splash渲染网页
#coding=utf8
import requests,time,random
import threadpool render_html = 'http://192.168.30.128:8050/render.html' ##填写你的地址
url=’http://s.weibo.com/weibo/%25E8%25B5%25B5%25E9%259B%2585%25E8%258A%259D?topnav=1&wvr=6&b=1'
headerx = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0'}
datax = {"url": url, "wait": , 'images': , 'timeout': } #如果要使用代理ip加上这个 ,'proxy':pr} # ,'proxy': 'http://119.115.233.93:8118'} responsex=requests.get(url=render_html ,headers=headerx,params=datax)
return responsex
splash 文档地址 http://splash.readthedocs.io/en/latest/scripting-tutorial.html
docker安装,自己百度。
装完docker后,运行
docker pull scrapinghub/spalsh
docker run -d -p 8050:8050 scrapinghub/spalsh
之后使用这个函数请求就可以得到渲染后的地址了。
电脑打开,http://192.168.30.128:8050/render.html (换成你自己的ip),可以在这里面测试,例如打开chinaz首页。
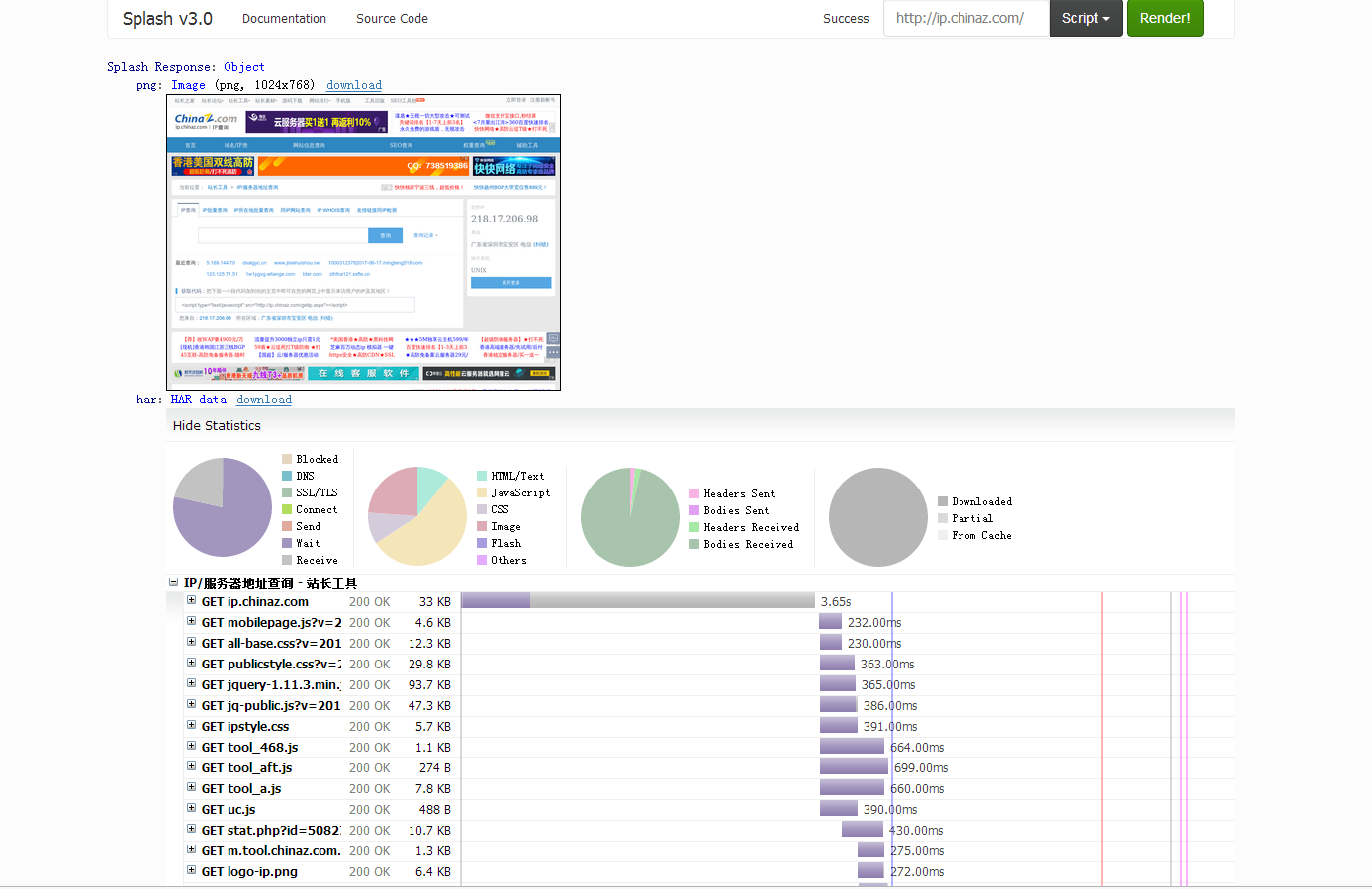
splash渲染网页的更多相关文章
- 关于js渲染网页时爬取数据的思路和全过程(附源码)
于js渲染网页时爬取数据的思路 首先可以先去用requests库访问url来测试一下能不能拿到数据,如果能拿到那么就是一个普通的网页,如果出现403类的错误代码可以在requests.get()方法里 ...
