ElasticSearch集群的安装(windows)
首先尽量保持你的磁盘空间足够大,比如你下载的软件的放在D盘,D盘尽量保持10G以上,还有C盘也差不多10G以上比较保险
一、下载
1)目前我下载的版本是elasticsearch-7.12.0-windows-x86_64,通过搜索引擎找到ElasticSearch的官网下载软件,目前的地址如下:
https://www.elastic.co/cn/downloads/elasticsearch
二、配置
1)解压
2)复制3份解压后的文件,重命名为node-1001,node-1002,node-1003
3)分别配置各自文件下config目录下的配置文件elasticsearch.yml
# 集群名称(所有节点同一个名字)
cluster.name: my-elasticsearch
# 集群节点名称(各自节点各自名字)
node.name: node-3
# 是不是为主节点
node.master: true
# 是否存储数据
node.data: true
# 最大集群节点数,因为3个集群,所以配置3
node.max_local_storage_nodes: 3
# 数据存储路径(配置各自节点目录)
path.data: D:/software/elastic/node-1003/data
# 日志存储路径:(配置各自节点目录)
#
path.logs: D:/software/elastic/node-1003/logs
# 网关地址
network.host: 0.0.0.0
# 端口(配置各自节点端口)
http.port: 9202
# 内部节点之间沟通端口(配置各自节点端口)
transport.tcp.port: 9800
# es7.x之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点,配置的是3个节点的内部节点之间的沟通端口
discovery.seed_hosts: ["127.0.0.1:9600", "127.0.0.1:9700", "127.0.0.1:9800"]
#
# es7.x之后新增的配置,初始化一个新的集群时需要此配置来选举master,配置的是3个节点各自的节点名字
cluster.initial_master_nodes: ["node-1", "node-2", "node-3"]
bootstrap.system_call_filter: false
http.cors.allow-origin: "*"
http.cors.enabled: true
http.cors.allow-headers : X-Requested-With,X-Auth-Token,Content-Type,Content-Length,Authorization
http.cors.allow-credentials: true
节点1配置具体如下:
# 集群名称(所有节点同一个名字)
cluster.name: my-elasticsearch
# 集群节点名称(各自节点各自名字)
node.name: node-1
# 是不是为主节点
node.master: true
# 是否存储数据
node.data: true
# 最大集群节点数,因为3个集群,所以配置3
node.max_local_storage_nodes: 3
# 数据存储路径
path.data: D:/software/elastic/node-1001/data
# 日志存储路径:
#
path.logs: D:/software/elastic/node-1001/logs
# 网关地址
network.host: 0.0.0.0
# 端口
http.port: 9200
# 内部节点之间沟通端口
transport.tcp.port: 9600
# es7.x之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点,配置的是3个节点的内部节点之间的沟通端口
discovery.seed_hosts: ["127.0.0.1:9600", "127.0.0.1:9700", "127.0.0.1:9800"]
#
# es7.x之后新增的配置,初始化一个新的集群时需要此配置来选举master,配置的是3个节点各自的节点名字
cluster.initial_master_nodes: ["node-1", "node-2", "node-3"]
bootstrap.system_call_filter: false
http.cors.allow-origin: "*"
http.cors.enabled: true
http.cors.allow-headers : X-Requested-With,X-Auth-Token,Content-Type,Content-Length,Authorization
http.cors.allow-credentials: true
节点2配置具体如下:
# 集群名称(所有节点同一个名字)
cluster.name: my-elasticsearch
# 集群节点名称(各自节点各自名字)
node.name: node-2
# 是不是为主节点
node.master: true
# 是否存储数据
node.data: true
# 最大集群节点数,因为3个集群,所以配置3
node.max_local_storage_nodes: 3
# 数据存储路径
path.data: D:/software/elastic/node-1002/data
# 日志存储路径:
#
path.logs: D:/software/elastic/node-1002/logs
