loglikelihood ratio 相似度
摘要:
在机器学习中常用到各种距离或者相似度,今天在看美团推荐系统重排序的文章时看到了loglikelihood ratio 相似度,特总结起来。以后有时间再把常用的相似度或者距离梳理到一篇文章。
背景:
记录loglikelihood ratio 相似度概念
总结:
在mahout中,loglikelihood ratio也作为一种相似度计算方法被采用。
下表表示了Event A和Event B之间的相互关系,其中:
k11 :Event A和Event B共现的次数
k12 :Event A发生,Event B未发生的次数
k21 :Event B发生,Event A未发生的次数
k22 :Event A和Event B都不发生的次数
则logLikelihoodRatio=2 * (matrixEntropy - rowEntropy - columnEntropy)
其中
rowEntropy = entropy(k11, k12) + entropy(k21, k22)
columnEntropy = entropy(k11, k21) + entropy(k12, k22)
matrixEntropy = entropy(k11, k12, k21, k22)
(entropy为几个元素组成的系统的香农熵)
下面举一个实际的例子:
我以一个实际的例子来介绍一下其中的计算过程:假设有商品全集I={a,b,c,d,e,f},其中A用户偏好商品{a,b,c},B用户偏好商品{b,d},那么有如下矩阵:
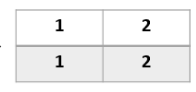
- k11表示用户A和用户B的共同偏好的商品数量,显然只有商品b,因此值为1
- k12表示用户A的特有偏好,即商品{a,c},因此值为2
- k21表示用户B的特有偏好,即商品d,因此值为1
- k22表示用户A、B的共同非偏好,有商品{e,f},值为2
此外我们还定义以下变量N=k11+k12+k21+k22,即总商品数量。
计算步骤如下:
计算行熵
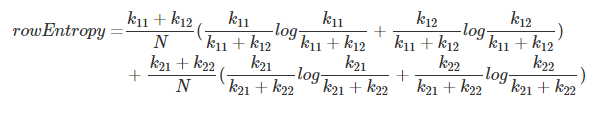
注:代码中k11+k12与k21+k22均被约掉了,分母N也省去了
计算列熵
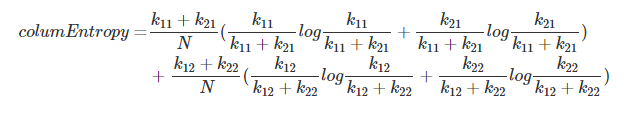
计算矩阵熵
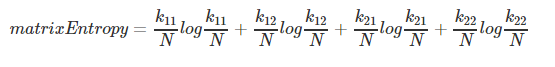
注意:以上熵的计算均没有加负号,后面会讲到原因
计算相似度
UserSimilarity=2∗(matrixEntropy−rowEntropy−columnEntropy)- 实现代码:https://github.com/Tongzhenguo/Java-codes/blob/master/src/main/java/data/code/similarity/logLikelihoodRatio.java
参考链接:
http://www.csdn.net/article/2015-01-30/2823783
http://blog.csdn.net/u014374284/article/details/49823557
loglikelihood ratio 相似度的更多相关文章
- SVM与LR的比较
两种方法都是常见的分类算法,从目标函数来看,区别在于逻辑回归采用的是logistical loss,svm采用的是hinge loss.这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与 ...
- DNA binding motif比对算法
DNA binding motif比对算法 2012-08-31 ~ ADMIN 之前介绍了序列比对的一些算法.本节主要讲述motif(有人翻译成结构模式,但本文一律使用基模)的比对算法. 那么什么是 ...
- OpenCV进行图像相似度对比的几种办法
转载请注明出处:http://blog.csdn.net/wangyaninglm/article/details/43853435, 来自:shiter编写程序的艺术 对计算图像相似度的方法,本文做 ...
- Python 连接MongoDB并比较两个字符串相似度的简单示例
本文介绍一个示例:使用 pymongo 连接 MongoDB,查询MongoDB中的 字符串 记录,并比较字符串之间的相似度. 一,Python连接MongoDB 大致步骤:创建MongoClient ...
- 字符串相似度算法-LEVENSHTEIN DISTANCE算法
Levenshtein Distance 算法,又叫 Edit Distance 算法,是指两个字符串之间,由一个转成另一个所需的最少编辑操作次数.许可的编辑操作包括将一个字符替换成另一个字符,插入一 ...
- 【NLP】Python实例:基于文本相似度对申报项目进行查重设计
Python实例:申报项目查重系统设计与实现 作者:白宁超 2017年5月18日17:51:37 摘要:关于查重系统很多人并不陌生,无论本科还是硕博毕业都不可避免涉及论文查重问题,这也对学术不正之风起 ...
- python-Levenshtein几个计算字串相似度的函数解析
linux环境下,没有首先安装python_Levenshtein,用法如下: 重点介绍几个该包中的几个计算字串相似度的几个函数实现. 1. Levenshtein.hamming(str1, str ...
- win7基于mahout推荐之用户相似度计算
http://www.douban.com/note/319219518/?type=like win7基于mahout推荐之用户相似度计算 2013-12-03 09:19:11 事情回到半年 ...
- Levenshtein计算相似度距离
使用Levenshtein计算相似度距离,装下模块,调用下函数就好. 拿idf还得自己去算权重,而且不一定准确度高,一般做idf还得做词性归一化,把动词形容词什么全部转成名词,很麻烦. Levensh ...
随机推荐
- 编译 wxWidgets-3.0.2 on Mac OS X Yosemite 出错?!的解决方法
tar -zxf wxWidgets-3.0.2.tar.bz2 //解压 //三部走 ./configure ./make 提示webKit出错 原因:有人偷懒,没试编译就发布了. 解决:找到. ...
- 如何写出优雅兼备可读性的javascript代码
即或是最简单的需求,不同的程序员也会写出不一样的代码: 需求:充值程序过虑不符合条件的充值金额,即只能充入100.200.500.1000金额,其它过虑: 1.菜鸟程序员可能会这样写,虽然可读性强,代 ...
- Linux的phpstudy mysql登录
使用绝对路径登录 /phpStudy/mysql/bin/mysql -uroot -p; 设置远程登录密码 GRANT ALL PRIVILEGES ON *.* TO 'itoffice'@'%' ...
- 和以往印象不同的Java
Java编程概述 一个Java源文件至多有一个public类,但是可以有很多class的定义 public static void main (String args[]) public 代表公共的, ...
- java 8种基本数据类型的默认值及所占字节数
通过一段代码来测试一下 8种基本数据类型的默认值 package dierge; public class Ceshi { int a; double b; boolean c; char d; fl ...
- 使用extjs6官方模板admin-dashboard
1.生成项目: sencha generate app -s templates/admin-dashboard/ Dashboard ../my-folder 2.修改app.json的output ...
- Win7 64位 VS2015环境编译cegui-0.8.5
首先是去官网下载源码与依赖库 http://cegui.org.uk/ 然后得提一下,编译DX11版本带Effects11框架的话会有问题,也就是默认情况编译有问题,这是因为VS2015升级后编译器对 ...
- Celery Running Environment
After running celery in my machine, I got this: Running a worker with superuser privileges when the ...
- 【开发环境】JAVA 环境变量批处理
@echo off set regpath=HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Session Manager\Environmen ...
- [UCSD白板题] Binary Search
Problem Introduction In this problem, you will implemented the binary search algorithm that allows s ...