JAVA 进行图片中文字识别(准确度高)!!!
OCR 识别文字项目
该项目 可以进行两种方式进行身份证识别
1. 使用百度接口
1.1 application-dev.yml配置
ocr:
# 使用baiduOcr 需要有Ocr服务器 使用百度需要相应的百度账号即可
useOcrType: baiduOcr
# 需要OCR 的文件夹
ocrFolderPath: E:\ocr-wait-image\16210910333-8e2fa7f52db04a538ed584c919ce33b1
# 需要OCR 的文件
ocrFile: H:\Desktop\test\14.jpg
# 百度OCR 配置 https://cloud.baidu.com/doc/OCR/s/Nkibizxlf
baiduOcr:
# 使用token 形式
useToken: false
# 使用卡证识别接口 卡证识别一天500次免费(识别率高推荐) 通用识别50000次免费(识别率较低)
useIdCard: true
# 使用token 形式调用接口 token 通过接口获取(推荐使用sdk模式)
token: XXXXXXXX
idCardUrl: https://aip.baidubce.com/rest/2.0/ocr/v1/idcard
idCardPrefix: id_card_side=front&image=
generalBasicUrl: https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic
generalBasicPrefix: image=
# 不使用token sak形式调用接口(通过百度账号创建应用获取)
appId: XXXXXXXXXX
apiKey: XXXXXXXXXX
secretKey: XXXXXXXXXX
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
1.2 创建百度应用
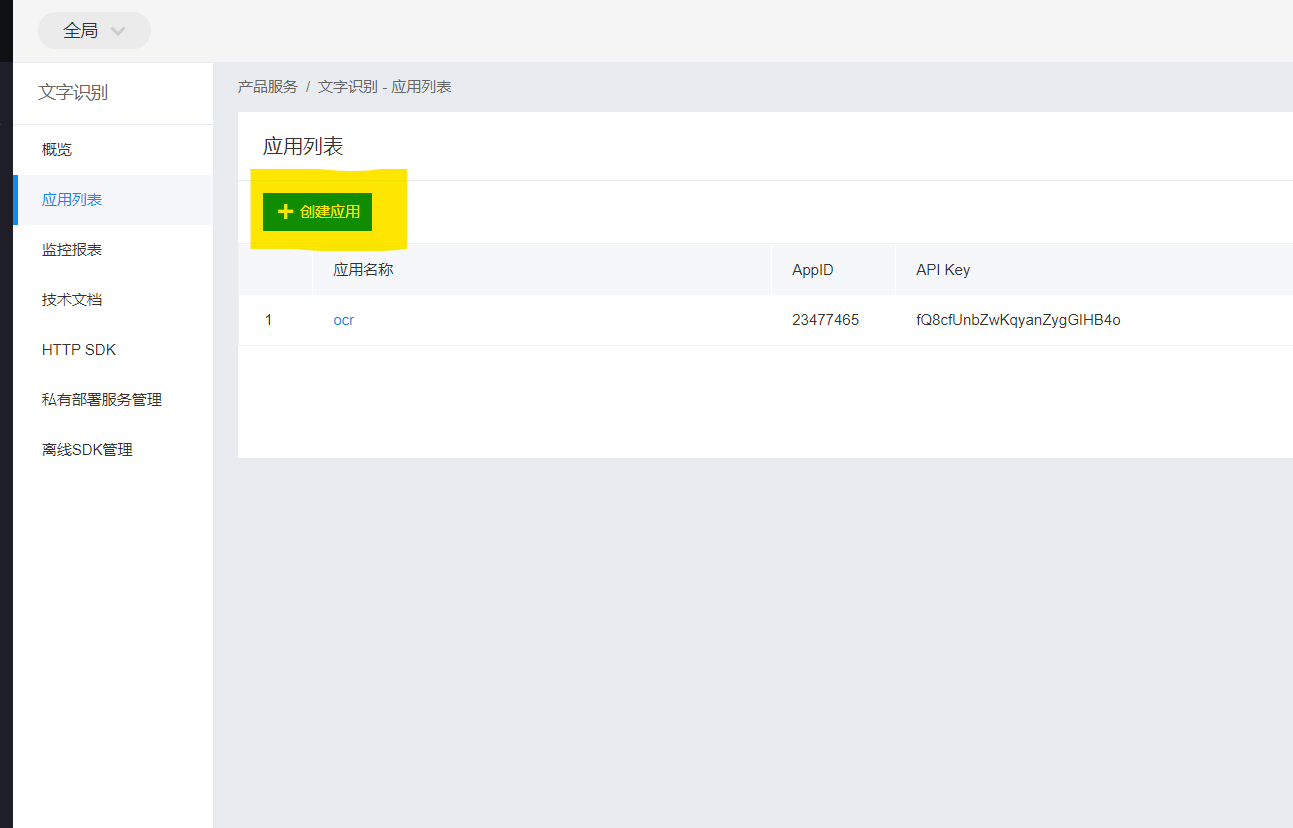
填入必填项即可
再次出来即有一个创建的应用
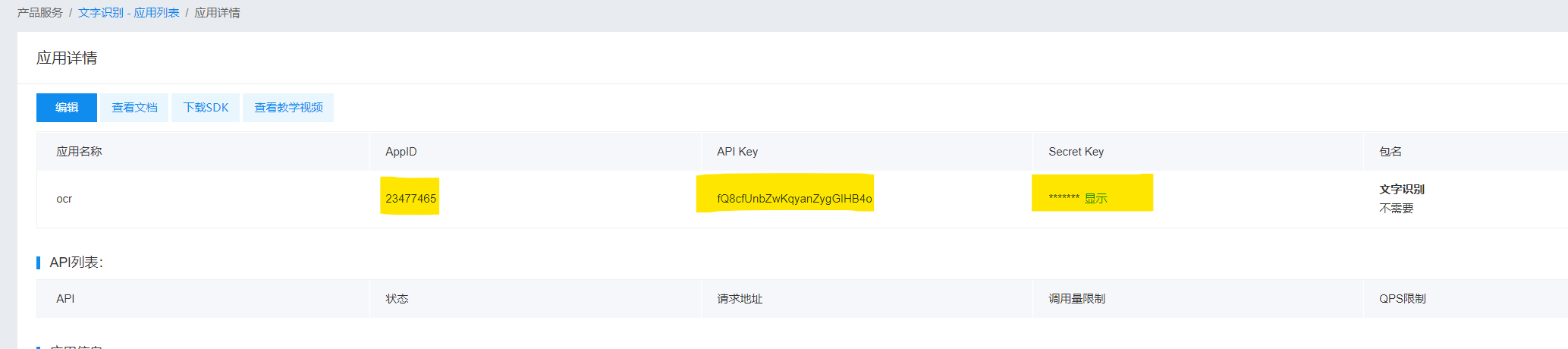
以上配置的appId,apiKey,secretKey 三项在这里获取
1.3 结果显示
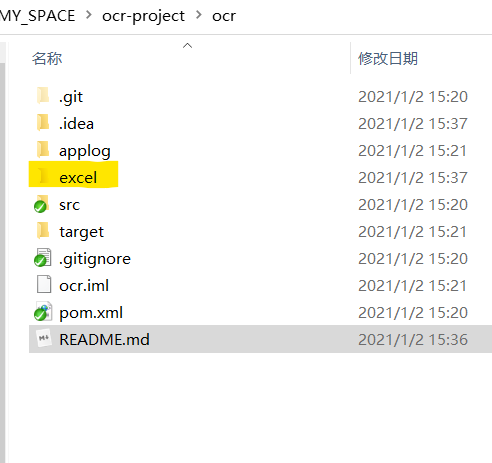
获得结果会保存在这个文件夹

1.3 使用百度免费OCR 项目配置结束
1.4 主要代码展示
package com.ocr.baidu;
import com.baidu.aip.ocr.AipOcr;
import com.framework.config.OcrConfig;
import com.utils.Base64Util;
import com.utils.FileUtil;
import com.utils.HttpUtil;
import lombok.extern.slf4j.Slf4j;
import org.json.JSONObject;
import java.net.URLEncoder;
import java.nio.charset.StandardCharsets;
import java.util.HashMap;
@Slf4j
public class BaiduOCRUtils {
/**
* 卡证识别
*/
public static String idCardByToken(OcrConfig.BaiduOcr baiduOcr,String filePath) {
String idCardPrefix = baiduOcr.getIdCardPrefix();
String idCardUrl = baiduOcr.getIdCardUrl();
String token = baiduOcr.getToken();
// 请求url
try {
// 本地文件路径
byte[] imgData = FileUtil.readFileByBytes(filePath);
String imgStr = Base64Util.encode(imgData);
String imgParam = URLEncoder.encode(imgStr, StandardCharsets.UTF_8.name());