# 网关地址
network.host: 0.0.0.0
# 端口
http.port: 9201
# 内部节点之间沟通端口
transport.tcp.port: 9700
# es7.x之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点,配置的是3个节点的内部节点之间的沟通端口
discovery.seed_hosts: ["127.0.0.1:9600", "127.0.0.1:9700", "127.0.0.1:9800"]
#
# es7.x之后新增的配置,初始化一个新的集群时需要此配置来选举master,配置的是3个节点各自的节点名字
cluster.initial_master_nodes: ["node-1", "node-2", "node-3"]
bootstrap.system_call_filter: false
http.cors.allow-origin: "*"
http.cors.enabled: true
http.cors.allow-headers : X-Requested-With,X-Auth-Token,Content-Type,Content-Length,Authorization
http.cors.allow-credentials: true
节点3配置如下:
# 集群名称(所有节点同一个名字)
cluster.name: my-elasticsearch
# 集群节点名称(各自节点各自名字)
node.name: node-3
# 是不是为主节点
node.master: true
# 是否存储数据
node.data: true
# 最大集群节点数,因为3个集群,所以配置3
node.max_local_storage_nodes: 3
# 数据存储路径
path.data: D:/software/elastic/node-1003/data
# 日志存储路径:
#
path.logs: D:/software/elastic/node-1003/logs
# 网关地址
network.host: 0.0.0.0
# 端口
http.port: 9202
# 内部节点之间沟通端口
transport.tcp.port: 9800
# es7.x之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点,配置的是3个节点的内部节点之间的沟通端口
discovery.seed_hosts: ["127.0.0.1:9600", "127.0.0.1:9700", "127.0.0.1:9800"]
#
# es7.x之后新增的配置,初始化一个新的集群时需要此配置来选举master,配置的是3个节点各自的节点名字
cluster.initial_master_nodes: ["node-1", "node-2", "node-3"]
bootstrap.system_call_filter: false
http.cors.allow-origin: "*"
http.cors.enabled: true
http.cors.allow-headers : X-Requested-With,X-Auth-Token,Content-Type,Content-Length,Authorization
http.cors.allow-credentials: true
4)清空各自文件夹下的data和logs文件夹内容(后面重启时有必要时也要进行此操作)
5)启动(双击如:node-1001\bin\elasticsearch.bat文件,但这种方式一旦有错误时,命令行会直接关掉,所以还是以命令行的形式打开,如打开cmd文件,进入该文件夹,或在node-1001\bin\目录下的文件路径地址栏输入cmd回车即可打开命令行且切换到该路径下,再输入elasticsearch.bat)
6)全部启动后,访问http://localhost:9200/、http://localhost:9201/、http://localhost:9202/地址,结果如下

三、可视化客户端工具的安装(cerebro)
下载地址https://github.com/lmenezes/cerebro/releases
解压打开文件夹里面的bin目录,和ElasticSearch启动一样,可以直接双击,也可以命令行形式启动,默认地址端口是9000,
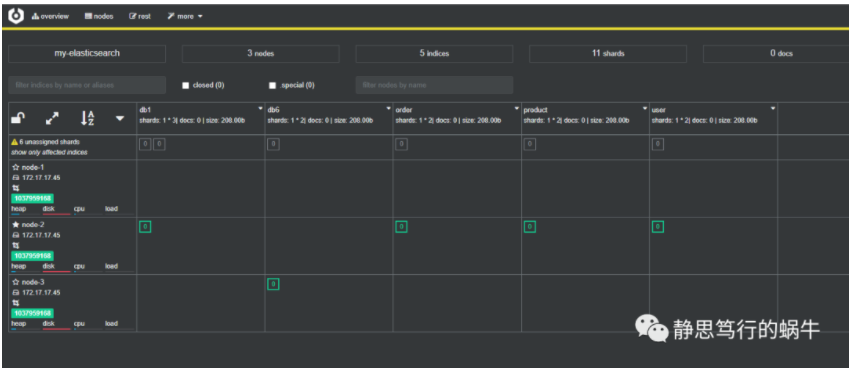
如果端口被占用我们可以指定一个端口,先cmd命令行进入该文件夹的bin目录下,输入命令,如cerebro -Dhttp.port=9999,就可以指定9999端口启动cerebro了,访问地址是http://localhost:9999/,输入ElasticSearch地址,如上面的http://localhost:9200/,就可以连接到ElasticSearch,可视化界面如下:
谢谢关注公众号:

ElasticSearch集群的安装(windows)的更多相关文章
- ElasticSearch实战系列一: ElasticSearch集群+Kinaba安装教程
前言 本文主要介绍的是ElasticSearch集群和kinaba的安装教程. ElasticSearch介绍 ElasticSearch是一个基于Lucene的搜索服务器,其实就是对Lucene进行 ...
- elasticsearch 集群的安装部署
一 介绍 elasticsearch 是居于lucene的搜素引擎,可以横向集群扩展以及分片,开发者无需关注如何实现了索引的备份,集群同步,分片等,我们很容易通过简单的配置就可以启动elasticse ...
