chapter02 朴素贝叶斯分类器对新闻文本数据进行类型预测
基本数学假设:各个维度上的特征被分类的条件概率之间是相互独立的。所以在特征关联性较强的分类任务上的性能表现不佳。 #coding=utf8 # 从sklearn.datasets里导入新闻数据抓取器fetch_20newsgroups。 from sklearn.datasets import fetch_20newsgroups # 从sklearn.model_selection中导入train_test_split用于数据分割。 from sklearn.model_selection import train_test_split # 与之前预存的数据不同,fetch_20newsgroups需要即时从互联网下载数据。 news = fetch_20newsgroups(subset='all') # 随机采样25%的数据样本作为测试集。 X_train, X_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25, random_state=33) # 从sklearn.feature_extraction.text里导入用于文本特征向量转化模块。 from sklearn.feature_extraction.text import CountVectorizer vec = CountVectorizer() X_train = vec.fit_transform(X_train) X_test = vec.transform(X_test) # 从sklearn.naive_bayes里导入朴素贝叶斯模型。 from sklearn.naive_bayes import MultinomialNB # 从使用默认配置初始化朴素贝叶斯模型。 mnb = MultinomialNB() # 利用训练数据对模型参数进行估计。 mnb.fit(X_train, y_train) # 对测试样本进行类别预测,结果存储在变量y_predict中。 y_predict = mnb.predict(X_test) # 从sklearn.metrics里导入classification_report用于详细的分类性能报告。 from sklearn.metrics import classification_report print 'The accuracy of Naive Bayes Classifier is', mnb.score(X_test, y_test) print classification_report(y_test, y_predict, target_names=news.target_names)
结果:
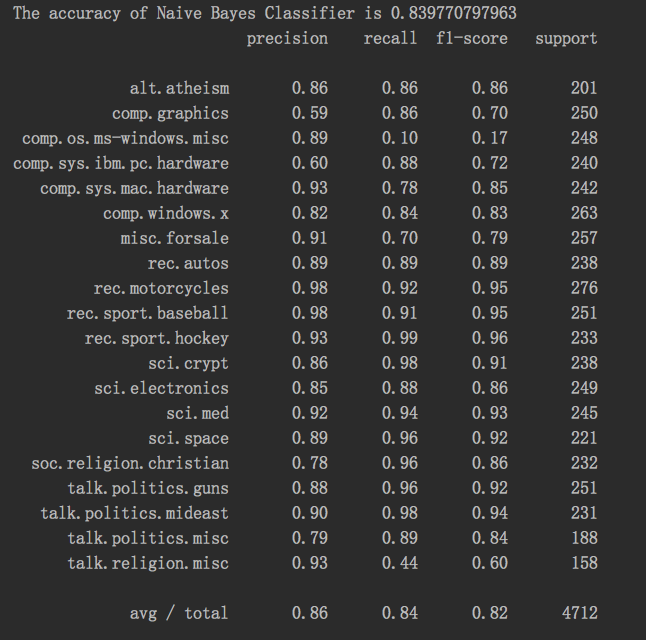
chapter02 朴素贝叶斯分类器对新闻文本数据进行类型预测的更多相关文章
- 机器学习之路: python 朴素贝叶斯分类器 MultinomialNB 预测新闻类别
使用python3 学习朴素贝叶斯分类api 设计到字符串提取特征向量 欢迎来到我的git下载源代码: https://github.com/linyi0604/MachineLearning fro ...
- (数据科学学习手札30)朴素贝叶斯分类器的原理详解&Python与R实现
一.简介 要介绍朴素贝叶斯(naive bayes)分类器,就不得不先介绍贝叶斯决策论的相关理论: 贝叶斯决策论(bayesian decision theory)是概率框架下实施决策的基本方法.对分 ...
- 文本分类(TFIDF/朴素贝叶斯分类器/TextRNN/TextCNN/TextRCNN/FastText/HAN)
目录 简介 TFIDF 朴素贝叶斯分类器 贝叶斯公式 贝叶斯决策论的理解 极大似然估计 朴素贝叶斯分类器 TextRNN TextCNN TextRCNN FastText HAN Highway N ...
