SuperEdge 高可用云边隧道有哪些特点?
作者
作者李腾飞,腾讯容器技术研发工程师,腾讯云TKE后台研发,SuperEdge核心开发成员。
背景
在边缘集群中,边缘端和云端为单向网络,云端无法主动连接边缘端,常见的解决方案是边缘端主动和云端(tunnel server)建立长连接,云端通过长连接将请求转发到边缘端。在云端隧道 server 实例扩容后需要考虑新增的实例对已有的边缘端长连接转发的影响。出于系统稳定性的考虑,能通过云边隧道采集到边缘端的监控信息。
社区方案ANP
隧道云端 Server 自动扩缩容
ANP 主要用于代理转发 apiserver 的请求,架构图如下图所示:
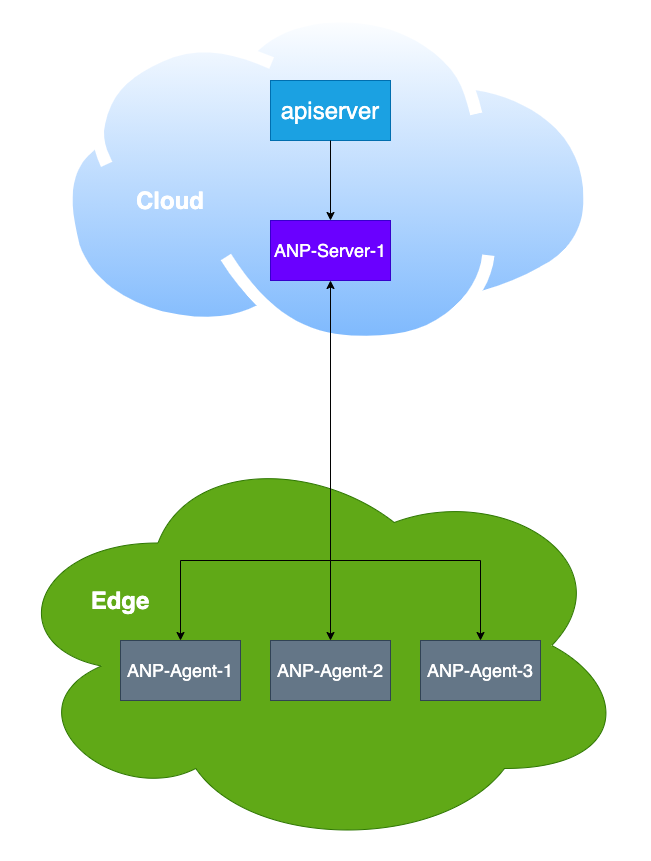
ANP 的 server 仅支持单实例,如果是多实例会存存在以问题,下面根据多实例的架构图进行说明:

- ANP Agent 需要和所有的 ANP Server 实例建立长连接。
- ANP Server 扩容之后,支持接入的 ANP Agent 的规模不会增加
节点监控
ANP 项目主要针对 K8s 1.16版本发布的特性 EgressSelector,在这个特性中 apiserver 会首先使用 HTTP CONNECT 方法建立隧道,然后通过隧道把请求边缘端的请求发送到 ANP Server,ANP Server 通过与 ANP Agent 建立的长连接,把请求发送到边缘端。业界常用的监控采集组件 Prometheus 是不支持 EgressSelector 特性的,因此使用 ANP 项目是无法支持节点监控的。
SuperEdge 云边隧道(tunnel)方案
SuperEdge 云边隧道 tunnel 在方案设计时使用 DNS 做边缘节点的注册中心,注册中心存储的是 tunnel-edge 的ID 和 tunnel-edge 连接到 tunnel-cloud 的 podIp,在做 apiserver 到边缘端请求转发时可以根据注册中心的ID将请求转发到边缘端连接到的 tunnel cloud 的 pod 上,具体架构图如下所示:
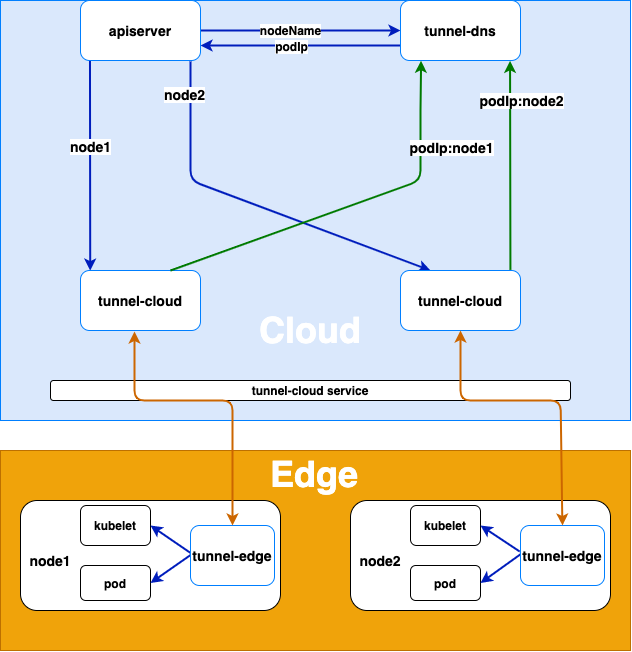
上图中的 apiserver 组件可以是云端其他组件,比如 Prometheus,下面分别从自动扩缩容和节点监控对 tunnel 的使用场景做进一步的说明。
tunnel cloud 的自动扩缩容(HPA)
在多实例的场景下对比 ANP 项目,tunnel 具备以下的优势:
- tunnel-edge 只需和一个 tunnel-cloud 实例长连接即可。apiserver 根据 tunnel-dns 的存储的 tunnel-edge 的 ID 和 tunnel-cloud pod 的映射关系确定请求的 tunnel-cloud pod ,然后再把请求转发到 tunnel-edge。
- tunnel-cloud 扩容之后,tunnel-cloud 支持接入的 tunnel-edge 的数目会增加。
自定义自动扩缩容策略
tunnel-cloud 除了根据内存和 CPU 的使用情况自动扩缩容之外,还可以根据与 tunnel-cloud 建立长连接的边缘节点的个数实现自动扩缩容,架构图如下:
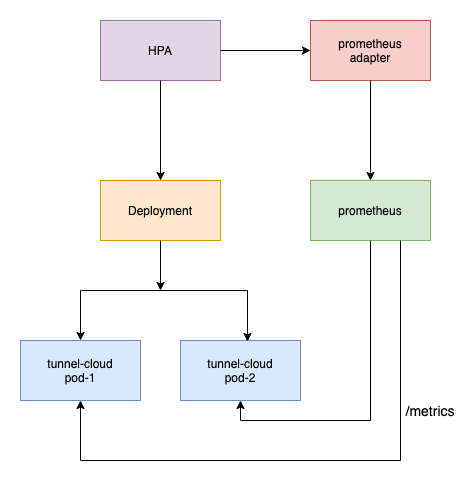
- prometheus 从 tunnel-cloud 的 pod 采集 metrics
{
"__name__": "tunnel_cloud_nodes",
"instance": "172.31.0.10:6000",
"job": "tunnel-cloud-metrics",
"kubernetes_namespace": "edge-system",
"kubernetes_pod_name": "tunnel-cloud-64ff7d9c9d-4lljh"