String param = idCardPrefix + imgParam;
// 注意这里仅为了简化编码每一次请求都去获取access_token,线上环境access_token有过期时间, 客户端可自行缓存,过期后重新获取。
return HttpUtil.post(idCardUrl, token, param);
} catch (Exception e) {
log.error(e.getMessage());
e.printStackTrace();
}
return null;
}
/**
* 通用文字识别
*/
public static String generalBasicByToken(OcrConfig.BaiduOcr baiduOcr,String filePath) {
String generalBasicPrefix = baiduOcr.getGeneralBasicPrefix();
String generalBasicUrl = baiduOcr.getGeneralBasicUrl();
String token = baiduOcr.getToken();
// 请求url
try {
// 本地文件路径
byte[] imgData = FileUtil.readFileByBytes(filePath);
String imgStr = Base64Util.encode(imgData);
String imgParam = URLEncoder.encode(imgStr, StandardCharsets.UTF_8.name());
String param = generalBasicPrefix + imgParam;
// 注意这里仅为了简化编码每一次请求都去获取access_token,线上环境access_token有过期时间, 客户端可自行缓存,过期后重新获取。
return HttpUtil.post(generalBasicUrl, token, param);
} catch (Exception e) {
log.error(e.getMessage());
e.printStackTrace();
}
return null;
}
/**
* 通用文字识别 sdk
*/
public static JSONObject generalBasicBySdk(OcrConfig.BaiduOcr baiduOcr,String filePath) {
String appId = baiduOcr.getAppId();
String apiKey = baiduOcr.getApiKey();
String secredKey = baiduOcr.getSecretKey();
AipOcr client = new AipOcr(appId, apiKey, secredKey);
// 可选:设置网络连接参数
client.setConnectionTimeoutInMillis(2000);
client.setSocketTimeoutInMillis(60000);
return client.basicGeneral(filePath, new HashMap<>());
}
/**
* 身份证文字识别 sdk
*/
public static JSONObject idCardBySdk(OcrConfig.BaiduOcr baiduOcr,String filePath) {
String appId = baiduOcr.getAppId();
String apiKey = baiduOcr.getApiKey();
String secredKey = baiduOcr.getSecretKey();
AipOcr client = new AipOcr(appId, apiKey, secredKey);
// 可选:设置网络连接参数
client.setConnectionTimeoutInMillis(2000);
client.setSocketTimeoutInMillis(60000);
return client.idcard(filePath,"front", new HashMap<>());
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
