.50
>>> price * tax
12.5625
>>> price + _
113.0625
>>> round(_, 2)
113.06
该变量应被用户视为只读。不要为其显式赋值 - 您将创建一个具有相同名称的独立局部变量,以使用其魔术行为屏蔽内置变量。
除了int和之外float,Python还支持其他类型的数字,例如Decimal和Fraction。Python还内置了对复数的支持,并使用j或J后缀来表示虚部(例如3+5j)。
3.1.2 字符串
除了数字之外,Python还可以操作字符串,这可以通过多种方式表达。它们可以用单引号('...')或双引号("...")括起来,结果相同[2]。 \可用于转义引号:
>>> 'spam eggs' # single quotes
'spam eggs'
>>> 'doesn\'t' # use \' to escape the single quote...
"doesn't"
>>> "doesn't" # ...or use double quotes instead
"doesn't"
>>> '"Yes," they said.'
'"Yes," they said.'
>>> "\"Yes,\" they said."
'"Yes," they said.'
>>> '"Isn\'t," they said.'
'"Isn\'t," they said.'
在交互式解释器中,输出字符串用引号括起来,特殊字符用反斜杠转义。虽然这可能有时看起来与输入不同(封闭的引号可能会改变),但这两个字符串是等价的。如果字符串包含单引号而没有双引号,则该字符串用双引号括起来,否则用单引号括起来。该print()函数通过省略括号引号并打印转义字符和特殊字符,产生更可读的输出:
>>> '"Isn\'t," they said.'
'"Isn\'t," they said.'
>>> print('"Isn\'t," they said.')
"Isn't," they said.
>>> s = 'First line.\nSecond line.' # \n means newline
>>> s # without print(), \n is included in the output
'First line.\nSecond line.'
>>> print(s) # with print(), \n produces a new line
First line.
Second line.
如果您不希望将前面提到的字符\解释为特殊字符,则可以通过在第一个引号之前添加原始字符串来使用原始字符串r:
>>> print('C:\some\name') # here \n means newline!
C:\some
ame
>>> print(r'C:\some\name') # note the r before the quote
C:\some\name
字符串文字可以跨越多行。一种方法是使用三引号: """..."""或'''...'''。行尾自动包含在字符串中,但可以通过\在行尾添加a来防止这种情况。以下示例:
print("""\
Usage: thingy [OPTIONS]
-h Display this usage message
-H hostname Hostname to connect to
""")
产生以下输出(请注意,不包括初始换行符):
Usage: thingy [OPTIONS]
-h Display this usage message
-H hostname Hostname to connect to
字符串可以与+操作符连接(粘合在一起),并重复*:
>>> # 3 times 'un', followed by 'ium'
>>> 3 * 'un' + 'ium'
'unununium'
两个或多个彼此相邻的字符串文字(即引号之间的字符串)会自动连接。
>>> 'Py' 'thon'
'Python'
当您想要断开长字符串时,此功能特别有用:
>>> text = ('Put several strings within parentheses '
... 'to have them joined together.')
>>> text
'Put several strings within parentheses to have them joined together.'
这仅适用于两个文字,而不是变量或表达式:
>>> prefix = 'Py'
>>> prefix 'thon' # can't concatenate a variable and a string literal
...
SyntaxError: invalid syntax
>>> ('un' * 3) 'ium'
...
SyntaxError: invalid syntax
如果要连接变量或变量和文字,请使用+:
>>> prefix + 'thon'
'Python'
字符串可以被索引(下标),第一个字符具有索引0.没有单独的字符类型; 一个字符只是一个大小为1的字符串:
>>> word = 'Python'
>>> word[0] # character in position 0
'P'
>>> word[5] # character in position 5
'n'
指数也可能是负数,从右边开始计算:
>>> word[-1] # last character
'n'
>>> word[-2] # second-last character
'o'
>>> word[-6]
'P'
请注意,由于-0与0相同,因此负索引从-1开始。
除索引外,还支持切片。虽然索引用于获取单个字符,但切片允许您获取子字符串:
>>> word[0:2] # characters from position 0 (included) to 2 (excluded)
'Py'
>>> word[2:5] # characters from position 2 (included) to 5 (excluded)
'tho'
请注意如何始终包含开始,并始终排除结束。这可以确保始终等于:s[:i] + s[i:]s
>>> word[:2] + word[2:]
'Python'
>>> word[:4] + word[4:]
'Python'
切片索引具有有用的默认值; 省略的第一个索引默认为零,省略的第二个索引默认为要切片的字符串的大小。
>>> word[:2] # character from the beginning to position 2 (excluded)
'Py'
>>> word[4:] # characters from position 4 (included) to the end
'on'
>>> word[-2:] # characters from the second-last (included) to the end
'on'
记住切片如何工作的一种方法是将索引视为指向 字符之间,第一个字符的左边缘编号为0.然后,n个字符串的最后一个字符的右边缘具有索引n,例如:
+---+---+---+---+---+---+
| P | y | t | h | o | n |
+---+---+---+---+---+---+
0 1 2 3 4 5 6
-6 -5 -4 -3 -2 -1
第一行数字给出了字符串中索引0 ... 6的位置; 第二行给出相应的负指数。从i到 j的切片分别由标记为i和j的边之间的所有字符组成。
对于非负索引,切片的长度是索引的差异,如果两者都在边界内。例如,长度word[1:3]为2。
尝试使用过大的索引将导致错误:
>>> word[42] # the word only has 6 characters
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: string index out of range
但是,在用于切片时,优雅地处理超出范围的切片索引:
>>> word[4:42]
'on'
>>> word[42:]
''
Python字符串无法更改 - 它们是不可变的。因此,分配给字符串中的索引位置会导致错误:
>>> word[0] = 'J'
...
TypeError: 'str' object does not support item assignment
>>> word[2:] = 'py'
...
TypeError: 'str' object does not support item assignment
如果您需要不同的字符串,则应创建一个新字符串:
>>> 'J' + word[1:]
'Jython'
>>> word[:2] + 'py'
'Pypy'
内置函数len()返回字符串的长度:
>>> s = 'supercalifragilisticexpialidocious'
>>> len(s)
34
也可以看看
- 文本序列类型 - str
- 字符串是序列类型的示例,并支持此类型支持的常见操作。
- 字符串方法
- 字符串支持大量基本转换和搜索方法。
- 格式化的字符串文字
- 具有嵌入式表达式的字符串文字。
- 格式字符串语法
- 有关字符串格式的信息
str.format()。 - printf-style字符串格式
- 当字符串是运算
%符的左操作数时调用的旧格式化操作在此处更详细地描述。
3.1.3 列表
Python知道许多复合数据类型,用于将其他值组合在一起。最通用的是列表,它可以写成方括号之间的逗号分隔值(项)列表。列表可能包含不同类型的项目,但通常项目都具有相同的类型。
>>> squares = [1, 4, 9, 16, 25]
>>> squares
[1, 4, 9, 16, 25]
像字符串(以及所有其他内置序列类型)一样,列表可以被索引和切片:
>>> squares[0] # indexing returns the item
1
>>> squares[-1]
25
>>> squares[-3:] # slicing returns a new list
[9, 16, 25]
所有切片操作都返回包含所请求元素的新列表。这意味着以下切片返回列表的新(浅)副本:
>>> squares[:]
[1, 4, 9, 16, 25]
列表还支持串联等操作:
>>> squares + [36, 49, 64, 81, 100]
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
>>> cubes = [1, 8, 27, 65, 125] # something's wrong here
>>> 4 ** 3 # the cube of 4 is 64, not 65!
64
>>> cubes[3] = 64 # replace the wrong value
>>> cubes
[1, 8, 27, 64, 125]
您还可以使用该append() 方法在列表末尾添加新项目(我们稍后会看到有关方法的更多信息):
>>> cubes.append(216) # add the cube of 6
>>> cubes.append(7 ** 3) # and the cube of 7
>>> cubes
[1, 8, 27, 64, 125, 216, 343]
也可以分配给切片,这甚至可以改变列表的大小或完全清除它:
>>> letters = ['a', 'b', 'c', 'd', 'e', 'f', 'g']
>>> letters
['a', 'b', 'c', 'd', 'e', 'f', 'g']
>>> # replace some values
>>> letters[2:5] = ['C', 'D', 'E']
>>> letters
['a', 'b', 'C', 'D', 'E', 'f', 'g']
>>> # now remove them
>>> letters[2:5] = []
>>> letters
['a', 'b', 'f', 'g']
>>> # clear the list by replacing all the elements with an empty list
>>> letters[:] = []
>>> letters
[]
内置函数len()也适用于列表:
>>> letters = ['a', 'b', 'c', 'd']
>>> len(letters)
4
可以嵌套列表(创建包含其他列表的列表),例如:
>>> a = ['a', 'b', 'c']
>>> n = [1, 2, 3]
>>> x = [a, n]
>>> x
[['a', 'b', 'c'], [1, 2, 3]]
>>> x[0]
['a', 'b', 'c']
>>> x[0][1]
'b'
3.2 迈向编程的第一步
当然,我们可以将Python用于更复杂的任务,而不是将两个和两个一起添加。例如,我们可以编写Fibonacci 系列的初始子序列,如下所示:
>>> # Fibonacci series:
... # the sum of two elements defines the next
... a, b = 0, 1
>>> while b < 10:
... print(b)
... a, b = b, a+b
...
1
1
2
3
5
8
此示例介绍了几个新功能。
第一行包含多个赋值:变量
a并b同时获取新值0和1.在最后一行再次使用它,证明在任何赋值发生之前,右边的表达式都是先评估的。右侧表达式从左到右进行评估。while只要条件(此处为:)保持为真,循环就会执行。在Python中,就像在C中一样,任何非零整数值都是真的; 零是假的。条件也可以是字符串或列表值,实际上是任何序列; 任何长度非零的东西都是真的,空序列都是假的。该示例中使用的测试是简单的比较。标准比较运算符的编写方式与C中的相同:( 小于),(大于), (等于),(小于或等于),(大于或等于)和(不等于)。b < 10<>==<=>=!=在体循环是缩进:缩进是Python对语句分组的方法。在交互式提示符下,您必须为每个缩进行键入一个选项卡或空格。在实践中,您将使用文本编辑器为Python准备更复杂的输入; 所有体面的文本编辑都有自动缩进功能。当以交互方式输入复合语句时,必须后跟一个空行以指示完成(因为解析器在您键入最后一行时无法猜出)。请注意,基本块中的每一行必须缩进相同的数量。
该
print()函数写入给定参数的值。它与仅处理多个参数,浮点数量和字符串的方式不同,只是编写您想要编写的表达式(正如我们之前在计算器示例中所做的那样)。字符串打印时不带引号,并在项目之间插入空格,因此您可以很好地格式化事物,如下所示:>>>>>> i = 256*256
>>> print('The value of i is', i)
The value of i is 65536关键字参数end可用于在输出后避免换行,或者使用不同的字符串结束输出:
>>>>>> a, b = 0, 1
>>> while b < 1000:
... print(b, end=',')
... a, b = b, a+b
...
1,1,2,3,5,8,13,21,34,55,89,144,233,377,610,987,
四.更多控制流工具
除了while刚刚介绍的语句之外,Python还知道其他语言中常见的控制流语句,并且有一些曲折。
4.1 if陈述
也许最着名的陈述类型是if陈述。例如:
>>> x = int(input("Please enter an integer: "))
Please enter an integer: 42
>>> if x < 0:
... x = 0
... print('Negative changed to zero')
... elif x == 0:
... print('Zero')
... elif x == 1:
... print('Single')
... else:
... print('More')
...
More
可以有零个或多个elif零件,else零件是可选的。关键字' elif'是'else if'的缩写,有助于避免过度缩进。一 if... ... elif... ... elif... ...序列的替代switch或 case其它语言中的语句。
4.2 for陈述
forPython中的语句与您在C或Pascal中使用的语句略有不同。而不是总是迭代数字的算术级数(如在Pascal中),或者让用户能够定义迭代步骤和暂停条件(如C),Python的for语句迭代任何序列的项目(列表或string),按照它们出现在序列中的顺序。例如(没有双关语):
>>> # Measure some strings:
... words = ['cat', 'window', 'defenestrate']
>>> for w in words:
... print(w, len(w))
...
cat 3
window 6
defenestrate 12
如果您需要修改在循环内迭代的序列(例如复制所选项目),建议您先复制一份。迭代序列不会隐式地复制。切片表示法使这特别方便:
>>> for w in words[:]: # Loop over a slice copy of the entire list.
... if len(w) > 6:
... words.insert(0, w)
...
>>> words
['defenestrate', 'cat', 'window', 'defenestrate']
有了,该示例将尝试创建一个无限列表,一遍又一遍地插入。for w in words:defenestrate
4.3 该range()功能
如果你需要迭代一系列数字,内置函数 range()就派上用场了。它生成算术进度:
>>> for i in range(5):
... print(i)
...
0
1
2
3
4
给定的终点永远不是生成序列的一部分; range(10)生成10个值,长度为10的序列的项目的合法索引。可以让范围从另一个数字开始,或者指定不同的增量(甚至是负数;有时这称为“步骤”):
range(5, 10)
5, 6, 7, 8, 9 range(0, 10, 3)
0, 3, 6, 9 range(-10, -100, -30)
-10, -40, -70
要遍历序列的索引,您可以组合range()并 len()如下:
>>> a = ['Mary', 'had', 'a', 'little', 'lamb']
>>> for i in range(len(a)):
... print(i, a[i])
...
0 Mary
1 had
2 a
3 little
4 lamb
但是,在大多数此类情况下,使用该enumerate() 函数很方便,请参阅循环技术。
如果你只打印一个范围,就会发生一件奇怪的事:
>>> print(range(10))
range(0, 10)
在许多方面,返回的对象range()表现得好像它是一个列表,但事实上并非如此。它是一个对象,当您迭代它时,它返回所需序列的连续项,但它并不真正使列表,从而节省空间。
我们说这样的对象是可迭代的,也就是说,适合作为函数和构造的目标,这些函数和构造期望在供应耗尽之前它们可以从中获得连续的项目。我们已经看到该for语句是一个迭代器。功能list() 是另一个; 它从迭代创建列表:
>>> list(range(5))
[0, 1, 2, 3, 4]
稍后我们将看到更多返回iterables的函数,并将iterables作为参数。
4.4 break和continue语句以及else循环条款
在break声明中,类似于C,爆发最内层的 for或while循环。
循环语句可能有一个else子句; 当循环通过列表耗尽(with for)或条件变为false(with while)时终止,但是当循环被break语句终止时不执行它。这通过以下循环来举例说明,该循环搜索素数:
>>> for n in range(2, 10):
... for x in range(2, n):
... if n % x == 0:
... print(n, 'equals', x, '*', n//x)
... break
... else:
... # loop fell through without finding a factor
... print(n, 'is a prime number')
...
2 is a prime number
3 is a prime number
4 equals 2 * 2
5 is a prime number
6 equals 2 * 3
7 is a prime number
8 equals 2 * 4
9 equals 3 * 3
(是的,这是正确的代码,仔细一看:该else条款属于for循环,不是的if。陈述)
当循环使用,该else条款有更多的共同点与 else一个条款try声明比它认为的 if语句:一个try语句的else时候也不例外条款发生运行和循环的else条款时没有运行break 发生。有关try语句和异常的更多信息,请参阅 处理异常。
该continue声明也是从C借用的,继续循环的下一次迭代:
>>> for num in range(2, 10):
... if num % 2 == 0:
... print("Found an even number", num)
... continue
... print("Found a number", num)
Found an even number 2
Found a number 3
Found an even number 4
Found a number 5
Found an even number 6
Found a number 7
Found an even number 8
Found a number 9
4.5 pass陈述
该pass语句什么也不做。当语法需要语句但程序不需要操作时,可以使用它。例如:
>>> while True:
... pass # Busy-wait for keyboard interrupt (Ctrl+C)
...
这通常用于创建最小类:
>>> class MyEmptyClass:
... pass
...
pass当您处理新代码时,可以使用另一个地方作为函数或条件体的占位符,允许您在更抽象的层次上继续思考。将pass被自动忽略:
>>> def initlog(*args):
... pass # Remember to implement this!
...
4.6 定义函数
我们可以创建一个将Fibonacci系列写入任意边界的函数:
>>> def fib(n): # write Fibonacci series up to n
... """Print a Fibonacci series up to n."""
... a, b = 0, 1
... while a < n:
... print(a, end=' ')
... a, b = b, a+b
... print()
...
>>> # Now call the function we just defined:
... fib(2000)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597
该关键字def引入了一个函数定义。它必须后跟函数名称和带括号的形式参数列表。构成函数体的语句从下一行开始,并且必须缩进。
函数体的第一个语句可以选择是字符串文字; 此字符串文字是函数的文档字符串或docstring。(有关文档字符串的更多信息,请参阅文档字符串部分。)有些工具使用文档字符串自动生成在线或印刷文档,或者让用户以交互方式浏览代码; 在您编写的代码中包含docstrings是一种很好的做法,所以要养成习惯。
函数的执行引入了用于函数局部变量的新符号表。更准确地说,函数中的所有变量赋值都将值存储在本地符号表中; 而变量引用首先在本地符号表中查找,然后在封闭函数的本地符号表中查找,然后在全局符号表中查找,最后在内置名称表中查找。因此,全局变量不能直接在函数内赋值(除非在global语句中命名),尽管可以引用它们。
调用函数调用的实际参数(参数)在被调用函数的本地符号表中引入; 因此,使用call by value传递参数(其中值始终是对象引用,而不是对象的值)。[1]当函数调用另一个函数时,将为该调用创建一个新的本地符号表。
函数定义在当前符号表中引入函数名称。函数名称的值具有解释器将其识别为用户定义函数的类型。此值可以分配给另一个名称,该名称也可以用作函数。这是一般的重命名机制:
>>> fib
<function fib at 10042ed0>
>>> f = fib
>>> f(100)
0 1 1 2 3 5 8 13 21 34 55 89
来自其他语言,您可能会反对这fib不是一个函数而是一个过程,因为它不返回值。实际上,即使是没有return语句的函数也会 返回一个值,尽管它是一个相当无聊的值。调用此值None(它是内置名称)。None如果它是唯一写入的值,则解释器通常会禁止写入值。如果你真的想使用它,你可以看到它print():
>>> fib(0)
>>> print(fib(0))
None
编写一个函数可以很简单地返回Fibonacci系列的数字列表,而不是打印它:
>>> def fib2(n): # return Fibonacci series up to n
... """Return a list containing the Fibonacci series up to n."""
... result = []
... a, b = 0, 1
... while a < n:
... result.append(a) # see below
... a, b = b, a+b
... return result
...
>>> f100 = fib2(100) # call it
>>> f100 # write the result
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]
像往常一样,此示例演示了一些新的Python功能:
- 该
return语句返回一个函数的值。return没有表达式参数返回None。从函数的末尾掉落也会返回None。 - 该语句
result.append(a)调用list对象 的方法result。方法是“属于”对象并被命名的函数obj.methodname,其中obj是某个对象(可能是表达式),并且methodname是由对象的类型定义的方法的名称。不同类型定义不同的方法。不同类型的方法可以具有相同的名称而不会引起歧义。(可以使用类定义自己的对象类型和方法,请参阅类)append()示例中显示的方法是为列表对象定义的; 它在列表的末尾添加了一个新元素。在这个例子中它相当于 ,但效率更高。result = result + [a]
4.7 更多关于定义函数的信息
也可以使用可变数量的参数定义函数。有三种形式可以组合。
4.7.1 默认参数值
最有用的形式是为一个或多个参数指定默认值。这创建了一个函数,可以使用比定义允许的参数更少的参数调用。例如:
def ask_ok(prompt, retries=4, reminder='Please try again!'):
while True:
ok = input(prompt)
if ok in ('y', 'ye', 'yes'):
return True
if ok in ('n', 'no', 'nop', 'nope'):
return False
retries = retries - 1
if retries < 0:
raise ValueError('invalid user response')
print(reminder)
可以通过多种方式调用此函数:
- 只给出强制性参数:
ask_ok('Do you really want to quit?') - 给出一个可选参数:
ask_ok('OK to overwrite the file?', 2) - 甚至给出所有论据:
ask_ok('OK to overwrite the file?', 2, 'Come on, only yes or no!')
