Spark SQL 之 Data Sources
Spark SQL 之 Data Sources
转载请注明出处:http://www.cnblogs.com/BYRans/
数据源(Data Source)
Spark SQL的DataFrame接口支持多种数据源的操作。一个DataFrame可以进行RDDs方式的操作,也可以被注册为临时表。把DataFrame注册为临时表之后,就可以对该DataFrame执行SQL查询。Data Sources这部分首先描述了对Spark的数据源执行加载和保存的常用方法,然后对内置数据源进行深入介绍。
一般Load/Save方法
Spark SQL的默认数据源为Parquet格式。数据源为Parquet文件时,Spark SQL可以方便的执行所有的操作。修改配置项spark.sql.sources.default,可修改默认数据源格式。读取Parquet文件示例如下:
- Scala
val df = sqlContext.read.load("examples/src/main/resources/users.parquet")
df.select("name", "favorite_color").write.save("namesAndFavColors.parquet")
- Java
DataFrame df = sqlContext.read().load("examples/src/main/resources/users.parquet");
df.select("name", "favorite_color").write().save("namesAndFavColors.parquet");
手动指定选项(Manually Specifying Options)
当数据源格式不是parquet格式文件时,需要手动指定数据源的格式。数据源格式需要指定全名(例如:org.apache.spark.sql.parquet),如果数据源格式为内置格式,则只需要指定简称(json,parquet,jdbc)。通过指定的数据源格式名,可以对DataFrames进行类型转换操作。示例如下:
- Scala
val df = sqlContext.read.format("json").load("examples/src/main/resources/people.json")
df.select("name", "age").write.format("parquet").save("namesAndAges.parquet")
- Java
DataFrame df = sqlContext.read().format("json").load("examples/src/main/resources/people.json");
df.select("name", "age").write().format("parquet").save("namesAndAges.parquet");
存储模式(Save Modes)
可以采用SaveMode执行存储操作,SaveMode定义了对数据的处理模式。需要注意的是,这些保存模式不使用任何锁定,不是原子操作。此外,当使用Overwrite方式执行时,在输出新数据之前原数据就已经被删除。SaveMode详细介绍如下表:

持久化到表(Saving to Persistent Tables)
当使用HiveContext时,可以通过saveAsTable方法将DataFrames存储到表中。与registerTempTable方法不同的是,saveAsTable将DataFrame中的内容持久化到表中,并在HiveMetastore中存储元数据。存储一个DataFrame,可以使用SQLContext的table方法。table先创建一个表,方法参数为要创建的表的表名,然后将DataFrame持久化到这个表中。
默认的saveAsTable方法将创建一个“managed table”,表示数据的位置可以通过metastore获得。当存储数据的表被删除时,managed table也将自动删除。
Parquet文件
Parquet是一种支持多种数据处理系统的柱状的数据格式,Parquet文件中保留了原始数据的模式。Spark SQL提供了Parquet文件的读写功能。
读取Parquet文件(Loading Data Programmatically)
读取Parquet文件示例如下:
- Scala
// sqlContext from the previous example is used in this example.
// This is used to implicitly convert an RDD to a DataFrame.
import sqlContext.implicits._
val people: RDD[Person] = ... // An RDD of case class objects, from the previous example.
// The RDD is implicitly converted to a DataFrame by implicits, allowing it to be stored using Parquet.
people.write.parquet("people.parquet")
// Read in the parquet file created above. Parquet files are self-describing so the schema is preserved.
// The result of loading a Parquet file is also a DataFrame.
val parquetFile = sqlContext.read.parquet("people.parquet")
//Parquet files can also be registered as tables and then used in SQL statements.
parquetFile.registerTempTable("parquetFile")
val teenagers = sqlContext.sql("SELECT name FROM parquetFile WHERE age >= 13 AND age <= 19")
teenagers.map(t => "Name: " + t(0)).collect().foreach(println)
- Java
// sqlContext from the previous example is used in this example.