2. 使用百度开源项目PaddleHub
PS: 识别通过paddle(python 运行) ,JAVA 进行结果处理
2.1 按照教程安装PaddleHub
2.2 application-dev.yml配置
ocr:
paddleOcr:
# 使用本地
url: 192.168.0.106
port: 8866
moduleMap:
# 文字识别OCR 安装 https://www.paddlepaddle.org.cn/hubdetail?name=chinese_ocr_db_crnn_mobile&en_category=TextRecognition
chinese_ocr_db_crnn_mobile: 1.1.1
# 人脸识别OCR(识别身份证正面或手持身份证) 安装 https://www.paddlepaddle.org.cn/hubdetail?name=pyramidbox_lite_server&en_category=FaceDetection
pyramidbox_lite_server: 1.2.0
# 是否分析
analysis: false
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2.3 结果显示
获得结果会保存在这个文件夹

2.4 主要代码展示
package com.ocr.paddle;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.google.common.collect.Lists;
import com.ocr.paddle.domain.LocalHubOcrResultDTO;
import com.ocr.paddle.domain.OCRHubResultDTO;
import com.utils.Base64Util;
import com.utils.FileUtil;
import com.utils.HttpClientUtils;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import java.io.File;
import java.io.IOException;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
@Slf4j
public class LocalHubOcrUtils {
public static List<LocalHubOcrResultDTO> localAllOcr(String textUrl, String faceUrl, List<File> allFiles) {
long l = System.currentTimeMillis();
List<LocalHubOcrResultDTO> localOcrResultDTOList = Lists.newArrayList();
int urlCount = 0;
boolean useTextUrl = false;
boolean useFaceUrl = false;
if (StringUtils.isEmpty(textUrl)) {
log.info("不进行文字识别");
} else {
urlCount++;
useTextUrl = true;
log.info("需要进行文字识别");
}
if (StringUtils.isEmpty(faceUrl)) {
log.info("不进行人脸识别");
} else {
urlCount++;
useFaceUrl = true;
log.info("需要进行人脸识别");
}
int ocrCount = allFiles.size() * urlCount;
log.info("预估进行OCR" + ocrCount + "次");
if (ocrCount == 0) {
return localOcrResultDTOList;
}
int textIndex = 0;
int faceIndex = 0;
// 本地文件路径
Map<String, String> partentFile = allFiles.stream().collect(Collectors.toMap(File::getName, File::getParent, (e1, e2) -> e1));
