大数据系列之分布式大数据查询引擎Presto
关于presto部署及详细介绍请参考官方链接 http://prestodb-china.com
PRESTO是什么?
Presto是一个开源的分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB字节。
Presto的设计和编写完全是为了解决像Facebook这样规模的商业数据仓库的交互式分析和处理速度的问题。
它可以做什么?
Presto支持在线数据查询,包括Hive, Cassandra, 关系数据库以及专有数据存储。 一条Presto查询可以将多个数据源的数据进行合并,可以跨越整个组织进行分析。
Presto以分析师的需求作为目标,他们期望响应时间小于1秒到几分钟。 Presto终结了数据分析的两难选择,要么使用速度快的昂贵的商业方案,要么使用消耗大量硬件的慢速的“免费”方案。
谁在使用它?
Facebook使用Presto进行交互式查询,用于多个内部数据存储,包括300PB的数据仓库。 每天有1000多名Facebook员工使用Presto,执行查询次数超过30000次,扫描数据总量超过1PB。
领先的互联网公司包括Airbnb和Dropbox都在使用Presto。
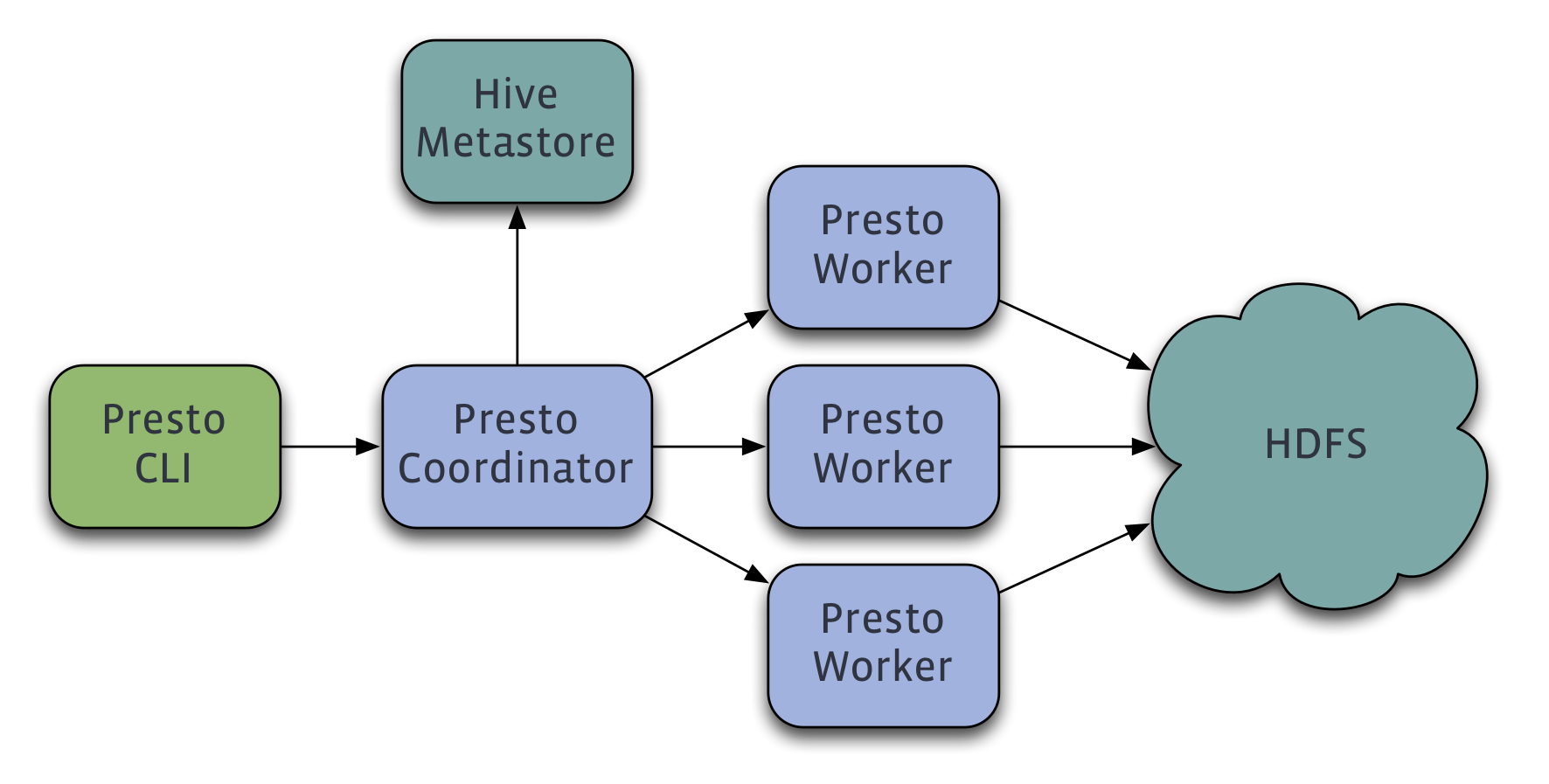