DataFrame schemaPeople = ... // The DataFrame from the previous example.
// DataFrames can be saved as Parquet files, maintaining the schema information.
schemaPeople.write().parquet("people.parquet");
// Read in the Parquet file created above. Parquet files are self-describing so the schema is preserved.
// The result of loading a parquet file is also a DataFrame.
DataFrame parquetFile = sqlContext.read().parquet("people.parquet");
// Parquet files can also be registered as tables and then used in SQL statements.
parquetFile.registerTempTable("parquetFile");
DataFrame teenagers = sqlContext.sql("SELECT name FROM parquetFile WHERE age >= 13 AND age <= 19");
List<String> teenagerNames = teenagers.javaRDD().map(new Function<Row, String>() {
public String call(Row row) {
return "Name: " + row.getString(0);
}
}).collect();
解析分区信息(Partition Discovery)
对表进行分区是对数据进行优化的方式之一。在分区的表内,数据通过分区列将数据存储在不同的目录下。Parquet数据源现在能够自动发现并解析分区信息。例如,对人口数据进行分区存储,分区列为gender和country,使用下面的目录结构:
path
└── to
└── table
├── gender=male
│ ├── ...
│ │
│ ├── country=US
│ │ └── data.parquet
│ ├── country=CN
│ │ └── data.parquet
│ └── ...
└── gender=female
├── ...
│
├── country=US
│ └── data.parquet
├── country=CN
│ └── data.parquet
└── ...
通过传递path/to/table给 SQLContext.read.parquet或SQLContext.read.load,Spark SQL将自动解析分区信息。返回的DataFrame的Schema如下:
root
|-- name: string (nullable = true)
|-- age: long (nullable = true)
|-- gender: string (nullable = true)
|-- country: string (nullable = true)
需要注意的是,数据的分区列的数据类型是自动解析的。当前,支持数值类型和字符串类型。自动解析分区类型的参数为:spark.sql.sources.partitionColumnTypeInference.enabled,默认值为true。如果想关闭该功能,直接将该参数设置为disabled。此时,分区列数据格式将被默认设置为string类型,不再进行类型解析。
Schema合并(Schema Merging)
像ProtocolBuffer、Avro和Thrift那样,Parquet也支持Schema evolution(Schema演变)。用户可以先定义一个简单的Schema,然后逐渐的向Schema中增加列描述。通过这种方式,用户可以获取多个有不同Schema但相互兼容的Parquet文件。现在Parquet数据源能自动检测这种情况,并合并这些文件的schemas。
因为Schema合并是一个高消耗的操作,在大多数情况下并不需要,所以Spark SQL从1.5.0开始默认关闭了该功能。可以通过下面两种方式开启该功能:
- 当数据源为Parquet文件时,将数据源选项mergeSchema设置为true
- 设置全局SQL选项spark.sql.parquet.mergeSchema为true
示例如下:
- Scala
// sqlContext from the previous example is used in this example.
// This is used to implicitly convert an RDD to a DataFrame.
import sqlContext.implicits._
// Create a simple DataFrame, stored into a partition directory
val df1 = sc.makeRDD(1 to 5).map(i => (i, i * 2)).toDF("single", "double")
df1.write.parquet("data/test_table/key=1")
// Create another DataFrame in a new partition directory,
// adding a new column and dropping an existing column
val df2 = sc.makeRDD(6 to 10).map(i => (i, i * 3)).toDF("single", "triple")
df2.write.parquet("data/test_table/key=2")
// Read the partitioned table
val df3 = sqlContext.read.option("mergeSchema", "true").parquet("data/test_table")
df3.printSchema()
// The final schema consists of all 3 columns in the Parquet files together
// with the partitioning column appeared in the partition directory paths.