此示例还介绍了in关键字。这测试序列是否包含某个值。
默认值在定义范围内的函数定义点进行计算 ,以便进行
i = 5 def f(arg=i):
print(arg) i = 6
f()
将打印5。
重要警告: 默认值仅评估一次。当默认值是可变对象(例如列表,字典或大多数类的实例)时,这会产生差异。例如,以下函数会累积在后续调用中传递给它的参数:
def f(a, L=[]):
L.append(a)
return L print(f(1))
print(f(2))
print(f(3))
这将打印出来
[1]
[1, 2]
[1, 2, 3]
如果您不希望在后续调用之间共享默认值,则可以编写如下函数:
def f(a, L=None):
if L is None:
L = []
L.append(a)
return L
4.7.2 关键字参数
也可以使用 表单的关键字参数调用函数kwarg=value。例如,以下功能:
def parrot(voltage, state='a stiff', action='voom', type='Norwegian Blue'):
print("-- This parrot wouldn't", action, end=' ')
print("if you put", voltage, "volts through it.")
print("-- Lovely plumage, the", type)
print("-- It's", state, "!")
接受一个所需参数(voltage)和三个可选参数(state,action,和type)。可以通过以下任何方式调用此函数:
parrot(1000) # 1 positional argument
parrot(voltage=1000) # 1 keyword argument
parrot(voltage=1000000, action='VOOOOOM') # 2 keyword arguments
parrot(action='VOOOOOM', voltage=1000000) # 2 keyword arguments
parrot('a million', 'bereft of life', 'jump') # 3 positional arguments
parrot('a thousand', state='pushing up the daisies') # 1 positional, 1 keyword
但以下所有调用都将无效:
parrot() # required argument missing
parrot(voltage=5.0, 'dead') # non-keyword argument after a keyword argument
parrot(110, voltage=220) # duplicate value for the same argument
parrot(actor='John Cleese') # unknown keyword argument
在函数调用中,关键字参数必须遵循位置参数。传递的所有关键字参数必须与函数接受的参数之一匹配(例如actor,不是函数的有效参数 parrot),并且它们的顺序并不重要。这还包括非可选参数(例如parrot(voltage=1000)也是有效的)。没有参数可能会多次获得一个值。以下是由于此限制而失败的示例:
>>> def function(a):
... pass
...
>>> function(0, a=0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: function() got multiple values for keyword argument 'a'
当**name存在表单的最终形式参数时,它接收包含除了与形式参数相对应的所有关键字参数的字典(参见映射类型 - 字典)。这可以与形式的形式参数*name(在下一小节中描述)组合,该参数接收包含超出形式参数列表的位置参数的元组。(*name必须在之前发生**name。)例如,如果我们定义一个这样的函数:
def cheeseshop(kind, *arguments, **keywords):
print("-- Do you have any", kind, "?")
print("-- I'm sorry, we're all out of", kind)
for arg in arguments:
print(arg)
print("-" * 40)
for kw in keywords:
print(kw, ":", keywords[kw])
它可以像这样调用:
cheeseshop("Limburger", "It's very runny, sir.",
"It's really very, VERY runny, sir.",
shopkeeper="Michael Palin",
client="John Cleese",
sketch="Cheese Shop Sketch")
当然它会打印:
-- Do you have any Limburger ?
-- I'm sorry, we're all out of Limburger
It's very runny, sir.
It's really very, VERY runny, sir.
----------------------------------------
shopkeeper : Michael Palin
client : John Cleese
sketch : Cheese Shop Sketch
请注意,打印关键字参数的顺序保证与函数调用中提供它们的顺序相匹配。
4.7.3 任意参数列表
最后,最不常用的选项是指定可以使用任意数量的参数调用函数。这些参数将被包含在一个元组中(参见元组和序列)。在可变数量的参数之前,可能会出现零个或多个正常参数。
def write_multiple_items(file, separator, *args):
file.write(separator.join(args))
通常,这些variadic参数将在形式参数列表中排在最后,因为它们会挖掘传递给函数的所有剩余输入参数。在*args 参数之后出现的任何形式参数都是“仅关键字”参数,这意味着它们只能用作关键字而不是位置参数。
>>> def concat(*args, sep="/"):
... return sep.join(args)
...
>>> concat("earth", "mars", "venus")
'earth/mars/venus'
>>> concat("earth", "mars", "venus", sep=".")
'earth.mars.venus'
4.7.4 解压缩参数列表
当参数已经在列表或元组中但需要为需要单独位置参数的函数调用解包时,会发生相反的情况。例如,内置range()函数需要单独的 start和stop参数。如果它们不是单独可用的,请使用*-operator 编写函数调用以 从列表或元组中解压缩参数:
>>> list(range(3, 6)) # normal call with separate arguments
[3, 4, 5]
>>> args = [3, 6]
>>> list(range(*args)) # call with arguments unpacked from a list
[3, 4, 5]
以相同的方式,字典可以使用**-operator 提供关键字参数:
>>> def parrot(voltage, state='a stiff', action='voom'):
... print("-- This parrot wouldn't", action, end=' ')
... print("if you put", voltage, "volts through it.", end=' ')
... print("E's", state, "!")
...
>>> d = {"voltage": "four million", "state": "bleedin' demised", "action": "VOOM"}
>>> parrot(**d)
-- This parrot wouldn't VOOM if you put four million volts through it. E's bleedin' demised !
4.7.5 Lambda表达式
可以使用lambda关键字创建小的匿名函数。此函数返回其两个参数的总和:。Lambda函数可以在需要函数对象的任何地方使用。它们在语法上限于单个表达式。从语义上讲,它们只是正常函数定义的语法糖。与嵌套函数定义一样,lambda函数可以引用包含范围的变量:lambda a, b: a+b
>>> def make_incrementor(n):
... return lambda x: x + n
...
>>> f = make_incrementor(42)
>>> f(0)
42
>>> f(1)
43
上面的示例使用lambda表达式返回一个函数。另一个用途是传递一个小函数作为参数:
>>> pairs = [(1, 'one'), (2, 'two'), (3, 'three'), (4, 'four')]
>>> pairs.sort(key=lambda pair: pair[1])
>>> pairs
[(4, 'four'), (1, 'one'), (3, 'three'), (2, 'two')]
4.7.6 文档字符串
以下是有关文档字符串的内容和格式的一些约定。
第一行应始终是对象目的的简短概述。为简洁起见,它不应显式声明对象的名称或类型,因为这些可通过其他方式获得(除非名称恰好是描述函数操作的动词)。该行应以大写字母开头,以句点结尾。
如果文档字符串中有更多行,则第二行应为空白,从而在视觉上将摘要与其余描述分开。以下行应该是一个或多个段落,描述对象的调用约定,其副作用等。
Python解析器不会从Python中删除多行字符串文字的缩进,因此处理文档的工具必须在需要时删除缩进。这是使用以下约定完成的。字符串第一行之后的第一个非空行 确定整个文档字符串的缩进量。(我们不能使用第一行,因为它通常与字符串的开头引号相邻,因此它的缩进在字符串文字中不明显。)然后从字符串的所有行的开头剥离与该缩进“等效”的空格。 。缩进的行不应该出现,但是如果它们出现,则应该剥离它们的所有前导空格。应在扩展标签后测试空白的等效性(通常为8个空格)。
以下是多行文档字符串的示例:
>>> def my_function():
... """Do nothing, but document it.
...
... No, really, it doesn't do anything.
... """
... pass
...
>>> print(my_function.__doc__)
Do nothing, but document it. No, really, it doesn't do anything.
4.7.7 功能注释
函数注释是关于用户定义函数使用的类型的完全可选元数据信息(请参阅PEP 3107和 PEP 484了解更多信息)。
注释__annotations__作为字典存储在函数的属性中,对函数的任何其他部分没有影响。参数注释由参数名称后面的冒号定义,后跟一个表达式,用于评估注释的值。返回注释由->参数列表和表示def语句结尾的冒号之间的文字,后跟表达式定义。以下示例具有位置参数,关键字参数和注释的返回值:
>>> def f(ham: str, eggs: str = 'eggs') -> str:
... print("Annotations:", f.__annotations__)
... print("Arguments:", ham, eggs)
... return ham + ' and ' + eggs
...
>>> f('spam')
Annotations: {'ham': <class 'str'>, 'return': <class 'str'>, 'eggs': <class 'str'>}
Arguments: spam eggs
'spam and eggs'
4.8 Intermezzo:编码风格
现在您要编写更长,更复杂的Python,现在是讨论编码风格的好时机。大多数语言都可以用不同的风格编写(或更简洁,格式化); 有些比其他人更具可读性。让其他人轻松阅读您的代码总是一个好主意,采用一种好的编码风格对此有很大帮助。
对于Python, PEP 8已成为大多数项目坚持的风格指南; 它促进了一种非常易读且令人赏心悦目的编码风格。每个Python开发人员都应该在某个时候阅读它; 以下是为您提取的最重要的要点:
使用4空格缩进,没有标签。
4个空格是小压痕(允许更大的嵌套深度)和大压痕(更容易阅读)之间的良好折衷。标签引入混淆,最好省略。
换行,使其不超过79个字符。
这有助于用户使用小型显示器,并且可以在较大的显示器上并排放置多个代码文件。
使用空行分隔函数和类,以及函数内的较大代码块。
如果可能,将评论放在他们自己的一行上。
使用docstrings。
在操作符周围和逗号后面使用空格,但不能直接在包围结构中使用:。
a = f(1, 2) + g(3, 4)一致地命名您的类和函数; 约定
CamelCase用于类和lower_case_with_underscores函数和方法。始终使用self第一个方法参数的名称(有关类和方法的更多信息,请参阅类的初步查看)。如果您的代码旨在用于国际环境,请不要使用花哨的编码。Python的默认值,UTF-8甚至纯ASCII在任何情况下都能最好地工作。
同样,如果只有最轻微的机会,说不同语言的人会阅读或维护代码,请不要在标识符中使用非ASCII字符。
五.数据结构
本章将更详细地介绍您已经了解的一些内容,并添加了一些新内容。
5.1 更多关于列表
列表数据类型有更多方法。以下是列表对象的所有方法:
list.append(x )-
将项添加到列表的末尾。相当于。
a[len(a):] = [x]
list.extend(可迭代的)-
通过附加iterable中的所有项来扩展列表。相当于 。
a[len(a):] = iterable
list.insert(i,x )-
在给定位置插入项目。第一个参数是要插入的元素的索引,因此插入列表的前面,并且等效于。
a.insert(0,x)a.insert(len(a), x)a.append(x)
list.remove(x )-
从列表中删除值为x的第一个项目。如果没有这样的项目则是错误的。
list.pop([ i ] )-
删除列表中给定位置的项目,然后将其返回。如果未指定索引,则
a.pop()删除并返回列表中的最后一项。(方法签名中i周围的方括号表示该参数是可选的,而不是您应该在该位置键入方括号。您将在Python Library Reference中经常看到这种表示法。)
list.clear()-
从列表中删除所有项目。相当于。
del a[:]
list.index(x [,start [,end ] ] )-
在值为x的第一个项的列表中返回从零开始的索引。
ValueError如果没有这样的项目,则提高a 。可选参数start和end被解释为切片表示法,并用于将搜索限制为列表的特定子序列。返回的索引是相对于完整序列的开头而不是start参数计算的。
list.count(x )-
返回x出现在列表中的次数。
list.sort(key = None,reverse = False )-
对列表中的项目进行排序(参数可用于排序自定义,请参阅
sorted()其说明)。
list.reverse()-
反转列表中的元素。
list.copy()-
返回列表的浅表副本。相当于
a[:]。
使用大多数列表方法的示例:
>>> fruits = ['orange', 'apple', 'pear', 'banana', 'kiwi', 'apple', 'banana']
>>> fruits.count('apple')
2
>>> fruits.count('tangerine')
0
>>> fruits.index('banana')
3
>>> fruits.index('banana', 4) # Find next banana starting a position 4
6
>>> fruits.reverse()
>>> fruits
['banana', 'apple', 'kiwi', 'banana', 'pear', 'apple', 'orange']
>>> fruits.append('grape')
>>> fruits
['banana', 'apple', 'kiwi', 'banana', 'pear', 'apple', 'orange', 'grape']
>>> fruits.sort()
>>> fruits
['apple', 'apple', 'banana', 'banana', 'grape', 'kiwi', 'orange', 'pear']
>>> fruits.pop()
'pear'
您可能已经注意到,方法一样insert,remove或者sort只修改列表没有返回值印刷-它们返回的默认 None。[1] 这是Python中所有可变数据结构的设计原则。
5.1.1 使用列表作为堆栈
list方法可以很容易地将列表用作堆栈,其中添加的最后一个元素是检索到的第一个元素(“last-in,first-out”)。要将项添加到堆栈顶部,请使用append()。要从堆栈顶部检索项目,请在pop()没有显式索引的情况下使用。例如:
>>> stack = [3, 4, 5]
>>> stack.append(6)
>>> stack.append(7)
>>> stack
[3, 4, 5, 6, 7]
>>> stack.pop()
7
>>> stack
[3, 4, 5, 6]
>>> stack.pop()
6
>>> stack.pop()
5
>>> stack
[3, 4]
5.1.2 使用列表作为队列
也可以使用列表作为队列,其中添加的第一个元素是检索的第一个元素(“先进先出”); 但是,列表不能用于此目的。虽然列表末尾的追加和弹出很快,但是从列表的开头进行插入或弹出是很慢的(因为所有其他元素都必须移动一个)。
要实现队列,请使用collections.deque设计为具有快速追加和从两端弹出的队列。例如:
>>> from collections import deque
>>> queue = deque(["Eric", "John", "Michael"])
>>> queue.append("Terry") # Terry arrives
>>> queue.append("Graham") # Graham arrives
>>> queue.popleft() # The first to arrive now leaves
'Eric'
>>> queue.popleft() # The second to arrive now leaves
'John'
>>> queue # Remaining queue in order of arrival
deque(['Michael', 'Terry', 'Graham'])
5.1.3 列表理解
列表推导提供了创建列表的简明方法。常见的应用是创建新的列表,其中每个元素是应用于另一个序列的每个成员或可迭代的一些操作的结果,或者创建满足特定条件的那些元素的子序列。
例如,假设我们要创建一个正方形列表,例如:
>>> squares = []
>>> for x in range(10):
... squares.append(x**2)
...
>>> squares
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
请注意,这会创建(或覆盖)一个名为x在循环完成后仍然存在的变量。我们可以使用以下方法计算没有任何副作用的正方形列表:
squares = list(map(lambda x: x**2, range(10)))
或者,等效地:
squares = [x**2 for x in range(10)]
这更简洁,更易读。
列表推导由括号组成,括号中包含一个表达式,后跟一个for子句,然后是零个或多个for或if 子句。结果将是一个新的列表,该列表是通过在其后面的for和if子句的上下文中评估表达式而得到的。例如,如果列表不相等,则此listcomp将两个列表的元素组合在一起:
>>> [(x, y) for x in [1,2,3] for y in [3,1,4] if x != y]
[(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]
它相当于:
>>> combs = []
>>> for x in [1,2,3]:
... for y in [3,1,4]:
... if x != y:
... combs.append((x, y))
...
>>> combs
[(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]
如果表达式是元组(例如前面示例中的元组),则必须将其括起来。(x, y)
>>> vec = [-4, -2, 0, 2, 4]
>>> # create a new list with the values doubled
>>> [x*2 for x in vec]
[-8, -4, 0, 4, 8]
>>> # filter the list to exclude negative numbers
>>> [x for x in vec if x >= 0]
[0, 2, 4]
>>> # apply a function to all the elements
>>> [abs(x) for x in vec]
[4, 2, 0, 2, 4]
>>> # call a method on each element
>>> freshfruit = [' banana', ' loganberry ', 'passion fruit ']
>>> [weapon.strip() for weapon in freshfruit]
['banana', 'loganberry', 'passion fruit']
>>> # create a list of 2-tuples like (number, square)
>>> [(x, x**2) for x in range(6)]
[(0, 0), (1, 1), (2, 4), (3, 9), (4, 16), (5, 25)]
>>> # the tuple must be parenthesized, otherwise an error is raised
>>> [x, x**2 for x in range(6)]
File "<stdin>", line 1, in <module>
[x, x**2 for x in range(6)]
^
SyntaxError: invalid syntax
>>> # flatten a list using a listcomp with two 'for'
>>> vec = [[1,2,3], [4,5,6], [7,8,9]]
>>> [num for elem in vec for num in elem]
[1, 2, 3, 4, 5, 6, 7, 8, 9]
列表推导可以包含复杂的表达式和嵌套函数:
>>> from math import pi
>>> [str(round(pi, i)) for i in range(1, 6)]
['3.1', '3.14', '3.142', '3.1416', '3.14159']
5.1.4 嵌套列表理解
列表推导中的初始表达式可以是任意表达式,包括另一个列表推导。
考虑以下3x4矩阵示例,该矩阵实现为3个长度为4的列表:
>>> matrix = [
... [1, 2, 3, 4],
... [5, 6, 7, 8],
... [9, 10, 11, 12],
... ]
以下列表理解将转置行和列:
>>> [[row[i] for row in matrix] for i in range(4)]
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
正如我们在上一节中看到的那样,嵌套的listcomp在其后面的上下文中进行计算for,因此该示例等效于:
>>> transposed = []
>>> for i in range(4):
... transposed.append([row[i] for row in matrix])
...
>>> transposed
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
反过来,它与:
>>> transposed = []
>>> for i in range(4):
... # the following 3 lines implement the nested listcomp
... transposed_row = []
... for row in matrix:
... transposed_row.append(row[i])
... transposed.append(transposed_row)
...
>>> transposed
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
在现实世界中,您应该更喜欢内置函数来处理复杂的流语句。该zip()功能对于这个用例非常有用:
>>> list(zip(*matrix))
[(1, 5, 9), (2, 6, 10), (3, 7, 11), (4, 8, 12)]
有关此行中星号的详细信息,请参阅解压缩参数列表。
5.2 该del声明
有一种方法可以从列表中删除一个项目,而不是它的值:del语句。这与pop()返回值的方法不同。该del语句还可用于从列表中删除切片或清除整个列表(我们之前通过将空列表分配给切片来执行此操作)。例如:
>>> a = [-1, 1, 66.25, 333, 333, 1234.5]
>>> del a[0]
>>> a
[1, 66.25, 333, 333, 1234.5]
>>> del a[2:4]
>>> a
[1, 66.25, 1234.5]
>>> del a[:]
>>> a
[]
del 也可以用来删除整个变量:
>>> del a
a以下引用名称是一个错误(至少在为其分配了另一个值之前)。我们会在del以后找到其他用途。
5.3 元组和序列
我们看到列表和字符串有许多常见属性,例如索引和切片操作。它们是序列数据类型的两个示例(请参阅 序列类型 - 列表,元组,范围)。由于Python是一种不断发展的语言,因此可能会添加其他序列数据类型。还有另一种标准序列数据类型: 元组。
元组由逗号分隔的多个值组成,例如:
>>> t = 12345, 54321, 'hello!'