Presto是一个运行在多台服务器上的分布式系统。 完整安装包括一个coordinator和多个worker。 由客户端提交查询,从Presto命令行CLI提交到coordinator。 coordinator进行解析,分析并执行查询计划,然后分发处理队列到worker。
本文介绍Hive与Presto的优缺点:
- 执行效率比较:
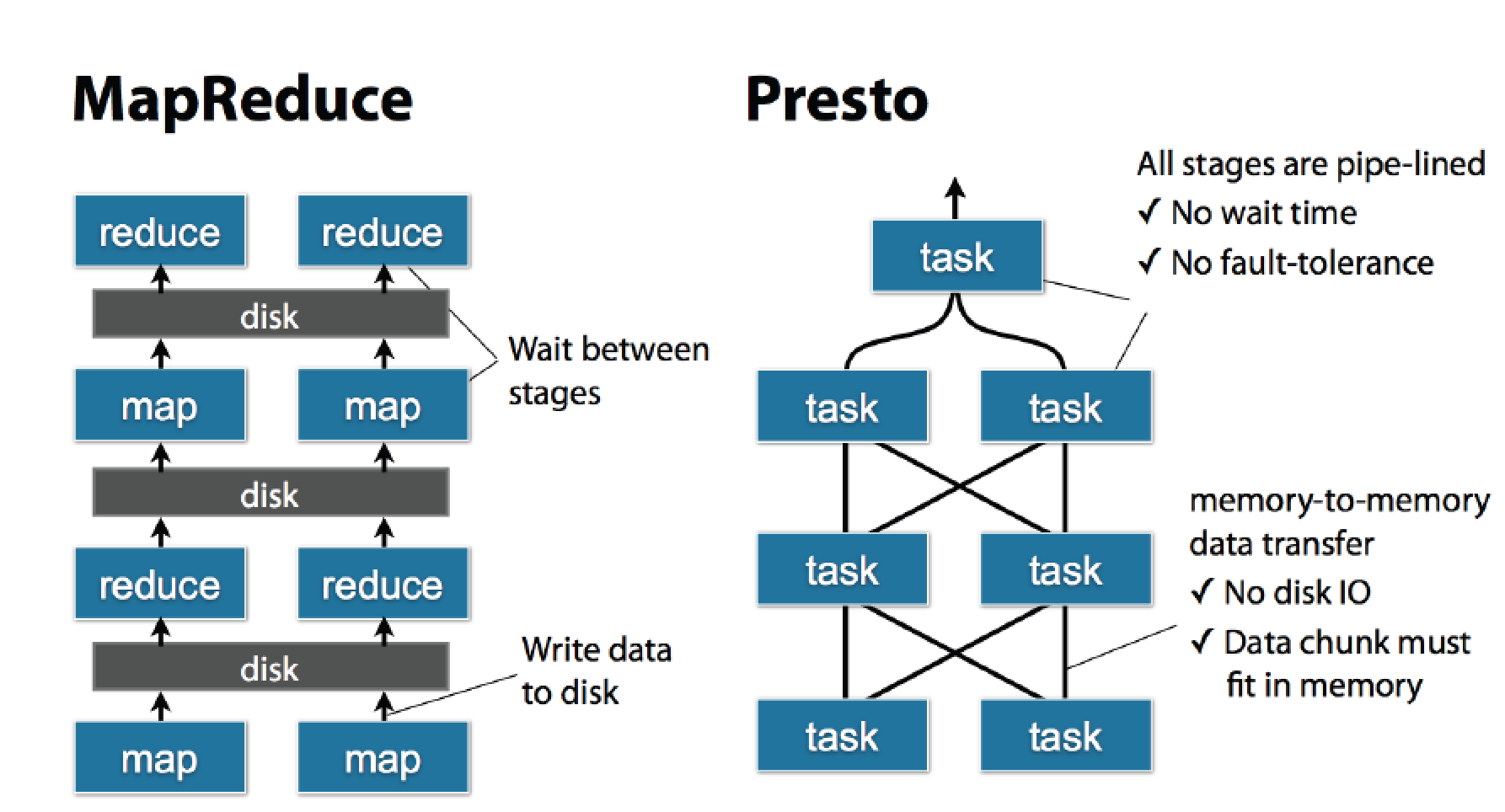
- Hive是Facebook在几年前专为Hadoop打造的一款数据仓库工具。因为它主要依赖MapReduce进行运行,所以随着年龄的上升,其在速度上已不能满足日益增长的数据要求。浏览一个完整的数据集可能要花费几分到几小时,这完全是不切实际的。
- Presto进行简单的查询只需要几百毫秒,即使是非常复杂的查询,也只需数分钟即可完成,它在内存中运行,并且不会向磁盘写入。
- 原理比较:
- Hive是依赖MapReduce进行运行,这个在之前关于Hive的博文中是有介绍的。MR在运行过程中会将结果落入HDFS上,这个比较耗时的。见下图:
大数据系列之分布式大数据查询引擎Presto的更多相关文章
- 大数据系列之分布式数据库HBase-0.9.8安装及增删改查实践
若查看HBase-1.2.4版本内容及demo代码详见 大数据系列之分布式数据库HBase-1.2.4+Zookeeper 安装及增删改查实践 1. 环境准备: 1.需要在Hadoop启动正常情况下安 ...
