(一)FastDFS 高可用集群架构学习---简介
1、什么是FastDFS
FastDFS 是余庆老师用c语言编写的一筐开源的分布式文件系统,充分考虑了冗余备份,负载均衡,线性扩容等机制,并注重高可用、高性能等指标,使用FastDFS可以很容易搭建一套高性能的文件服务器集群提供文件上传下载.
FastDFS 实现了软件方式的RAID,可以使用廉价的IDE硬盘进行存储支持存储服务器在线扩容支持相同内容的文件只保存一份,节约磁盘空间;
FastDFS 只能通过Client API访问,不支持POSIX访问方式;
FastDFS 特别适合大中型网站使用,用来存储资源文件(如:图片、文档、音频、视频等等)。
2、FastDFS 的框架结构
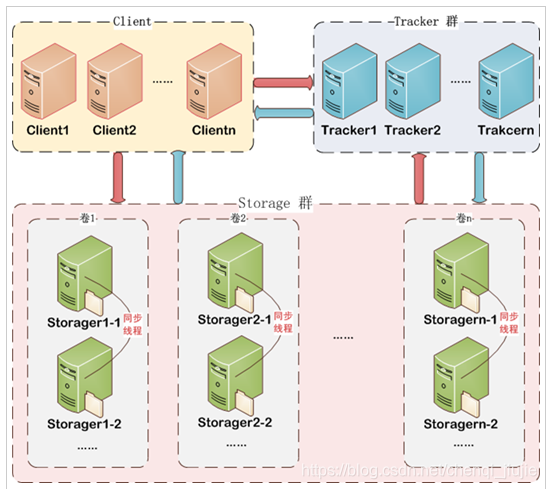
FastDFS 系统有三个角色:跟踪服务器(Tracker Server)、存储服务器(Storage Server)和客户端(Client)。
Tracker Server: 跟踪服务器,主要做调度工作,起到均衡的作用;负责管理所有的storage server和group,每个storage在启动后会连接 Tracker,告知自己所属 group 等信息,并保持周期性心跳。多个Tracker之间是对等关系,不存在单点故障。
Storage Server: 存储服务器,主要提供容量和备份服务;以 group 为单位,每个 group 内可以有多台 storage server,组内的所有Storage Server之间是平等关系,会相互连接 进行文件同步,从而保证组内的所有Storage Server的文件内容一致,所以建议group内的多个storage尽量配置相同,以免造成存储空间的浪费,不同组之间的Storage Server之间不会相互通信。
group内每个storage的存储依赖于本地文件系统,storage可配置多个数据存储目录,比如有10块磁盘,分别挂载在/data/disk1-/data/disk10,则可将这10个目录都配置为storage的数据存储目录。
storage接受到写文件请求时,会根据配置好的规则(后面会介绍),选择其中一个存储目录来存储文件。为了避免单个目录下的文件数太多,在storage第一次启动时,会在每个数据存储目录里创建2级子目录,每级256个,总共65536个文件,新写的文件会以hash的方式被路由到其中某个子目录下,然后将文件数据直接作为一个本地文件存储到该目录中。
采用分组存储的方式的好处是实现了冗余备份,负载均衡,线性扩容的机制,当一个组的服务器的访问的压力比较大 的时候可以在各组之内增加存储服务器来扩充服务能力(纵向扩容),当系统的容量不足时,可以增加组来扩充容量(横向扩容)
Client:客户端请求Tracker Server进行文件的上传下载,通过Tracker Server调度最终由Storage Server完成文件的上传和下载。FastDFS向使用者提供基本文件访问接口,比如upload、download、append、delete等,以客户端库的方式提供给用户使用。
模块之间的主要关系如下:
3、FastDFS 的工作流程
a、上传文件
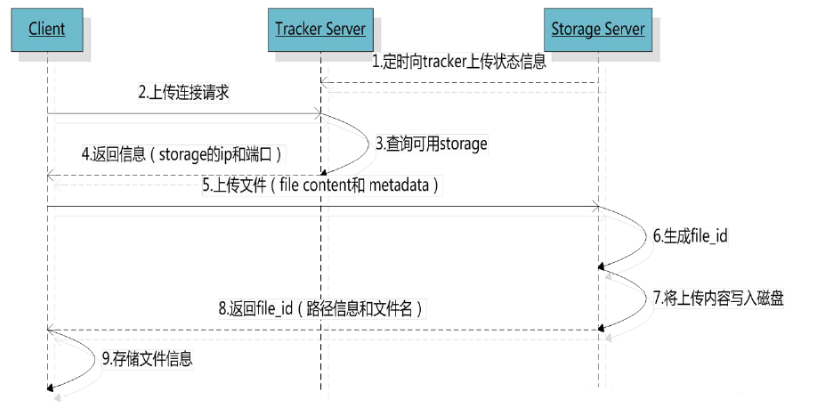
选择tracker server
当集群中不止一个tracker server时,由于tracker之间是完全对等的关系,客户端在upload文件时可以任意选择一个trakcer。
选择存储的group
当tracker接收到upload file的请求时,会为该文件分配一个可以存储该文件的group,支持如下选择group的规则: 1. Round robin,所有的group间轮询 2. Specified group,指定某一个确定的group 3. Load balance,剩余存储空间多多group优先
选择storage server
当选定group后,tracker会在group内选择一个storage server给客户端,支持如下选择storage的规则: 1. Round robin,在group内的所有storage间轮询 2. First server ordered by ip,按ip排序 3. First server ordered by priority,按优先级排序(优先级在storage上配置)
