Kafka:ZK+Kafka+Spark Streaming集群环境搭建(八)安装zookeeper-3.4.12
如何搭建配置centos虚拟机请参考《Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。》
如何安装hadoop2.9.0请参考《Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二)安装hadoop2.9.0》
如何配置hadoop2.9.0 HA 请参考《Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA》
如何安装spark2.2.1请参考《Kafka:ZK+Kafka+Spark Streaming集群环境搭建(三)安装spark2.2.1》
安装zookeeper的服务器:
192.168.0.120 master
192.168.0.121 slave1
192.168.0.122 slave2
192.168.0.123 slave3
备注:只在master,slave1,slave2三个节店上安装zookeeper,slave3节店不安装(其实前边hadoop中master不作为datanode节店,spark中master不作为worker节店)。关于zk只允许安装奇数节点的原因这里不写。
1. 简介
Kafka 依赖 Zookeeper 管理自身集群(Broker、Offset、Producer、Consumer等),所以先要安装 Zookeeper。
为了达到高可用的目的,Zookeeper 自身也不能是单点,接下来就介绍如何搭建一个最小的 Zookeeper 集群(3个 zk 节点)。
2.下载解压zk
从官网找到下载地址,并下载zookeeper-3.4.12
上传zookeeper-3.4.12.tar.gz在master节点上,并解压:
[spark@master ~]$ cd /opt/
[spark@master opt]$ su root
Password:
[root@master opt]# tar -zxvf zookeeper-3.4..tar.gz
[root@master opt]# ls
hadoop-2.9. jdk1..0_171 scala-2.11. spark-2.2.-bin-hadoop2. zookeeper-3.4.
hadoop-2.9..tar.gz jdk-8u171-linux-x64.tar.gz scala-2.11..tgz spark-2.2.-bin-hadoop2..tgz zookeeper-3.4..tar.gz
[root@master opt]#
3.配置zk
1)配置文件位置
路径:/opt/zookeeper-3.4.12/conf/
[root@master conf]# cd /opt/zookeeper-3.4./conf/
[root@master conf]# ls
configuration.xsl log4j.properties zoo_sample.cfg
[root@master conf]#
2)生成配置文件
将 zoo_sample.cfg 复制一份,命名为 zoo.cfg,此即为Zookeeper的配置文件。
[root@master conf]# cd /opt/zookeeper-3.4./conf/
[root@master conf]# cp zoo_sample.cfg zoo.cfg
3)编辑配置文件zoo.cfg
# The number of milliseconds of each tick
tickTime=
# The number of ticks that the initial
# synchronization phase can take
initLimit=
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes. dataDir=/opt/zookeeper-3.4./data
dataLogDir=/opt/zookeeper-3.4./logs # the port at which the clients will connect
clientPort=
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=
# Purge task interval in hours
# Set to "" to disable auto purge feature
#autopurge.purgeInterval= server.=192.168.0.120::
server.=192.168.0.121::
server.=192.168.0.122::
说明:
- dataDir 和 dataLogDir 需要在启动前创建完成
[root@master conf]# mkdir /opt/zookeeper-3.4./data
[root@master conf]# mkdir /opt/zookeeper-3.4./logs - clientPort 为 zookeeper的服务端口
- server.0、server.1、server.2 为 zk 集群中三个 node 的信息,定义格式为 hostname:port1:port2,其中 port1 是 node 间通信使用的端口,port2 是node 选举使用的端口,需确保三台主机的这两个端口都是互通的。
4. 更改日志配置
Zookeeper 默认会将控制台信息输出到启动路径下的 zookeeper.out 中,通过如下方法,可以让 Zookeeper 输出按尺寸切分的日志文件:
1)修改/opt/zookeeper-3.4.12/conf/log4j.properties文件,将
zookeeper.root.logger=INFO, CONSOLE
改为
zookeeper.root.logger=INFO, ROLLINGFILE
2)修改/opt/zookeeper-3.4.12/bin/zkEnv.sh文件,将
ZOO_LOG4J_PROP="INFO,CONSOLE"
