galera mariadb集群恢复策略
1 galera mariadb
首先MariaDB是一个数据库,可以看成是MySQL的一个分支,由于MySQL被SUN收购,所以MySQL面临着闭源的风险,当时MySQL之父Widenius并没有加入SUN,而是基于MySQL的代码开发新的分支,命名为MariaDB,并全部开源。
Galera是Galera Cluster,是一种为数据库设计的新型的、数据不共享的、高度冗余的高可用方案,galera mariadb就是集成了Galera插件的MariaDB集群,Galera本身是具有多主特性的,所以galera mariadb不是传统的主备模式的集群,而是多主节点架构。
2 galera mariadb的配置方式
我的一篇OpenStack高可用模块博客中其中有一段是描述搭建galera mariadb的(2.2.1数据库服务高可用配置):OpenStack高可用方案及配置
3 galera mariadb的一些基本概念
(1)当前节点数据库状态
MariaDB [(none)]> show status like 'wsrep_local_state_comment';
+---------------------------+--------+
| Variable_name | Value |
+---------------------------+--------+
| wsrep_local_state_comment | Synced |
+---------------------------+--------+
状态查询表:
| 状态 | 状态说明 |
| Open | 节点启动成功,尝试连接到集群 |
| Primary | 节点已处于集群中,在新节点加入时,选取donor进行数据库同步时会产生的状态 |
| Joiner | 节点处于等待接收或正在接收同步文件的状态 |
| Joined | 节点完成数据同步,但还有部分数据不是最新的,在追赶与集群数据一致的状态 |
| Synced | 节点正常提供服务的状态,表示当前节点数据状态与集群数据状态是一致的 |
| Donor | 表示该节点被选为Donor节点,正在为新加进来的节点进行全量数据同步,此时该节点对客户端不提供服务 |
(2)Primary Component
在网络发生故障时,由于网络连接原因,集群可能被分成好几个小集群,但只能有一个集群可以继续进行数据修改,集群的这部分称为Primary Component
(3)GTID
英文全称为Global Transaction ID,由UUID和sequence number偏移量组成,wsrep api中定义的集群内部全局事务id,一个顺序id,用来集群集群中状态改变的唯一标志及队列中的偏移量
(4)SST
英文全称为State Snapshot Transfer,即状态快照迁移:通过从一个节点到另一个节点迁移完整的数据拷贝(全量拷贝)。当一个新的节点加入到集群中,新的节点从集群中已有节点进行数据同步,开始进行状态快照迁移。
Galera中有两种不同的状态迁移方法:
<1>逻辑数据迁移:采用mysqldump命令,这是一个阻塞式的方法。
<2>物理数据迁移:该方法采用rsync、rsync_wan、xtrabackup等方法直接在服务器之间拷贝数据,接收的服务器在拷贝完数据后启动服务。
可以通过配置文件中修改SST的方式:
wsrep_sst_method=rsync
(5)IST
英文全称为Increamental State Transfer,即增量状态迁移:集群一个节点通过识别新加入的节点缺失的事务操作,将该操作发送,而并不像SST那样的全量数据拷贝。最常见情况就是该节点之前已经存在于该集群,只是关机重启了,重新加入该集群会使用IST进行同步。
(6)grastate.dat
可以通过该文件查看到该节点记录的uuid和seqno,也就是上面说的GTID,当节点正常退出Galera集群时,会将GTID的值更新到该文件中,如下:
[root@abc3 ~]# cat /var/lib/mysql/grastate.dat
# GALERA saved state
version: 2.1
uuid: 30ae87da-8e8e-11e8-810c-6a8da854119b
seqno:
safe_to_bootstrap:
如果该节点数据库服务正在运行,则seqno的值是-1的
(7)gvwstate.dat
当节点形成或改变Primary Component时,节点会创建或更新该文件,确保节点保留最新Primary Component的状态,如果节点正常关闭,该文件会被删除。
4 一些故障场景的恢复
(1)场景1
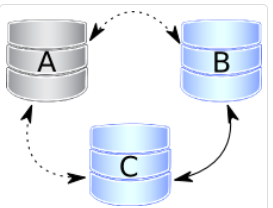
其中1个节点挂了,一般只需要重启A节点的服务即可
(2)场景2
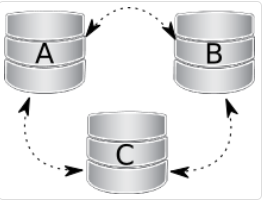
所有节点都挂了,重启服务时不能单纯的全部重启,需要找状态最新的那个节点启动,且启动时需要加上--wsrep-new-cluster参数,该节点启动后其它节点再正常启动服务即可。
这里就涉及到一个关键点,那就是怎么找哪个是状态最新的那个节点,第5点介绍查找最新节点的策略。
5 恢复策略和自动恢复脚本
(1)恢复策略
<1>首先判断当前数据库集群中是否有服务在启动着,如果有则直接启动服务即可
<2>如果当前所有节点的数据库服务都挂了,则需要找状态最新的那个节点让它携带--wsrep-new-cluster参数启动,启动起来之后其它节点直接启动服务即可。
查找最新节点策略:
首先获取各节点的grastate.dat文件中的seqno值,值最大的那个就是最新的节点;如果所有节点的seqno都是-1,则去比较所有节点的gvwstate.dat文件中的my_uuid和view_id是否相等,相等的那个则作为第一个启动节点,第一个启动节点启动后,其它节点正常启动即可;如果依然未找到则需要人工干预来恢复了。
以下是我自己写的自动恢复脚本:
#!/usr/bin/python2
# -*- coding: utf-8 -*- import os
import time
import traceback
import logging
import sys # 初始化日志对象
logger = logging.getLogger("check-or-recover-galera")
log_file='/var/log/check-or-recover-galera/check-or-recover-galera.log'
if not os.path.exists(log_file):
os.system('mkdir -p /var/log/check-or-recover-galera/')
os.system('touch ' + log_file) formatter = logging.Formatter('%(asctime)s (filename)s[line:%(lineno)d] %(levelname)s %(message)s')
file_handler = logging.FileHandler(log_file)
file_handler.setFormatter(formatter) logger.addHandler(file_handler)
logger.setLevel(logging.DEBUG) import socket PORT = 10000