}
- prometheus-adapter 向 apiserver 注册 Custom Metrics API 的扩展 apiserver
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "custom.metrics.k8s.io/v1beta1",
"resources": [
{
"name": "namespaces/nodes_per_pod",
"singularName": "",
"namespaced": false,
"kind": "MetricValueList",
"verbs": [
"get"
]
},
{
"name": "pods/nodes_per_pod",
"singularName": "",
"namespaced": true,
"kind": "MetricValueList",
"verbs": [
"get"
]
}
]
}
- prometheus-adapter 将 metrics 转化为 pod 度量指标
{
"describedObject":{
"kind":"Pod",
"namespace":"edge-system",
"name":"tunnel-cloud-64ff7d9c9d-vmkxh",
"apiVersion":"/v1"
},
"metricName":"nodes_per_pod",
"timestamp":"2021-07-14T10:19:37Z",
"value":"1",
"selector":null
}
- 配置自定义 HPA
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: tunnel-cloud
namespace: edge-system
spec:
minReplicas: 1
maxReplicas: 10
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: tunnel-cloud
metrics:
- type: Pods
pods:
metric:
name: nodes_per_pod
target:
averageValue: 300 #平均每个pod连接的边缘节点的个数,超过这个数目就会触发扩容
type: AverageValue
节点监控方案
节点监控主要采集边缘节点 kubelet 的 metrics 和 node-exporter 采集到的硬件、系统指标。在部署 Prometheus 时配置 pod 的 dns 指向 tunnel-dns,Prometheus 使用节点名访问边缘节点上的 kubelet 和 node-exporter,tunnel-dns 会把节点名解析为边缘节点的 tunnel-edge 连接的 tunnel-cloud 的 podIp,Prometheus 根据 podIp 访问 tunnel-cloud(其中获取 kubelet 的 metrics 访问的是10250端口,请求 node-exporter 访问的9100端口),tunnel-cloud 通过长连接隧道将请求转发到 tunnel-edge,由 tunnel-edge 向 kubelet 和 node-exporter 发起请求,整个流程的框图如下所示:
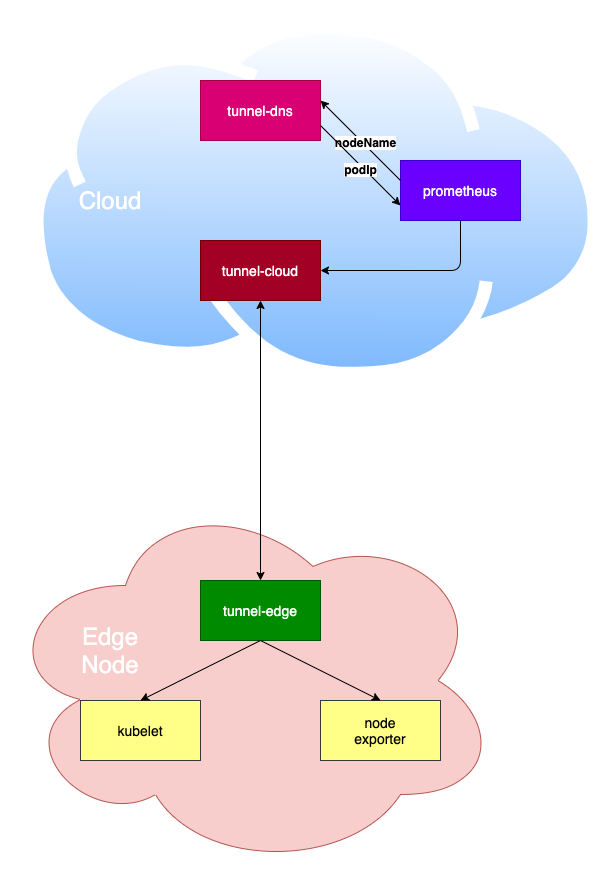
- 配置 Prometheus 的 DNS 指向 tunnel-dns
dnsConfig:
nameservers:
- <tunnel-dns的clusterip>
options:
- name: ndots
value: "5"
searches:
- edge-system.svc.cluster.local
