“秒杀”问题的数据库和SQL设计【转载】
“秒杀”问题的数据库和SQL设计
问题的来源
上篇文章介绍了 ETL 场景下的高性能最终一致性解决方案,这次的问题也是一个常见的问题。
最近发现很多人被类似秒杀这样的设计困扰,其实这类问题可以很方便地解决,先来说说这类问题的关键点是什么:
- 一定要高性能,不然还能叫秒杀吗?
- 要强一致性,库存只有100个,不能卖出去101个吧?但是库存10000实际只卖了9999是否允许呢?
- 既然这里说了是秒杀,那往往还会针对每个用户有购买数量的限制。
总结一下,还是那几个词:高性能强一致性!
下文的所有解决方案是在 Mysql InnoDB 下做的。因为用到了很多数据库特性。其他的数据库或其他的数据库引擎会有不同的表现,请注意。
完全不考虑一致性的方案
表结构
+-----------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-----------+------------------+------+-----+---------+----------------+
| id | int(11) unsigned | NO | PRI | NULL | auto_increment |
| user_id | int(11) | NO | | NULL | |
| deal_id | int(11) | NO | | NULL | |
| buy_count | int(11) | NO | | NULL | |
+-----------+------------------+------+-----+---------+----------------+
方案
表结构很简单,其实就是一个user和deal的关联表。谁买了多少就插入数据呗。
首先,还要检查一下传过来的buy_count是否超过单人购买限制。
接下来,每次插入前执行以下以下操作检查一下是否超卖即可:
select sum(buy_count) from UserDeal where deal_id = ?
最后还要检查一下这个用户是否购买过:
select count(*) from UserDeal where user_id = ? and deal_id = ?
全都没问题了就插入数据:
insert into UserDeal (user_id, deal_id, buy_count) values (?, ?, ?)
存在的问题
大家别笑,这样的设计你一定做过,刚毕业的时候谁没设计过这样的系统啊?而且大部分系统对性能和一致性的要求并没有那么高,所以以上的设计方案还真是普遍存在的。
那就说说在什么情况下会出问题吧:
- 如果库存只剩一个,两个用户同时点购买,两个人检查全部成功,最后,就超卖了。
- 如果一个用户同时发起两次请求,检测部分同样可能会同时通过,最后,数据就异常了。
那就让我们一步步来解决里面存在的问题吧。
保证单用户不会重复购买
先来解决最简单的问题,保证单用户不会重复购买。
其实只要利用数据库特性即可,让我们来加一个索引:
alter table UserDeal add unique user_id_deal_id(user_id, deal_id)
加上唯一索引后,不仅查询性能提高了,插入的时候如果重复还会自动报错。
当然别忘了在业务代码中 catch 一下这个异常,并在页面上给用户友好的提醒。
解决超卖问题
方案
为了解决这个问题,第一个想到的就是把这几次操作在事务中操作。否则无论怎么改,也都不是原子性的了。
但是加完事务后就完了?
上面的select语句没有使用for update关键字,所以就算加入了事务也不会影响其他人读写。
所以我们只要改一下select语句即可:
select sum(buy_count) from UserDeal where deal_id = ? for update
优化
刚改完后发现,问题解决了!so easy!步步高点读机,哪里不会点哪里,so easy!
但是不对啊!为什么两个用户操作不同的deal也会相互影响呢?
原来我们的select语句中的查询条件是where deal_id = ?,你以为只会锁所有满足条件的数据对吧?
但实际上,如果你查询的条件不在索引中,那么 InnoDB 会启用表锁!
那就加一个索引呗:
alter table UserDeal add index ix_deal_id(deal_id)
提高性能了
好了,到目前为止,无论用户怎没点,无论多少个人买同一单,都不会出现一致性的问题的。
而且事务都是行锁,如果你的业务场景不是秒杀,操作是分散在各个单子上的。而且你的压力不大,那么优化到这就够了。
但是,如果你真的会有几万人、几十万人同时秒杀一个单子怎么办?
很多交易类网站都会有这样的活动。
我们现在思考一下,上面的优化好像已经是极致了,不仅满足了一致性,而且性能方面也做了足够的考量,无从下手啊!