选择storage path
当分配好storage server后,客户端将向storage发送写文件请求,storage将会为文件分配一个数据存储目录,支持如下规则: 1. Round robin,多个存储目录间轮询 2. 剩余存储空间最多的优先
生成Fileid
选定存储目录之后,storage会为文件生一个Fileid,由storage server ip、文件创建时间、文件大小、文件crc32和一个随机数拼接而成,然后将这个二进制串进行base64编码,转换为可打印的字符串。
选择两级目录
当选定存储目录之后,storage会为文件分配一个fileid,每个存储目录下有两级256*256的子目录,storage会按文件fileid进行两次hash(猜测),路由到其中一个子目录,然后将文件以fileid为文件名存储到该子目录下。
生成文件名
当文件存储到某个子目录后,即认为该文件存储成功,接下来会为该文件生成一个文件名,文件名由group、存储目录、两级子目录、fileid、文件后缀名(由客户端指定,主要用于区分文件类型)拼接而成。

文件同步
写文件时,客户端将文件写至group内一个storage server即认为写文件成功,storage server写完文件后,会由后台线程将文件同步至同group内其他的storage server。
每个storage写文件后,同时会写一份binlog,binlog里不包含文件数据,只包含文件名等元信息,这份binlog用于后台同步,storage会记录向group内其他storage同步的进度,以便重启后能接上次的进度继续同步;进度以时间戳的方式进行记录,所以最好能保证集群内所有server的时钟保持同步。
storage的同步进度会作为元数据的一部分汇报到tracker上,tracke在选择读storage的时候会以同步进度作为参考。
比如一个group内有A、B、C三个storage server,A向C同步到进度为T1 (T1以前写的文件都已经同步到B上了),B向C同步到时间戳为T2(T2 > T1),tracker接收到这些同步进度信息时,就会进行整理,将最小的那个做为C的同步时间戳,本例中T1即为C的同步时间戳为T1(即所有T1以前写的数据都已经同步到C上了);同理,根据上述规则,tracker会为A、B生成一个同步时间戳。
b、下载文件
客户端upload file成功后,会拿到一个storage生成的文件名,接下来客户端根据这个文件名即可访问到该文件。

跟upload file一样,在download file时客户端可以选择任意tracker server。
tracker发送download请求给某个tracker,必须带上文件名信息,tracke从文件名中解析出文件的group、大小、创建时间等信息,然后为该请求选择一个storage用来服务读请求。由于group内的文件同步时在后台异步进行的,所以有可能出现在读到时候,文件还没有同步到某些storage server上,为了尽量避免访问到这样的storage,tracker按照如下规则选择group内可读的storage。
文件创建时间戳-storage被同步到的时间戳 且(当前时间-文件创建时间戳)>文件同步最大时间(5分钟),说明文件创建后,认为经过最大同步时间后,肯定已经同步到其他storage了。
(一)FastDFS 高可用集群架构学习---简介的更多相关文章
- (三)FastDFS 高可用集群架构学习---Client 接口开发
一.Python3 与 FastDFS 交互 1.安装 py3fdfs模块 # pip3 install py3Fdfs 2.测试使用 py3Fdfs 与 Fastdfs 集群交互(上传文件) fro ...
- (二)FastDFS 高可用集群架构学习---搭建
一.单group 单磁盘 的 FastDFS 集群 a.前期准备 1.系统软件说明: 名称 说明 CentOS 7.x(安装系统) libfastcommon FastDFS分离出的一些公用函数包 F ...