- ElasticSearch和Kibana 5.X集群的安装
ElasticSearch和Kibana 5.X集群的安装 1.准备工作 1.1.下载安装包 1.2.系统的准备 2.ElasticSearch集群的安装 2.1.修改 config/elastics ...
- k8s上安装elasticsearch集群
官方文档地址:https://www.elastic.co/guide/en/cloud-on-k8s/current/k8s-quickstart.html yaml文件地址:https://dow ...
- Azure vm 扩展脚本自动部署Elasticsearch集群
一.完整过程比较长,我仅给出Azure vm extension script 一键部署Elasticsearch集群的安装脚本,有需要的同学,可以邮件我,我给你完整的ARM Template 如果你 ...
- Elasticsearch集群搭建及使用Java客户端对数据存储和查询
本次博文发两块,前部分是怎样搭建一个Elastic集群,后半部分是基于Java对数据进行写入和聚合统计. 一.Elastic集群搭建 1. 环境准备. 该集群环境基于VMware虚拟机.CentOS ...
- CentOS 7下ElasticSearch集群搭建案例
最近在网上看到很多ElasticSearch集群的搭建方法,本人在这人使用Elasticsearch5.0.1版本,介绍如何搭建ElasticSearch集群并安装head插件和其他插件安装方法. 一 ...
- CentOS下 elasticsearch集群安装
1.进入root目录并下载elasticsearch cd /root wget https://download.elastic.co/elasticsearch/elasticsearch/ela ...
- ElasticSearch 集群环境搭建,安装ElasticSearch-head插件,安装错误解决
ElasticSearch-5.3.1集群环境搭建,安装ElasticSearch-head插件,安装错误解决 说起来甚是惭愧,博主在写这篇文章的时候,还没有系统性的学习一下ES,只知道可以拿来做全文 ...
随机推荐
- js hook
//cookie hook (function () { 'use strict'; var cookie_cache = document.cookie; Object.defineProperty ...
- 聊聊TCP Keepalive、Netty和Docker
聊聊TCP Keepalive.Netty和Docker 本文主要阐述TCP Keepalive和对应的内核参数,及其在Netty,Docker中的实现.简单总结了工作中遇到的问题,与大家共勉. 起因 ...
- 剑指 Offer 40. 最小的k个数
剑指 Offer 40. 最小的k个数 输入整数数组 arr ,找出其中最小的 k 个数.例如,输入4.5.1.6.2.7.3.8这8个数字,则最小的4个数字是1.2.3.4. 示例 1: 输入:ar ...
- swift文件调用oc分类时崩溃解决办法(可能全网唯一)
背景 oc为基础创建的sdk混编工程,在被sdk关联的混编demo工程中swift文件调用时,会崩溃,提示找不到sdk中oc分类方法.常规的,在demo中设置-Objc和-all_load也还是会崩. ...
- Bugku-login1(SKCTF)(SQL约束攻击)
原因 sql语句中insert和select对长度和空格的处理方式差异造成漏洞. select对参数后面的空格的处理方式是删除,insert只是取规定的最大长度的字符串. 逻辑 1.用 select ...
- 五、从GitHub浏览Prism示例代码的方式入门WPF下的Prism之MVVM中的EventAggregator
这一篇我们主要再看完示例12.13后,写了个例子,用于再Modules下执行ApplicationCommands,使用IActiveAware执行当前View的Commands,或者Applicat ...
- IP地址,InetAddress类的使用
IP地址 IP地址:InetAddress(没有构造器,通过静态方法返回) java.net包下 唯一定位一台网络上的计算机 127.0.0.1:本机localhost ip地址的分类 IPV4/IP ...
- 软件或jar包版本的小知识---Beta版、Final版、Free版等
对于各种软件或jar包,其后面总有不同的"尾巴",如: 等,刚开始接触的肯定有些不知道.那么他们到底代表什么意思呢? 0.Release:发布版 1.Beta版:产品发布之前的测试 ...
- Notes about "Exploring Expect"
Chapter 3 Section "The expect Command": expect_out(0,string) can NOT be written as "e ...
- Greenplum 6安装指南(CentOS 7.X)
一.基本概念 Greenplum是一个面向数据仓库应用的关系型数据库,因为有良好的体系结构,所以 在数据存储.高并发.高可用.线性扩展.反应速度.易用性和性价比等方面有非常 明显的优势.Greenpl ...