presto架构和原理
Presto 是 Facebook 推出的一个基于Java开发的大数据分布式 SQL 查询引擎,可对从数 G 到数 P 的大数据进行交互式的查询,查询的速度达到商业数据仓库的级别,据称该引擎的性能是 Hive 的 10 倍以上。Presto 可以查询包括 Hive、Cassandra 甚至是一些商业的数据存储产品,单个 Presto 查询可合并来自多个数据源的数据进行统一分析。Presto 的目标是在可期望的响应时间内返回查询结果,Facebook 在内部多个数据存储中使用 Presto 交互式查询,包括 300PB 的数据仓库,超过 1000 个 Facebook 员工每天在使用 Presto 运行超过 3 万个查询,每天扫描超过 1PB 的数据。
目录:
- presto架构
- presto低延迟原理
- presto存储插件
- presto执行过程
- presto引擎对比
Presto架构

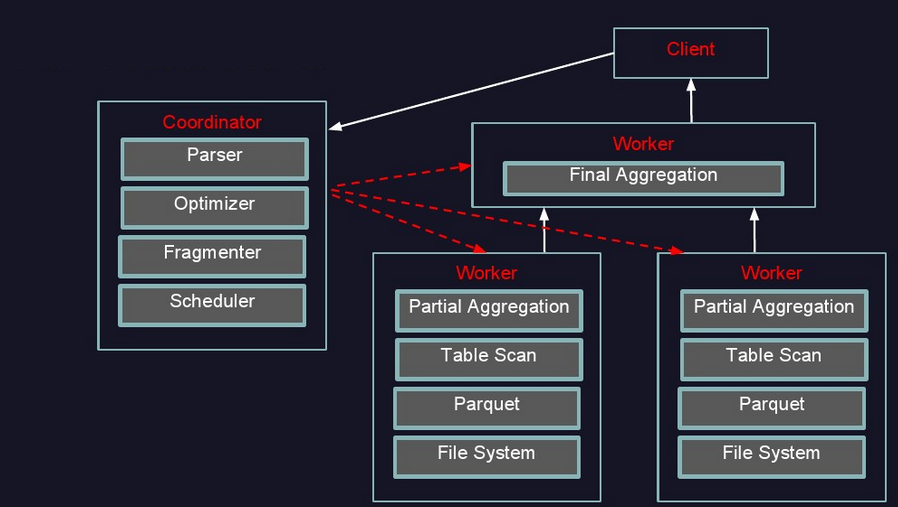
- Presto查询引擎是一个Master-Slave的架构,由下面三部分组成:
- 一个Coordinator节点
- 一个Discovery Server节点
- 多个Worker节点
- Coordinator: 负责解析SQL语句,生成执行计划,分发执行任务给Worker节点执行
- Discovery Server: 通常内嵌于Coordinator节点中
- Worker节点: 负责实际执行查询任务,负责与HDFS交互读取数据
- Worker节点启动后向Discovery Server服务注册,Coordinator从Discovery Server获得可以正常工作的Worker节点。如果配置了Hive Connector,需要配置一个Hive MetaStore服务为Presto提供Hive元信息
- 更形象架构图如下:

Presto低延迟原理
- 完全基于内存的并行计算
- 流水线式计算作业
- 本地化计算
- 动态编译执行计划
- GC控制
Presto存储插件
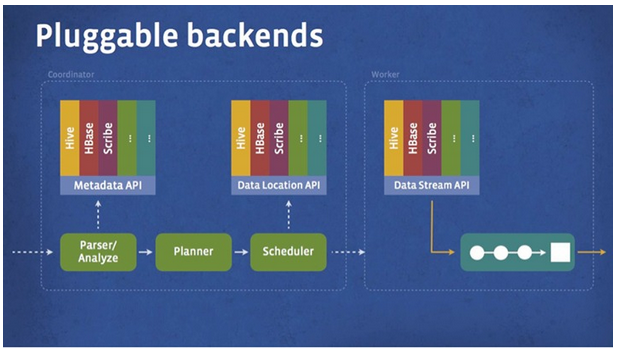
- Presto设计了一个简单的数据存储的抽象层, 来满足在不同数据存储系统之上都可以使用SQL进行查询。
- 存储插件(连接器,connector)只需要提供实现以下操作的接口, 包括对元数据(metadata)的提取,获得数据存储的位置,获取数据本身的操作等。
- 除了我们主要使用的Hive/HDFS后台系统之外, 我们也开发了一些连接其他系统的Presto 连接器,包括HBase,Scribe和定制开发的系统
- 插件结构图如下:
presto执行过程
- 执行过程示意图:
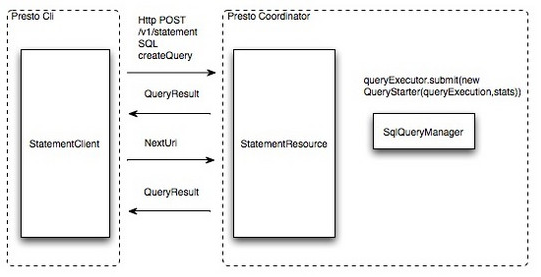
- 提交查询:用户使用Presto Cli提交一个查询语句后,Cli使用HTTP协议与Coordinator通信,Coordinator收到查询请求后调用SqlParser解析SQL语句得到Statement对象,并将Statement封装成一个QueryStarter对象放入线程池中等待执行,如下图:示例SQL如下
select c1.rank, count(*) from dim.city c1 join dim.city c2 on c1.id = c2.id where c1.id > 10 group by c1.rank limit 10;
