【模式匹配】KMP算法的来龙去脉
1. 引言
字符串匹配是极为常见的一种模式匹配。简单地说,就是判断主串\(T\)中是否出现该模式串\(P\),即\(P\)为\(T\)的子串。特别地,定义主串为\(T[0 \dots n-1]\),模式串为\(P[0 \dots p-1]\),则主串与模式串的长度各为\(n\)与\(p\)。
暴力匹配
暴力匹配方法的思想非常朴素:
- 依次从主串的首字符开始,与模式串逐一进行匹配;
- 遇到失配时,则移到主串的第二个字符,将其与模式串首字符比较,逐一进行匹配;
- 重复上述步骤,直至能匹配上,或剩下主串的长度不足以进行匹配。
下图给出了暴力匹配的例子,主串T="ababcabcacbab",模式串P="abcac",第一次匹配:
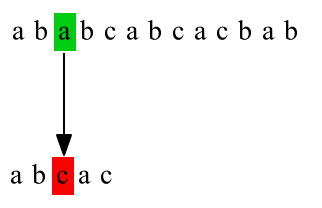
第二次匹配:

第三次匹配:
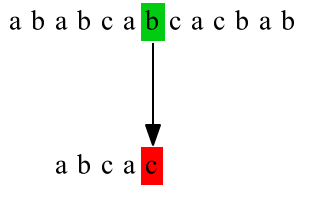
C代码实现:
int brute_force_match(char *t, char *p) {
int i, j, tem;
int tlen = strlen(t), plen = strlen(p);
for(i = 0, j = 0; i <= tlen - plen; i++, j = 0) {
tem = i;
while(t[tem] == p[j] & j < plen) {
tem++;
j++;
}
// matched
if(j == plen) {
return i;
}
}
// [p] is not a substring of [t]
return -1;
}
时间复杂度:i在主串移动次数(外层的for循环)有\(n-p\)次,在失配时j移动次数最多有\(p-1\)次(最坏情况下);因此,复杂度为\(O(n*p)\)。
我们仔细观察暴力匹配方法,发现:失配后下一次匹配,
- 主串的起始位置 = 上一轮匹配的起始位置 + 1;
- 模式串的起始位置 = 首字符
P[0]。
如此未能利用已经匹配上的字符的信息,造成了重复匹配。举个例子,比如:第一次匹配失败时,主串、模式串失配位置的字符分别为 a 与 c,下一次匹配时主串、模式串的起始位置分别为T[1]与P[0];而在模式串中c之前是ab,未有重复字符结构,因此T[1]与P[0]肯定不能匹配上,这样造成了重复匹配。直观上,下一次的匹配应从T[2]与P[0]开始。
2. KMP算法
KMP思想
根据暴力方法的缺点,而引出KMP算法的思想。首先,一般化匹配失败,如下图所示:

在暴力匹配方法中,下一次匹配开始时,主串指针会回溯到i+1,模式串指针会回退到0。那么,如果不让主串指针发生回溯,模式串的指针应回退到哪个位置才能保证正确匹配呢?首先,我们从上图中可以得到已匹配上的字符:
\]
KMP算法思想便是利用已经匹配上的字符信息,使得模式串的指针回退的字符位置能将主串与模式串已经匹配上的字符结构重新对齐。当有重复字符结构时,下一次匹配如下图所示:

从图中可以看出,下一次匹配开始时,主串指针在失配位置i+j,模式串指针回退到m+1;模式串的重复字符结构:
\begin{equation}
T[i+j-m-1 \dots i+j-1] = P[j-m-1 \dots j-1] = P[0 \dots m]
\label{eq:overlap}
\end{equation}
且有
\]
那么应如何选取\(m\)值呢?假定有满足式子\eqref{eq:overlap}的两个值\(m_1 > m_2\),如下图所示:
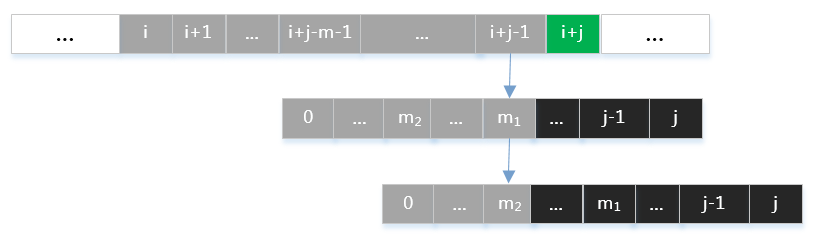
如果选取\(m=m_2\),则会丢失\(m=m_1\)的这一种字符匹配情况。由数学归纳法容易知道,应取所有满足式子\eqref{eq:overlap}中最大的\(m\)值。
KMP算法中每一次的匹配,
- 主串的起始位置 = 上一轮匹配的失配位置;
- 模式串的起始位置 = 重复字符结构的下一位字符(无重复字符结构,则模式串的首字符)
模式串P="abcac"匹配主串T="ababcabcacbab"的KMP过程如下图:
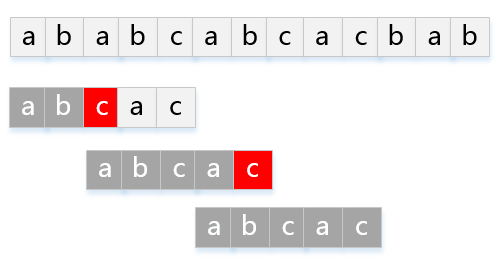
部分匹配函数
根据上面的讨论,我们定义部分匹配函数(Partial Match,在数据结构书[2]称之为失配函数):
{\max \{ m \} } & P[0\dots m]=P[{j-m}\dots {j}],0\le m < j \cr
{-1} & else \cr
} } \right.
