HBase结构
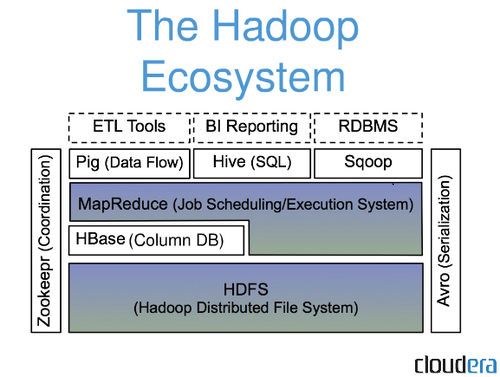
1.什么是HBase
2.HBase的特点
3.HBase表格示意图

4.HBase的组件构成
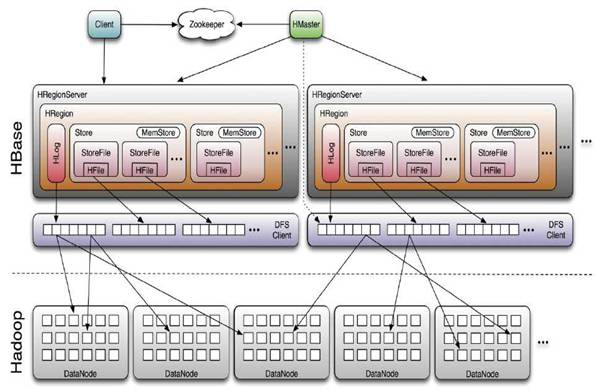
5.HBase中表格的存储
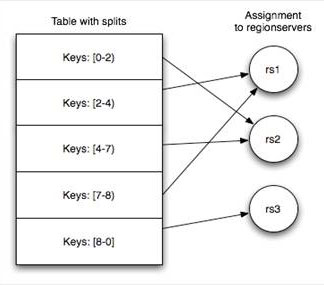
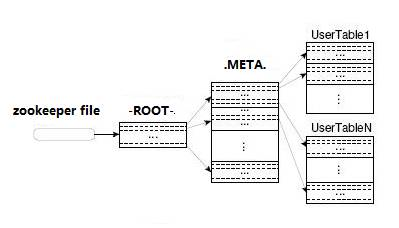
6.HBase读数据
7.HBase写数据
HBase结构的更多相关文章
- Hbase结构简单、作法
Hbase架构简单介绍.实践 版权声明:本文博主原创文章,博客,未经同意不得转载.
- Phoenix(sql on hbase)简单介绍
Phoenix(sql on hbase)简单介绍 介绍: Phoenix is a SQL skin over HBase delivered as a client-embedded JDBC d ...
- kylin-cube存储结构
前言 本篇文章通过图文的方式分析不同维度组合下的cube在hbase中的存储结构 需要声明的是,kylin不存原始数据,存储cube 全维度构建 假设一张表有3个字段name,age,sex,那么当通 ...
- RDBMS关系型数据库与HBase的对比
关系型数据库 结构: * 数据库以表的形式存在 * 支持FAT.NTFS.EXT.文件系统 * 使用Commit log存储日志 * 参考系统是坐标系统 * 使用主键(PK) * 支持分区 * 使用行 ...
- 大数据篇:Hbase
大数据篇:Hbase Hbase是什么 Hbase是一个分布式.可扩展.支持海量数据存储的NoSQL数据库,物理结构存储结构(K-V). 如果没有Hbase 如何在大数据场景中,做到上亿数据秒级返回. ...
- 深度预警:深入理解HBase的系统架构
HBase的构成 物理上来说,HBase是由三种类型的服务器以主从模式构成的.这三种服务器分别是:Region server,HBase HMaster,ZooKeeper. 其中Region ser ...
- hbase_2
====HBase API========================================================= ** 配置maven依赖(pom.xml),不需要hado ...
- HBase 的表结构
HBase 的表结构 2016-10-13 杜亦舒 HBase 是一个NoSQL数据库,用于处理海量数据,可以支持10亿行百万列的大表,下面就了解一下数据是如何存放在HBase表中的 关系型数据库的表 ...
- Hbase之修改表结构
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; impo ...
随机推荐
- Vue页面内公共的多类型附件图片上传区域并适用折叠面板
在前端项目中,附件上传是很常用的功能,几乎所有的app相关项目中都会使用到,一般在选择使用某个前端UI框架时,可以查找其内封装好的图片上传组件,但某些情况下可能并不适用于自身的项目需求,本文中实现的附 ...
- Json解析案例-teachers数据集
背景: 通过平台执行接口时,接口往往返回的JSON串,所以平台要能提供方便快捷的JSON解析函数. 一.Json字符串: 1 { 2 "lemon": { 3 "teac ...
- Linux(Centos) 设置显示vim行号
1.修改vimrc文件 vim /etc/vimrc 2.在最后添加 set nu 如下图片所示 然后wq! 保存退出
- 【LeetCode】862. Shortest Subarray with Sum at Least K 解题报告(C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 队列 日期 题目地址:https://leetcod ...
- 1254 - Prison Break
1254 - Prison Break PDF (English) Statistics Forum Time Limit: 2 second(s) Memory Limit: 32 MB Mic ...
- 倍福CX5120嵌入式控制器使用教程
1.新建工程 新建TwinCAT XAE Project 2.连接设备 点击SYSTEM,再点击"Change Target..." 在弹出的"choose Targt ...
- 面试官:this和super有什么区别?this能调用到父类吗?
本文已收录<Java常见面试题>:https://gitee.com/mydb/interview this 和 super 都是 Java 中常见的关键字,虽然二者在很多情况下都可以被省 ...
- Regularizing Deep Networks with Semantic Data Augmentation
目录 概 主要内容 代码 Wang Y., Huang G., Song S., Pan X., Xia Y. and Wu C. Regularizing Deep Networks with Se ...
- 从零开始学springboot-2.配置项目
### 配置项目 #### 将application.properties改名为application.yml #### 在resources文件夹中(和上面那个配置文件同一路径下)新建一个文件app ...
- ATA考试
一.确定机房作为ATA考试机器的数量. (1)确定本次ATA考试本校每个机房上报了多少台机器. ATA考试机的使用总数量不包含ATA管理机器.在上报机房机器数量的时候,在 机房的总数量上减去 ...