- Splash (渲染JS服务)介绍安装
一. splash介绍 1.Splash 是一个带有 HTTP API 的 javascript 渲染服务.它是一个带有 HTTP API 的轻量级浏览器,使用 Twisted 和 QT5 在 Pyt ...
- 关于强制IE不使用兼容模式渲染网页
现在IE11是唯一受微软支持的IE浏览器. IE11有兼容模式,开启后有网页会出错. 在html header标签下加上 <meta http-equiv="X-UA-Compatib ...
- 如何让360、遨游、猎豹等双核浏览器默认以webkit内核渲染网页?
众知目前国内不少浏览器都自称双核,一般是 IE(Trident)+Webkit.因为 webkit 急速的体验和对 HTML5 的支持,有些情况下开发者可能希望用户优先甚至只使用 webkit 内核渲 ...
- Cufon在渲染网页字体你不知道的事
清单 1. 无效的 font-family 字体指定 <style> .introduction { font-family:'Baroque Script';} </style&g ...
- selenium +chrome headless Adhoc模式渲染网页
mannual和adhoc模式比较 Manual vs. Adhoc In the script above, we start the ChromeDriver server process whe ...
- selenium +chrome headless Manual 模式渲染网页
可以看看这个里面的介绍,写得很好.https://duo.com/blog/driving-headless-chrome-with-python from selenium import webdr ...
- selenium+phantomjs渲染网页
from selenium import webdriverfrom selenium.webdriver.common.desired_capabilities import DesiredCapa ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
随机推荐
- drupal 精彩文章
1.如何快速查找Drupal表单的Form ID?http://www.drupalla.com/node/2306
- Extjs4.x Ext.tree.Panel 遍历当前节点下的所有子节点
Ext.define('WMS.controller.Org', { extend: 'Ext.app.Controller', stores: ['OrgUser', 'OrgTree'], mod ...
- mysql查看不同级别的字符集
库的字符集: SELECT default_character_set_name FROM information_schema.SCHEMATA SWHERE schema_name = 'test ...
- kd-tree理论以及在PCL 中的代码的实现
(小技巧记录:博客园编辑的网页界面变小了使用Ctrl ++来变大网页字体) 通过雷达,激光扫描,立体摄像机等三维测量设备获取的点云数据,具有数据量大,分布不均匀等特点,作为三维领域中一个重要的数据来 ...
- [maven] settings 文件 国内镜像站
<?xml version="1.0" encoding="UTF-8"?> <!-- Licensed to the Apache Soft ...
- 提供openssl -aes-256-cbc兼容加密/解密的简单python函数
原文链接:http://joelinoff.com/blog/?p=885 这里的示例显示了如何使用python以与openssl aes-256-cbc完全兼容的方式加密和解密数据.它是基于我在本网 ...
- 解决git pull 每一次都需要输入密码的问题
方法1: 当我们配置好我们的git以后呢,我们可以在配置文件~/.gitconfig 或 ~/.config/git/config 文件里加入这么两行: [credential] helper = s ...
- 第三百五十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy信号详解
第三百五十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy信号详解 信号一般使用信号分发器dispatcher.connect(),来设置信号,和信号触发函数,当捕获到信号时执行 ...
- 转:用法总结:NSNumber、NSString、NSDate、NSCalendarDate、NSData(待续)
NSNumber + (NSNumber *)numberWithInt:(int)value; + (NSNumber *)numberWithDouble:(double)value; - (in ...
- (原)tslib的交叉编译
今天准备重新来交叉编译qt5.3.1的源码,由于按网上说的,需要先编译tslib,所以拿起来之前的编译源码,打算重新用新的交叉编译工具再次编译一次,在查找资料的过程中浪费了些许时间.其实直接就在使用s ...