>>> t[0]
12345
>>> t
(12345, 54321, 'hello!')
>>> # Tuples may be nested:
... u = t, (1, 2, 3, 4, 5)
>>> u
((12345, 54321, 'hello!'), (1, 2, 3, 4, 5))
>>> # Tuples are immutable:
... t[0] = 88888
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>> # but they can contain mutable objects:
... v = ([1, 2, 3], [3, 2, 1])
>>> v
([1, 2, 3], [3, 2, 1])
如您所见,输出元组始终用括号括起来,以便正确解释嵌套元组; 它们可以输入有或没有周围的括号,尽管通常括号是必要的(如果元组是较大表达式的一部分)。无法分配元组的各个项,但是可以创建包含可变对象的元组,例如列表。
尽管元组看起来与列表类似,但它们通常用于不同的情况并用于不同的目的。元组是不可变的,并且通常包含异构的元素序列,这些元素可以通过解包(参见本节后面部分)或索引(或者甚至是属性的情况下namedtuples)来访问。列表是可变的,它们的元素通常是同类的,可以通过遍历列表来访问。
一个特殊的问题是构造包含0或1项的元组:语法有一些额外的怪癖来适应这些。空元组是由一对空括号构成的; 通过使用逗号跟随值来构造具有一个项目的元组(在括号中包含单个值是不够的)。丑陋但有效。例如:
>>> empty = ()
>>> singleton = 'hello', # <-- note trailing comma
>>> len(empty)
0
>>> len(singleton)
1
>>> singleton
('hello',)
该语句是元组打包的一个例子:值,并在元组中打包在一起。反向操作也是可能的:t = 12345, 54321,'hello!'1234554321'hello!'
>>> x, y, z = t
这足够恰当地称为序列解包,适用于右侧的任何序列。序列解包需要在等号左侧有尽可能多的变量,因为序列中有元素。请注意,多重赋值实际上只是元组打包和序列解包的组合。
5.4 集合
Python还包括集合的数据类型。集合是无序集合,没有重复元素。基本用途包括成员资格测试和消除重复条目。集合对象还支持数学运算,如并集,交集,差异和对称差异。
大括号或set()函数可用于创建集合。注意:要创建一个空集,你必须使用set(),而不是{}; 后者创建一个空字典,一个我们将在下一节讨论的数据结构。
这是一个简短的演示:
>>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
>>> print(basket) # show that duplicates have been removed
{'orange', 'banana', 'pear', 'apple'}
>>> 'orange' in basket # fast membership testing
True
>>> 'crabgrass' in basket
False
>>> # Demonstrate set operations on unique letters from two words
...
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a # unique letters in a
{'a', 'r', 'b', 'c', 'd'}
>>> a - b # letters in a but not in b
{'r', 'd', 'b'}
>>> a | b # letters in a or b or both
{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # letters in both a and b
{'a', 'c'}
>>> a ^ b # letters in a or b but not both
{'r', 'd', 'b', 'm', 'z', 'l'}
与列表推导类似,也支持集合理解:
>>> a = {x for x in 'abracadabra' if x not in 'abc'}
>>> a
{'r', 'd'}
5.5 字典
Python内置的另一个有用的数据类型是字典(请参阅 映射类型 - 字典)。词典有时在其他语言中被称为“关联记忆”或“关联阵列”。与通过一系列数字索引的序列不同,字典由键索引,键可以是任何不可变类型; 字符串和数字总是键。如果元组仅包含字符串,数字或元组,则它们可用作键; 如果元组直接或间接包含任何可变对象,则不能将其用作键。你不能用链表做关键字,因为链表可以用索引赋值,切片赋值,或类似的方法进行修改append()和extend()。
最好将字典视为一组无序的键:值对,并要求键是唯一的(在一个字典中)。一对大括号创建一个空字典:{}。在括号内放置以逗号分隔的键:值对列表,将初始键:值对添加到字典中; 这也是字典在输出上的写法。
字典上的主要操作是使用某个键存储值并提取给定键的值。也可以删除键:值对del。如果使用已在使用的密钥进行存储,则会忘记与该密钥关联的旧值。使用不存在的密钥提取值是错误的。
list(d.keys())对字典执行会以任意顺序返回字典中使用的所有键的列表(如果您希望对其进行排序,则只需使用它 sorted(d.keys()))。[2] 要检查单个键是否在字典中,请使用in关键字。
这是一个使用字典的小例子:
>>> tel = {'jack': 4098, 'sape': 4139}
>>> tel['guido'] = 4127
>>> tel
{'sape': 4139, 'guido': 4127, 'jack': 4098}
>>> tel['jack']
4098
>>> del tel['sape']
>>> tel['irv'] = 4127
>>> tel
{'guido': 4127, 'irv': 4127, 'jack': 4098}
>>> list(tel.keys())
['irv', 'guido', 'jack']
>>> sorted(tel.keys())
['guido', 'irv', 'jack']
>>> 'guido' in tel
True
>>> 'jack' not in tel
False
的dict()构造直接从键-值对的序列构建字典:
>>> dict([('sape', 4139), ('guido', 4127), ('jack', 4098)])
{'sape': 4139, 'jack': 4098, 'guido': 4127}
此外,dict comprehensions可用于从任意键和值表达式创建字典:
>>> {x: x**2 for x in (2, 4, 6)}
{2: 4, 4: 16, 6: 36}
当键是简单字符串时,有时使用关键字参数指定对更容易:
>>> dict(sape=4139, guido=4127, jack=4098)
{'sape': 4139, 'jack': 4098, 'guido': 4127}
5.6 循环技术
循环遍历字典时,可以使用该items()方法同时检索密钥和相应的值。
>>> knights = {'gallahad': 'the pure', 'robin': 'the brave'}
>>> for k, v in knights.items():
... print(k, v)
...
gallahad the pure
robin the brave
循环遍历序列时,可以使用该enumerate()函数同时检索位置索引和相应的值。
>>> for i, v in enumerate(['tic', 'tac', 'toe']):
... print(i, v)
...
0 tic
1 tac
2 toe
要同时循环两个或更多个序列,条目可以与该zip()功能配对。
>>> questions = ['name', 'quest', 'favorite color']
>>> answers = ['lancelot', 'the holy grail', 'blue']
>>> for q, a in zip(questions, answers):
... print('What is your {0}? It is {1}.'.format(q, a))
...
What is your name? It is lancelot.
What is your quest? It is the holy grail.
What is your favorite color? It is blue.
要反向循环序列,首先在正向指定序列,然后调用该reversed()函数。
>>> for i in reversed(range(1, 10, 2)):
... print(i)
...
9
7
5
3
1
要按排序顺序循环序列,请使用sorted()返回新排序列表的函数,同时保持源不变。
>>> basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana']
>>> for f in sorted(set(basket)):
... print(f)
...
apple
banana
orange
pear
当你循环它时,有时很有可能改变一个列表; 但是,创建新列表通常更简单,更安全。
>>> import math
>>> raw_data = [56.2, float('NaN'), 51.7, 55.3, 52.5, float('NaN'), 47.8]
>>> filtered_data = []
>>> for value in raw_data:
... if not math.isnan(value):
... filtered_data.append(value)
...
>>> filtered_data
[56.2, 51.7, 55.3, 52.5, 47.8]
5.7 更多关于条件
while和if语句中使用的条件可以包含任何运算符,而不仅仅是比较。
比较运算符in并检查序列中是否出现(不发生)值。运算符并比较两个对象是否真的是同一个对象; 这只对像列表这样的可变对象很重要。所有比较运算符具有相同的优先级,低于所有数值运算符的优先级。not inisis not
比较可以链接。例如,测试是否小于,而且等于。a < b == cabbc
比较可以使用布尔运算符进行组合and和or,和一个比较的结果(或任何其它的布尔表达式的)可以与否定not。这些优先级低于比较运算符; 它们之间,not具有最高优先级和or最低优先级,因此相当于。与往常一样,括号可用于表达所需的组成。A and not B or C(A and (not B)) or C
布尔运算符and和or所谓的短路 运算符:它们的参数从左到右进行计算,一旦确定结果,评估就会停止。例如,如果A且C为true但B为false,则不评估表达式 。当用作一般值而不是布尔值时,短路运算符的返回值是最后一个求值的参数。A and B and CC
可以将比较结果或其他布尔表达式分配给变量。例如,
>>> string1, string2, string3 = '', 'Trondheim', 'Hammer Dance'
>>> non_null = string1 or string2 or string3
>>> non_null
'Trondheim'
请注意,在Python中,与C不同,赋值不能出现在表达式中。C程序员可能会抱怨这一点,但它避免了C程序中遇到的常见问题:=在==预期时输入表达式。
5.8 比较序列和其他类型
可以将序列对象与具有相同序列类型的其他对象进行比较。比较使用词典排序:首先比较前两个项目,如果它们不同,则确定比较的结果; 如果它们相等,则比较接下来的两个项目,依此类推,直到任一序列用完为止。如果要比较的两个项本身是相同类型的序列,则递归地执行词典比较。如果两个序列的所有项目相等,则认为序列相等。如果一个序列是另一个序列的初始子序列,则较短的序列是较小的(较小的)序列。字符串的字典顺序使用Unicode代码点编号来排序单个字符。相同类型序列之间比较的一些示例:
(1, 2, 3) < (1, 2, 4)
[1, 2, 3] < [1, 2, 4]
'ABC' < 'C' < 'Pascal' < 'Python'
(1, 2, 3, 4) < (1, 2, 4)
(1, 2) < (1, 2, -1)
(1, 2, 3) == (1.0, 2.0, 3.0)
(1, 2, ('aa', 'ab')) < (1, 2, ('abc', 'a'), 4)
请注意,如果对象具有适当的比较方法,则将不同类型的对象与对象进行比较<或是>合法的。例如,混合数字类型根据它们的数值进行比较,因此0等于0.0等。否则,解释器将引发TypeError异常,而不是提供任意排序。
六.模块
如果退出Python解释器并再次输入,则所做的定义(函数和变量)将丢失。因此,如果您想编写一个稍长的程序,最好使用文本编辑器为解释器准备输入并将该文件作为输入运行。这称为创建脚本。随着程序变得越来越长,您可能希望将其拆分为多个文件以便于维护。您可能还想使用您在多个程序中编写的便捷功能,而无需将其定义复制到每个程序中。
为了支持这一点,Python有一种方法可以将定义放在一个文件中,并在脚本或解释器的交互式实例中使用它们。这样的文件称为 模块 ; 模块中的定义可以导入到其他模块或主模块中(在顶级和计算器模式下执行的脚本中可以访问的变量集合)。
模块是包含Python定义和语句的文件。文件名是.py附加后缀的模块名称。在模块中,模块的名称(作为字符串)可用作全局变量的值 __name__。例如,使用您喜欢的文本编辑器创建一个fibo.py在当前目录中调用的文件,其中包含以下内容:
# Fibonacci numbers module def fib(n): # write Fibonacci series up to n
a, b = 0, 1
while b < n:
print(b, end=' ')
a, b = b, a+b
print() def fib2(n): # return Fibonacci series up to n
result = []
a, b = 0, 1
while b < n:
result.append(b)
a, b = b, a+b
return result
现在输入Python解释器并使用以下命令导入此模块:
>>> import fibo
这不会fibo 直接在当前符号表中输入定义的函数的名称; 它只在fibo那里输入模块名称。使用模块名称可以访问这些功能:
>>> fibo.fib(1000)
1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
>>> fibo.fib2(100)
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]
>>> fibo.__name__
'fibo'
如果您打算经常使用某个函数,可以将其分配给本地名称:
>>> fib = fibo.fib
>>> fib(500)
1 1 2 3 5 8 13 21 34 55 89 144 233 377
6.1 更多关于模块
模块可以包含可执行语句以及函数定义。这些语句用于初始化模块。它们仅在第一次在import语句中遇到模块名时执行。[1] (如果文件作为脚本执行,它们也会运行。)
每个模块都有自己的私有符号表,该表用作模块中定义的所有函数的全局符号表。因此,模块的作者可以在模块中使用全局变量,而不必担心与用户的全局变量的意外冲突。另一方面,如果您知道自己在做什么,则可以使用与其函数相同的符号来触摸模块的全局变量modname.itemname。
模块可以导入其他模块。习惯但不要求将所有 import语句放在模块的开头(或脚本,就此而言)。导入的模块名称放在导入模块的全局符号表中。
该import语句的变体将模块中的名称直接导入导入模块的符号表。例如:
>>> from fibo import fib, fib2
>>> fib(500)
1 1 2 3 5 8 13 21 34 55 89 144 233 377
这不会引入从本地符号表中获取导入的模块名称(因此在示例中fibo未定义)。
甚至还有一个变体来导入模块定义的所有名称:
>>> from fibo import *
>>> fib(500)
1 1 2 3 5 8 13 21 34 55 89 144 233 377
这将导入除以下划线(_)开头的所有名称。在大多数情况下,Python程序员不使用此工具,因为它在解释器中引入了一组未知的名称,可能隐藏了您已定义的一些内容。
请注意,通常*从模块或包导入的做法是不受欢迎的,因为它经常导致代码可读性差。但是,可以使用它来保存交互式会话中的输入。
如果后跟模块名称as,则以下名称as将直接绑定到导入的模块。
>>> import fibo as fib
>>> fib.fib(500)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377
这实际上是以与 将要执行的方式相同的方式导入模块。import fibofib
在使用from具有类似效果时也可以使用它:
>>> from fibo import fib as fibonacci
>>> fibonacci(500)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377
注意
出于效率原因,每个模块仅在每个解释器会话中导入一次。因此,如果更改模块,则必须重新启动解释器 - 或者,如果只是一个模块要进行交互式测试,请使用importlib.reload(),例如。import importlib;importlib.reload(modulename)
6.1.1 将模块作为脚本执行
当你运行Python模块时
python fibo.py <arguments>
将执行模块中的代码,就像您导入它一样,但__name__设置为"__main__"。这意味着通过在模块的末尾添加此代码:
if __name__ == "__main__":
import sys
fib(int(sys.argv[1]))
您可以使该文件可用作脚本以及可导入模块,因为解析命令行的代码仅在模块作为“主”文件执行时才会运行:
$ python fibo.py 50
1 1 2 3 5 8 13 21 34
如果导入模块,则不运行代码:
>>> import fibo
>>>
这通常用于为模块提供方便的用户界面,或用于测试目的(在脚本执行测试套件时运行模块)。
6.1.2 模块搜索路径
spam导入命名模块时,解释器首先搜索具有该名称的内置模块。如果未找到,则会搜索spam.py由变量给出的目录列表中指定 的文件sys.path。 sys.path从这些位置初始化:
- 包含输入脚本的目录(或未指定文件时的当前目录)。
PYTHONPATH(目录名列表,语法与shell变量相同PATH)。- 依赖于安装的默认值。
注意
在支持符号链接的文件系统上,在遵循符号链接后计算包含输入脚本的目录。换句话说,包含符号链接的目录不会添加到模块搜索路径中。
初始化后,Python程序可以修改sys.path。包含正在运行的脚本的目录位于搜索路径的开头,位于标准库路径之前。这意味着将加载该目录中的脚本,而不是库目录中的同名模块。除非有意更换,否则这是一个错误。有关更多信息,请参见标准模块一节
6.1.3 “编译”的Python文件
为了加速加载模块,Python将每个模块的编译版本缓存在__pycache__名称下的目录中,其中版本对编译文件的格式进行编码; 它通常包含Python版本号。例如,在CPython版本3.3中,spam.py的编译版本将被缓存为。此命名约定允许来自不同版本和不同版本的Python的已编译模块共存。module.version.pyc__pycache__/spam.cpython-33.pyc
Python根据编译版本检查源的修改日期,以查看它是否已过期并需要重新编译。这是一个完全自动化的过程。此外,编译的模块与平台无关,因此可以在具有不同体系结构的系统之间共享相同的库。
Python在两种情况下不检查缓存。首先,它总是重新编译并且不存储直接从命令行加载的模块的结果。其次,如果没有源模块,它不会检查缓存。要支持非源(仅编译)分发,已编译的模块必须位于源目录中,并且不得有源模块。
专家提示:
- 您可以使用Python命令上的
-O或-OO开关来减小已编译模块的大小。该-O开关删除断言语句时,-OO开关同时删除断言语句和__doc__字符串。由于某些程序可能依赖于这些程序可用,因此如果您知道自己在做什么,则应该只使用此选项。“优化”模块有一个opt-标签,通常更小。未来版本可能会改变优化的效果。 - 从
.pyc文件读取程序时,程序运行速度不比从文件读取程序时运行速度快.py; 对.pyc文件来说,唯一更快的是它们加载的速度。 - 该模块
compileall可以为目录中的所有模块创建.pyc文件。 - 有关此过程的更多详细信息,包括决策的流程图 PEP 3147。
6.2 标准模块
Python附带了一个标准模块库,在单独的文档Python库参考(以下称为“库参考”)中进行了描述。一些模块内置于解释器中; 这些操作提供对不属于语言核心但仍然内置的操作的访问,以提高效率或提供对系统调用等操作系统原语的访问。这些模块的集合是一个配置选项,它也取决于底层平台。例如,该winreg模块仅在Windows系统上提供。一个特定的模块值得注意: sys它是内置于每个Python解释器中的。变量 sys.ps1并sys.ps2定义用作主要和次要提示的字符串:
>>> import sys
>>> sys.ps1
'>>> '
>>> sys.ps2
'... '
>>> sys.ps1 = 'C> '
C> print('Yuck!')
Yuck!