- svc.cluster.local
- cluster.local
dnsPolicy: None
- 配置 Prometheus 使用节点名访问 kubelet 和 node-exporter
- job_name: node-cadvisor
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
insecure_skip_verify: true
relabel_configs:
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __address__
replacement: ${1}:10250
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /metrics/cadvisor
- source_labels: [__address__]
target_label: "unInstanceId"
replacement: "none"
- job_name: node-exporter
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
insecure_skip_verify: true
relabel_configs:
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __address__
replacement: ${1}:9100
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /metrics
- source_labels: [__address__]
target_label: "unInstanceId"
replacement: "none"
总结和展望
SuperEdge 的云边隧道方案(tunnel)相比社区的 ANP 方案,具有以下的特点:
- 支持自动扩缩容
- 支持了 Prometheus 采集节点监控数据
- SSH 登录边缘节点
- 支持 TCP 转发
当然我们也会继续完善 tunnel 的能力,使其能够满足更多场景的需求,根据社区小伙伴的反馈,接下来 tunnel 组件会支持以下功能:
- 支持从云端访问边缘端的 service 和边缘端访问云端的 service
- 支持 EgressSelector 特性
合作与开源
云边隧道的支持云端 server 自动扩缩容和节点监控新特性已经在 SuperEdge release 0.5.0 [https://github.com/superedge/superedge/blob/main/CHANGELOG/CHANGELOG-0.5.md] 开源,欢迎大家体验。我们也会持续提升 Tunnel 的能力,适用更加复杂的边缘网络场景,也欢迎对边缘计算感兴趣的公司、组织及个人一起共建 SuperEdge 边缘容器项目。
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!

SuperEdge 高可用云边隧道有哪些特点?的更多相关文章
- 一文读懂 SuperEdge 云边隧道
作者 李腾飞,腾讯容器技术研发工程师,腾讯云TKE后台研发,SuperEdge核心开发成员. 杜杨浩,腾讯云高级工程师,热衷于开源.容器和Kubernetes.目前主要从事镜像仓库,Kubernete ...
- keepalived工作原理和配置说明 腾讯云VPC内通过keepalived搭建高可用主备集群
keepalived工作原理和配置说明 腾讯云VPC内通过keepalived搭建高可用主备集群 内网路由都用mac地址 一个mac地址绑定多个ip一个网卡只能一个mac地址,而且mac地址无法改,但 ...