// root
// |-- single: int (nullable = true)
// |-- double: int (nullable = true)
// |-- triple: int (nullable = true)
// |-- key : int (nullable = true)
Hive metastore Parquet表转换(Hive metastore Parquet table conversion)
当向Hive metastore中读写Parquet表时,Spark SQL将使用Spark SQL自带的Parquet SerDe(SerDe:Serialize/Deserilize的简称,目的是用于序列化和反序列化),而不是用Hive的SerDe,Spark SQL自带的SerDe拥有更好的性能。这个优化的配置参数为spark.sql.hive.convertMetastoreParquet,默认值为开启。
Hive/Parquet Schema反射(Hive/Parquet Schema Reconciliation)
从表Schema处理的角度对比Hive和Parquet,有两个区别:
- Hive区分大小写,Parquet不区分大小写
- hive允许所有的列为空,而Parquet不允许所有的列全为空
由于这两个区别,当将Hive metastore Parquet表转换为Spark SQL Parquet表时,需要将Hive metastore schema和Parquet schema进行一致化。一致化规则如下:
- 这两个schema中的同名字段必须具有相同的数据类型。一致化后的字段必须为Parquet的字段类型。这个规则同时也解决了空值的问题。
- 一致化后的schema只包含Hive metastore中出现的字段。
- 忽略只出现在Parquet schema中的字段
- 只在Hive metastore schema中出现的字段设为nullable字段,并加到一致化后的schema中
元数据刷新(Metadata Refreshing)
Spark SQL缓存了Parquet元数据以达到良好的性能。当Hive metastore Parquet表转换为enabled时,表修改后缓存的元数据并不能刷新。所以,当表被Hive或其它工具修改时,则必须手动刷新元数据,以保证元数据的一致性。示例如下:
- Scala
// sqlContext is an existing HiveContext
sqlContext.refreshTable("my_table")
- Java
// sqlContext is an existing HiveContext
sqlContext.refreshTable("my_table")
配置(Configuration)
配置Parquet可以使用SQLContext的setConf方法或使用SQL执行SET key=value命令。详细参数说明如下:
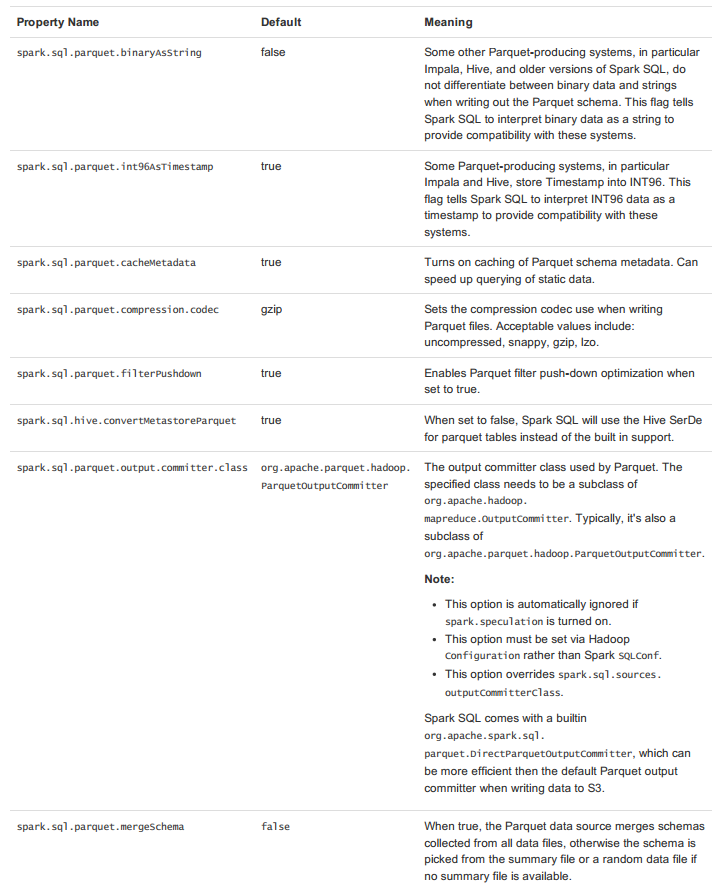
JSON数据集
Spark SQL能自动解析JSON数据集的Schema,读取JSON数据集为DataFrame格式。读取JSON数据集方法为SQLContext.read().json()。该方法将String格式的RDD或JSON文件转换为DataFrame。
需要注意的是,这里的JSON文件不是常规的JSON格式。JSON文件每一行必须包含一个独立的、自满足有效的JSON对象。如果用多行描述一个JSON对象,会导致读取出错。读取JSON数据集示例如下:
- Scala
// sc is an existing SparkContext.