for (File imageFile : allFiles) {
List<OCRHubResultDTO> ocrHubResultDTOS = Lists.newArrayList();
byte[] imgData = new byte[0];
try {
imgData = FileUtil.readFileByBytes(imageFile);
} catch (IOException e) {
log.error("图片读取错误");
continue;
}
String imgStr = Base64Util.encode(imgData);
JSONObject jsonObject = new JSONObject();
List<String> imageParams = Lists.newArrayList();
imageParams.add(imgStr);
jsonObject.put("images", imageParams);
String textResult = "";
if (useTextUrl) {
textResult = HttpClientUtils.sendJsonStr(textUrl, jsonObject.toJSONString());
textIndex++;
log.info("已进行文字OCR" + textIndex + "次");
if (StringUtils.isEmpty(textResult)) {
log.error("获取文字接口失败");
log.info("还需进行" + (ocrCount - faceIndex - textIndex) + "次");
continue;
}
JSONObject resultTest = (JSONObject) JSONObject.parse(textResult);
JSONArray textResultsArray = resultTest.getJSONArray("results");
if (textResultsArray == null){
log.error("返回值错误,错误信息为:" + textResult);
}
for (Object o : textResultsArray) {
JSONObject j = (JSONObject) o;
JSONArray data = j.getJSONArray("data");
for (Object datum : data) {
JSONObject jo = (JSONObject) datum;
jo.remove("text_box_position");
OCRHubResultDTO ocrHubResultDTO = jo.toJavaObject(OCRHubResultDTO.class);
ocrHubResultDTOS.add(ocrHubResultDTO);
}
}
}
int faceCount = 0;
String faceResult = "";
if (useFaceUrl) {
faceResult = HttpClientUtils.sendJsonStr(faceUrl, jsonObject.toJSONString());
faceIndex++;
log.info("已进行人脸OCR" + faceIndex + "次");
if (StringUtils.isEmpty(faceResult)) {
log.error("获取人脸识别接口失败");
log.info("还需进行" + (ocrCount - faceIndex - textIndex) + "次");
continue;
}
JSONObject resultFace = (JSONObject) JSONObject.parse(faceResult);
JSONArray faceResultsArray = resultFace.getJSONArray("results");
for (Object o : faceResultsArray) {
JSONObject j = (JSONObject) o;
JSONArray data = j.getJSONArray("data");
faceCount = data.size();
}
}