这时候,只能牺牲一些东西了。
鱼与熊掌不可兼得
优化的思路
性能和一致性常常同时出现,却又相互排斥。刚才我们为了解决一致性问题带入了性能问题。现在我们又要为了性能而牺牲一致性了。
这里想提高性能的话,就要去掉事务了。那么一旦去掉事务,一致性就没办法保证了,但有些一致性的问题并不是那么地严重。
所以,这里最关键的就是要想清楚,你的业务场景对什么不能容忍,对什么可以容忍。不同业务场景最后的方案一定是不同的。
秒杀可以容忍什么
本文标题说的是秒杀,因为这个业务场景很常见,那么我们就来说说秒杀。
秒杀最怕的是超卖,但却可以接受少卖。什么是少卖?我有一万份,卖了9999份,但数据库里却说已经买完了。
这个严重吗?只要我们能把这个错误的量控制在一定比例以内并且可以后续修复,那这在秒杀中就不是一个问题了。
为了性能牺牲一致性的设计方案
去掉了事务会发生什么
在上述的方案中,如果去掉了事务,单用户重复购买是不会有问题的,因为这个是通过唯一索引来实现的。
所以这边我们主要是去解决超卖问题。
既然去掉了事务,那么for update锁行就无效了,我们可以另辟蹊径,来解决这个问题。
修改表结构
刚才一直没有提Deal表,其实它就是存了一下基本信息,包括最大售卖量。
之前我们是通过对关联表进行sum(buy_count)操作来得到已经卖掉的数量的,然后进行判断后再进行插入数据。
现在没了事务,这样的操作就不是原子性的了。
所以让我们来修改一下Deal表,把已经售卖的量也存放在Deal表中,然后巧妙地把操作转换成一行update语句。
+-----------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-----------+------------------+------+-----+---------+----------------+
| id | int(11) unsigned | NO | PRI | NULL | auto_increment |
| buy_max | int(11) | NO | | NULL | |
| buy_count | int(11) | NO | | NULL | |
+-----------+------------------+------+-----+---------+----------------+
修改执行过程
如果你继续先把数据查出来到内存中然后再操作,那就不是原子性的了,必定会出问题。
这时候,神奇的update语句来了:
update Deal set buy_count = buy_count + 1 where id = ? and buy_count + 1 <= buy_max
如果一单的buy_max是1000,如果有2000个用户同时操作会发生什么?
虽然没有事务,但是update语句天然会有行锁,前1000个用户都会执行成功,返回生效行数1。而剩下的1000人不会报错,但是生效行数为0。
所以程序中只要判断update语句的生效行数就知道是否抢购成功了。
还没有结束
问题解决了?好像也没牺牲一致性啊,用户根本不会超卖啊?
但是,购买的时候有两个关键信息,“剩余多少”和“谁买了”,刚才的执行过程只处理了第一个信息,它根本没存“谁买了”这个信息。
而这两个信息其实也是原子性的,但是为了性能,我们不得不牺牲一下了。
刚才说到如果update的生效行数是1,就代表购买成功。所以,如果一个用户购买成功了,那么就再去UserDeal表中插入一下数据。
可如果一个用户重复购买了,那么这里也会出错,所以如果这里出错的话还需要去操作一下Deal表把刚才购买的还回去:
update Deal set buy_count = buy_count - 1 where id = ? and buy_count - 1 >= 0
这边理论上不会出现buy_count - 1 < 0的情况,除非你实现的不对。
…… 无图无真相,完全混乱了
只看文字不清晰,还是来张完整的流程图吧!