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// A JSON dataset is pointed to by path.
// The path can be either a single text file or a directory storing text files.
val path = "examples/src/main/resources/people.json"
val people = sqlContext.read.json(path)
// The inferred schema can be visualized using the printSchema() method.
people.printSchema()
// root
// |-- age: integer (nullable = true)
// |-- name: string (nullable = true)
// Register this DataFrame as a table.
people.registerTempTable("people")
// SQL statements can be run by using the sql methods provided by sqlContext.
val teenagers = sqlContext.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19")
// Alternatively, a DataFrame can be created for a JSON dataset represented by
// an RDD[String] storing one JSON object per string.
val anotherPeopleRDD = sc.parallelize(
"""{"name":"Yin","address":{"city":"Columbus","state":"Ohio"}}""" :: Nil)
val anotherPeople = sqlContext.read.json(anotherPeopleRDD)
- Java
// sc is an existing JavaSparkContext.
SQLContext sqlContext = new org.apache.spark.sql.SQLContext(sc);
// A JSON dataset is pointed to by path.
// The path can be either a single text file or a directory storing text files.
DataFrame people = sqlContext.read().json("examples/src/main/resources/people.json");
// The inferred schema can be visualized using the printSchema() method.
people.printSchema();
// root
// |-- age: integer (nullable = true)
// |-- name: string (nullable = true)
// Register this DataFrame as a table.
people.registerTempTable("people");
// SQL statements can be run by using the sql methods provided by sqlContext.
DataFrame teenagers = sqlContext.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19");
// Alternatively, a DataFrame can be created for a JSON dataset represented by
// an RDD[String] storing one JSON object per string.
List<String> jsonData = Arrays.asList(
"{\"name\":\"Yin\",\"address\":{\"city\":\"Columbus\",\"state\":\"Ohio\"}}");
JavaRDD<String> anotherPeopleRDD = sc.parallelize(jsonData);
DataFrame anotherPeople = sqlContext.read().json(anotherPeopleRDD);
Hive表
Spark SQL支持对Hive的读写操作。需要注意的是,Hive所依赖的包,没有包含在Spark assembly包中。增加Hive时,需要在Spark的build中添加 -Phive 和 -Phivethriftserver配置。这两个配置将build一个新的assembly包,这个assembly包含了Hive的依赖包。注意,必须上这个心的assembly包到所有的worker节点上。因为worker节点在访问Hive中数据时,会调用Hive的 serialization and deserialization libraries(SerDes),此时将用到Hive的依赖包。
Hive的配置文件为conf/目录下的hive-site.xml文件。在YARN上执行查询命令之前,lib_managed/jars目录下的datanucleus包和conf/目录下的hive-site.xml必须可以被driverhe和所有的executors所访问。确保被访问,最方便的方式就是在spark-submit命令中通过--jars选项和--file选项指定。
操作Hive时,必须创建一个HiveContext对象,HiveContext继承了SQLContext,并增加了对MetaStore和HiveQL的支持。除了sql方法,HiveContext还提供了一个hql方法,hql方法可以执行HiveQL语法的查询语句。示例如下:
- Scala
// sc is an existing SparkContext.
val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
sqlContext.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")
sqlContext.sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src")
// Queries are expressed in HiveQL
sqlContext.sql("FROM src SELECT key, value").collect().foreach(println)
- Java
// sc is an existing JavaSparkContext.