- Facebook 正式开源其大数据查询引擎 Presto
Facebook 正式宣布开源 Presto —— 数据查询引擎,可对250PB以上的数据进行快速地交互式分析.该项目始于 2012 年秋季开始开发,目前该项目已经在超过 1000 名 Faceboo ...
- 大数据系列之分布式数据库HBase-1.2.4+Zookeeper 安装及增删改查实践
之前介绍过关于HBase 0.9.8版本的部署及使用,本篇介绍下最新版本HBase1.2.4的部署及使用,有部分区别,详见如下: 1. 环境准备: 1.需要在Hadoop[hadoop-2.7.3] ...
- 大数据系列(3)——Hadoop集群完全分布式坏境搭建
前言 上一篇我们讲解了Hadoop单节点的安装,并且已经通过VMware安装了一台CentOS 6.8的Linux系统,咱们本篇的目标就是要配置一个真正的完全分布式的Hadoop集群,闲言少叙,进入本 ...
- CRL快速开发框架系列教程十一(大数据分库分表解决方案)
本系列目录 CRL快速开发框架系列教程一(Code First数据表不需再关心) CRL快速开发框架系列教程二(基于Lambda表达式查询) CRL快速开发框架系列教程三(更新数据) CRL快速开发框 ...
- 大数据系列(1)——Hadoop集群坏境搭建配置
前言 关于时下最热的技术潮流,无疑大数据是首当其中最热的一个技术点,关于大数据的概念和方法论铺天盖地的到处宣扬,但其实很多公司或者技术人员也不能详细的讲解其真正的含义或者就没找到能被落地实施的可行性方 ...
- 大数据系列之并行计算引擎Spark介绍
相关博文:大数据系列之并行计算引擎Spark部署及应用 Spark: Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎. Spark是UC Berkeley AMP lab ( ...
- 分布式大数据高并发的web开发框架
一.引言 通常我们认为静态网页html的网站速度是最快的,但是自从有了动态网页之后,很多交互数据都从数据库查询而来,数据也是经常变化的,除了一些新闻资讯类的网站,使用html静态化来提高访问速度是不太 ...
- 大数据系列(5)——Hadoop集群MYSQL的安装
前言 有一段时间没写文章了,最近事情挺多的,现在咱们回归正题,经过前面四篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,相关的两款软件VSFTP和SecureCRT也已经正常安装了. ...
随机推荐
- http的无状态无连接
搞爬虫的核心:http协议. 在理解http中的无状态和无连接时,有一些困惑,下文可以解决. 转自:http://www.cnblogs.com/bellkosmos/p/5237146.html h ...
- VDOM configuration
VDOM configuration 来源 https://cookbook.fortinet.com/vdom-configuration/ Posted on January 6, 2015 by ...
- Ubuntu实用软件安装[转]
Gedit编辑器配置 Ubuntu14.04从安装软件到卸载软件,删除安装包 linux wget 命令用法详解(附实例说明) ==================================== ...
- web项目中classPath指的是哪里?
classpath可以是SRC下面的路径 但是项目最终编译会到WEB-INF下面,所以有时候WEB-INF下面的classes也可以放配置文件,也可以读取到. 因为最终src都会放到WEB-INF下面 ...
- K8S之Secret
目录 简介 创建secret 1.加密用户名密码 2.加密证书文件 使用secret 1.使用volume挂载方式 2.将secret用于env 简介 secret顾名思义,用于存储一些敏感的需要加密 ...
- 二叉树(前序,中序,后序,层序)遍历递归与循环的python实现
二叉树的遍历是在面试使比较常见的项目了.对于二叉树的前中后层序遍历,每种遍历都可以递归和循环两种实现方法,且每种遍历的递归实现都比循环实现要简洁.下面做一个小结. 一.中序遍历 前中后序三种遍历方法对 ...
- git使用初探
1.创建文件夹,初始化git 比如在 E:\Study\xuexixuexi\guns 下创建一个guns的文件夹 使用cmd进入该文件夹:输入git init git init 2.添加远程仓库: ...
- Django 2.0.1 官方文档翻译: 快速安装向导 (Page5)
快速安装向导 (Page 5) 在你使用 Django 前,你需要先安装它.我们有一个完整的安装向导,它包含所有涉及的内容,这个向导会指导你进行一个简单的.最小化的安装,当你通过浏览介绍内容的时候,这 ...
- Android SDK更新失败对策
Fetching https://dl-ssl.google.com/android/repository/addons_list-2.xml Failed to fetch URL https:// ...
- 单进程单线程的Redis如何能够高并发
redis快的原因: 1.纯内存操作2.异步非阻塞 IO 参考文档: (1)http://yaocoder.blog.51cto.com/2668309/888374 (2)http://www.cn ...