log.info("还需进行" + (ocrCount - faceIndex - textIndex) + "次");
localOcrResultDTOList.add(new LocalHubOcrResultDTO(imageFile.getAbsolutePath(), imageFile.getParent(), ocrHubResultDTOS, faceCount));
}
log.info("OCR 总耗时" + (System.currentTimeMillis() - l) / 1000 + "S");
log.info("OCR 次数" + ocrCount + "次");
log.info("OCR 平均耗时" + (System.currentTimeMillis() - l) / 1000 / ocrCount + "s");
return localOcrResultDTOList;
}
private static void func(File file, List<File> fileList) {
File[] fs = file.listFiles();
for (File f : fs) {
if (f.isDirectory()) {
//若是目录,则递归打印该目录下的文件
func(f, fileList);
}
if (f.isFile()) {
String imageName = f.getName();
boolean isJpg = imageName.endsWith(".jpg");
boolean isJPG = imageName.endsWith(".JPG");
boolean isPng = imageName.endsWith(".png");
if (isJPG || isPng || isJpg) {
//若是图片加入列表
fileList.add(f);
}
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
sJpg = imageName.endsWith(".jpg");
boolean isJPG = imageName.endsWith(".JPG");
boolean isPng = imageName.endsWith(".png");
if (isJPG || isPng || isJpg) {
//若是图片加入列表
fileList.add(f);
}
}
}
}
}
原文章:https://blog.csdn.net/AirOrange_qi/article/details/112102739
JAVA 进行图片中文字识别(准确度高)!!!的更多相关文章
- JAVA的图片文字识别技术
从2013年的记录看,JAVA中图片文字识别技术大部分采用ORC的tesseract的软件功能,后来渐渐开放了java-api调用接口. 图片文字识别技术,还是采用训练的方法.并未从根本上解决图片与文 ...
- java实现图片文字识别的两种方法
一.使用tesseract-ocr 1. https://github.com/tesseract-ocr/tesseract/wiki上下载安装包安装和简体中文训练文件 window64位安装 ...
- 识别率很高的java文字识别技术
java文字识别程序的关键是寻找一个可以调用的OCR引擎.tesseract-ocr就是一个这样的OCR引擎,在1985年到1995年由HP实验室开发,现在在Google.tesseract-ocr ...
- 【图片识别】java 图片文字识别 ocr (转)
http://www.cnblogs.com/inkflower/p/6642264.html 最近在开发的时候需要识别图片中的一些文字,网上找了相关资料之后,发现google有一个离线的工具,以下为 ...
- java 图片文字识别 ocr
最近在开发的时候需要识别图片中的一些文字,网上找了相关资料之后,发现google有一个离线的工具,以下为java使用的demo 在此之前,使用这个工具需要在本地安装OCR工具: 下面一个是一定要安装的 ...
- Java文字识别软件-调用百度ocr实现文字识别
java_baidu_ocr Java调用百度OCR文字识别API实现图片文字识别软件 这是一款小巧方便,强大的文字识别软件,由Java编写,配上了窗口界面 调用了百度ocr文字识别API 识别精度高 ...