BUFF_SIZE = 10240 def test_connect_ok(ip):
client_sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client_sock.settimeout(3)
client_sock.connect((ip, PORT))
client_sock.close() # 这个方法要求在要远程的节点上需要有个进程在监听PORT端口等待处理命令
def send_request(ip, data, timeout=60):
test_connect_ok(ip)
client_sock = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
client_sock.settimeout(timeout)
client_sock.connect((ip, PORT))
client_sock.send(data)
ret_data = client_sock.recv(BUFF_SIZE)
client_sock.close()
return ret_data def remote_send_request(ip, data, timeout=60):
res_remote = send_request(ip, json.dumps(data), timeout=timeout)
if res_remote is None or res_remote == '':
raise Exception('res_remote is null')
res_remote = json.loads(res_remote)
if res_remote['ret_state'] != 'success':
raise Exception('ret_state is not success')
return res_remote # 默认vmbr0是本地ip
def get_local_ip():
cmd_out = os.popen('cat /etc/sysconfig/network-scripts/ifcfg-vmbr0 2>/dev/null |grep IPADDR').read()
if cmd_out and cmd_out != '':
cmd_out = cmd_out.strip()
cmd_out = cmd_out.replace('"', '').replace(' ', '')
tmp = cmd_out.split('=')
if len(tmp) >= 2:
ip = tmp[1]
return ip
return None # 获取各节点的seqno值
def get_all_nodes_seqno(node_ips_arr):
seqno_dict = {}
data = {'req_type': 'get_seqno'}
for node_ip in node_ips_arr:
try:
res_remote = remote_send_request(node_ip, data)
seqno_dict[node_ip] = res_remote['seqno']
except Exception,e:
seqno_dict[node_ip] = -1
logger.error(traceback.format_exc())
return seqno_dict # 获取各节点的gvwstate.dat文件的my_uuid和view_id的比对值结果
def get_all_nodes_uv_is_equal(node_ips_arr):
uv_equal_dict = {}
data = {'req_type': 'get_uv_equal_value'}
for node_ip in node_ips_arr:
try:
res_remote = remote_send_request(node_ip, data)
uv_equal_dict[node_ip] = res_remote['equal']
except Exception,e:
uv_equal_dict[node_ip] = 0
logger.error(traceback.format_exc())
return uv_equal_dict # 检查自身mariadb服务是否已经启动
def check_is_active_now():
is_active = os.popen('systemctl is-active mysqld_safe 2>/dev/null').read()
is_active = is_active.strip()
if is_active and is_active == 'active':
logger.info('the mariadb is already up')
return True
return False # 第一个启动的节点
def start_mariadb_with_wsrep():
os.system("sed -i 's/--wsrep-new-cluster//' /usr/lib/systemd/system/mysqld_safe.service")
os.system("sed -i 's/user=mysql/user=mysql --wsrep-new-cluster/' /usr/lib/systemd/system/mysqld_safe.service")
os.system("sed -i 's/safe_to_bootstrap:.*/safe_to_bootstrap: 1/' /var/lib/mysql/grastate.dat")
os.system('systemctl daemon-reload')
os.system('systemctl start mysqld_safe')
# 将配置文件恢复回去
os.system("sed -i 's/--wsrep-new-cluster//' /usr/lib/systemd/system/mysqld_safe.service")
os.system('systemctl daemon-reload')
time.sleep(10)
if check_is_active_now() is True:
return True
else:
logger.error('use option wsrep-new-cluster start mariadb failed')
return False def main():
while True:
try:
time.sleep(10)
# 先检测自己的mariadb是否已经自己启动
if check_is_active_now() is True:
time.sleep(60)
continue # 这里应该先检测下thintaskd服务是否已经启动,如果还没启动则需等待
is_thintaskd_active = os.popen('/etc/init.d/thintaskd status 2>/dev/null |grep active |grep running').read()
if not is_thintaskd_active or is_thintaskd_active == '':
logger.info('wait thintaskd service start')
time.sleep(5) # 获取当前galera的集群的各节点的ip