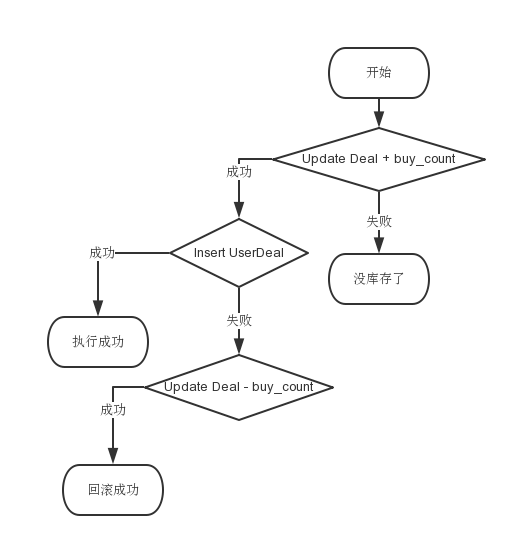
毫无破绽啊!不是说要牺牲一致性吗?为什么没看到?因为上面的流程图还没有考虑数据库故障或者网络故障,最后还是来一张最完整的流程图吧:
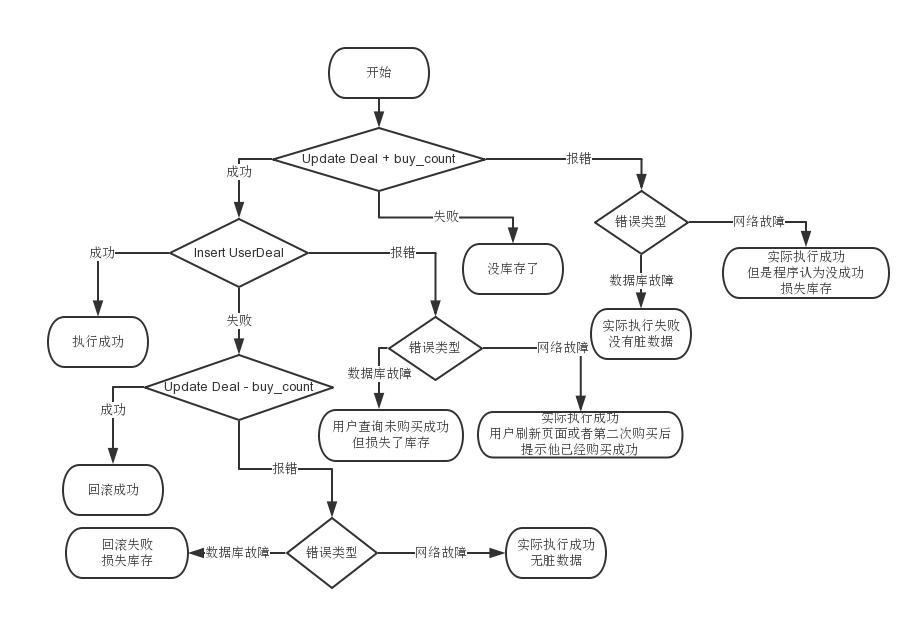
仔细看一下整张流程图,最终就这几种情况:
- 执行成功
- 无库存
- 回滚成功
- 损失库存
前三种是正常的,只有“损失库存”是有问题的。其实,“损失库存”这种情况其实很难出现,只有在网络故障或者数据库的情况下才可能偶尔。
那你的业务可以容忍它吗?最终还是具体问题具体分析了。
不要过度优化
最后还是提醒一句,千万不要过度优化,第一个使用事务的方案其实已经够好了!
除非你的业务特殊,全中国几十万人几百万人会同时来买,那才有必要牺牲一下一致性提升性能。
对了,如果是像双十一或者小米这样子的抢购,上面的方案也是不够的…
本作品由 Dozer 创作,采用 知识共享署名-非商业性使用 4.0 国际许可协议 进行许可。
“秒杀”问题的数据库和SQL设计【转载】的更多相关文章
- SQL语句优化、mysql不走索引的原因、数据库索引的设计原则
SQL语句优化 1 企业SQL优化思路 1.把一个大的不使用索引的SQL语句按照功能进行拆分 2.长的SQL语句无法使用索引,能不能变成2条短的SQL语句让它分别使用上索引. 3.对SQL语句功能的拆 ...
- SQL Server数据库学习笔记-设计表时应该考虑的因素
设计数据库其实就是设计数据库中的表.到底要注意些什么才能够设计好一个数据库呢?一个宗旨,8个建议. 一个宗旨“尽量少的表,每个表中尽量少的列,合理的表结构”. 8个建议: 第一个,首先要考虑的是咱们这 ...
- 淘宝数据库OceanBase SQL编译器部分 源代码阅读--Schema模式
淘宝数据库OceanBase SQL编译器部分 源代码阅读--Schema模式 什么是Database,什么是Schema,什么是Table,什么是列,什么是行,什么是User?我们能够能够把Data ...