C>
仅当解释器处于交互模式时才定义这两个变量。
变量sys.path是一个字符串列表,用于确定解释器的模块搜索路径。它被初始化为从环境变量获取的默认路径PYTHONPATH,或者来自内置默认值 PYTHONPATH没有设定。您可以使用标准列表操作对其进行修改:
>>> import sys
>>> sys.path.append('/ufs/guido/lib/python')
6.3 该dir()功能
内置函数dir()用于找出模块定义的名称。它返回一个排序的字符串列表:
>>> import fibo, sys
>>> dir(fibo)
['__name__', 'fib', 'fib2']
>>> dir(sys)
['__displayhook__', '__doc__', '__excepthook__', '__loader__', '__name__',
'__package__', '__stderr__', '__stdin__', '__stdout__',
'_clear_type_cache', '_current_frames', '_debugmallocstats', '_getframe',
'_home', '_mercurial', '_xoptions', 'abiflags', 'api_version', 'argv',
'base_exec_prefix', 'base_prefix', 'builtin_module_names', 'byteorder',
'call_tracing', 'callstats', 'copyright', 'displayhook',
'dont_write_bytecode', 'exc_info', 'excepthook', 'exec_prefix',
'executable', 'exit', 'flags', 'float_info', 'float_repr_style',
'getcheckinterval', 'getdefaultencoding', 'getdlopenflags',
'getfilesystemencoding', 'getobjects', 'getprofile', 'getrecursionlimit',
'getrefcount', 'getsizeof', 'getswitchinterval', 'gettotalrefcount',
'gettrace', 'hash_info', 'hexversion', 'implementation', 'int_info',
'intern', 'maxsize', 'maxunicode', 'meta_path', 'modules', 'path',
'path_hooks', 'path_importer_cache', 'platform', 'prefix', 'ps1',
'setcheckinterval', 'setdlopenflags', 'setprofile', 'setrecursionlimit',
'setswitchinterval', 'settrace', 'stderr', 'stdin', 'stdout',
'thread_info', 'version', 'version_info', 'warnoptions']
没有参数,dir()列出您当前定义的名称:
>>> a = [1, 2, 3, 4, 5]
>>> import fibo
>>> fib = fibo.fib
>>> dir()
['__builtins__', '__name__', 'a', 'fib', 'fibo', 'sys']
请注意,它列出了所有类型的名称:变量,模块,函数等。
dir()不列出内置函数和变量的名称。如果您需要这些列表,则在标准模块中定义它们 builtins:
>>> import builtins
>>> dir(builtins)
['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException',
'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning',
'ChildProcessError', 'ConnectionAbortedError', 'ConnectionError',
'ConnectionRefusedError', 'ConnectionResetError', 'DeprecationWarning',
'EOFError', 'Ellipsis', 'EnvironmentError', 'Exception', 'False',
'FileExistsError', 'FileNotFoundError', 'FloatingPointError',
'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError',
'ImportWarning', 'IndentationError', 'IndexError', 'InterruptedError',
'IsADirectoryError', 'KeyError', 'KeyboardInterrupt', 'LookupError',
'MemoryError', 'NameError', 'None', 'NotADirectoryError', 'NotImplemented',
'NotImplementedError', 'OSError', 'OverflowError',
'PendingDeprecationWarning', 'PermissionError', 'ProcessLookupError',
'ReferenceError', 'ResourceWarning', 'RuntimeError', 'RuntimeWarning',
'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError',
'SystemExit', 'TabError', 'TimeoutError', 'True', 'TypeError',
'UnboundLocalError', 'UnicodeDecodeError', 'UnicodeEncodeError',
'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning',
'ValueError', 'Warning', 'ZeroDivisionError', '_', '__build_class__',
'__debug__', '__doc__', '__import__', '__name__', '__package__', 'abs',
'all', 'any', 'ascii', 'bin', 'bool', 'bytearray', 'bytes', 'callable',
'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits',
'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval', 'exec', 'exit',
'filter', 'float', 'format', 'frozenset', 'getattr', 'globals', 'hasattr',
'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass',
'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview',
'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property',
'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice',
'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars',
'zip']
6.4 包
包是一种使用“点模块名称”构造Python模块命名空间的方法。例如,模块名称A.B指定在名为B的包中命名的子模块A。就像模块的使用使得不同模块的作者不必担心彼此的全局变量名称一样,使用虚线模块名称可以节省NumPy或Pillow等多模块软件包的作者不必担心彼此的模块名称。
假设您要设计一组模块(“包”),用于统一处理声音文件和声音数据。有许多不同的声音格式(通常由它们的扩展的认可,例如:.wav, .aiff,.au),所以你可能需要为不同的文件格式之间转换,创建和维护一个不断增长的集合。您可能还需要对声音数据执行许多不同的操作(例如混音,添加回声,应用均衡器功能,创建人工立体声效果),所以此外您还将编写一个永无止境的模块流来执行这些行动。这是您的包的可能结构(以分层文件系统的形式表示):
sound/ Top-level package
__init__.py Initialize the sound package
formats/ Subpackage for file format conversions
__init__.py
wavread.py
wavwrite.py
aiffread.py
aiffwrite.py
auread.py
auwrite.py
...
effects/ Subpackage for sound effects
__init__.py
echo.py
surround.py
reverse.py
...
filters/ Subpackage for filters
__init__.py
equalizer.py
vocoder.py
karaoke.py
...
导入包时,Python会在目录中搜索 sys.pathpackage子目录。
这些__init__.py文件需要使Python将目录视为包含包; 这样做是为了防止具有通用名称的目录,例如string,无意中隐藏稍后在模块搜索路径上发生的有效模块。在最简单的情况下,__init__.py可以只是一个空文件,但它也可以执行包的初始化代码或设置__all__变量,稍后描述。
包的用户可以从包中导入单个模块,例如:
import sound.effects.echo
这会加载子模块sound.effects.echo。必须以其全名引用它。
sound.effects.echo.echofilter(input, output, delay=0.7, atten=4)
导入子模块的另一种方法是:
from sound.effects import echo
这也会加载子模块echo,并使其在没有包前缀的情况下可用,因此可以按如下方式使用:
echo.echofilter(input, output, delay=0.7, atten=4)
另一种变化是直接导入所需的函数或变量:
from sound.effects.echo import echofilter
同样,这会加载子模块echo,但这会使其功能 echofilter()直接可用:
echofilter(input, output, delay=0.7, atten=4)
请注意,在使用时,该项可以是包的子模块(或子包),也可以是包中定义的其他名称,如函数,类或变量。该语句首先测试该项是否在包中定义; 如果没有,它假定它是一个模块并尝试加载它。如果找不到, 则会引发异常。from package import itemimportImportError
相反,当使用语法时,除了最后一个项目之外的每个项目都必须是一个包; 最后一项可以是模块或包,但不能是前一项中定义的类或函数或变量。import item.subitem.subsubitem
6.4.1 从包中导入*
现在用户写的时候会发生什么?理想情况下,人们希望以某种方式传递给文件系统,找到包中存在哪些子模块,并将它们全部导入。这可能需要很长时间,导入子模块可能会产生不必要的副作用,这种副作用只有在显式导入子模块时才会发生。from sound.effects import *
唯一的解决方案是让包作者提供包的显式索引。该import语句使用以下约定:如果包的 __init__.py代码定义了一个名为的列表__all__,则它将被视为遇到时应导入的模块名称列表。在发布新版本的软件包时,由软件包作者决定是否保持此列表的最新状态。如果包装作者没有看到从包装中导入*的用途,他们也可能决定不支持它。例如,该文件可能包含以下代码:from package import *sound/effects/__init__.py
__all__ = ["echo", "surround", "reverse"]
这意味着将导入包的三个命名子模块。from sound.effects import *sound
如果__all__没有定义,语句 也不会导入从包中的所有子模块到当前的命名空间; 它只确保已导入包(可能在其中运行任何初始化代码),然后导入包中定义的任何名称。这包括定义的任何名称(以及显式加载的子模块)。它还包括由先前语句显式加载的包的任何子模块。考虑以下代码:from sound.effects import*sound.effectssound.effects__init__.py__init__.pyimport
import sound.effects.echo
import sound.effects.surround
from sound.effects import *
在此示例中,echo和surround模块将导入当前命名空间,因为它们是在执行语句sound.effects时在包中定义的from...import。(这在__all__定义时也有效 。)
虽然某些模块设计为在使用时仅导出遵循某些模式的名称,但在生产代码中仍然被认为是不好的做法。import *
请记住,使用没有错!实际上,除非导入模块需要使用来自不同包的同名子模块,否则这是推荐的表示法。fromPackage import specific_submodule
6.4.2 包内引用
当包被组织成子包时(与sound示例中的包一样),您可以使用绝对导入来引用兄弟包的子模块。例如,如果模块sound.filters.vocoder需要使用包中的echo模块sound.effects,则可以使用。from sound.effects import echo
您还可以使用import语句的形式编写相对导入。这些导入使用前导点来指示相对导入中涉及的当前和父包。 例如,从模块中,您可以使用:from module import namesurround
from . import echo
from .. import formats
from ..filters import equalizer
请注意,相对导入基于当前模块的名称。由于主模块的名称始终是"__main__",因此用作Python应用程序主模块的模块必须始终使用绝对导入。
6.4.3 多个目录中的包
包支持另一个特殊属性__path__。这被初始化为一个列表,其中包含在__init__.py执行该文件中的代码之前保存包的目录的名称。这个变量可以修改; 这样做会影响将来对包中包含的模块和子包的搜索。
虽然通常不需要此功能,但它可用于扩展程序包中的模块集。
七.输入输出
有几种方法可以呈现程序的输出; 数据可以以人类可读的形式打印,或写入文件以供将来使用。本章将讨论一些可能性。
7.1 Fancier输出格式
到目前为止,我们遇到了两种写值的方法:表达式语句和print()函数。(第三种方法是使用write()文件对象的方法;标准输出文件可以作为参考sys.stdout。有关详细信息,请参阅库参考。)
通常,您需要更多地控制输出的格式,而不仅仅是打印空格分隔的值。有两种方法可以格式化输出; 第一种方法是自己做所有的字符串处理; 使用字符串切片和连接操作,您可以创建任何您可以想象的布局。字符串类型有一些方法可以执行将字符串填充到给定列宽的有用操作; 这些将在稍后讨论。第二种方法是使用格式化的字符串文字或str.format()方法。
该string模块包含一个Template类,它提供了另一种将值替换为字符串的方法。
当然还有一个问题:如何将值转换为字符串?幸运的是,Python有办法将任何值转换为字符串:将其传递给repr() 或str()函数。
该str()函数用于返回值相当于人类可读的值的表示,同时repr()用于生成可由解释器读取的表示(或者SyntaxError如果没有等效语法则强制执行)。对于没有特定人类消费表示的对象,str()将返回相同的值repr()。许多值,例如数字或结构(如列表和字典),使用任一函数都具有相同的表示。特别是字符串有两个不同的表示。
一些例子:
>>> s = 'Hello, world.'
>>> str(s)
'Hello, world.'
>>> repr(s)
"'Hello, world.'"
>>> str(1/7)
'0.14285714285714285'
>>> x = 10 * 3.25
>>> y = 200 * 200
>>> s = 'The value of x is ' + repr(x) + ', and y is ' + repr(y) + '...'
>>> print(s)
The value of x is 32.5, and y is 40000...
>>> # The repr() of a string adds string quotes and backslashes:
... hello = 'hello, world\n'
>>> hellos = repr(hello)
>>> print(hellos)
'hello, world\n'
>>> # The argument to repr() may be any Python object:
... repr((x, y, ('spam', 'eggs')))
"(32.5, 40000, ('spam', 'eggs'))"
以下是编写正方形和立方体表的两种方法:
>>> for x in range(1, 11):
... print(repr(x).rjust(2), repr(x*x).rjust(3), end=' ')
... # Note use of 'end' on previous line
... print(repr(x*x*x).rjust(4))
...
1 1 1
2 4 8
3 9 27
4 16 64
5 25 125
6 36 216
7 49 343
8 64 512
9 81 729
10 100 1000 >>> for x in range(1, 11):
... print('{0:2d} {1:3d} {2:4d}'.format(x, x*x, x*x*x))
...
1 1 1
2 4 8
3 9 27
4 16 64
5 25 125
6 36 216
7 49 343
8 64 512
9 81 729
10 100 1000
(请注意,在第一个示例中,每个列之间的一个空格是按照print()工作方式添加的:默认情况下,它在参数之间添加空格。)
此示例演示了str.rjust()字符串对象的方法,该方法通过在左侧填充空格,在给定宽度的字段中对字符串进行右对齐。有类似的方法str.ljust()和 str.center()。这些方法不会写任何东西,它们只返回一个新字符串。如果输入字符串太长,它们不会截断它,但会保持不变; 这会弄乱你的列布局,但这通常比替代方案更好,这可能是一个值。(如果你真的想要截断,你可以随时添加切片操作,如 x.ljust(n)[:n]。)
还有另一种方法,str.zfill()用零填充左侧的数字字符串。它了解正负号:
>>> '12'.zfill(5)
'00012'
>>> '-3.14'.zfill(7)
'-003.14'
>>> '3.14159265359'.zfill(5)
'3.14159265359'
该str.format()方法的基本用法如下所示:
>>> print('We are the {} who say "{}!"'.format('knights', 'Ni'))
We are the knights who say "Ni!"
其中的括号和字符(称为格式字段)将替换为传递给str.format()方法的对象。括号中的数字可用于表示传递给str.format()方法的对象的位置 。
>>> print('{0} and {1}'.format('spam', 'eggs'))
spam and eggs
>>> print('{1} and {0}'.format('spam', 'eggs'))
eggs and spam
如果在str.format()方法中使用关键字参数,则使用参数的名称引用它们的值。
>>> print('This {food} is {adjective}.'.format(
... food='spam', adjective='absolutely horrible'))
This spam is absolutely horrible.
位置和关键字参数可以任意组合:
>>> print('The story of {0}, {1}, and {other}.'.format('Bill', 'Manfred',
other='Georg'))
The story of Bill, Manfred, and Georg.
'!a'(apply ascii()),'!s'(apply str())和'!r' (apply repr())可用于在格式化之前转换值:
>>> contents = 'eels'
>>> print('My hovercraft is full of {}.'.format(contents))
My hovercraft is full of eels.
>>> print('My hovercraft is full of {!r}.'.format(contents))
My hovercraft is full of 'eels'.
可选的':'格式说明符可以跟随字段名称。这样可以更好地控制值的格式化方式。以下示例将Pi舍入到小数点后的三个位置。
>>> import math
>>> print('The value of PI is approximately {0:.3f}.'.format(math.pi))
The value of PI is approximately 3.142.
在该':'字段之后传递一个整数将导致该字段为最小字符数。这对于使表非常有用很有用。
>>> table = {'Sjoerd': 4127, 'Jack': 4098, 'Dcab': 7678}
>>> for name, phone in table.items():
... print('{0:10} ==> {1:10d}'.format(name, phone))
...
Jack ==> 4098
Dcab ==> 7678
Sjoerd ==> 4127
如果你有一个非常长的格式字符串,你不想拆分,那么如果你可以引用变量来按名称而不是按位置进行格式化将会很好。这可以通过简单地传递dict并使用方括号'[]'来访问键来完成
>>> table = {'Sjoerd': 4127, 'Jack': 4098, 'Dcab': 8637678}
>>> print('Jack: {0[Jack]:d}; Sjoerd: {0[Sjoerd]:d}; '
... 'Dcab: {0[Dcab]:d}'.format(table))
Jack: 4098; Sjoerd: 4127; Dcab: 8637678
这也可以通过将表作为关键字参数传递'**'表示法来完成。
>>> table = {'Sjoerd': 4127, 'Jack': 4098, 'Dcab': 8637678}
>>> print('Jack: {Jack:d}; Sjoerd: {Sjoerd:d}; Dcab: {Dcab:d}'.format(**table))
Jack: 4098; Sjoerd: 4127; Dcab: 8637678
这与内置函数结合使用特别有用,内置函数 vars()返回包含所有局部变量的字典。
有关字符串格式的完整概述str.format(),请参阅 格式字符串语法。
7.1.1 旧字符串格式
该%运营商还可以用于字符串格式化。它将左参数解释为非常类似于sprintf()要应用于右参数的格式字符串,并返回由此格式化操作产生的字符串。例如:
>>> import math
>>> print('The value of PI is approximately %5.3f.' % math.pi)
The value of PI is approximately 3.142.
可以在printf样式的字符串格式部分中找到更多信息。
7.2 读写文件
open()返回一个文件对象,最常用的有两个参数:。open(filename, mode)
>>> f = open('workfile', 'w')
第一个参数是包含文件名的字符串。第二个参数是另一个字符串,其中包含一些描述文件使用方式的字符。 模式可以是'r'仅读取文件时,'w' 仅写入(将删除同名的现有文件),并 'a'打开文件进行追加; 写入文件的任何数据都会自动添加到最后。 'r+'打开文件进行读写。所述模式参数是可选的; 'r'将被假设,如果它被省略。
通常,文件以文本模式打开,这意味着您从文件读取和写入文件,这些文件以特定编码进行编码。如果未指定编码,则默认值取决于平台(请参阅参考资料 open())。'b'附加到模式后以二进制模式打开文件 :现在以bytes对象的形式读取和写入数据。此模式应用于所有不包含文本的文件。
在文本模式下,读取时的默认设置是将平台特定的行结尾(\n在Unix上,\r\n在Windows上)转换为just \n。在文本模式下写入时,默认设置是将事件的发生转换\n为特定于平台的行结尾。这幕后的修改文件数据精细的文本文件,但会喜欢,在破坏了二进制数据 JPEG或EXE文件。在读取和写入此类文件时要非常小心地使用二进制模式。
with在处理文件对象时,最好使用关键字。优点是文件在套件完成后正确关闭,即使在某个时刻引发了异常。使用with也比写相当于短得多try- finally块:
>>> with open('workfile') as f:
... read_data = f.read()
>>> f.closed
True
如果您没有使用该with关键字,那么您应该调用 f.close()以关闭该文件并立即释放它使用的任何系统资源。如果您没有显式关闭文件,Python的垃圾收集器最终将销毁该对象并为您关闭打开的文件,但该文件可能会保持打开状态一段时间。另一个风险是不同的Python实现将在不同的时间进行清理。
通过with语句或通过调用关闭文件对象后f.close(),尝试使用该文件对象将自动失败。
>>> f.close()
>>> f.read()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: I/O operation on closed file
7.2.1 文件对象的方法
本节中的其余示例将假定f已创建一个名为的文件对象 。
要读取文件的内容,请调用f.read(size),读取一些数据并将其作为字符串(在文本模式下)或字节对象(在二进制模式下)返回。 size是可选的数字参数。当省略size或negative时,将读取并返回文件的全部内容; 如果文件的大小是机器内存的两倍,那么这就是你的问题。否则,最多读取并返回大小字节。如果已到达文件末尾,f.read()则返回空字符串('')。
>>> f.read()
'This is the entire file.\n'
>>> f.read()
''
f.readline()从文件中读取一行; 换行符(\n)留在字符串的末尾,如果文件没有以换行符结尾,则只在文件的最后一行省略。这使得返回值明确无误; 如果f.readline()返回一个空字符串,则表示已到达文件末尾,而空行表示为'\n'一个只包含一个换行符的字符串。
>>> f.readline()
'This is the first line of the file.\n'
>>> f.readline()
'Second line of the file\n'
>>> f.readline()
''
要从文件中读取行,可以循环遍历文件对象。这是内存高效,快速,并导致简单的代码:
>>> for line in f:
... print(line, end='')
...
This is the first line of the file.