- 逻辑执行过程示意图如下:
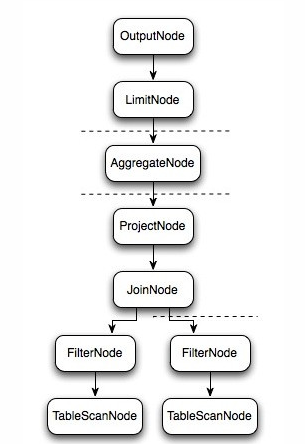
- 上图逻辑执行计划图中的虚线就是Presto对逻辑执行计划的切分点,逻辑计划Plan生成的SubPlan分为四个部分,每一个SubPlan都会提交到一个或者多个Worker节点上执行
- SubPlan有几个重要的属性planDistribution、outputPartitioning、partitionBy属性整个执行过程的流程图如下:
- PlanDistribution:表示一个查询阶段的分发方式,上图中的4个SubPlan共有3种不同的PlanDistribution方式
- Source:表示这个SubPlan是数据源,Source类型的任务会按照数据源大小确定分配多少个节点进行执行
- Fixed: 表示这个SubPlan会分配固定的节点数进行执行(Config配置中的query.initial-hash-partitions参数配置,默认是8)
- None: 表示这个SubPlan只分配到一个节点进行执行
- OutputPartitioning:表示这个SubPlan的输出是否按照partitionBy的key值对数据进行Shuffle(洗牌), 只有两个值HASH和NONE
- PlanDistribution:表示一个查询阶段的分发方式,上图中的4个SubPlan共有3种不同的PlanDistribution方式
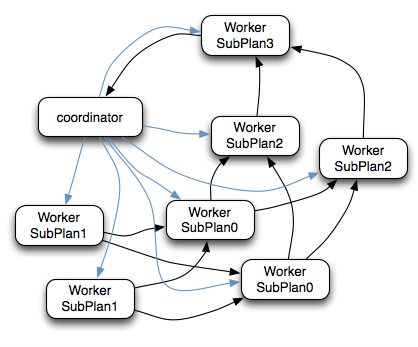
- 在上图的执行计划中,SubPlan1和SubPlan0 PlanDistribution=Source,这两个SubPlan都是提供数据源的节点,SubPlan1所有节点的读取数据都会发向SubPlan0的每一个节点;SubPlan2分配8个节点执行最终的聚合操作;SubPlan3只负责输出最后计算完成的数据,如下图:
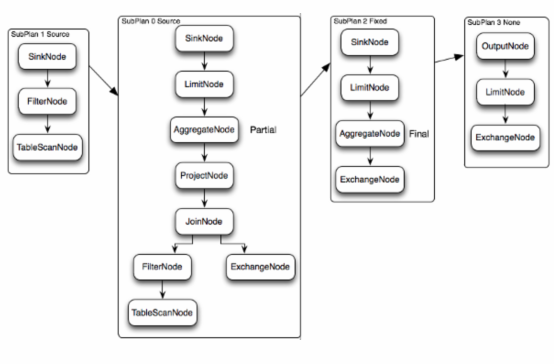
- SubPlan1和SubPlan0 作为Source节点,它们读取HDFS文件数据的方式就是调用的HDFS InputSplit API,然后每个InputSplit分配一个Worker节点去执行,每个Worker节点分配的InputSplit数目上限是参数可配置的,Config中的query.max-pending-splits-per-node参数配置,默认是100
- SubPlan1的每个节点读取一个Split的数据并过滤后将数据分发给每个SubPlan0节点进行Join操作和Partial Aggr操作
- SubPlan0的每个节点计算完成后按GroupBy Key的Hash值将数据分发到不同的SubPlan2节点
- 所有SubPlan2节点计算完成后将数据分发到SubPlan3节点
- SubPlan3节点计算完成后通知Coordinator结束查询,并将数据发送给Coordinator
presto引擎对比
- 与hive、SparkSQL对比结果图

presto架构和原理的更多相关文章
- Presto架构及原理
Presto 是 Facebook 推出的一个基于Java开发的大数据分布式 SQL 查询引擎,可对从数 G 到数 P 的大数据进行交互式的查询,查询的速度达到商业数据仓库的级别,据称该引擎的性能是 ...