\]
其表示字符串\(P[0 \dots j]\)的前缀与后缀完全匹配的最大长度,也表示了模式串中重复字符结构信息。KMP中大名鼎鼎的next[j]函数表示对于模式串失配位置j+1,下一轮匹配时模式串的起始位置(即对齐于主串的失配位置);则
\]
如何计算部分匹配函数呢?首先来看一个例子,模式串P="ababababca"的部分匹配函数与next函数如下:
| j | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| P[j] | a | b | a | b | a | b | a | b | c | a |
| f(j) | -1 | -1 | 0 | 1 | 2 | 3 | 4 | 5 | -1 | 0 |
| next[j] | 0 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 0 | 1 |
模式串的f(j)满足\(P[0 \dots f(j)]=P[j-f(j) \dots j]\),在计算f(j+1)分为两类情况:
- 若\(P[j+1]=P[f(j)+1]\),则有\(P[0 \dots f(j)+1]=P[j-f(j) \dots j+1]\),因此
f(j+1)=f(j)+1。 - 若\(P[j+1] \neq P[f(j)+1]\),则要从\(P[0 \dots f(j)]\)中找出满足
P[f(j+1)]=P[j+1]的f(j+1),从而得到\(P[0 \dots f(j+1)]=P[j+1-f(j+1) \dots j+1]\)
其中,根据f(j)的定义有:
\]
其中,\(f^k(j)=f(f^{k-1}(j))\)。通过上面的例子可知,函数\(f^k(j)\)是随着\(k\)递减的,并最后收敛于-1。此外,P[j]与p[j+1]相邻;因此若存在P[f(j+1)]=P[j+1],则必有
\]
为了求满足条件的最大的f(j+1),因\(f^k(j)\)是随着\(k\)递减的,故应为满足上式的最小\(k\)值。
综上,部分匹配函数的计算公式如下:
{f^k(j-1)+1} & \min \limits_{k} P[f^k(j-1)+1]=P[j] \cr
{-1} & else \cr
} } \right.
\]
代码实现
部分匹配函数(失配函数)的C实现代码:
int *fail(char *p) {
int len = strlen(p);
int *f = (int *) malloc(len * sizeof(int));
f[0] = -1;
int i, j;
for(j = 1; j < len; j++) {
for(i = f[j-1]; ; i = f[i]) {
if(p[j] == p[i+1]) {
f[j] = i + 1;
break;
}
else if(i == -1) {
f[j] = -1;
break;
}
}
}
return f;
}
KMP的C实现代码:
int kmp(char *t, char *p) {
int *f = fail(p);
int i, j;
for(i = 0, j = 0; i < strlen(t) && j < strlen(p); ) {
if(t[i] == p[j]) {
i++;
j++;
}
else if(j == 0)
i++;
else
j = f[j-1] + 1;
}
return j == strlen(p) ? i - strlen(p) : -1;
}
时间复杂度:fail函数的复杂度为\(O(p)\),kmp函数的复杂度为\(O(n)\),所以整个KMP算法的复杂度为\(O(n+p)\)。
3. 参考资料
[1] dekai, Lecture 16: String Matching.
[2] E. Horowitz, S. Sahni, S. A. Freed, 《Fundamentals of Data Structures in C》.
[3] Jake Boxer, The Knuth-Morris-Pratt Algorithm in my own words.
【模式匹配】KMP算法的来龙去脉的更多相关文章
- 字符串模式匹配KMP算法
一篇不错的博客:http://www.cnblogs.com/dolphin0520/archive/2011/08/24/2151846.html KMP字符串模式匹配通俗点说就是一种在一个字符串中 ...
- KMP算法的来龙去脉
1. 引言 字符串匹配是极为常见的一种模式匹配.简单地说,就是判断主串TT中是否出现该模式串PP,即PP为TT的子串.特别地,定义主串为T[0-n−1]T[0-n−1],模式串为P[0-p−1]P[0 ...