Second line of the file
如果要读取列表中文件的所有行,也可以使用 list(f)或f.readlines()。
f.write(string)将string的内容写入文件,返回写入的字符数。
>>> f.write('This is a test\n')
15
在编写之前,需要将其他类型的对象转换为字符串(在文本模式下)或字节对象(在二进制模式下):
>>> value = ('the answer', 42)
>>> s = str(value) # convert the tuple to string
>>> f.write(s)
18
f.tell() 返回一个整数,给出文件对象在文件中的当前位置,表示为二进制模式下文件开头的字节数和文本模式下的不透明数字。
要更改文件对象的位置,请使用。通过向参考点添加偏移来计算位置; 参数点由from_what参数选择。甲from_what从文件的开头0措施值,1使用当前文件位置,和2使用该文件作为参考点的端部。 from_what可以省略,默认为0,使用文件的开头作为参考点。f.seek(offset, from_what)
>>> f = open('workfile', 'rb+')
>>> f.write(b'0123456789abcdef')
16
>>> f.seek(5) # Go to the 6th byte in the file
5
>>> f.read(1)
b'5'
>>> f.seek(-3, 2) # Go to the 3rd byte before the end
13
>>> f.read(1)
b'd'
在文本文件中(那些b在模式字符串中没有打开的文件),只允许相对于文件开头的搜索(寻找到文件结尾的例外),唯一有效的偏移值是从,或者返回的那些,或者零。任何其他偏移值都会产生未定义的行为。seek(0,2)f.tell()
文件对象有一些额外的方法,如isatty()和 truncate()其中较不频繁地使用的; 有关文件对象的完整指南,请参阅“库参考”。
7.2.2 使用保存结构化数据json
可以轻松地将字符串写入文件并从文件中读取。数字需要更多的努力,因为该read()方法只返回字符串,必须将其传递给类似的函数int(),它接受类似字符串'123' 并返回其数值123.当您想要保存更复杂的数据类型(如嵌套列表和字典,手工解析和序列化变得复杂。
Python允许您使用称为JSON(JavaScript Object Notation)的流行数据交换格式,而不是让用户不断编写和调试代码以将复杂的数据类型保存到文件中。调用的标准模块json可以采用Python数据层次结构,并将它们转换为字符串表示形式; 这个过程称为序列化。从字符串表示中重建数据称为反序列化。在序列化和反序列化之间,表示对象的字符串可能已存储在文件或数据中,或通过网络连接发送到某个远程机器。
注意
JSON格式通常被现代应用程序用于允许数据交换。许多程序员已经熟悉它,这使其成为互操作性的良好选择。
如果您有一个对象x,则可以使用一行简单的代码查看其JSON字符串表示:
>>> import json
>>> json.dumps([1, 'simple', 'list'])
'[1, "simple", "list"]'
dumps()调用该函数的另一个变体dump(),只是将对象序列化为文本文件。因此,如果f是一个 文本文件,对象为写入打开,我们可以这样做:
json.dump(x, f)
要再次解码对象,if f是一个已打开以供阅读的文本文件对象:
x = json.load(f)
这种简单的序列化技术可以处理列表和字典,但是在JSON中序列化任意类实例需要额外的努力。该json模块的参考包含对此的解释。
八.错误和异常
到目前为止,错误消息还没有提到,但是如果你已经尝试过这些例子,你可能已经看过了一些。存在(至少)两种可区分的错误:语法错误和异常。
8.1 语法错误
语法错误(也称为解析错误)可能是您在学习Python时最常见的抱怨:
>>> while True print('Hello world')
File "<stdin>", line 1
while True print('Hello world')
^
SyntaxError: invalid syntax
解析器重复出现违规行,并显示一个指向检测到错误的行中最早点的“箭头”。该错误是由箭头前面的标记引起的(或至少在其中检测到的):在该示例中,在函数处检测到错误print(),因为':'在它之前缺少冒号()。打印文件名和行号,以便在输入来自脚本时知道查找位置。
8.2 异常
即使语句或表达式在语法上是正确的,但在尝试执行它时可能会导致错误。在执行期间检测到的错误称为异常,并且不是无条件致命的:您将很快学会如何在Python程序中处理它们。但是,大多数异常都不是由程序处理的,并导致错误消息,如下所示:
>>> 10 * (1/0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ZeroDivisionError: division by zero
>>> 4 + spam*3
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'spam' is not defined
>>> '2' + 2
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: Can't convert 'int' object to str implicitly
错误消息的最后一行表明发生了什么。异常有不同的类型,类型作为消息的一部分打印出来:示例中的类型是ZeroDivisionError,NameError和TypeError。作为异常类型打印的字符串是发生的内置异常的名称。对于所有内置异常都是如此,但对于用户定义的异常不一定是这样(尽管它是一个有用的约定)。标准异常名称是内置标识符(不是保留关键字)。
该行的其余部分根据异常类型及其原因提供详细信息。
错误消息的前一部分以堆栈回溯的形式显示发生异常的上下文。通常它包含列出源代码行的堆栈回溯; 但是,它不会显示从标准输入读取的行。
内置异常列出了内置异常及其含义。
8.3 处理异常
可以编写处理所选异常的程序。请查看以下示例,该示例要求用户输入,直到输入有效整数,但允许用户中断程序(使用Control-C或操作系统支持的任何内容); 请注意,通过引发KeyboardInterrupt异常来发出用户生成的中断信号。
>>> while True:
... try:
... x = int(input("Please enter a number: "))
... break
... except ValueError:
... print("Oops! That was no valid number. Try again...")
...
该try声明的工作原理如下。
- 首先,执行try子句(
try和except关键字之间的语句)。 - 如果没有发生异常,则跳过except子句并
try完成语句的执行 。 - 如果在执行try子句期间发生异常,则跳过该子句的其余部分。然后,如果其类型匹配在
except关键字后面命名的异常 ,则执行except子句,然后在try语句之后继续执行。 - 如果发生的异常与except子句中指定的异常不匹配,则将其传递给外部
try语句; 如果没有找到处理程序,则它是一个未处理的异常,执行将停止并显示如上所示的消息。
一个try语句可能有不止一个,除了子句,分别指定处理不同的异常。最多将执行一个处理程序。处理程序仅处理相应try子句中发生的异常,而不处理同一try语句的其他处理程序中的异常。except子句可以将多个异常命名为带括号的元组,例如:
... except (RuntimeError, TypeError, NameError):
... pass
如果except子句中的类与同一个类或其基类相同,则它与异常兼容(但不是相反 - 列出派生类的except子句与基类不兼容)。例如,以下代码将按以下顺序打印B,C,D:
class B(Exception):
pass class C(B):
pass class D(C):
pass for cls in [B, C, D]:
try:
raise cls()
except D:
print("D")
except C:
print("C")
except B:
print("B")
请注意,如果except子句被颠倒(第一个),它将打印B,B,B - 触发第一个匹配的except子句。except B
最后一个except子句可以省略异常名称,以用作通配符。请谨慎使用,因为以这种方式很容易掩盖真正的编程错误!它还可以用于打印错误消息,然后重新引发异常(允许调用者也处理异常):
import sys try:
f = open('myfile.txt')
s = f.readline()
i = int(s.strip())
except OSError as err:
print("OS error: {0}".format(err))
except ValueError:
print("Could not convert data to an integer.")
except:
print("Unexpected error:", sys.exc_info()[0])
raise
该try... except语句有一个可选的else子句,其中,如果存在的话,必须遵循所有的条款除外。如果try子句不引发异常,则对于必须执行的代码很有用。例如:
for arg in sys.argv[1:]:
try:
f = open(arg, 'r')
except OSError:
print('cannot open', arg)
else:
print(arg, 'has', len(f.readlines()), 'lines')
f.close()
使用该else子句比向该子句添加其他代码更好,try因为它避免意外捕获由try... except语句保护的代码未引发的异常。
发生异常时,它可能具有关联值,也称为异常参数。参数的存在和类型取决于异常类型。
except子句可以在异常名称后面指定一个变量。该变量绑定到存储参数的异常实例 instance.args。为方便起见,异常实例定义 __str__()了参数可以直接打印而无需引用.args。也可以在提升之前首先实例化异常,并根据需要向其添加任何属性。
>>> try:
... raise Exception('spam', 'eggs')
... except Exception as inst:
... print(type(inst)) # the exception instance
... print(inst.args) # arguments stored in .args
... print(inst) # __str__ allows args to be printed directly,
... # but may be overridden in exception subclasses
... x, y = inst.args # unpack args
... print('x =', x)
... print('y =', y)
...
<class 'Exception'>
('spam', 'eggs')
('spam', 'eggs')
x = spam
y = eggs
如果异常有参数,则它们将作为未处理异常的消息的最后一部分(“详细信息”)打印。
异常处理程序不仅处理异常(如果它们立即出现在try子句中),而且还发生在try子句中调用(甚至间接)的函数内部。例如:
>>> def this_fails():
... x = 1/0
...
>>> try:
... this_fails()
... except ZeroDivisionError as err:
... print('Handling run-time error:', err)
...
Handling run-time error: division by zero
8.4 提高异常
该raise语句允许程序员强制发生指定的异常。例如:
>>> raise NameError('HiThere')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: HiThere
唯一的参数raise表示要引发的异常。这必须是异常实例或异常类(派生自的类Exception)。如果传递了一个异常类,它将通过调用没有参数的构造函数来隐式实例化:
raise ValueError # shorthand for 'raise ValueError()'
如果您需要确定是否引发了异常但不打算处理它,则更简单的raise语句形式允许您重新引发异常:
>>> try:
... raise NameError('HiThere')
... except NameError:
... print('An exception flew by!')
... raise
...
An exception flew by!
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
NameError: HiThere
8.5 用户定义的异常
程序可以通过创建新的异常类来命名它们自己的异常(有关Python类的更多信息,请参阅 类)。通常应Exception直接或间接地从类中派生异常。
可以定义异常类,它可以执行任何其他类可以执行的任何操作,但通常保持简单,通常只提供许多属性,这些属性允许处理程序为异常提取有关错误的信息。在创建可能引发多个不同错误的模块时,通常的做法是为该模块定义的异常创建基类,并为不同错误条件创建特定异常类的子类:
class Error(Exception):
"""Base class for exceptions in this module."""
pass class InputError(Error):
"""Exception raised for errors in the input. Attributes:
expression -- input expression in which the error occurred
message -- explanation of the error
""" def __init__(self, expression, message):
self.expression = expression
self.message = message class TransitionError(Error):
"""Raised when an operation attempts a state transition that's not
allowed. Attributes:
previous -- state at beginning of transition
next -- attempted new state
message -- explanation of why the specific transition is not allowed
""" def __init__(self, previous, next, message):
self.previous = previous
self.next = next
self.message = message
大多数异常都定义为名称以“错误”结尾,类似于标准异常的命名。
许多标准模块定义了它们自己的异常,以报告它们定义的函数中可能出现的错误。有关类的更多信息,请参见类Classes。
8.6 定义清理动作
该try语句有另一个可选子句,用于定义必须在所有情况下执行的清理操作。例如:
>>> try:
... raise KeyboardInterrupt
... finally:
... print('Goodbye, world!')
...
Goodbye, world!
KeyboardInterrupt
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
一个finally子句在离开之前一直执行try 的语句,是否已经发生也不例外。当try子句中发生异常且未被except子句处理 (或者它已经发生在except或 else子句中)时,在finally子句执行后重新引发它。该finally条款也被执行“的出路”的时候,任何其他条款try的语句是通过左 break,continue或return声明。一个更复杂的例子:
>>> def divide(x, y):
... try:
... result = x / y
... except ZeroDivisionError:
... print("division by zero!")
... else:
... print("result is", result)
... finally:
... print("executing finally clause")
...
>>> divide(2, 1)
result is 2.0
executing finally clause
>>> divide(2, 0)
division by zero!
executing finally clause
>>> divide("2", "1")
executing finally clause
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 3, in divide
TypeError: unsupported operand type(s) for /: 'str' and 'str'
如您所见,该finally子句在任何情况下都会执行。TypeError通过划分两个字符串而 引发的内容不由该except子句处理 ,因此在该finally 子句执行后重新引发。
在实际应用程序中,该finally子句对于释放外部资源(例如文件或网络连接)非常有用,无论资源的使用是否成功。
8.7 预定义的清理操作
某些对象定义了在不再需要该对象时要执行的标准清理操作,无论使用该对象的操作是成功还是失败。请查看以下示例,该示例尝试打开文件并将其内容打印到屏幕上。
for line in open("myfile.txt"):
print(line, end="")
此代码的问题在于,在部分代码执行完毕后,它会使文件保持打开一段不确定的时间。这在简单脚本中不是问题,但对于较大的应用程序可能是一个问题。该with语句允许以一种方式使用文件等对象,以确保始终及时正确地清理它们。
with open("myfile.txt") as f:
for line in f:
print(line, end="")
执行语句后,即使在处理行时遇到问题,文件f也始终关闭。与文件一样,提供预定义清理操作的对象将在其文档中指出这一点。
九.类
类提供了将数据和功能捆绑在一起的方法。创建新类会创建一种新类型的对象,从而允许创建该类型的新实例。每个类实例都可以附加属性以维护其状态。类实例还可以具有用于修改其状态的方法(由其类定义)。
与其他编程语言相比,Python的类机制添加了具有最少新语法和语义的类。它是C ++和Modula-3中的类机制的混合体。Python类提供面向对象编程的所有标准功能:类继承机制允许多个基类,派生类可以覆盖其基类或类的任何方法,并且方法可以调用具有相同名称的基类的方法。对象可以包含任意数量和种类的数据。与模块一样,类依赖于Python的动态特性:它们是在运行时创建的,并且可以在创建后进一步修改。
在C ++术语中,通常类成员(包括数据成员)是 公共的(除了参见下面的私有变量),并且所有成员函数都是 虚拟的。与在Modula-3中一样,没有用于从其方法引用对象成员的简写:方法函数使用表示对象的显式第一个参数声明,该参数由调用隐式提供。与Smalltalk一样,类本身也是对象。这为导入和重命名提供了语义。与C ++和Modula-3不同,内置类型可以用作用户扩展的基类。此外,与C ++一样,大多数具有特殊语法(算术运算符,下标等)的内置运算符都可以重新定义为类实例。
(由于缺乏普遍接受的术语来讨论类,我偶尔会使用Smalltalk和C ++术语。我会使用Modula-3术语,因为它的面向对象语义比C ++更接近Python,但我希望读者很少听说过。)
9.1 一个关于名称和对象的词
对象具有个性,多个名称(在多个范围内)可以绑定到同一个对象。这在其他语言中称为别名。乍一看Python时通常不会理解这一点,在处理不可变的基本类型(数字,字符串,元组)时可以安全地忽略它。但是,别名对涉及可变对象(如列表,字典和大多数其他类型)的Python代码的语义可能会产生惊人的影响。这通常用于程序的好处,因为别名在某些方面表现得像指针。例如,传递一个对象很便宜,因为实现只传递一个指针; 如果函数修改了作为参数传递的对象,调用者将看到更改 - 这消除了对Pascal中两个不同的参数传递机制的需要。
9.2 Python范围和命名空间
在介绍类之前,我首先要告诉你一些Python的范围规则。类定义对命名空间有一些巧妙的技巧,你需要知道范围和命名空间如何工作才能完全理解正在发生的事情。顺便说一下,关于这个主题的知识对任何高级Python程序员都很有用。
让我们从一些定义开始。
一个命名空间是从名字到对象的映射。大多数名称空间当前都是作为Python词典实现的,但通常不会以任何方式显示(性能除外),并且它可能在将来发生变化。命名空间的示例是:内置名称集(包含诸如abs()和内置异常名称之类的函数); 模块中的全局名称; 和函数调用中的本地名称。在某种意义上,对象的属性集也形成了命名空间。关于命名空间的重要一点是,不同命名空间中的名称之间绝对没有关系; 例如,两个不同的模块都可以定义函数maximize而不会产生混淆 - 模块的用户必须在其前面加上模块名称。
顺便说一句,我对word 后面的任何名称使用word 属性 - 例如,在表达式中z.real,real是对象的属性 z。严格地说,对模块中名称的引用是属性引用:在表达式中modname.funcname,modname是模块对象并且funcname是它的属性。在这种情况下,模块的属性和模块中定义的全局名称之间恰好有一个直接的映射:它们共享相同的命名空间![1]
属性可以是只读的或可写的。在后一种情况下,可以分配属性。模块属性是可写的:你可以写 。可写属性也可以使用语句删除 。例如,将从名为的对象中删除该属性。modname.the_answer = 42deldelmodname.the_answerthe_answermodname
命名空间在不同时刻创建,具有不同的生命周期。包含内置名称的命名空间是在Python解释器启动时创建的,并且永远不会被删除。读入模块定义时会创建模块的全局命名空间; 通常,模块名称空间也会一直持续到解释器退出。由解释程序的顶级调用执行的语句(从脚本文件读取或交互式读取)被视为调用模块的一部分__main__,因此它们具有自己的全局命名空间。(内置名称实际上也存在于模块中;这称为builtins。)
函数的本地命名空间在调用函数时创建,并在函数返回或引发函数内未处理的异常时删除。(实际上,遗忘是描述实际情况的更好方法。)当然,递归调用每个都有自己的本地命名空间。
甲范围是Python程序,其中一个命名空间是可直接访问的文本区域。这里的“可直接访问”意味着对名称的非限定引用会尝试在命名空间中查找名称。
尽管范围是静态确定的,但它们是动态使用的。在执行期间的任何时候,至少有三个嵌套的作用域,其名称空间可以直接访问:
- 最先搜索的最内部范围包含本地名称
- 从最近的封闭范围开始搜索的任何封闭函数的范围包含非本地名称,也包括非全局名称
- 倒数第二个范围包含当前模块的全局名称
- 最外面的范围(最后搜索)是包含内置名称的命名空间
如果名称声明为全局,则所有引用和赋值将直接转到包含模块全局名称的中间作用域。要重新绑定在最内层范围之外找到的变量,nonlocal可以使用该语句; 如果没有声明为非本地变量,那些变量是只读的(尝试写入这样的变量只会在最里面的范围内创建一个新的局部变量,保持同名的外部变量不变)。
通常,本地范围引用(文本)当前函数的本地名称。在外部函数中,本地作用域引用与全局作用域相同的名称空间:模块的名称空间。类定义在本地范围中放置另一个命名空间。
重要的是要意识到范围是以文本方式确定的:模块中定义的函数的全局范围是模块的命名空间,无论从何处或通过调用函数的别名。另一方面,名称的实际搜索是在运行时动态完成的 - 但是,语言定义在“编译”时朝着静态名称解析发展,所以不要依赖于动态名称解析!(事实上,局部变量已经静态确定。)
Python的一个特殊之处在于 - 如果没有global语句生效 - 对名称的赋值总是进入最内层范围。分配不复制数据 - 它们只是将名称绑定到对象。删除也是如此:该语句删除了本地范围引用的命名空间的绑定。实际上,引入新名称的所有操作都使用本地范围:特别是,语句和函数定义绑定本地范围中的模块或函数名称。del xximport
该global陈述可用于表明特定变量存在于全球范围内,并应在那里反弹; 该 nonlocal陈述表明特定变量存在于封闭范围内,应该在那里反弹。
9.2.1 范围和命名空间示例
这是一个例子展示了如何引用不同的范围和命名空间,以及如何global和nonlocal影响可变结合:
def scope_test():
def do_local():
spam = "local spam" def do_nonlocal():
nonlocal spam
spam = "nonlocal spam" def do_global():
global spam
spam = "global spam" spam = "test spam"
do_local()
print("After local assignment:", spam)
do_nonlocal()
print("After nonlocal assignment:", spam)
do_global()
print("After global assignment:", spam) scope_test()
print("In global scope:", spam)
示例代码的输出是:
After local assignment: test spam
After nonlocal assignment: nonlocal spam
After global assignment: nonlocal spam
In global scope: global spam
请注意本地分配(默认)如何不改变scope_test对垃圾邮件的绑定。该nonlocal分配改变了scope_test对垃圾邮件的绑定,并且该global分配更改了模块级绑定。
您还可以在分配之前 看到之前没有垃圾邮件绑定global。
9.3 初看类
类引入了一些新语法,三种新对象类型和一些新语义。
9.3.1 类定义语法
最简单的类定义形式如下所示:
class ClassName:
<statement-1>
.
.
.
<statement-N>
类定义,如函数定义(def语句)必须在它们产生任何影响之前执行。(您可以想象将类定义放在if语句的分支中,或者放在函数内部。)
实际上,类定义中的语句通常是函数定义,但其他语句是允许的,有时也很有用 - 我们稍后会再回过头来讨论它。类中的函数定义通常具有一种特殊形式的参数列表,由方法的调用约定决定 - 再次,这将在后面解释。
输入类定义时,会创建一个新的命名空间,并将其用作本地范围 - 因此,对局部变量的所有赋值都将进入此新命名空间。特别是,函数定义在此处绑定新函数的名称。
正常保留类定义(通过结尾)时,会创建一个类对象。这基本上是类定义创建的命名空间内容的包装器; 我们将在下一节中了解有关类对象的更多信息。恢复原始本地范围(在输入类定义之前生效的范围),并且类对象在此处绑定到类定义标头(ClassName在示例中)中给出的类名。
9.3.2 类对象
类对象支持两种操作:属性引用和实例化。
属性引用使用Python中所有属性引用使用的标准语法:obj.name。有效的属性名称是创建类对象时类的命名空间中的所有名称。所以,如果类定义看起来像这样:
class MyClass:
"""A simple example class"""
i = 12345 def f(self):
return 'hello world'
然后MyClass.i和MyClass.f是有效的属性的引用,分别返回一个整数和一个功能对象。也可以为类属性分配,因此您可以MyClass.i通过赋值更改值。 __doc__也是一个有效的属性,返回属于该类的docstring : ."A simple exampleclass"
类实例化使用函数表示法。只是假装类对象是一个无参数函数,它返回一个新的类实例。例如(假设上述类):
x = MyClass()
创建类的新实例,并将此对象分配给局部变量x。
实例化操作(“调用”类对象)创建一个空对象。许多类喜欢创建具有针对特定初始状态定制的实例的对象。因此,类可以定义一个名为的特殊方法 __init__(),如下所示:
def __init__(self):
self.data = []
当类定义__init__()方法时,类实例化会自动调用__init__()新创建的类实例。因此,在此示例中,可以通过以下方式获取新的初始化实例:
x = MyClass()
当然,该__init__()方法可能具有更大灵活性的论据。在这种情况下,将给予类实例化运算符的参数传递给__init__()。例如,
>>> class Complex:
... def __init__(self, realpart, imagpart):
... self.r = realpart
... self.i = imagpart
...