HiveContext sqlContext = new org.apache.spark.sql.hive.HiveContext(sc.sc);
sqlContext.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)");
sqlContext.sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src");
// Queries are expressed in HiveQL.
Row[] results = sqlContext.sql("FROM src SELECT key, value").collect();
访问不同版本的Hive Metastore(Interacting with Different Versions of Hive Metastore)
Spark SQL经常需要访问Hive metastore,Spark SQL可以通过Hive metastore获取Hive表的元数据。从Spark 1.4.0开始,Spark SQL只需简单的配置,就支持各版本Hive metastore的访问。注意,涉及到metastore时Spar SQL忽略了Hive的版本。Spark SQL内部将Hive反编译至Hive 1.2.1版本,Spark SQL的内部操作(serdes, UDFs, UDAFs, etc)都调用Hive 1.2.1版本的class。版本配置项见下面表格:
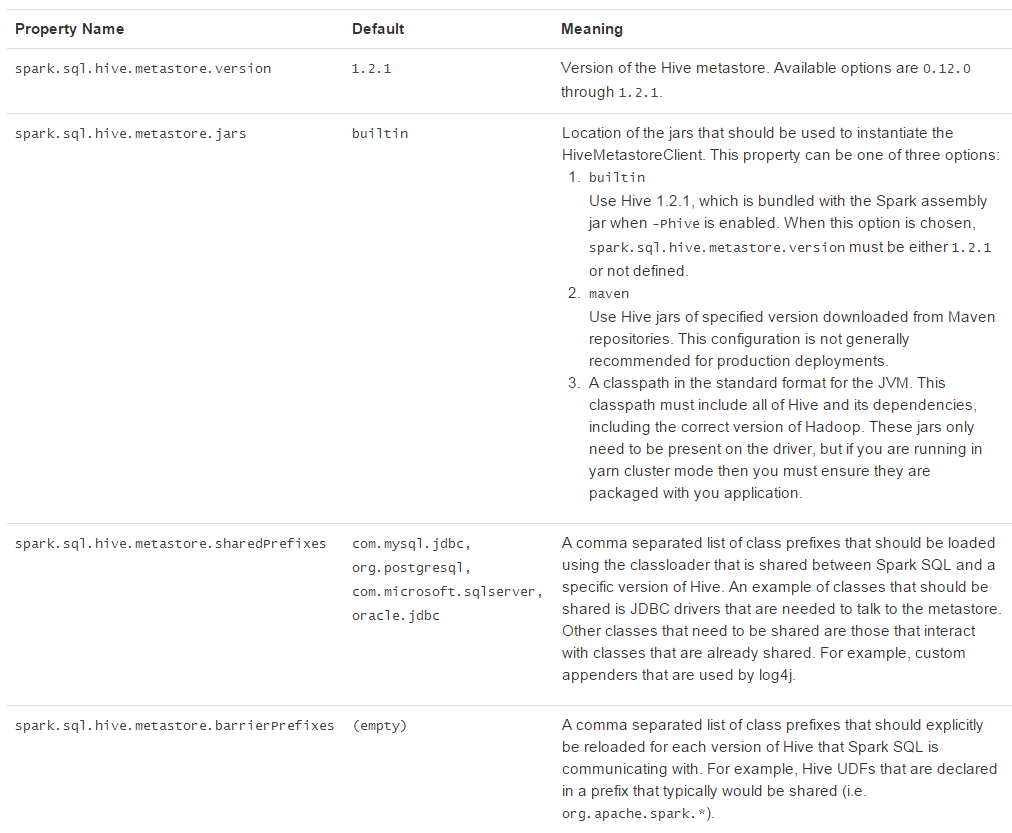
JDBC To Other Databases
Spark SQL支持使用JDBC访问其他数据库。当时用JDBC访问其它数据库时,最好使用JdbcRDD。使用JdbcRDD时,Spark SQL操作返回的DataFrame会很方便,也会很方便的添加其他数据源数据。JDBC数据源因为不需要用户提供ClassTag,所以很适合使用Java或Python进行操作。
使用JDBC访问数据源,需要在spark classpath添加JDBC driver配置。例如,从Spark Shell连接postgres的配置为:
SPARK_CLASSPATH=postgresql-9.3-1102-jdbc41.jar bin/spark-shell
远程数据库的表,可用DataFrame或Spark SQL临时表的方式调用数据源API。支持的参数有:
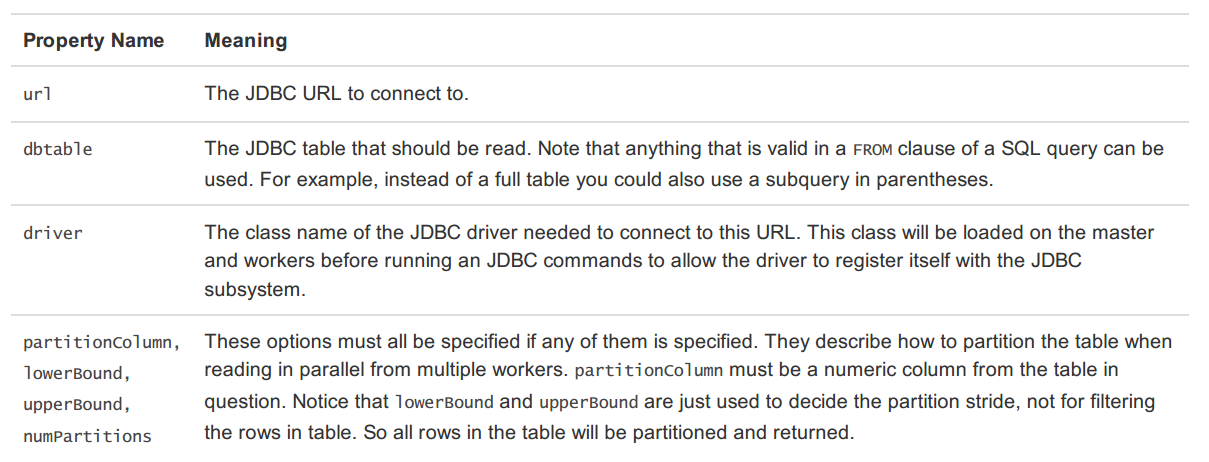
代码示例如下:
- Scala