- 用scikit-learn实现朴素贝叶斯分类器 转
原文:http://segmentfault.com/a/1190000002472791 朴素贝叶斯(Naive Bayes Classifier)是一种「天真」的算法(假定所有特征发生概率是独立的 ...
- python实现随机森林、逻辑回归和朴素贝叶斯的新闻文本分类
实现本文的文本数据可以在THUCTC下载也可以自己手动爬虫生成, 本文主要参考:https://blog.csdn.net/hao5335156/article/details/82716923 nb ...
- 机器学习---朴素贝叶斯分类器(Machine Learning Naive Bayes Classifier)
朴素贝叶斯分类器是一组简单快速的分类算法.网上已经有很多文章介绍,比如这篇写得比较好:https://blog.csdn.net/sinat_36246371/article/details/6014 ...
- 数据挖掘十大经典算法(9) 朴素贝叶斯分类器 Naive Bayes
贝叶斯分类器 贝叶斯分类器的分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类.眼下研究较多的贝叶斯分类器主要有四种, ...
- 十大经典数据挖掘算法(9) 朴素贝叶斯分类器 Naive Bayes
贝叶斯分类器 贝叶斯分类分类原则是一个对象的通过先验概率.贝叶斯后验概率公式后计算,也就是说,该对象属于一类的概率.选择具有最大后验概率的类作为对象的类属.现在更多的研究贝叶斯分类器,有四个,每间:N ...
- 朴素贝叶斯分类器(Naive Bayes)
1. 贝叶斯定理 如果有两个事件,事件A和事件B.已知事件A发生的概率为p(A),事件B发生的概率为P(B),事件A发生的前提下.事件B发生的概率为p(B|A),事件B发生的前提下.事件A发生的概率为 ...
随机推荐
- WZY社区
WZY社区是我自己做的一个网站,后面会详细更新,敬请关注!
- Django 综合篇
前面,已经将Django最主要的五大系统介绍完毕,除了这些主要章节,还有很多比较重要的内容,比如开发流程相关.安全.本地化与国际化.常见工具和一些框架核心功能.这些内容的篇幅都不大,但整合起来也是Dj ...
- 用docker部署flask+gunicorn+nginx
说来惭愧,写了好几个flask django项目都是在原型阶段直接python app.py 运行的,涉及到部署用nginx和gunicorn 都是让别人帮我部署的,据说好像说很麻烦的样子,我就没自己 ...
- C++学习笔记(一)——一个字符串分割和统计的工具(TextUtils)
第一讲先从一个实例开始——我们需要完成一个遍历文件并统计单词出现次数的任务.分解功能:首先,按行读取文件并舍弃可能的空行.其次,将每一行都按照空格划分单词.因为可能存在标点符号,我们还需要将标点符号都 ...
- Python 爬虫-图片的爬取
2017-07-25 22:49:21 import requests import os url = 'https://wallpapers.wallhaven.cc/wallpapers/full ...
- java使用freemarker生成静态html页面
1. 模板文件static.html <!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" " ...
- 雷林鹏分享:Ruby 方法
Ruby 方法 Ruby 方法与其他编程语言中的函数类似.Ruby 方法用于捆绑一个或多个重复的语句到一个单元中. 方法名应以小写字母开头.如果您以大写字母作为方法名的开头,Ruby 可能会把它当作常 ...
- 测序中Q20 Q30 Q40
你能给别人讲清楚这个概念吗? 二代测序中,每测一个碱基会给出一个相应的质量值,这个质量值是衡量测序准确度的.碱基的质量值13,错误率为5%,20的错误率为1%,30的错误率为0.1%.行业中Q20与Q ...
- Silverlight自定义控件系列 – TreeView (1)
原文路径:http://blog.csdn.net/wlanye/article/details/7265457 很多人都对MS自带的控件不太满意(虽然MS走的是简约风格),都会试图去修改或创建让 ...
- English trip -- VC(情景课)2 B Classroom objects
Vocabulary focus 核心词汇 Listen and repeat. 听并跟读 1. a dictionary 2. paper 3. a pen 4. a ruler 5. a stap ...