>>> x = Complex(3.0, -4.5)
>>> x.r, x.i
(3.0, -4.5)
9.3.3 实例对象
现在我们可以用实例对象做什么?实例对象理解的唯一操作是属性引用。有两种有效的属性名称,数据属性和方法。
数据属性对应于Smalltalk中的“实例变量”,以及C ++中的“数据成员”。不需要声明数据属性; 就像局部变量一样,它们在第一次被分配时就会存在。例如,如果 x是MyClass上面创建的实例,则以下代码段将打印该值16,而不留下跟踪:
x.counter = 1
while x.counter < 10:
x.counter = x.counter * 2
print(x.counter)
del x.counter
另一种实例属性引用是一种方法。方法是“属于”对象的函数。(在Python中,术语方法不是类实例唯一的:其他对象类型也可以有方法。例如,列表对象具有名为append,insert,remove,sort等的方法。但是,在下面的讨论中,除非另有明确说明,否则我们将专门使用术语方法来表示类实例对象的方法。)
实例对象的有效方法名称取决于其类。根据定义,作为函数对象的类的所有属性都定义其实例的相应方法。所以在我们的例子中,x.f是一个有效的方法引用,因为它MyClass.f是一个函数,但x.i不是,因为 MyClass.i它不是。但x.f它不是同一个东西MyClass.f- 它是一个方法对象,而不是一个函数对象。
9.3.4 方法对象
通常,绑定后立即调用方法:
x.f()
在MyClass示例中,这将返回字符串。但是,没有必要立即调用方法:是一个方法对象,可以存储起来并在以后调用。例如:'hello world'x.f
xf = x.f
while True:
print(xf())
将继续打印,直到时间结束。hello world
调用方法时到底发生了什么?您可能已经注意到, x.f()上面没有参数调用,即使f()指定参数的函数定义。这个论点怎么了?当一个需要参数的函数被调用而没有任何东西时,Python肯定会引发异常 - 即使参数实际上没有被使用......
实际上,您可能已经猜到了答案:方法的特殊之处在于实例对象作为函数的第一个参数传递。在我们的示例中,调用x.f()完全等同于MyClass.f(x)。通常,使用n个参数列表调用方法等效于使用通过在第一个参数之前插入方法的实例对象而创建的参数列表来调用相应的函数。
如果您仍然不了解方法的工作原理,那么查看实现可能会澄清问题。当引用不是数据属性的实例属性时,将搜索其类。如果名称表示作为函数对象的有效类属性,则通过打包(指向)实例对象和刚在抽象对象中找到的函数对象来创建方法对象:这是方法对象。当使用参数列表调用方法对象时,将从实例对象和参数列表构造新的参数列表,并使用此新参数列表调用函数对象。
9.3.5 类和实例变量
一般来说,实例变量是针对每个实例唯一的数据,而类变量是针对类的所有实例共享的属性和方法:
class Dog:
kind = 'canine' # class variable shared by all instances
def __init__(self, name):
self.name = name # instance variable unique to each instance
>>> d = Dog('Fido')
>>> e = Dog('Buddy')
>>> d.kind # shared by all dogs
'canine'
>>> e.kind # shared by all dogs
'canine'
>>> d.name # unique to d
'Fido'
>>> e.name # unique to e
'Buddy'
正如在关于名称和对象的单词中所讨论的,共享数据可能具有令人惊讶的效果,涉及可变对象,例如列表和字典。例如,以下代码中的技巧列表不应该用作类变量,因为所有Dog 实例只共享一个列表:
class Dog:
tricks = [] # mistaken use of a class variable
def __init__(self, name):
self.name = name
def add_trick(self, trick):
self.tricks.append(trick)
>>> d = Dog('Fido')
>>> e = Dog('Buddy')
>>> d.add_trick('roll over')
>>> e.add_trick('play dead')
>>> d.tricks # unexpectedly shared by all dogs
['roll over', 'play dead']
正确设计类应该使用实例变量:
class Dog:
def __init__(self, name):
self.name = name
self.tricks = [] # creates a new empty list for each dog
def add_trick(self, trick):
self.tricks.append(trick)
>>> d = Dog('Fido')
>>> e = Dog('Buddy')
>>> d.add_trick('roll over')
>>> e.add_trick('play dead')
>>> d.tricks
['roll over']
>>> e.tricks
['play dead']
9.4 随机备注
数据属性覆盖具有相同名称的方法属性; 为了避免可能导致大型程序中难以发现的错误的意外名称冲突,使用某种最小化冲突机会的约定是明智的。可能的约定包括大写方法名称,使用小的唯一字符串(可能只是下划线)为数据属性名称加前缀,或者使用动词作为数据属性的方法和名词。
数据属性可以由方法以及对象的普通用户(“客户端”)引用。换句话说,类不可用于实现纯抽象数据类型。事实上,Python中没有任何东西可以强制执行数据隐藏 - 它完全基于约定。(另一方面,用C语言编写的Python实现可以完全隐藏实现细节并在必要时控制对对象的访问;这可以由用C编写的Python的扩展来使用。)
客户端应谨慎使用数据属性 - 客户端可能会通过标记其数据属性来破坏方法维护的不变量。请注意,客户端可以将自己的数据属性添加到实例对象,而不会影响方法的有效性,只要避免名称冲突 - 同样,命名约定可以在这里节省很多麻烦。
从方法中引用数据属性(或其他方法!)没有简写。我发现这实际上增加了方法的可读性:当浏览方法时,没有可能混淆局部变量和实例变量。
通常,调用方法的第一个参数self。这只不过是一个惯例:这个名字self对Python来说绝对没有特殊意义。但请注意,如果不遵循惯例,您的代码可能对其他Python程序员来说可读性较低,并且可以想象可能会编写依赖于此类约定的 类浏览器程序。
作为类属性的任何函数对象都为该类的实例定义了一个方法。函数定义不必在文本中包含在类定义中:将函数对象赋值给类中的局部变量也是可以的。例如:
# Function defined outside the class
def f1(self, x, y):
return min(x, x+y) class C:
f = f1 def g(self):
return 'hello world' h = g
现在f,g并且h是类的所有属性都C引用了函数对象,因此它们都是实例的方法 C- h完全等同于g。请注意,这种做法通常只会使程序的读者感到困惑。
方法可以通过使用self 参数的方法属性来调用其他方法:
class Bag:
def __init__(self):
self.data = [] def add(self, x):
self.data.append(x) def addtwice(self, x):
self.add(x)
self.add(x)
方法可以以与普通函数相同的方式引用全局名称。与方法关联的全局范围是包含其定义的模块。(一个类永远不会被用作全局范围。)虽然很少遇到在方法中使用全局数据的充分理由,但是全局范围有许多合法用途:一方面,导入全局范围的函数和模块可以由方法,以及在其中定义的函数和类使用。通常,包含该方法的类本身在此全局范围内定义,在下一节中,我们将找到一些方法想要引用其自己的类的一些很好的理由。
每个值都是一个对象,因此有一个类(也称为其类型)。它存储为object.__class__。
9.5 继承
当然,如果不支持继承,语言特性就不值得称为“类”。派生类定义的语法如下所示:
class DerivedClassName(BaseClassName):
<statement-1>
.
.
.
<statement-N>
名称BaseClassName必须在含有派生类定义中的范围来限定。代替基类名称,也允许使用其他任意表达式。这可能很有用,例如,在另一个模块中定义基类时:
class DerivedClassName(modname.BaseClassName):
派生类定义的执行与基类的执行相同。构造类对象时,会记住基类。这用于解析属性引用:如果在类中找不到请求的属性,则搜索继续查找基类。如果基类本身是从其他类派生的,则递归应用此规则。
关于派生类的实例化没有什么特别之处: DerivedClassName()创建一个新的类实例。方法引用按如下方式解析:搜索相应的类属性,如果需要,沿着基类链向下移动,如果生成函数对象,则方法引用有效。
派生类可以覆盖其基类的方法。因为方法在调用同一对象的其他方法时没有特殊权限,所以调用同一基类中定义的另一个方法的基类方法最终可能会调用覆盖它的派生类的方法。(对于C ++程序员:Python中的所有方法都是有效的virtual。)
派生类中的重写方法实际上可能希望扩展而不是简单地替换同名的基类方法。有一种直接调用基类方法的简单方法:只需调用即可。这对客户来说偶尔也很有用。(请注意,这仅在基类可以在全局范围内访问时才有效。)BaseClassName.methodname(self, arguments)BaseClassName
Python有两个内置函数可以继承:
- 使用
isinstance()检查实例的类型: 会,如果仅是或来源于一些类。isinstance(obj,int)Trueobj.__class__intint - 使用
issubclass()检查类继承: 是,因为是的子类。然而, 就是因为不是一个子类。issubclass(bool,int)Trueboolintissubclass(float, int)Falsefloatint
9.5.1 多重继承
Python也支持多重继承的形式。具有多个基类的类定义如下所示:
class DerivedClassName(Base1, Base2, Base3):
<statement-1>
.
.
.
<statement-N>
在大多数情况下,在最简单的情况下,您可以将从父类继承的属性的搜索视为深度优先,从左到右,而不是在层次结构中存在重叠的同一类中搜索两次。因此,如果没有找到属性,则在DerivedClassName其中搜索Base1,然后(递归地)搜索它Base1,如果在那里找不到,则搜索它Base2,依此类推。
事实上,它稍微复杂一些; 方法解析顺序动态变化以支持协作调用super()。这种方法在一些其他多继承语言中称为call-next-method,并且比单继承语言中的超级调用更强大。
动态排序是必要的,因为所有多重继承的情况都表现出一个或多个菱形关系(其中至少有一个父类可以通过最底层的多个路径访问)。例如,所有类都继承自object,因此任何多重继承的情况都提供了多个到达的路径object。为了防止基类被多次访问,动态算法将搜索顺序线性化,以保留每个类中指定的从左到右的顺序,只调用每个父类一次,这是单调的(意思是一个类可以被子类化,而不会影响其父级的优先顺序)。总之,这些属性使得设计具有多重继承的可靠且可扩展的类成为可能。有关详细信息,请参阅https://www.python.org/download/releases/2.3/mro/。
9.6 私有变量
Python中不存在除对象内部之外无法访问的“私有”实例变量。但是,大多数Python代码都遵循一个约定:以下划线(例如_spam)为前缀的名称应被视为API的非公共部分(无论是函数,方法还是数据成员)。它应被视为实施细节,如有更改,恕不另行通知。
由于类私有成员有一个有效的用例(即为了避免名称与子类定义的名称冲突),因此对这种称为名称修改的机制的支持有限。表单的任何标识符 __spam(至少两个前导下划线,最多一个尾随下划线)在文本上替换为_classname__spam,其中classname当前类名称带有前导下划线。只要它出现在类的定义中,就可以在不考虑标识符的句法位置的情况下完成这种修改。
名称修改有助于让子类覆盖方法而不破坏类内方法调用。例如:
class Mapping:
def __init__(self, iterable):
self.items_list = []
self.__update(iterable) def update(self, iterable):
for item in iterable:
self.items_list.append(item) __update = update # private copy of original update() method class MappingSubclass(Mapping): def update(self, keys, values):
# provides new signature for update()
# but does not break __init__()
for item in zip(keys, values):
self.items_list.append(item)
请注意,修剪规则主要是为了避免事故; 它仍然可以访问或修改被视为私有的变量。这在特殊情况下甚至可能很有用,例如在调试器中。
请注意,代码传递给exec()或eval()不将调用类的类名视为当前类; 这类似于global语句的效果,其效果同样限于字节编译在一起的代码。同样的限制也适用于 getattr(),setattr()与delattr(),以及引用时为 __dict__直接。
9.7 赔率和结束
有时,使用类似于Pascal“record”或C“struct”的数据类型是有用的,将一些命名数据项捆绑在一起。一个空的类定义可以很好地完成:
class Employee:
pass john = Employee() # Create an empty employee record # Fill the fields of the record
john.name = 'John Doe'
john.dept = 'computer lab'
john.salary = 1000
需要特定抽象数据类型的Python代码通常可以传递一个模拟该数据类型方法的类。例如,如果您有一个从文件对象格式化某些数据的函数,则可以使用方法定义一个类,read()然后readline()从字符串缓冲区获取数据,并将其作为参数传递。
实例方法对象也具有属性:m.__self__是具有该方法的实例对象m(),并且m.__func__是与该方法对应的函数对象。
9.8 迭代器
到目前为止,您可能已经注意到大多数容器对象都可以使用for语句循环:
for element in [1, 2, 3]:
print(element)
for element in (1, 2, 3):
print(element)
for key in {'one':1, 'two':2}:
print(key)
for char in "123":
print(char)
for line in open("myfile.txt"):
print(line, end='')
这种访问方式清晰,简洁,方便。迭代器的使用遍及并统一了Python。在幕后,for语句调用iter()容器对象。该函数返回一个迭代器对象,该对象定义__next__()一次访问容器中元素的方法。当没有更多元素时, __next__()引发一个StopIteration异常,告诉 for循环终止。您可以__next__()使用next()内置函数调用该方法; 这个例子说明了它是如何工作的:
>>> s = 'abc'
>>> it = iter(s)
>>> it
<iterator object at 0x00A1DB50>
>>> next(it)
'a'
>>> next(it)
'b'
>>> next(it)
'c'
>>> next(it)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
next(it)
StopIteration
看过迭代器协议背后的机制,很容易将迭代器行为添加到类中。定义一个使用__iter__()方法返回对象的__next__()方法。如果类定义了__next__(),那么__iter__()可以返回self:
class Reverse:
"""Iterator for looping over a sequence backwards."""
def __init__(self, data):
self.data = data
self.index = len(data) def __iter__(self):
return self def __next__(self):
if self.index == 0:
raise StopIteration
self.index = self.index - 1
return self.data[self.index]
>>> rev = Reverse('spam')
>>> iter(rev)
<__main__.Reverse object at 0x00A1DB50>
>>> for char in rev:
... print(char)
...
m
a
p
s
9.9 发电机
Generator是一个用于创建迭代器的简单而强大的工具。它们像常规函数一样编写,但yield只要他们想要返回数据就使用该语句。每次next()调用它时,生成器从它停止的地方恢复(它记住所有数据值和上次执行的语句)。一个例子表明,生成器很容易创建:
def reverse(data):
for index in range(len(data)-1, -1, -1):
yield data[index]
>>> for char in reverse('golf'):
... print(char)
...
f
l
o
g
任何可以使用生成器完成的操作也可以使用基于类的迭代器完成,如上一节中所述。使发电机如此紧凑的原因是__iter__()和__next__()方法是自动创建的。
另一个关键特性是在调用之间自动保存局部变量和执行状态。与使用self.index 和等实例变量的方法相比,这使得函数更容易编写并且更加清晰self.data。
除了自动创建方法和保存程序状态外,当生成器终止时,它们会自动引发StopIteration。结合使用这些功能,可以轻松创建迭代器,而不需要编写常规函数。
9.10 生成器表达式
一些简单的生成器可以使用类似于列表推导的语法简洁地编码为表达式,但使用括号而不是方括号。这些表达式适用于通过封闭函数立即使用生成器的情况。生成器表达式比完整的生成器定义更紧凑但功能更少,并且往往比等效列表推导更具内存友好性。
例子:
>>> sum(i*i for i in range(10)) # sum of squares
285 >>> xvec = [10, 20, 30]
>>> yvec = [7, 5, 3]
>>> sum(x*y for x,y in zip(xvec, yvec)) # dot product
260 >>> from math import pi, sin
>>> sine_table = {x: sin(x*pi/180) for x in range(0, 91)} >>> unique_words = set(word for line in page for word in line.split()) >>> valedictorian = max((student.gpa, student.name) for student in graduates) >>> data = 'golf'
>>> list(data[i] for i in range(len(data)-1, -1, -1))
['f', 'l', 'o', 'g']
十.标准库简介
10.1 操作系统接口
该os模块提供了许多与操作系统交互的功能:
>>> import os
>>> os.getcwd() # Return the current working directory
'C:\\Python36'
>>> os.chdir('/server/accesslogs') # Change current working directory
>>> os.system('mkdir today') # Run the command mkdir in the system shell
0
一定要使用样式而不是。这将不会影响内置函数,该函数的运行方式大不相同。import osfrom os import*os.open()open()
内置函数dir()和help()函数可用作处理大型模块的交互式辅助工具,例如os:
>>> import os
>>> dir(os)
<returns a list of all module functions>
>>> help(os)
<returns an extensive manual page created from the module's docstrings>
对于日常文件和目录管理任务,该shutil模块提供了更易于使用的更高级别的界面:
>>> import shutil
>>> shutil.copyfile('data.db', 'archive.db')
'archive.db'
>>> shutil.move('/build/executables', 'installdir')
'installdir'
10.2 文件通配符
该glob模块提供了从目录通配符搜索中创建文件列表的功能:
>>> import glob
>>> glob.glob('*.py')
['primes.py', 'random.py', 'quote.py']
10.3 命令行参数
通用实用程序脚本通常需要处理命令行参数。这些参数作为列表存储在sys模块的argv属性中。例如,以下输出来自在命令行运行:python demo.py one two three
>>> import sys
>>> print(sys.argv)
['demo.py', 'one', 'two', 'three']
该getopt模块使用Unix 函数的约定 处理sys.argvgetopt()。该argparse模块提供了更强大和灵活的命令行处理。
10.4 错误输出重定向和程序终止
该sys模块还具有stdin,stdout和stderr的属性。后者对于发出警告和错误消息非常有用,即使在重定向stdout时也可以看到它们:
>>> sys.stderr.write('Warning, log file not found starting a new one\n')
Warning, log file not found starting a new one
终止脚本的最直接方法是使用sys.exit()。
10.5 字符串模式匹配
该re模块为高级字符串处理提供正则表达式工具。对于复杂的匹配和操作,正则表达式提供了简洁,优化的解决方案:
>>> import re
>>> re.findall(r'\bf[a-z]*', 'which foot or hand fell fastest')
['foot', 'fell', 'fastest']
>>> re.sub(r'(\b[a-z]+) \1', r'\1', 'cat in the the hat')
'cat in the hat'
当只需要简单的功能时,首选字符串方法,因为它们更易于阅读和调试:
>>> 'tea for too'.replace('too', 'two')
'tea for two'
10.6 数学
该math模块提供对浮点数学的底层C库函数的访问:
>>> import math
>>> math.cos(math.pi / 4)
0.70710678118654757
>>> math.log(1024, 2)
10.0
该random模块提供了进行随机选择的工具:
>>> import random
>>> random.choice(['apple', 'pear', 'banana'])
'apple'
>>> random.sample(range(100), 10) # sampling without replacement
[30, 83, 16, 4, 8, 81, 41, 50, 18, 33]
>>> random.random() # random float
0.17970987693706186
>>> random.randrange(6) # random integer chosen from range(6)
4
该statistics模块计算数值数据的基本统计属性(均值,中位数,方差等):
>>> import statistics
>>> data = [2.75, 1.75, 1.25, 0.25, 0.5, 1.25, 3.5]
>>> statistics.mean(data)
1.6071428571428572
>>> statistics.median(data)
1.25
>>> statistics.variance(data)
1.3720238095238095
SciPy项目< https://scipy.org >有许多其他模块用于数值计算。
10.7 上网
有许多模块可用于访问互联网和处理互联网协议。其中两个最简单的方法是urllib.request从URL检索数据和smtplib发送邮件:
>>> from urllib.request import urlopen
>>> with urlopen('http://tycho.usno.navy.mil/cgi-bin/timer.pl') as response:
... for line in response:
... line = line.decode('utf-8') # Decoding the binary data to text.