改为
ZOO_LOG4J_PROP="INFO,ROLLINGFILE"
5.在master主机的 dataDir 路径下创建一个文件名为 myid 的文件
文件内容为该 zk 节点的编号。
在master上操作:
[root@master zookeeper-3.4.]# echo >>/opt/zookeeper-3.4./data/myid
[root@master zookeeper-3.4.]# cd /opt/zookeeper-3.4./data/
[root@master data]# ls
myid
[root@master data]# more myid
1
[root@master data]#
备注:
1、在第一台master主机上建立的 myid 文件内容是 1,第二台slave1主机上建立的myid文件内容是 2,第三台slave2主机上建立的myid文件内容是 3。myid文件内容需要与/opt/zookeeper-3.4.12/conf/zoo.cfg中的配置的server.id的编号对应。
2、可以先把zk文件拷贝到其他节点后,再在各自的节点上手动修改myid编号。
6.将master主机上配置好的zookeeper文件拷贝到slave1,slave2上,并修改各自的myid编号。
1)将master主机上配置好的zookeeper文件拷贝到slave1,slave2上
此时直接拷贝,会提示权限不足问题:
[root@master opt]# scp -r /opt/zookeeper-3.4. spark@slave1:/opt/
spark@slave1's password:
scp: /opt/zookeeper-3.4.12: Permission denied
需要现在slave1,slave2上创建/opt/zookeeper-3.4.12目录,并分配777操作权限。
Last login: Sat Jun :: from 192.168.0.103
[spark@slave1 ~]$ su root
Password:
[root@slave1 spark]# mkdir /opt/zookeeper-3.4.
[root@slave1 spark]# cd /opt/
[root@slave1 opt]# chmod zookeeper-3.4.
拷贝master上的zk到slave1,slave2节点
[spark@master opt]$ scp -r /opt/zookeeper-3.4. spark@slave1:/opt/
[spark@master opt]$ scp -r /opt/zookeeper-3.4. spark@slave2:/opt/
2)并修改各自的myid编号
slave1
[root@slave1 opt]# vi /opt/zookeeper-3.4./data/myid
[root@slave1 opt]# more /opt/zookeeper-3.4./data/myid
2
[root@slave1 opt]#
slave2
[root@slave2 opt]# vi /opt/zookeeper-3.4./data/myid
[root@slave2 opt]# more /opt/zookeeper-3.4./data/myid
3
[root@slave2 opt]#
7. 启动
启动三台主机上的 zookeeper 服务
此时自己启动会抛出异常:
[spark@master opt]$ cd /opt/zookeeper-3.4./bin
[spark@master bin]$ ls
README.txt zkCleanup.sh zkCli.cmd zkCli.sh zkEnv.cmd zkEnv.sh zkServer.cmd zkServer.sh
[spark@master bin]$ ./zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.4./bin/../conf/zoo.cfg
Starting zookeeper ... ./zkServer.sh: line : /opt/zookeeper-3.4./data/zookeeper_server.pid: Permission denied
FAILED TO WRITE PID
原因,是dataDir无权限写入。
解决,分别在三个节点(master,slave1,slave2)上执行chmod分配写入权限
[spark@master bin]$ su root
Password:
[root@master bin]# chmod 777 /opt/zookeeper-3.4./data
[root@master bin]#
然后分别启动三个节点上的zk。
[root@master bin]# su spark
[spark@master bin]$ cd /opt/zookeeper-3.4./bin
[spark@master bin]$ ./zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.4./bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[spark@master bin]$
备注:如果出现使用root账户可以启动zk,但是非root账户不可以启动zk(一般错误原因无权限写入dataDir或者dataLogDir),即使是分配了权限后依然无法操作。那么,可以尝试把data下的dataDir和ldataLogDir目录删除,在dataDir新建myid,写配置编号,后使用非root账户启动。
8. 查看集群状态
jps命令查看各个节点是否启动了QuorumPeerMain进程:
[spark@slave2 bin]$ jps
Jps
QuorumPeerMain
[spark@slave2 bin]$
3个节点启动完成后,可依次执行如下命令查看集群状态:
cd /opt/zookeeper-3.4./bin
./zkServer.sh status
master(192.168.0.120)返回:

slave1(192.168.0.121)返回:

slave2(192.168.0.122)返回:

9. 测试集群高可用性
1)停掉集群中的为 leader 的 zookeeper 服务,本文中的leader为 slave1(192.168.0.121)。
在slave1中执行:
cd /opt/zookeeper-3.4./bin
./zkServer.sh stop
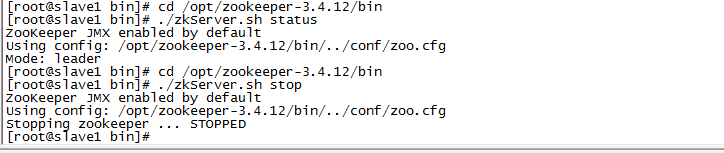
2)查看集群中 master(192.168.0.120)和 slave2(192.168.0.122)的的状态
master(192.168.0.120):

slave2(192.168.0.122)

此时,master(192.168.0.120)成为了集群中的 follower,slave2(192.168.0.122)依然为 leader。
3)启动 slave1(192.168.0.121)的 zookeeper 服务,并查看状态
cd /opt/zookeeper-3.4./bin
./zkServer.sh start
./zkServer.sh status

此时, slave1(192.168.0.121)成为了集群中的 follower。
此时,Zookeeper 集群的安装及高可用性验证已完成!
参考《https://www.cnblogs.com/RUReady/p/6479464.html》
Kafka:ZK+Kafka+Spark Streaming集群环境搭建(八)安装zookeeper-3.4.12的更多相关文章
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十一)NIFI1.7.1安装
一.nifi基本配置 1. 修改各节点主机名,修改/etc/hosts文件内容. 192.168.0.120 master 192.168.0.121 slave1 192.168.0.122 sla ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十三)kafka+spark streaming打包好的程序提交时提示虚拟内存不足(Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical memory used; 2.2 GB of 2.1 G)
异常问题:Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical mem ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十二)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。
Centos7出现异常:Failed to start LSB: Bring up/down networking. 按照<Kafka:ZK+Kafka+Spark Streaming集群环境搭 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十一)定制一个arvo格式文件发送到kafka的topic,通过Structured Streaming读取kafka的数据
将arvo格式数据发送到kafka的topic 第一步:定制avro schema: { "type": "record", "name": ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(九)安装kafka_2.11-1.1.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(三)安装spark2.2.1
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二)安装hadoop2.9.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(七)针对hadoop2.9.0启动DataManager失败问题
DataManager启动失败 启动过程中发现一个问题:slave1,slave2,slave3都是只启动了DataNode,而DataManager并没有启动: [spark@slave1 hado ...
随机推荐
- Calculate CAN bit timing parameters
Calculate CAN bit timing parameters TSYNC_SEG === 1 TSEG1 = Prop_Seg + Phase_Seg1 TSEG2 = Phase_Seg2 ...
- Git 修复 bug 切换分支时,如何保存修改过的代码(即如何保存现场)?
工作除了开发最新的版本之外还要对原来的版本做例行的维护,修修补补.于是有了在两个分支之间游走切换的问题,最新改版的代码在分支 new 上,旧版本的代码在分支 old 上,我在 new 上开发了一半,忽 ...
- mybatis 详解
http://www.cnblogs.com/ysocean/category/1007230.html
- WebService使用实例
近期刚刚開始学习使用WebService的方法进行server端数据交互,发现网上的资料不是非常全, 眼下就结合收集到的一些资料做了一个小样例和大家分享一下~ 我们在PC机器javaclient中.须 ...
- VS2008 LINK : fatal error LNK1104: cannot open file 'atls.lib'错误解决方案
用VS 2008编写ATL的64位应用程序时,提示链接错误:VS2008 LINK : fatal error LNK1104: cannot open file 'atls.lib' 问题原因 VS ...
- TrinityCore 魔兽世界私服11159 完整配置
为什么要研究TrinityCore ? (1)它是一个完整成熟的可运行调试的网游服务器框架. (2)它是一个跨平台的标准C++编写的项目,在Windows.Linux.MacOSX上都可编译运行. ( ...
- MongoDB 安装 Windows XP
〇. 一个提供MonogoDB丰富资料的中文网站 http://www.cnblogs.com/hoojo/archive/2012/02/17/2355384.html 一. http://www ...
- Unity3D实践系列09, 物理引擎与碰撞检测
在Unity3D中,一个物体通常包含一个Collider和一个Rigidbody.Collider是碰撞体,一个物体是Collider,才可以进行碰撞检测.Collider组件中的"Is T ...
- 什么是.Net, IL, CLI, BCL, FCL, CTS, CLS, CLR, JIT
什么是.NET? 起源:比尔盖茨在2000年的Professional Developers Conference介绍了一个崭新的平台叫作Next Generation Windows Service ...
- iOS objc_msgSend 报错解决方案
错误代码: objc_msgSend(self.beginRefreshingTaget, self.beginRefreshingAction, self); Too many arguments ...