val jdbcDF = sqlContext.read.format("jdbc").options(
Map("url" -> "jdbc:postgresql:dbserver",
"dbtable" -> "schema.tablename")).load()
- Java
Map<String, String> options = new HashMap<String, String>();
options.put("url", "jdbc:postgresql:dbserver");
options.put("dbtable", "schema.tablename");
DataFrame jdbcDF = sqlContext.read().format("jdbc"). options(options).load();
故障排除(Troubleshooting)
- 在客户端session和所有的executors上,JDBC driver必须对启动类加载器(primordial class loader)设置为visible。因为当创建一个connection时,Java的DriverManager类会执行安全验证,安全验证将忽略所有对启动类加载器为非visible的driver。一个很方便的解决方法是,修改所有worker节点上的compute_classpath.sh脚本,将driver JARs添加至脚本。
- 有些数据库(例:H2)将所有的名字转换为大写,所以在这些数据库中,Spark SQL也需要将名字全部大写。
Spark SQL 之 Data Sources的更多相关文章
- Spark SQL External Data Sources JDBC官方实现写测试
通过Spark SQL External Data Sources JDBC实现将RDD的数据写入到MySQL数据库中. jdbc.scala重要API介绍: /** * Save this RDD ...
- Spark SQL External Data Sources JDBC简易实现
在spark1.2版本中最令我期待的功能是External Data Sources,通过该API可以直接将External Data Sources注册成一个临时表,该表可以和已经存在的表等通过sq ...
- Spark SQL External Data Sources JDBC官方实现读测试
在最新的master分支上官方提供了Spark JDBC外部数据源的实现,先尝为快. 通过spark-shell测试: import org.apache.spark.sql.SQLContext v ...