... if 'EST' in line or 'EDT' in line: # look for Eastern Time
... print(line) <BR>Nov. 25, 09:43:32 PM EST >>> import smtplib
>>> server = smtplib.SMTP('localhost')
>>> server.sendmail('soothsayer@example.org', 'jcaesar@example.org',
... """To: jcaesar@example.org
... From: soothsayer@example.org
...
... Beware the Ides of March.
... """)
>>> server.quit()
(请注意,第二个示例需要在localhost上运行的邮件服务器。)
10.8 日期和时间
该datetime模块提供了以简单和复杂的方式操作日期和时间的类。虽然支持日期和时间算法,但实现的重点是有效的成员提取以进行输出格式化和操作。该模块还支持时区感知的对象。
>>> # dates are easily constructed and formatted
>>> from datetime import date
>>> now = date.today()
>>> now
datetime.date(2003, 12, 2)
>>> now.strftime("%m-%d-%y. %d %b %Y is a %A on the %d day of %B.")
'12-02-03. 02 Dec 2003 is a Tuesday on the 02 day of December.' >>> # dates support calendar arithmetic
>>> birthday = date(1964, 7, 31)
>>> age = now - birthday
>>> age.days
14368
10.9 数据压缩
:共同数据存档和压缩格式直接由模块,包括支持zlib,gzip,bz2,lzma,zipfile和 tarfile。
>>> import zlib
>>> s = b'witch which has which witches wrist watch'
>>> len(s)
41
>>> t = zlib.compress(s)
>>> len(t)
37
>>> zlib.decompress(t)
b'witch which has which witches wrist watch'
>>> zlib.crc32(s)
226805979
10.10 绩效评估
一些Python用户对了解同一问题的不同方法的相对性能产生了浓厚的兴趣。Python提供了一种可以立即回答这些问题的测量工具。
例如,使用元组打包和解包功能而不是传统方法来交换参数可能很诱人。该timeit 模块快速展示了适度的性能优势:
>>> from timeit import Timer
>>> Timer('t=a; a=b; b=t', 'a=1; b=2').timeit()
0.57535828626024577
>>> Timer('a,b = b,a', 'a=1; b=2').timeit()
0.54962537085770791
10.11 质量控制
开发高质量软件的一种方法是在开发过程中为每个函数编写测试,并在开发过程中经常运行这些测试。
该doctest模块提供了一个工具,用于扫描模块并验证程序文档字符串中嵌入的测试。测试构造就像将典型调用及其结果剪切并粘贴到文档字符串一样简单。这通过向用户提供示例来改进文档,并且它允许doctest模块确保代码保持对文档的真实性:
def average(values):
"""Computes the arithmetic mean of a list of numbers. >>> print(average([20, 30, 70]))
40.0
"""
return sum(values) / len(values) import doctest
doctest.testmod() # automatically validate the embedded tests
该unittest模块不像模块那样轻松doctest,但它允许在单独的文件中维护更全面的测试集:
import unittest
class TestStatisticalFunctions(unittest.TestCase):
def test_average(self):
self.assertEqual(average([20, 30, 70]), 40.0)
self.assertEqual(round(average([1, 5, 7]), 1), 4.3)
with self.assertRaises(ZeroDivisionError):
average([])
with self.assertRaises(TypeError):
average(20, 30, 70)
unittest.main() # Calling from the command line invokes all tests
10.12 包含电池
Python具有“包含电池”的理念。通过其较大包装的复杂和强大功能可以最好地看到这一点。例如:
- 在
xmlrpc.client和xmlrpc.server模块实现远程过程调用了在琐碎的任务。尽管有模块名称,但不需要直接了解或处理XML。 - 该
email软件包是一个用于管理电子邮件的库,包括MIME和其他基于 RFC 2822的消息文档。不同于smtplib和poplib其实际上发送和接收消息,电子邮件封装具有用于构建或复杂的消息结构(包括附件)进行解码,并用于实现互联网编码和头协议的完整工具集。 - 该
json软件包为解析这种流行的数据交换格式提供了强大的支持。该csv模块支持以逗号分隔值格式直接读取和写入文件,这些格式通常由数据库和电子表格支持。XML处理是支持的xml.etree.ElementTree,xml.dom和xml.sax包。这些模块和软件包共同大大简化了Python应用程序和其他工具之间的数据交换。 - 该
sqlite3模块是SQLite数据库库的包装器,提供了一个持久性数据库,可以使用稍微非标准的SQL语法进行更新和访问。 - 国际化是由多个模块,包括所支持
gettext,locale以及codecs包。
十一.标准库简介 - 第二部分
第二次巡演涵盖了支持专业编程需求的更高级模块。这些模块很少出现在小脚本中。
11.1 输出格式
该reprlib模块提供了一个repr()定制版本,用于缩放大型或深层嵌套容器的显示:
>>> import reprlib
>>> reprlib.repr(set('supercalifragilisticexpialidocious'))
"{'a', 'c', 'd', 'e', 'f', 'g', ...}"
该pprint模块提供了更加复杂的控制,可以以解释器可读的方式打印内置和用户定义的对象。当结果长于一行时,“漂亮的打印机”会添加换行符和缩进以更清楚地显示数据结构:
>>> import pprint
>>> t = [[[['black', 'cyan'], 'white', ['green', 'red']], [['magenta',
... 'yellow'], 'blue']]]
...
>>> pprint.pprint(t, width=30)
[[[['black', 'cyan'],
'white',
['green', 'red']],
[['magenta', 'yellow'],
'blue']]]
该textwrap模块格式化文本段落以适合给定的屏幕宽度:
>>> import textwrap
>>> doc = """The wrap() method is just like fill() except that it returns
... a list of strings instead of one big string with newlines to separate
... the wrapped lines."""
...
>>> print(textwrap.fill(doc, width=40))
The wrap() method is just like fill()
except that it returns a list of strings
instead of one big string with newlines
to separate the wrapped lines.
该locale模块访问文化特定数据格式的数据库。locale格式函数的分组属性提供了使用组分隔符格式化数字的直接方法:
>>> import locale
>>> locale.setlocale(locale.LC_ALL, 'English_United States.1252')
'English_United States.1252'
>>> conv = locale.localeconv() # get a mapping of conventions
>>> x = 1234567.8
>>> locale.format("%d", x, grouping=True)
'1,234,567'
>>> locale.format_string("%s%.*f", (conv['currency_symbol'],
... conv['frac_digits'], x), grouping=True)
'$1,234,567.80'
11.2 模板
该string模块包括一个通用Template类,其语法简化,适合最终用户编辑。这允许用户自定义他们的应用程序而无需更改应用程序。
该格式使用由$有效的Python标识符(字母数字字符和下划线)组成的占位符名称。使用大括号围绕占位符允许其后跟更多的字母数字字母,没有中间空格。写作$$会创建一个转义$:
>>> from string import Template
>>> t = Template('${village}folk send $$10 to $cause.')
>>> t.substitute(village='Nottingham', cause='the ditch fund')
'Nottinghamfolk send $10 to the ditch fund.'
该substitute()方法KeyError在字典或关键字参数中未提供占位符时引发。对于邮件合并样式应用程序,用户提供的数据可能不完整, safe_substitute()方法可能更合适 - 如果数据丢失,它将保持占位符不变:
>>> t = Template('Return the $item to $owner.')
>>> d = dict(item='unladen swallow')
>>> t.substitute(d)
Traceback (most recent call last):
...
KeyError: 'owner'
>>> t.safe_substitute(d)
'Return the unladen swallow to $owner.'
模板子类可以指定自定义分隔符。例如,照片浏览器的批量重命名实用程序可以选择对占位符使用百分号,例如当前日期,图像序列号或文件格式:
>>> import time, os.path
>>> photofiles = ['img_1074.jpg', 'img_1076.jpg', 'img_1077.jpg']
>>> class BatchRename(Template):
... delimiter = '%'
>>> fmt = input('Enter rename style (%d-date %n-seqnum %f-format): ')
Enter rename style (%d-date %n-seqnum %f-format): Ashley_%n%f >>> t = BatchRename(fmt)
>>> date = time.strftime('%d%b%y')
>>> for i, filename in enumerate(photofiles):
... base, ext = os.path.splitext(filename)
... newname = t.substitute(d=date, n=i, f=ext)
... print('{0} --> {1}'.format(filename, newname)) img_1074.jpg --> Ashley_0.jpg
img_1076.jpg --> Ashley_1.jpg
img_1077.jpg --> Ashley_2.jpg
模板的另一个应用是将程序逻辑与多种输出格式的细节分开。这样就可以替换XML文件,纯文本报告和HTML Web报告的自定义模板。
11.3 使用二进制数据记录布局
该struct模块提供pack()和 unpack()使用可变长度二进制记录格式的功能。以下示例显示如何在不使用zipfile模块的情况下循环ZIP文件中的标头信息 。打包代码"H"并分别"I"表示两个和四个字节的无符号数字。在"<"表明他们是标准的尺寸和little-endian字节顺序:
import struct
with open('myfile.zip', 'rb') as f:
data = f.read()
start = 0
for i in range(3): # show the first 3 file headers
start += 14
fields = struct.unpack('<IIIHH', data[start:start+16])
crc32, comp_size, uncomp_size, filenamesize, extra_size = fields
start += 16
filename = data[start:start+filenamesize]
start += filenamesize
extra = data[start:start+extra_size]
print(filename, hex(crc32), comp_size, uncomp_size)
start += extra_size + comp_size # skip to the next header
11.4 多线程
线程化是一种解耦非顺序依赖的任务的技术。线程可用于提高接受用户输入的应用程序的响应能力,而其他任务在后台运行。相关用例是与另一个线程中的计算并行运行I / O.
以下代码显示了threading当主程序继续运行时,高级模块如何在后台运行任务:
import threading, zipfile class AsyncZip(threading.Thread):
def __init__(self, infile, outfile):
threading.Thread.__init__(self)
self.infile = infile
self.outfile = outfile def run(self):
f = zipfile.ZipFile(self.outfile, 'w', zipfile.ZIP_DEFLATED)
f.write(self.infile)
f.close()
print('Finished background zip of:', self.infile) background = AsyncZip('mydata.txt', 'myarchive.zip')
background.start()
print('The main program continues to run in foreground.') background.join() # Wait for the background task to finish
print('Main program waited until background was done.')
多线程应用程序的主要挑战是协调共享数据或其他资源的线程。为此,线程模块提供了许多同步原语,包括锁,事件,条件变量和信号量。
虽然这些工具功能强大,但较小的设计错误可能导致难以重现的问题。因此,任务协调的首选方法是将对资源的所有访问集中在一个线程中,然后使用该 queue模块为来自其他线程的请求提供该线程。使用Queue对象进行线程间通信和协调的应用程序更易于设计,更易读,更可靠。
11.5 记录
该logging模块提供功能齐全且灵活的记录系统。最简单的是,日志消息被发送到文件或sys.stderr:
import logging
logging.debug('Debugging information')
logging.info('Informational message')
logging.warning('Warning:config file %s not found', 'server.conf')
logging.error('Error occurred')
logging.critical('Critical error -- shutting down')
这会产生以下输出:
WARNING:root:Warning:config file server.conf not found
ERROR:root:Error occurred
CRITICAL:root:Critical error -- shutting down
默认情况下,信息和调试消息被抑制,输出发送到标准错误。其他输出选项包括通过电子邮件,数据报,套接字或HTTP服务器路由消息。:新过滤器可根据消息优先级来选择不同的路由DEBUG, INFO,WARNING,ERROR,和CRITICAL。
日志记录系统可以直接从Python配置,也可以从用户可编辑的配置文件加载,以便自定义日志记录而无需更改应用程序。
11.6 弱引用
Python执行自动内存管理(大多数对象的引用计数和 垃圾收集以消除循环)。在消除了对最后一次引用后不久释放的内存。
这种方法适用于大多数应用程序,但偶尔需要跟踪对象,只要它们被其他东西使用。不幸的是,只是跟踪它们会创建一个使它们永久化的引用。该weakref模块提供了跟踪对象的工具,而无需创建引用。当不再需要该对象时,它将自动从weakref表中删除,并为weakref对象触发回调。典型应用程序包括缓存创建成本高昂的对象:
>>> import weakref, gc
>>> class A:
... def __init__(self, value):
... self.value = value
... def __repr__(self):
... return str(self.value)
...
>>> a = A(10) # create a reference
>>> d = weakref.WeakValueDictionary()
>>> d['primary'] = a # does not create a reference
>>> d['primary'] # fetch the object if it is still alive
10
>>> del a # remove the one reference
>>> gc.collect() # run garbage collection right away
0
>>> d['primary'] # entry was automatically removed
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
d['primary'] # entry was automatically removed
File "C:/python36/lib/weakref.py", line 46, in __getitem__
o = self.data[key]()
KeyError: 'primary'
11.7 使用列表的工具
内置列表类型可以满足许多数据结构需求。但是,有时需要具有不同性能权衡的替代实现。
该array模块提供的array()对象类似于仅存储同类数据的列表,并且更紧凑地存储它。以下示例显示了存储为两个字节无符号二进制数(typecode "H")的数字数组,而不是通常的Python int对象列表的每个条目通常16个字节:
>>> from array import array
>>> a = array('H', [4000, 10, 700, 22222])
>>> sum(a)
26932
>>> a[1:3]
array('H', [10, 700])
该collections模块提供的deque()对象类似于列表,具有更快的附加和左侧弹出,但在中间查找较慢。这些对象非常适合实现队列和广度优先树搜索:
>>> from collections import deque
>>> d = deque(["task1", "task2", "task3"])
>>> d.append("task4")
>>> print("Handling", d.popleft())
Handling task1
unsearched = deque([starting_node])
def breadth_first_search(unsearched):
node = unsearched.popleft()
for m in gen_moves(node):
if is_goal(m):
return m
unsearched.append(m)
除了替代列表实现之外,该库还提供了其他工具,例如bisect具有用于操作排序列表的函数的模块:
>>> import bisect
>>> scores = [(100, 'perl'), (200, 'tcl'), (400, 'lua'), (500, 'python')]
>>> bisect.insort(scores, (300, 'ruby'))
>>> scores
[(100, 'perl'), (200, 'tcl'), (300, 'ruby'), (400, 'lua'), (500, 'python')]
该heapq模块提供了基于常规列表实现堆的功能。最低值的条目始终保持在零位置。这对于重复访问最小元素但不想运行完整列表排序的应用程序非常有用:
>>> from heapq import heapify, heappop, heappush
>>> data = [1, 3, 5, 7, 9, 2, 4, 6, 8, 0]
>>> heapify(data) # rearrange the list into heap order
>>> heappush(data, -5) # add a new entry
>>> [heappop(data) for i in range(3)] # fetch the three smallest entries
[-5, 0, 1]
11.8 十进制浮点运算
该decimal模块提供Decimal十进制浮点运算的数据类型。与float 二进制浮点的内置实现相比,该类特别有用
- 财务申请和其他需要精确十进制表示的用途,
- 控制精度,
- 控制四舍五入以满足法律或监管要求,
- 跟踪有效小数位,或
- 用户希望结果与手工完成的计算相匹配的应用程序。
例如,计算70美分手机费用的5%税,会产生十进制浮点和二进制浮点数的不同结果。如果结果四舍五入到最接近的分数,则差异变得很大:
>>> from decimal import *
>>> round(Decimal('0.70') * Decimal('1.05'), 2)
Decimal('0.74')
>>> round(.70 * 1.05, 2)
0.73
该Decimal结果保留尾随零,自动推断来自两个地方的意义被乘数4点地方的意义。Decimal可以手动复制数学,避免了二进制浮点不能精确表示十进制数时可能出现的问题。
精确表示使Decimal类能够执行不适合二进制浮点的模数计算和相等性测试:
>>> Decimal('1.00') % Decimal('.10')
Decimal('0.00')
>>> 1.00 % 0.10
0.09999999999999995
>>> sum([Decimal('0.1')]*10) == Decimal('1.0')
True
>>> sum([0.1]*10) == 1.0
False
该decimal模块提供了所需的精度算术:
>>> getcontext().prec = 36
>>> Decimal(1) / Decimal(7)
Decimal('0.142857142857142857142857142857142857')
十二.虚拟环境和包
12.1 介绍
Python应用程序通常会使用不作为标准库一部分的包和模块。应用程序有时需要特定版本的库,因为应用程序可能需要修复特定的错误,或者可以使用库的接口的过时版本编写应用程序。
这意味着一个Python安装可能无法满足每个应用程序的要求。如果应用程序A需要特定模块的1.0版本但应用程序B需要2.0版本,则需求存在冲突,安装版本1.0或2.0将导致一个应用程序无法运行。
此问题的解决方案是创建一个虚拟环境,一个包含特定Python版本的Python安装的自包含目录树,以及许多其他软件包。
然后,不同的应用可以使用不同的虚拟环 要解决先前的冲突需求示例,应用程序A可以拥有自己的1.0版本安装虚拟环境,而应用程序B则具有版本2.0的另一个虚拟环境。如果应用程序B要求将库升级到3.0版,则不会影响应用程序A的环境。
12.2 创建虚拟环境
用于创建和管理虚拟环境的模块被调用 venv。 venv通常会安装您可用的最新版本的Python。如果您的系统上有多个版本的Python,则可以通过运行python3或任何您想要的版本来选择特定的Python版本。
要创建虚拟环境,请确定要放置它的目录,然后将该venv模块作为带有目录路径的脚本运行:
python3 -m venv tutorial-env
tutorial-env如果目录不存在,这将创建目录,并在其中创建包含Python解释器,标准库和各种支持文件的副本的目录。
创建虚拟环境后,您可以激活它。
在Windows上,运行:
tutorial-env\Scripts\activate.bat
在Unix或MacOS上,运行:
source tutorial-env/bin/activate
(这个脚本是为bash shell编写的。如果你使用 csh或fish shell,你应该使用替代 activate.csh和activate.fish脚本。)
激活虚拟环境将改变shell的提示,以显示您正在使用的虚拟环境,并修改环境,以便运行 python将获得特定版本和Python的安装。例如:
$ source ~/envs/tutorial-env/bin/activate
(tutorial-env) $ python
Python 3.5.1 (default, May 6 2016, 10:59:36)
...
>>> import sys
>>> sys.path
['', '/usr/local/lib/python35.zip', ...,
'~/envs/tutorial-env/lib/python3.5/site-packages']
>>>
12.3 使用pip管理包
您可以使用名为pip的程序安装,升级和删除软件包 。默认情况下,pip将从Python包索引< https://pypi.org > 安装包。您可以在Web浏览器中浏览Python Package Index,也可以使用pip有限的搜索功能:
(tutorial-env) $ pip search astronomy
skyfield - Elegant astronomy for Python
gary - Galactic astronomy and gravitational dynamics.
novas - The United States Naval Observatory NOVAS astronomy library
astroobs - Provides astronomy ephemeris to plan telescope observations
PyAstronomy - A collection of astronomy related tools for Python.