- Presto 架构和原理简介(转)
Presto 是 Facebook 推出的一个基于Java开发的大数据分布式 SQL 查询引擎,可对从数 G 到数 P 的大数据进行交互式的查询,查询的速度达到商业数据仓库的级别,据称该引擎的性能是 ...
- HBase的基本架构及其原理介绍
1.概述:最近,有一些工程师问我有关HBase的基本架构的问题,其实这个问题仅仅说架构是非常简单,但是需要理解.在这里,我觉得可以用HDFS的架构作为借鉴.(其实像Hadoop生态系统中的大部分组建的 ...
- SQL Server AlwaysOn架构及原理
SQL Server AlwaysOn架构及原理 SQL Server2012所支持的AlwaysOn技术集中了故障转移群集.数据库镜像和日志传送三者的优点,但又不相同.故障转移群集的单位是SQL实例 ...
- 爱莲(iLinkIT)的架构与原理
随着移动互联网时代的到来,手机正在逐步替代其他的设备,手机是电话.手机是即时通讯,手机是相机,手机是导航仪,手机是钱包,手机是音乐播放器……. 除此之外,手机还是一个大大的U盘,曾几何时,我们用一根长 ...
- Hbase架构与原理
Hbase架构与原理 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang所撰写的Google论文"Bigtable:一个结构化数据的分布式存储系统".就 ...
- [转帖]万字详解Oracle架构、原理、进程,学会世间再无复杂架构
万字详解Oracle架构.原理.进程,学会世间再无复杂架构 http://www.itpub.net/2019/04/24/1694/ 里面的图特别好 数据和云 2019-04-24 09:11:59 ...
- HDFS架构及原理
原文链接:HDFS架构及原理 引言 进入大数据时代,数据集的大小已经超过一台独立物理计算机的存储能力,我们需要对数据进行分区(partition)并存储到若干台单独的计算机上,也就出现了管理网络中跨多 ...
- Spark基本架构及原理
Hadoop 和 Spark 的关系 Spark 运算比 Hadoop 的 MapReduce 框架快的原因是因为 Hadoop 在一次 MapReduce 运算之后,会将数据的运算结果从内存写入到磁 ...
随机推荐
- unix网络编程——TCP套接字编程
TCP客户端和服务端所需的基本套接字.服务器先启动,之后的某个时刻客户端启动并试图连接到服务器.之后客户端向服务器发送请求,服务器处理请求,并给客户端一个响应.该过程一直持续下去,直到客户端关闭,给服 ...
- Node.js记录
在智能社上听了一些关于node.js的视频,总结一小部分内容,都是总结老师讲的知识点,并且也是在不断学习的过程,所以会不断更新.也是为了怕自己遗忘一些知识点,同时现今没有什么项目可以让我去真正实践,这 ...
- Gradle入门(2):构建简介
基本概念 在Gradle中,有两个基本概念:项目和任务.请看以下详解: 项目是指我们的构建产物(比如Jar包)或实施产物(将应用程序部署到生产环境).一个项目包含一个或多个任务. 任务是指不可分的最小 ...
- 理解jquery on 委托事件的机制
前两天做了一个点击任意位置,都能关闭菜单的功能,因为菜单里面的每一个a,的点击事件都是用on绑定的.所以在阻止冒泡的时候不管用,今天特意来理解一下on的机制 on 是委托事件,利用的就是冒泡原理 $( ...
- PAT 1069 微博转发抽奖
https://pintia.cn/problem-sets/994805260223102976/problems/994805265159798784 小明 PAT 考了满分,高兴之余决定发起微博 ...
- Oracle 默认的driectory 目录
1. 写导出命令忘记加directory参数了.. 查了一下: select directory_path from all_directories c:\cwdata\ C:\app\Adminis ...
- linux下 XGCOM串口助手的安装
源码下载:http://code.google.com/p/xgcom/ 也可以自己搜索下载 首先先安装依赖库,直接运行命令 #sudo apt-get install libglib2.0- ...
- Qt——容器类(译)
注:本文是我对Qt官方文档的翻译,错误之处还请指正. 原文链接:Container Classes 介绍 Qt库提供了一套通用的基于模板的容器类,可以用这些类存储指定类型的项.比如,你需要一个大小可变 ...
- Girls' research HDU - 3294(马拉车水题)
题意: 求最长回文串 长度要大于等于2 且输出起点和终点 输出回文串字符 这个字符还是要以给出的字符为起点a 输出 解析: 分析一下s_new串就好了 #include <iostream& ...
- CF960G Bandit Blues 【第一类斯特林数 + 分治NTT】
题目链接 CF960G 题解 同FJOI2016只不过数据范围变大了 考虑如何预处理第一类斯特林数 性质 \[x^{\overline{n}} = \sum\limits_{i = 0}^{n}\be ...