- 数据库基础SQL知识面试题一
数据库基础SQL知识面试题一 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 如标题所示,本篇博客主要介绍基础知识的面试题.大家可以用来测试面试者的技术水平,由于个人水平所限,难免 ...
- 十步完全理解SQL(转载)
1. SQL 是一种声明式语言 首先要把这个概念记在脑中:“声明”. SQL 语言是为计算机声明了一个你想从原始数据中获得什么样的结果的一个范例,而不是告诉计算机如何能够得到结果.这是不是很棒? (译 ...
- 树形结构的数据库表Schema设计-基于左右值编码
树形结构的数据库表Schema设计 程序设计过程中,我们常常用树形结构来表征某些数据的关联关系,如企业上下级部门.栏目结构.商品分类等等,通常而言,这些树状结构需要借助于数据库完 成持久化.然而目前的 ...
- 淘宝数据库OceanBase SQL编译器部分 源代码阅读--解析SQL语法树
OceanBase是阿里巴巴集团自主研发的可扩展的关系型数据库,实现了跨行跨表的事务,支持数千亿条记录.数百TB数据上的SQL操作. 在阿里巴巴集团下,OceanBase数据库支持了多个重要业务的数据 ...
- 《淘宝数据库OceanBase SQL编译器部分 源码阅读--解析SQL语法树》
淘宝数据库OceanBase SQL编译器部分 源码阅读--解析SQL语法树 曾经的学渣 2014-06-05 18:38:00 浏览1455 云数据库Oceanbase OceanBase是 ...
- 架构-数据库访问-SQL语言进行连接数据库服务器-DAO:DAO
ylbtech-架构-数据库访问-SQL语言进行连接数据库服务器-DAO:DAO DAO(Data Access Object) 数据访问对象是一个面向对象的数据库接口,它显露了 Microsoft ...
随机推荐
- 将本地项目托管到github 并预览
本地文件上传到github的步骤 1.先在github上建立一个仓库 2.将此仓库download 3.在此文件夹中git bash here 4.进行如下git操作 git git init git ...
- Mysql利用binlog日志恢复数据操作(转)
a.开启binlog日志:1)编辑打开mysql配置文件/etc/mys.cnf[root@vm-002 ~]# vim /etc/my.cnf在[mysqld] 区块添加 log-bin=mysql ...
- Hbase-0.96.2全然分布式安装部署
Hbase-0.96.2全然分布式安装部署 环境: Hadoop-2.2.0 Zookeeper-3.4.6 hbase-0.96.2 1.下载hbase-0.96.2-hadoop2-bin.tar ...
- typename在C++中的用法
. //在C++中typename一般用来声明模板的模板参数(template parameter): template<typename T> class X; //T是一个模板参数 . ...
- Linux下如何查看分区文件系统类型
1,fdisk -l fdisk -l 只能列出硬盘的分区表.容量大小以及分区类型,但看不到文件系统类型. 2,df -h df 命令是用来查看文件系统磁盘空间使用量的.但df 命令只会列出已挂载的文 ...
- OO第一次博客作业总结反思
使用了masteruml插件来生成类图和metrics插件分析代码 第一次作业 1.UML类图 >在第一次作业中,使用了两个类,代码中有没有使用的变量与函数,为平衡两个类的内容,我将输出函数放在 ...
- 在centos6.5下挂载windows共享文件夹
1.在windows下建立文件夹f:\linux,共享给win下用户username,该用户密码为passwd.该windows系统在局域网中IP为192.168.18.203 2.在centos6. ...
- Linux环境下的多线程
1. 按照POSIX 1003.1c 标准编写的程序与Linuxthread 库相链接即可支持Linux平台上的多线程,在程序中需包含头文件pthread. h,在编译链接时使用命令: gcc -D ...
- [agc011E]Increasing Numbers-[思考题]
Description 传送门 Solution 依题得所有不下降数(设为a)可以拆为若干个全1数的和(如:1558=1111+111+111+111+111+1+1+1) 并且任意a所能拆出的全一数 ...
- 小白用linode VPS搭建wordpress博客过程备忘 | Linode中文教程
第一步:装debian系统 1.访问linode官方网站,查看http://library.linode.com/getting-started,我用的是debian系统,用putty登录,升级deb ...