- spark第七篇:Spark SQL, DataFrame and Dataset Guide
预览 Spark SQL是用来处理结构化数据的Spark模块.有几种与Spark SQL进行交互的方式,包括SQL和Dataset API. 本指南中的所有例子都可以在spark-shell,pysp ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- Spark SQL知识点大全与实战
Spark SQL概述 1.什么是Spark SQL Spark SQL是Spark用于结构化数据(structured data)处理的Spark模块. 与基本的Spark RDD API不同,Sp ...
- Spark SQL知识点与实战
Spark SQL概述 1.什么是Spark SQL Spark SQL是Spark用于结构化数据(structured data)处理的Spark模块. 与基本的Spark RDD API不同,Sp ...
- Spark SQL 操作Hive 数据
Spark 2.0以前版本:val sparkConf = new SparkConf().setAppName("soyo") val spark = new SparkC ...
- 理解Spark SQL(三)—— Spark SQL程序举例
上一篇说到,在Spark 2.x当中,实际上SQLContext和HiveContext是过时的,相反是采用SparkSession对象的sql函数来操作SQL语句的.使用这个函数执行SQL语句前需要 ...
随机推荐
- 【Win 10应用开发】延迟共享
延迟共享是啥呢,这么说吧,就是在应用程序打开共享面板选择共享目标时,不会设置要共享的数据,而是等到共享目标请求数据时,才会发送数据,而且,延迟操作可以在后台进行. 这样说似乎过于抽象,最好的诠释方法, ...
- B树和B+树的区别
如图所示,区别有以下两点: 1. B+树中只有叶子节点会带有指向记录的指针(ROWID),而B树则所有节点都带有,在内部节点出现的索引项不会再出现在叶子节点中. 2. B+树中所有叶子节点都是通过指针 ...
- Linux平台 Oracle 11gR2 RAC安装Part3:DB安装
四.DB(Database)安装 4.1 解压DB的安装包 4.2 DB软件安装 4.3 ASMCA创建磁盘组 4.4 DBCA建库 4.5 验证crsctl的状态 Linux平台 Oracle 11 ...
- Vertica参数的设置
注:只是经验值设定,仅供参考. RHEL 6.2 CPU 24 Memory 128G 8节点 1.keep more event logs for dc_tuple_mover_events. ...
- 微服务和SOA服务
微服务和SOA都被认为是基于服务的架构,这意味着这两种架构模式都非常强调将“服务”作为其架构中的首要组件,用于实现各种功能(包括业务层面和非业务层面).微服务和SOA是两种差异很大的架构模式,但是他们 ...
- jquery对单选和下拉框的操作
jquery 对表单的操作: 对单选框的操作: 一.对单选框的操作: 1.$('input
- spring框架之javaconfig
简介:随着java5的推出,加上当年基于纯java annotation的依赖注入框架Guice的出现,spring推出并持续完善了基于java代码和annotation元信息的依赖关系绑定描述方法, ...
- 物联网框架SuperIO 2.2.9和ServerSuperIO 2.1同时更新,更适用于类似西门子s7-200发送多次数据,才能读取数据的情况
一.解决方案 二.更新内容 1.修改IRunDevice接口,把void Send(io,bytes)改成int Send(io,bytes).2.修改网络控制器,发送数据不直接使用IO实例,改为使用 ...
- Maven远程仓库的配置
在很多情况下,默认的中央仓库无法满足项目的需求,可能项目需要的构件存在于另外一个远程仓库中,如JBoss Maven仓库.这时,可以在POM中配置该仓库,见代码如下: <!-- 远程仓库的配置 ...
- Atitit 游戏的原理与概论attilax总结
Atitit 游戏的原理与概论attilax总结 1. 游戏历史2 1.1.1. 盘点PC游戏史上最重要的50款游戏2 1.1.2. 回味人类文明进程 五款经典的历史游戏2 2. 游戏类型(主要分为6 ...