- 字符串模式匹配——KMP算法
KMP算法匹配字符串 朴素匹配算法 字符串的模式匹配的方法刚开始是朴素匹配算法,也就是经常说的暴力匹配,说白了就是用子串去和父串一个一个匹配,从父串的第一个字符开始匹配,如果匹配到某一个失配了,就 ...
- 模式匹配KMP算法
关于KMP算法的原理网上有很详细的解释,我试着总结理解一下: KMP算法是什么 以这张图片为例子 匹配到j=5时失效了,BF算法里我们会使i=1,j=0,再看s的第i位开始能不能匹配,而KMP算法接下 ...
- 模式匹配-KMP算法
/***字符串匹配算法***/ #include<cstring> #include<iostream> using namespace std; #define OK 1 # ...
- 数据结构4.3_字符串模式匹配——KMP算法详解
next数组表示字符串前后缀匹配的最大长度.是KMP算法的精髓所在.可以起到决定模式字符串右移多少长度以达到跳跃式匹配的高效模式. 以下是对next数组的解释: 如何求next数组: 相关链接:按顺序 ...
- 深入理解KMP算法之续篇
前言: 纠结于KMP已经两天了,相较于本人之前博客中提到的几篇博文,本人感觉这篇文章更清楚地说明了KMP算法的来龙去脉. http://www.cnblogs.com/goagent/archive/ ...
- 字符串模式匹配之KMP算法图解与 next 数组原理和实现方案
之前说到,朴素的匹配,每趟比较,都要回溯主串的指针,费事.则 KMP 就是对朴素匹配的一种改进.正好复习一下. KMP 算法其改进思想在于: 每当一趟匹配过程中出现字符比较不相等时,不需要回溯主串的 ...
- 串的模式匹配和KMP算法
在对字符串的操作中,我们经常要用到子串的查找功能,我们称子串为模式串,模式串在主串中的查找过程我们成为模式匹配,KMP算法就是一个高效的模式匹配算法.KMP算法是蛮力算法的一种改进,下面我们先来介绍蛮 ...
随机推荐
- 弹层,iframe页面
前台页面: <img src="chb/老玩家 好礼送.jpg" border="0" width="202" height=&quo ...
- RCP:给GEF编辑器添加拖拽辅助线
当图形边缘碰触时,会产生一条帮助拖拽的辅助线 这里需要三个类: 1.SnapToGeomotry 2.SnapToGuide(非必须) 3.SnapFeedbackPolicy
- 【腾讯Bugly干货分享】深入理解 ButterKnife,让你的程序学会写代码
本文来自于腾讯bugly开发者社区,非经作者同意,请勿转载,原文地址:http://dev.qq.com/topic/578753c0c9da73584b025875 0.引子 话说我们做程序员的,都 ...
- 为 Exchange 服务器编写自定义的反垃圾插件
Exchange 2010 的 Edge Transport 包含了一些 Anti-spam 的 Feature,如图: 都开启了,但是呢,还是会有漏网之鱼,而且把这些邮件自己列为 Junk 也起不了 ...
- MVVM架构~knockoutjs系列之从Knockout.Validation.js源码中学习它的用法
返回目录 说在前 有时,我们在使用一个插件时,在网上即找不到它的相关API,这时,我们会很抓狂的,与其抓狂,还不如踏下心来,分析一下它的源码,事实上,对于JS这种开发语言来说,它开发的插件的使用方法都 ...
- bower使用记录
每次做项目的时候都不依赖某一个库来开发,每次需要某一个库的时候都是百度进入库官网再找到下载的库,经常会因为官网的改版更新而在里面绕半天找不到想要的版本号,当然直接去github,CDN 都可以找到需要 ...
- salesforce 零基础学习(三十三)通过REST方式访问外部数据以及JAVA通过rest方式访问salesforce
本篇参考Trail教程: https://developer.salesforce.com/trailhead/force_com_dev_intermediate/apex_integration_ ...
- iOS-SDWebImage
我之前写过一篇博客,介绍缓存处理的三种方式,其中最难,最麻烦,最占内存资源的还是图片缓存,最近做的项目有大量的图片处理,还是采用了SDWebImage来处理,但是发现之前封装好的代码报错了.研究发现, ...
- jQuery对 动态添加 的元素 绑定事件(on()的用法)
从jQuery 版本 1.7 起,on() 方法是向被选元素添加事件处理程序的(官方推荐)首选方法. 当浏览器下载完一个页面的时候就开始渲染(翻译)HTML标签,然后执行css.js代码,在执行js代 ...
- HTTP学习补充一
1 HTTP协议协商 1.1 NPN NPN:Next Protocol Negotiation,是由Google公司开发的用于SPDY进行协议协商扩展. 协商过程: 服务端在收到客户端的client ...