- 亚马逊AWS在线系列讲座——基于AWS云平台的高可用应用设计
设计高可用的应用是架构师的一个重要目标,可是基于云计算平台设计高可用应用与基于传统平台的设计有很多不同.云计算在给架构师带来了很多新的设计挑战的时候,也给带来了很多新的设计理念和可用的服务.怎样在设计 ...
- 转://Oracle 高可用技术与云基础架构
众所周知Oracle云基础架构已经在越来越多的行业里应用.大家了解云基础架构是如何演进的嘛?可能有人会说Oracle高可用技术是组成云架构的基础,那它们的关系是怎么样的?大家又了解Oracle高可用技 ...
- 腾讯云部署keepalived高可用
使用背景: 通过调用python SDK在腾讯云手动部署keepalived高可用 部署环境 系统:centos7.3 Master:192.168.0.100 Slave:192.168.0.14 ...
- 使用睿云智合开源 Breeze 工具部署 Kubernetes v1.12.3 高可用集群
一.Breeze简介 Breeze 项目是深圳睿云智合所开源的Kubernetes 图形化部署工具,大大简化了Kubernetes 部署的步骤,其最大亮点在于支持全离线环境的部署,且不需要FQ获取 G ...
- 基于阿里云SLB/ESS/EIP/ECS/VPC的同城高可用方案演练
今天基于阿里云SLB/ESS/EIP/ECS/VPC等产品进行了一次同城高可用方案演练: 基本步骤如下: 1. 在华东1创建VPC网络VPC1,在华东1可用区B和G各创建一个虚拟交换机vpc1_swi ...
- Redis之高可用、集群、云平台搭建(非原创)
文章大纲 一.基础知识学习二.Redis常见的几种架构及优缺点总结三.Redis之Redis Sentinel(哨兵)实战四.Redis之Redis Cluster(分布式集群)实战五.Java之Je ...
- 阿里巴巴高可用技术专家襄玲:压测环境的设计和搭建 PTS - 襄玲 云栖社区 今天
阿里巴巴高可用技术专家襄玲:压测环境的设计和搭建 PTS - 襄玲 云栖社区 今天
随机推荐
- external-provisioner源码分析(2)-main方法与Leader选举分析
更多ceph-csi其他源码分析,请查看下面这篇博文:kubernetes ceph-csi分析目录导航 external-provisioner源码分析(2)-main方法与Leader选举分析 本 ...
- python读取txt文件绘制散点图
方法和画折线图类似,差别在于画图函数不一样,用的是scatter() import matplotlib.pyplot as plt #以外部两个txt表分别作为x,y画图n=0m=0with ope ...
- Unity3D 本地数据持久化几种方式
下面介绍几种 Unity本地记录存储的实现方式. 第一种 Unity自身提供的 PlayerPrefs //保存数据 PlayerPrefs.SetString("Name",mN ...
- hdu 6034 贪心模拟 好坑
关键在排序!!! 数组间的排序会超时,所以需要把一个数组映射成一个数字,就可以了 #include <bits/stdc++.h> using namespace std; typedef ...
- AcWing 903. 昂贵的聘礼
年轻的探险家来到了一个印第安部落里. 在那里他和酋长的女儿相爱了,于是便向酋长去求亲. 酋长要他用10000个金币作为聘礼才答应把女儿嫁给他. 探险家拿不出这么多金币,便请求酋长降低要求. 酋长说:& ...
- AcWing 220. 最大公约数
给定整数N,求1<=x,y<=N且GCD(x,y)为素数的数对(x,y)有多少对. GCD(x,y)即求x,y的最大公约数. #include<bits/stdc++.h> u ...
- Docker:docker搭建redis一主多从集群(配置哨兵模式)
角色 实例IP 实例端口 宿主机IP 宿主机端口 master 172.19.0.2 6382 192.168.1.200 6382 slave01 172.19.0.3 6383 192.168.1 ...
- [心得]docker学习笔记
1. docker是什么??? (1) docker是一台类似虚拟机的功能, 内部由一个个镜像组成, 镜像里可以运行容器, 而这个容器可以是任何东西, 比如mysql, 比如tomcat等等, 它的目 ...
- MySQL 查看命令执行时间
查看执行时间 1 show profiles; 2 show variables like "%pro%";查看profiling 是否是on状态: 3 如果是off,则执行se ...
- 数据源连接数据库配置相关xml文件
学完数据源连接数据后,做个笔记,当我们的程序对数据库访问频繁时,为了提高程序运行效率,我们可以通过 数据源连接数据库,从数据库连接池中直接取得出于空闲状态的数据库连接对象,以下是相关xml文件的配置: ...