- 识别图片中文字(百度AI)
这个是百度官方的文档 https://ai.baidu.com/docs#/OCR-API/top 通用的文字识别,如果是其他的含生僻字/含位置信息的版本,请参考官方的文档,只 ...
- Android OCR文字识别 实时扫描手机号(极速扫描单行文本方案)
身份证识别:https://github.com/wenchaosong/OCR_identify 遇到一个需求,要用手机扫描纸质面单,获取面单上的手机号,最后决定用tesseract这个开源OCR库 ...
- 借@阿里巴巴 耍了个帅——HTML5 JavaScript实现图片文字识别与提取
写在前面 8月底的时候,@阿里巴巴 推出了一款名为“拯救斯诺克”的闯关游戏,作为前端校园招聘的热身,做的相当不错,让我非常喜欢.后来又传出了一条消息,阿里推出了A-star(阿里星)计划,入职阿里的技 ...
随机推荐
- LAMP环境搭建一个Discuz论坛
LAMP是Linux+Apache+Mysql/MariaDB+Perl/PHP/Python的简称.一组常用来搭建动态网站或者服务器的开源软件,本身都是各自独立的程序,但是因为常被放在一起使用,拥有 ...
- PowerShell-4.API调用以及DLL调用
PowerShell可以直接调用API,So...这东西完全和cmd不是一回事了... 调用API的时候几乎和C#一样(注意堆栈平衡): 调用MessageBox: $iii = Add-Type - ...
- 【python】Leetcode每日一题-森林中的兔子
[python]Leetcode每日一题-森林中的兔子 [题目描述] 森林中,每个兔子都有颜色.其中一些兔子(可能是全部)告诉你还有多少其他的兔子和自己有相同的颜色.我们将这些回答放在 answers ...
- 在 Linux 如何优雅的统计程序运行时间?恕我直言,你运行的可能是假 time
最近在使用 time 命令时,无意间发现了一些隐藏的小秘密和强大功能,今天分享给大家. time 在 Linux 下是比较常用的命令,可以帮助我们方便的计算程序的运行时间,对比采用不同方案时程序的运行 ...
- left join 后用 on 还是 where,区别大了!
前天写SQL时本想通过 A left B join on and 后面的条件来使查出的两条记录变成一条,奈何发现还是有两条. 后来发现 join on and 不会过滤结果记录条数,只会根据and后的 ...
- Windows进程间通讯(IPC)----内存映射文件
内存映射文件原理 内存映射文件是通过在虚拟地址空间中预留一块区域,然后通过从磁盘中已存在的文件为其调度物理存储器,访问此虚拟内存空间就相当于访问此磁盘文件了. 内存映射文件实现过程 HANDLE hF ...
- 一看就懂的MySQL的聚簇索引,以及聚簇索引是如何长高的
这一篇笔记我们简述一下 MySQL的B+Tree索引到底是咋回事? 聚簇索引索引到底是如何长高的. 一点一点看,其实蛮好理解的. 如果你看过了我之前的笔记,你肯定知道了MySQL进行CRUD是在内存中 ...
- [c++] 如何流畅地读写代码
代码不同于普通文字,阅读时注意两方面: 符号含义:相同符号,上下文不同时含义也不同,如*和& 阅读顺序:不总是按从左往右顺序阅读的,有时要倒着读或者跳着读逻辑才通顺 适当省略:有些内容虽然写了 ...
- [刷题] 77 Combinations
要求 给出两个整数n和k,在n个数字中选出k个数字的所有组合 示例 n=4 , k=2 [ [ 1, 2 ] , [ 1, 3 ] , [ 1, 4 ] , [ 2, 3 ] , [ 2, 4 ] , ...
- tail -n 13 history |awk '{print $2,$3,$4,$5,$6,$7,$8.$9,$10}'提取第2到第11列
# cat history |awk '{print $2,$3,$4,$5,$6,$7,$8.$9,$10}' # tail -n 13 history 215 systemctl stop 216 ...