- (四)FastDFS 高可用集群架构学习---后期运维--基础知识及常用命令
1.fastdfs 七种状态 FDFS_STORAGE_STATUS:INIT :初始化,尚未得到同步已有数据的源服务器 FDFS_STORAGE_STATUS:WAIT_SYNC :等待同步,已得到 ...
- FastDFS高可用集群架构配置搭建
一.基本模块及高可用架构 FastDFS 是余庆老师开发的一个开源的高性能分布式文件系统(DFS). 它的主要功能包括:文件存储,文件同步和文件访问,以及高容量和负载平衡. FastDFS 系统有 ...
- FastDFS高可用集群架构配置搭建及使用
一,概述FastDFS 是一个开源的高性能分布式文件系统(DFS). 它的主要功能包括:文件存储,文件同步和文件访问,以及高容量和负载平衡.FastDFS 系统有三个角色:跟踪服务器(Tracker ...
- MongoDB 高可用集群架构简介
在大数据的时代,传统的关系型数据库要能更高的服务必须要解决高并发读写.海量数据高效存储.高可扩展性和高可用性这些难题.不过就是因为这些问题Nosql诞生了. 转载自严澜的博文——<如何搭建高效的 ...
- Java高可用集群架构与微服务架构简单分析
序 可能大部分读者都在想,为什么在这以 dubbo.spring cloud 为代表的微服务时代,我要还要整理这种已经"过时"高可用集群架构? 本人工作上大部分团队都是7-15人编 ...
- 构建MHA实现MySQL高可用集群架构
一.MHA简介 MHA(Master HighAvailability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开 ...
- Mysql MHA高可用集群架构
** 记得之前发过一篇文章,名字叫<浅析MySQL高可用架构>,之后一直有很多小伙伴在公众号后台或其它渠道问我,何时有相关的深入配置管理文章出来,因此,民工哥,也将对前面的各类架构逐一进行 ...
随机推荐
- 开源物联网平台(Thingsboard)-编译
环境准备 Jdk8+ (3.2.2版本开始使用Jdk11) Maven3.2.1+ release-3.2分支 获取代码 ##get source from mirror git clone http ...
- Node.js躬行记(11)——E2E测试
Cypress是为现代网络构建的前端测试工具,解决了开发人员和 QA 工程师在测试应用程序时面临的关键痛点. 在这个测试框架中包含了E2E测试.集成测试和单元测试(内嵌了Mocha),我们需要的是它的 ...
- 大前端快闪二:react开发模式 一键启动多个服务
最近全权负责了一个前后端分离的web项目,前端使用create-react-app, 后端使用golang做的api服务. npx create-react-app my-app cd my-app ...
- CF235D-Graph Game【LCA,数学期望】
正题 题目链接:https://www.luogu.com.cn/problem/CF235D 题目大意 给出一棵基环树,每次随机选择一个点让权值加上这个点的连通块大小然后删掉这个点. 求删光所有点时 ...
- P7408-[JOI 2021 Final]ダンジョン 3【贪心,树状数组】
正题 题目链接:https://www.luogu.com.cn/problem/P7408 题目大意 一个有\(n+1\)层的地牢,从\(i\)到\(i+1\)层要\(A_i\)点能量,第\(i\) ...
- CF700E-Cool Slogans【SAM,线段树合并,dp】
正题 题目链接:https://www.luogu.com.cn/problem/CF700E 题目大意 给出一个字符串\(S\),求一个最大的\(k\)使得存在\(k\)个字符串其中\(s_1\)是 ...
- P5631-最小mex生成树【线段树,并查集】
正题 题目链接:https://www.luogu.com.cn/problem/P5631 题目大意 \(n\)个点\(m\)条边的一张图,求\(mex\)值最小的一棵生成树. 解题思路 考虑比较暴 ...
- P7276-送给好友的礼物【dp】
正题 题目链接:https://www.luogu.com.cn/problem/P7276?contestId=39577 题目大意 \(n\)个点的一棵树,\(k\)个关键点,两个人从根出发分别走 ...
- 10-Java中共享内存可见性以及synchronized和volatile关键字
Java中共享变量的内存可见性 我们首先来看一下在多线程下处理共享变量时Java的内存模型,如图所示 Java内存模型规定,将所有的变量都存放在主存中,当线程使用变量的时候,会把主内存里面的变量赋值到 ...
- 【C++ Primer Plus】编程练习答案——第4章
1 void ch4_1() { 2 using namespace std; 3 string fname, lname; 4 char grade; 5 unsigned int age; 6 c ...