node_ips_info = os.popen("cat /etc/my.cnf.d/mariadb-server.cnf |grep '^wsrep_cluster_address'").read()
node_ips_str = node_ips_info.split('gcomm://')[1]
node_ips_str = node_ips_str.strip()
node_ips_arr = node_ips_str.split(',') # 检测其它节点是否已经有在运行着的
data = {'req_type': 'check_mariadb_service'}
has_mariadb_service_on = False
for node_ip in node_ips_arr:
try:
res_remote = remote_send_request(node_ip, data)
state = res_remote['state']
if state == 'active':
has_mariadb_service_on = True
# 找到在运行着的节点
logger.info('find the running mariadb service node:' + node_ip)
# 直接启动自己服务
os.system('systemctl start mysqld_safe')
time.sleep(10)
if check_is_active_now() is True:
time.sleep(60)
else:
logger.info('start mariadb service error')
break
except Exception,e:
logger.error(traceback.format_exc())
logger.error('check_mariadb_service for ' + node_ip + ' failed, error:' + e.message)
if has_mariadb_service_on is True:
continue # 如果所有节点的mariadb都没在运行,则需要寻找一个节点进行启动
seqno_dict = get_all_nodes_seqno(node_ips_arr)
logger.info('get seqno_dict:%s', seqno_dict)
# 根据seqno值判断哪个节点为启动节点
first_boot_node = None
max_seqno = -2
for key in seqno_dict:
if seqno_dict[key] > max_seqno:
max_seqno = seqno_dict[key]
first_boot_node = key
if first_boot_node is not None:
logger.info('find the first_boot_node by seqno, first_boot_node:' + first_boot_node)
# 判断这个启动节点是不是自己,如果是就启动,否则等待其它节点启动起来
if first_boot_node == get_local_ip():
if start_mariadb_with_wsrep() is True:
time.sleep(60)
else:
logger.info('wait node ' + first_boot_node + ' start mariadb service')
time.sleep(5)
continue
else:
logger.info("all node's seqno is -1") # 如果所有节点的seqno都是-1则说明可能是全部主机非正常停止的,比如断电等
# 这时则通过比对gvwstate.dat文件的my_uuid和view_id是否相等来决定从这个节点启动
# 当集群时干净状态停止的时候该文件是被删除的
uv_equal_dict = get_all_nodes_uv_is_equal(node_ips_arr)
# 根据返回的值判断哪个是启动节点,1表示是,0表示否
for key in uv_equal_dict:
if uv_equal_dict[key] == 1:
first_boot_node = key
logger.info('find the first_boot_node by uv_equal_dict, first_boot_node:' + first_boot_node)
break
if first_boot_node is not None:
# 判断这个启动节点是不是自己,如果是就启动,否则等待其它节点启动起来
if first_boot_node == get_local_ip():
if start_mariadb_with_wsrep() is True:
time.sleep(60)
else:
logger.info('wait node ' + first_boot_node + ' start mariadb service')
time.sleep(5)
continue
else:
logger.info("can not find first_boot_node by gvwstate.dat file") # 如果经过上述步骤依然找不到启动节点,需要人工进行干预了,或者可以随机挑选个节点进行启动
logger.error('can not find first_boot_node, maybe you should ask admin to deal with this problem')
time.sleep(5)
except Exception,e:
logger.error(traceback.format_exc())
logger.error('error:' + e.message) if __name__ == "__main__":
sys.exit(main())
以下是自定义的mysqld_safe.service服务的文件,你可以将它放在/usr/lib/systemd/system/mysqld_safe.service
[Unit]
Description=Thinputer API Server
After=syslog.target network.target [Service]
Type=notify
NotifyAccess=all
TimeoutStartSec=
User=root ExecStartPre=/usr/libexec/mysql-check-socket
ExecStartPre=/usr/libexec/mysql-prepare-db-dir %n
ExecStart=/bin/mysqld_safe --defaults-file=/etc/my.cnf.d/mariadb-server.cnf --user=mysql [Install]
WantedBy=multi-user.target
galera mariadb集群恢复策略的更多相关文章
- 【原】基于 HAproxy 1.6.3 Keeplived 在 Centos 7 中实现mysql mariadb galera cluster 集群分发读写 —— 上篇
前言 有一段时间没有写blogs,乘着周末开始整理下haproxy + keeplived 实现 mysql mariadb galera cluster 集群访问环境的搭建工作. 本文集中讲hapr ...