...
pip有许多子命令:“搜索”,“安装”,“卸载”,“冻结”等。(有关完整文档,请参阅安装Python模块指南pip。)
您可以通过指定包的名称来安装最新版本的包:
(tutorial-env) $ pip install novas
Collecting novas
Downloading novas-3.1.1.3.tar.gz (136kB)
Installing collected packages: novas
Running setup.py install for novas
Successfully installed novas-3.1.1.3
您还可以通过提供包名称后跟==以及版本号来安装特定版本的包:
(tutorial-env) $ pip install requests==2.6.0
Collecting requests==2.6.0
Using cached requests-2.6.0-py2.py3-none-any.whl
Installing collected packages: requests
Successfully installed requests-2.6.0
如果重新运行此命令,pip将注意到已安装所请求的版本并且不执行任何操作。您可以提供不同的版本号来获取该版本,也可以运行以将软件包升级到最新版本:pip install --upgrade
(tutorial-env) $ pip install --upgrade requests
Collecting requests
Installing collected packages: requests
Found existing installation: requests 2.6.0
Uninstalling requests-2.6.0:
Successfully uninstalled requests-2.6.0
Successfully installed requests-2.7.0
pip uninstall 后跟一个或多个包名称将从虚拟环境中删除包。
pip show 将显示有关特定包的信息:
(tutorial-env) $ pip show requests
---
Metadata-Version: 2.0
Name: requests
Version: 2.7.0
Summary: Python HTTP for Humans.
Home-page: http://python-requests.org
Author: Kenneth Reitz
Author-email: me@kennethreitz.com
License: Apache 2.0
Location: /Users/akuchling/envs/tutorial-env/lib/python3.4/site-packages
Requires:
pip list 将显示虚拟环境中安装的所有软件包:
(tutorial-env) $ pip list
novas (3.1.1.3)
numpy (1.9.2)
pip (7.0.3)
requests (2.7.0)
setuptools (16.0)
pip freeze将生成类似的已安装包列表,但输出使用期望的格式。一个常见的约定是将此列表放在一个文件中:pip installrequirements.txt
(tutorial-env) $ pip freeze > requirements.txt
(tutorial-env) $ cat requirements.txt
novas==3.1.1.3
numpy==1.9.2
requests==2.7.0
然后requirements.txt可以将其提交到版本控制并作为应用程序的一部分提供。然后,用户可以安装所有必需的包:install -r
(tutorial-env) $ pip install -r requirements.txt
Collecting novas==3.1.1.3 (from -r requirements.txt (line 1))
...
Collecting numpy==1.9.2 (from -r requirements.txt (line 2))
...
Collecting requests==2.7.0 (from -r requirements.txt (line 3))
...
Installing collected packages: novas, numpy, requests
Running setup.py install for novas
Successfully installed novas-3.1.1.3 numpy-1.9.2 requests-2.7.0
pip还有更多选择。有关 完整文档,请参阅安装Python模块指南pip。当您编写包并希望在Python包索引中使其可用时,请参阅Distributing Python Modules指南。
十三.浮点运算:问题和局限
浮点数在计算机硬件中表示为基数2(二进制)分数。例如,小数部分
0.125
值为1/10 + 2/100 + 5/1000,二进制分数相同
0.001
值为0/2 + 0/4 + 1/8。这两个分数具有相同的值,唯一真正的区别是第一个用基数10分数表示法写入,第二个用基数2表示。
不幸的是,大多数小数部分不能完全表示为二进制分数。结果是,通常,您输入的十进制浮点数仅由实际存储在机器中的二进制浮点数近似。
这个问题最初在基数10中更容易理解。考虑1/3的分数。您可以将其近似为基数10分数:
0.3
或更好,
0.33
或更好,
0.333
等等。无论你愿意记下多少位数,结果都不会完全是1/3,但将会越来越好地逼近1/3。
同样,无论您愿意使用多少个2位数,十进制值0.1都不能完全表示为基数2分数。在碱2中,1/10是无限重复的部分
0.0001100110011001100110011001100110011001100110011...
停在任何有限的位数,你得到一个近似值。在今天的大多数机器上,浮点数使用二进制分数近似,分子使用前53位从最高位开始,分母为2的幂。在1/10的情况下,二进制分数接近但不完全等于1/10的真实值。3602879701896397 / 2 ** 55
由于显示值的方式,许多用户不知道近似值。Python仅打印十进制近似值到机器存储的二进制近似值的真实十进制值。在大多数机器上,如果Python要打印存储为0.1的二进制近似值的真实十进制值,则必须显示
>>> 0.1
0.1000000000000000055511151231257827021181583404541015625
这比大多数人认为有用的数字更多,因此Python通过显示舍入值来保持可管理的位数
>>> 1 / 10
0.1
请记住,即使打印结果看起来像1/10的精确值,实际存储的值也是最接近的可表示二进制分数。
有趣的是,有许多不同的十进制数,它们共享相同的最接近的近似二进制分数。例如,数字0.1和0.10000000000000001和 0.1000000000000000055511151231257827021181583404541015625都是近似的。由于所有这些十进制值共享相同的近似值,因此可以在保留不变量的同时显示它们中的任何一个。3602879701896397 / 2 **55eval(repr(x)) == x
从历史上看,Python提示和内置repr()函数将选择具有17位有效数字的函数0.10000000000000001。从Python 3.1开始,Python(在大多数系统上)现在能够选择最短的并简单地显示0.1。
请注意,这是二进制浮点的本质:这不是Python中的错误,也不是代码中的错误。您将在支持硬件浮点运算的所有语言中看到相同的类型(尽管某些语言默认情况下可能无法显示差异,或者在所有输出模式下都不会显示差异)。
为了获得更愉快的输出,您可能希望使用字符串格式来生成有限数量的有效数字:
>>> format(math.pi, '.12g') # give 12 significant digits
'3.14159265359' >>> format(math.pi, '.2f') # give 2 digits after the point
'3.14' >>> repr(math.pi)
'3.141592653589793'
重要的是要意识到,从实际意义上说,这是一种错觉:你只是简单地围绕真实机器价值的显示。
一种错觉可能会产生另一种错觉。例如,由于0.1不完全是1/10,因此将三个0.1的值相加可能不会精确地产生0.3,或者:
>>> .1 + .1 + .1 == .3
False
此外,由于0.1不能接近1/10的精确值,0.3不能接近3/10的精确值,那么使用round()函数预先舍入 不能帮助:
>>> round(.1, 1) + round(.1, 1) + round(.1, 1) == round(.3, 1)
False
尽管数字不能接近其预期的精确值,但该round()函数可用于后舍入,以使具有不精确值的结果彼此相当:
>>> round(.1 + .1 + .1, 10) == round(.3, 10)
True
二进制浮点运算有很多这样的惊喜。下面在“表示错误”部分中详细解释了“0.1”的问题。有关 其他常见惊喜的更完整说明,请参阅浮点危险。
正如接近结尾所说,“没有简单的答案。”不过,不要过分警惕浮点!Python浮点运算中的错误是从浮点硬件继承而来的,并且在大多数机器上每个操作的错误数量不超过1 ** 2 ** 53。这对于大多数任务来说已经足够了,但是你需要记住它不是十进制算术并且每次浮点运算都会遇到新的舍入错误。
虽然存在病态情况,但对于大多数临时使用浮点运算,如果您只是将最终结果的显示四舍五入到您期望的十进制数字,您将看到最终期望的结果。 str()通常就足够了,并且为了更好的控制,请参阅格式字符串语法中str.format() 方法的格式说明符。
对于需要精确十进制表示的用例,请尝试使用decimal适用于会计应用程序和高精度应用程序的实现十进制算术的模块。
精确算术的另一种形式由fractions模块支持,该模块基于有理数实现算术(因此可以精确地表示像1/3这样的数字)。
如果您是浮点运算的重要用户,您应该查看Numerical Python软件包以及SciPy项目提供的数学和统计操作的许多其他软件包。请参阅< https://scipy.org >。
Python提供的工具,可对这些罕见的情况下帮助当你真的 不想要知道一个浮动的精确值。该float.as_integer_ratio()方法将float的值表示为分数:
>>> x = 3.14159
>>> x.as_integer_ratio()
(3537115888337719, 1125899906842624)
由于比率是精确的,它可以用于无损地重新创建原始值:
>>> x == 3537115888337719 / 1125899906842624
True
该float.hex()方法以十六进制表示浮点数(基数为16),再次给出计算机存储的精确值:
>>> x.hex()
'0x1.921f9f01b866ep+1'
这个精确的十六进制表示可用于精确重建浮点值:
>>> x == float.fromhex('0x1.921f9f01b866ep+1')
True
由于表示是精确的,因此可以跨不同版本的Python(平台独立性)可靠地移植值,并与支持相同格式的其他语言(例如Java和C99)交换数据。
另一个有用的工具是math.fsum()有助于减少求和过程中精度损失的功能。当值添加到运行总计时,它会跟踪“丢失的数字”。这可能会对整体准确性产生影响,因此错误不会累积到影响最终总数的程度:
>>> sum([0.1] * 10) == 1.0
False
>>> math.fsum([0.1] * 10) == 1.0
True
13.1 表示错误
本节详细介绍“0.1”示例,并说明如何自行对此类案例进行精确分析。假设基本熟悉二进制浮点表示。
表示错误是指某些(大多数,实际上)小数部分不能完全表示为二进制(基数2)分数的事实。这就是为什么Python(或Perl,C,C ++,Java,Fortran和许多其他人)通常不会显示您期望的确切十进制数的主要原因。
这是为什么?1/10不能完全表示为二进制分数。今天(2000年11月)几乎所有机器都使用IEEE-754浮点运算,几乎所有平台都将Python浮点数映射到IEEE-754“双精度”。754双精度包含53位精度,因此在输入时,计算机努力将0.1转换为J / 2 ** N形式的最接近的分数,其中J是包含正好53位的整数。重写
1 / 10 ~= J / (2**N)
如
J ~= 2**N / 10
并且回想起J恰好有53位(但是),N的最佳值是56:>= 2**52< 2**53
>>> 2**52 <= 2**56 // 10 < 2**53
True
也就是说,56是N的唯一值,它使J正好为53位。然后,J的最佳可能值是舍入的商:
>>> q, r = divmod(2**56, 10)
>>> r
6
由于余数超过10的一半,因此通过四舍五入获得最佳近似值:
>>> q+1
7205759403792794
因此,754双精度的最佳可能近似值为1/10:
7205759403792794 / 2 ** 56
将分子和分母除以2将分数减少到:
3602879701896397 / 2 ** 55
请注意,由于我们向上舍入,这实际上比1/10大一点; 如果我们没有四舍五入,则商数将小于1/10。但在任何情况下都不能完全是 1/10!
所以计算机永远不会“看到”1/10:它看到的是上面给出的精确分数,它可以获得的最佳754双近似值:
>>> 0.1 * 2 ** 55
3602879701896397.0
如果我们将该分数乘以10 ** 55,我们可以看到55到十进制数字的值:
>>> 3602879701896397 * 10 ** 55 // 2 ** 55
1000000000000000055511151231257827021181583404541015625
意味着存储在计算机中的确切数字等于十进制值0.1000000000000000055511151231257827021181583404541015625。许多语言(包括旧版本的Python)不是显示完整的十进制值,而是将结果舍入为17位有效数字:
>>> format(0.1, '.17f')
'0.10000000000000001'
在fractions和decimal模块进行这些计算很简单:
>>> from decimal import Decimal
>>> from fractions import Fraction >>> Fraction.from_float(0.1)
Fraction(3602879701896397, 36028797018963968) >>> (0.1).as_integer_ratio()
(3602879701896397, 36028797018963968) >>> Decimal.from_float(0.1)
Decimal('0.1000000000000000055511151231257827021181583404541015625') >>> format(Decimal.from_float(0.1), '.17')
'0.10000000000000001'
十四.附录
14.1 交互模式
14.1.1 错误处理
发生错误时,解释器会输出错误消息和堆栈跟踪。在交互模式下,它然后返回主要提示; 当输入来自文件时,它在打印堆栈跟踪后以非零退出状态退出。(由语句中的except子句处理的异常try在此上下文中不是错误。)某些错误无条件地致命并导致退出非零退出; 这适用于内部不一致和一些内存不足的情况。所有错误消息都写入标准错误流; 执行命令的正常输出写入标准输出。
将中断字符(通常Control-C或Delete)键入主要或辅助提示会取消输入并返回主要提示。[1] 在执行命令时键入中断会引发 KeyboardInterrupt异常,这可能由try 语句处理。
14.1.2 可执行的Python脚本
在BSD的Unix系统上,Python脚本可以直接执行,就像shell脚本一样,通过放置行
#!/usr/bin/env python3.5
(假设翻译是在用户的 PATH)在脚本的开头,给文件一个可执行模式。的#!必须是文件的前两个字符。在某些平台上,第一行必须以Unix样式行ends('\n')结束,而不是以Windows('\r\n')行结尾。请注意,hash或pound字符'#'用于在Python中启动注释。
可以使用chmod命令为脚本指定可执行模式或权限 。
$ chmod +x myscript.py
在Windows系统上,没有“可执行模式”的概念。Python安装程序自动关联.py文件,python.exe以便双击Python文件将其作为脚本运行。.pyw在这种情况下,扩展也可以是通常出现的控制台窗口被抑制。
14.1.3 交互式启动文件
当您以交互方式使用Python时,每次启动解释器时都会执行一些标准命令,这通常很方便。您可以通过设置名为的环境变量来完成此操作PYTHONSTARTUP到包含启动命令的文件的名称。这类似于.profile Unix shell 的功能。
此文件仅在交互式会话中读取,而不是在Python从脚本读取命令时读取,而不是在/dev/tty作为显式命令源(其他行为类似于交互式会话)的情况下读取。它在执行交互式命令的同一命名空间中执行,因此可以在交互式会话中无限制地使用它定义或导入的对象。您也可以更改提示sys.ps1和sys.ps2此文件。
如果要从当前目录中读取其他启动文件,可以使用类似代码在全局启动文件中对此进行编程。如果要在脚本中使用启动文件,则必须在脚本中明确执行此操作:if os.path.isfile('.pythonrc.py'):exec(open('.pythonrc.py').read())
import os
filename = os.environ.get('PYTHONSTARTUP')
if filename and os.path.isfile(filename):
with open(filename) as fobj:
startup_file = fobj.read()
exec(startup_file)
14.1.4 定制模块
Python提供了两个钩子来让你自定义它:sitecustomize和 usercustomize。要查看其工作原理,首先需要找到用户site-packages目录的位置。启动Python并运行以下代码:
>>> import site
>>> site.getusersitepackages()
'/home/user/.local/lib/python3.5/site-packages'
现在,您可以创建usercustomize.py在该目录中命名的文件,并将所需内容放入其中。它会影响Python的每次调用,除非它是以-s禁用自动导入的选项启动的。
sitecustomize以相同的方式工作,但通常由全局site-packages目录中的计算机管理员创建,并在之前导入usercustomize。有关site 更多详细信息,请参阅模块的文档。
Python3语法详解的更多相关文章
- Velocity魔法堂系列二:VTL语法详解
一.前言 Velocity作为历史悠久的模板引擎不单单可以替代JSP作为Java Web的服务端网页模板引擎,而且可以作为普通文本的模板引擎来增强服务端程序文本处理能力.而且Velocity被移植到不 ...
- Hive笔记--sql语法详解及JavaAPI
Hive SQL 语法详解:http://blog.csdn.net/hguisu/article/details/7256833Hive SQL 学习笔记(常用):http://blog.sina. ...
- Hadoop Hive sql语法详解
Hadoop Hive sql语法详解 Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件 ...
- Thymeleaf3语法详解和实战
Thymeleaf3语法详解 Thymeleaf是Spring boot推荐使用的模版引擎,除此之外常见的还有Freemarker和Jsp.Jsp应该是我们最早接触的模版引擎.而Freemarker工 ...
- Xpath语法详解
1.简介 XPath是一门在XML和HTML文档中查找信息的语言,可以用来在XML和HTML文档中对元素和属性进行遍历 XPath的安装 Chrome插件XPath Helper 点Chrome浏览器 ...
- mysql用户授权、数据库权限管理、sql语法详解
mysql用户授权.数据库权限管理.sql语法详解 —— NiceCui 某个数据库所有的权限 ALL 后面+ PRIVILEGES SQL 某个数据库 特定的权限SQL mysql 授权语法 SQL ...
- Java8的Stream语法详解(转载)
1. Stream初体验 我们先来看看Java里面是怎么定义Stream的: A sequence of elements supporting sequential and parallel agg ...
- [持续交付实践] pipeline使用:语法详解
一.引言 jenkins pipeline语法的发展如此之快用日新月异来形容也不为过,而目前国内对jenkins pipeline关注的人还非常少,相关的文章更是稀少,唯一看到w3c有篇相关的估计是直 ...
- Java 8系列之Stream的基本语法详解
本文转至:https://blog.csdn.net/io_field/article/details/54971761 Stream系列: Java 8系列之Stream的基本语法详解 Java 8 ...
随机推荐
- js基础之DOM中元素对象的属性方法
在 HTML DOM (文档对象模型)中,每个部分都是节点. 节点是DOM结构中最基本的组成单元,每一个HTML标签都是DOM结构的节点. 文档是一个 文档节点 . 所有的HTML元素都是 ...
- NATS_09:NATS常见问题说明
1. Request() 和 Publish() 之间的不同 Publish()发送一条消息到 gnatsd 服务,是使用它的地址作为一个 主题(subject),而 gnatsd 交付消息给所有注册 ...
- POJ - 2976 Dropping tests && 0/1 分数规划
POJ - 2976 Dropping tests 你有 \(n\) 次考试成绩, 定义考试平均成绩为 \[\frac{\sum_{i = 1}^{n} a_{i}}{\sum_{i = 1}^{n} ...
- RabbitMQ基础介绍
非原创,仅作为个人的学习资料,转自 anzhsoft http://blog.csdn.net/anzhsoft/article/details/19563091, 1. 历史 RabbitMQ是一个 ...
- wepy
npm install -g cnpm --registry=https://registry.npm.taobao.org https://blog.csdn.net/qq_40414159/art ...
- django project 的快速构建
2003年,堪萨斯(Kansas)州 Lawrence 城中的一个 网络开发小组 ——World Online 小组,为了方便制作维护当地的几个新闻站点(一般要求几天或者几小时内被建立),Adrian ...
- Linux块设备和字符设备
块设备:系统能够随机无序访问固定大小的数据片的设备,这些数据片称为块.块设备是以固定大小长度来传送资料的,它使用缓冲区暂存数据,时机成熟后从缓存中一次性写入到设备或者从设备中一次性放到缓存区.常见的块 ...
- nodejs 剪切图像在上传,并保存到指定路径下(./public/img/' + req.session.token + '.jpg‘)
前jQuery端接收数据 function upAvatar(img){ console.log(img); // data:image/jpeg;base64,/9j/4AAQSkZJRgABAQA ...
- 【JAVA】配置JAVA环境变量,安装Eclipse
Java程序依赖JDK,就像C#程序依赖.NetFrameWork一样. 所以在开发之前,必须在win7或者是linux上,安装jdk(JavaDevelopkit)里面包括java一些工具,还有JR ...
- UCenter在JAVA项目中实现的单点登录应用实例
Comsenz(康盛)的UCenter当前在国内的单点登录领域占据绝对份额,其完整的产品线令UCenter成为了账号集成方面事实上的标准. 基于UCenter,可以将Comsenz旗下的Discuz! ...