- MariaDB集群Galera Cluster的研究与测试
MariaDB集群Galera Cluster的研究与测试 Galera Cluster是MariaDB的一个双活多主集群,其可以使得MariDB的所有节点保持同步,Galera为MariaDB提供了 ...
- MariaDB Galera Cluster集群搭建
MariaDB Galera Cluster是什么? Galera Cluster是由第三方公司Codership所研发的一套免费开源的集群高可用方案,实现了数据零丢失,官网地址为http://g ...
- MariaDB Galera Cluster 部署(如何快速部署 MariaDB 集群)
MariaDB Galera Cluster 部署(如何快速部署 MariaDB 集群) OneAPM蓝海讯通7月3日 发布 推荐 4 推荐 收藏 14 收藏,1.1k 浏览 MariaDB 作为 ...
- MariaDB Galera Cluster 部署(如何快速部署MariaDB集群)
MariaDB Galera Cluster 部署(如何快速部署MariaDB集群) [日期:--] 来源:Linux社区 作者:Linux [字体:大 中 小] MariaDB作为Mysql的一个分 ...
- MySQL/MariaDB数据库的Galera高可用性集群实战
MySQL/MariaDB数据库的Galera高可用性集群实战 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Galera Cluster概述 1>.什么是Gale ...
- mariadb集群与nginx负载均衡配置--centos7版本
这里配置得是单nginx主机..先准备4台主机,三台mariadb集群,一台nginx. ------------------------------------------------------- ...
- 负载均衡的mariadb集群搭建
集群介绍: Galera是一个MySQL(也支持MariaDB,Percona)的同步多主集群软件,目前只支持InnoDB引擎. 主要功能: 同步复制 真正的multi-master,即所有节点可以同 ...
- 私有云Mariadb集群搭建
MariaDB作为Mysql的一个分支,在开源项目中已经广泛使用,例如大热的openstack,所以,为了保证服务的高可用性, 同时提高系统的负载能力,集群部署是必不可少的. MariaDB Gale ...
随机推荐
- NodeJS之 Express框架 app.use(express.static)
一 .设置静态文件目录 语法如下: app.use(express.static(_dirname + '/public')); //设置静态文件目录 注: 将静态文件目录设置为项目根目录 + ‘/p ...
- DataTable如何删除特定行
DataTable dt = dataSet1.table1.GetAllRows(); DataRow[] foundRow = dt.Select("catalogid = 0" ...
- 从Object对象中读取属性的值
C#是强类型语言,强到多变态?一个对象没有定义某个属性,你想点出来,IDE直接给你报语法错误.远不如js那么自由,想怎么点怎么点. 如果你从别人接口中拿到的就是Object类型,你想获取某个属性的值怎 ...
- vue常见知识点整理
什么是 mvvm? MVVM 是 Model-View-ViewModel 的缩写.mvvm 是一种设计思想.Model 层代表数据模型,也可以在 Model 中定义数据修改和操作的业务逻辑:View ...
- [javaSE] 并发编程(线程间通信)
新建一个资源类Resource 定义成员变量String name 定义成员变量int age 新建一个输入类Input,实现Runnable接口 定义一个构造方法Input(),传入参数:Resou ...
- 使用JSON实现分页
使用JSON实现分页可直接用 Fenye.html <!DOCTYPE html> <html> <head> <title>JSON分页</ti ...
- cf605D. Board Game(BFS 树状数组 set)
题意 题目链接 有\(n\)张牌,每张牌有四个属性\((a, b, c, d)\),主人公有两个属性\((x, y)\)(初始时为(0, 0)) 一张牌能够被使用当且仅当\(a < x, b & ...
- 教程:RSS全文输出,自己动手做。(一)
这里以PHP版为例,尽量说得通俗点吧,水平实在有限,见谅. 目前我这里所有的获取全文输出的网站大概是三种情况: 要输出的内容集中在一页上,也就是看似列表页的页面里集中了你想要的所有内容,并不需要点击“ ...
- linux解压tar.gz
gnuzip或者tar -zxvf file.tar.gz unzip file.zip
- drupal7 带表达式条件的update
原本的mysql语句是这样的: ; 转化成drupal的api是这样的 $total_amount=1; $rows= db_update('my_payment_card') ->expres ...