大数据学习day14-----第三阶段-----scala02------1. 元组 2.类、对象、继承、特质 3.函数(必须掌握)
1. 元组
映射是K/V对偶的集合,对偶是元组的最简单的形式,元组可以装着多个不同类型的值
1.1 特点
元组相当于一个特殊的数组,其长度和内容都可变,并且数组中可以装任何类型的数据,其主要用处就是存一些类型不同的数据,如定义一个方法,其要返回多个类型不同的值,如果在java中就需要定义一个bean去set这些值并返回,而scala就方便了,直接将不同类型的数据放入元组返回。
1.2 创建元组
定义元组时用小括号将多个元素包起来,元素之间用逗号分隔,元素的类型可以不一样,元素的个数可以任意多个,如
object TupleDemo {
def main(args: Array[String]): Unit = {
val tuple: (Int, Double, String) = m(1, 2.5)
}
def m(x: Int, y: Double) = {
val x1 = x*10
val y1 = y*100
val w1 = "hello"
(x1, y1, w1)
}
}
此处涉及的快捷键:当定义元组时(m(1, 2.5)),这个时候在后面写上.var,回车即可得到变量,此时会出如下选择框(看是否给元组加类型),如下:
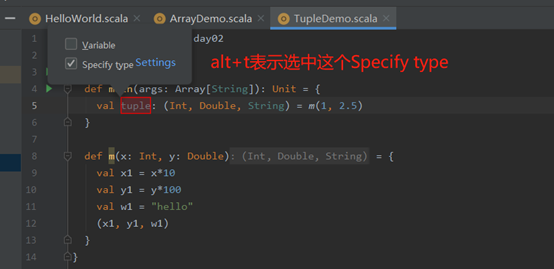
alt+t即可选中Specify type(给元组加上类型),变量等定义也是一样的,当元组已经定义完了,并且没有加上数据类型,但后面又想加上,此时的快捷键为alt+enter
1.3 获取元组中的值
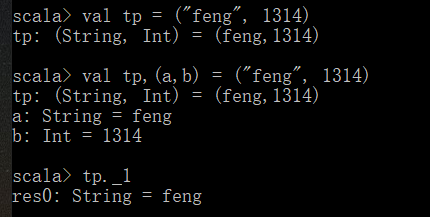
获取元组中的元素可以使用下划线加角标,但是需要注意的是元组中的元素角标是从1开始的,此外还可以自己将元组中的元素赋值给某个数(如下,a,b分别代表feng,1314)
1.4 将对偶的集合(元组不行)转换成映射


1.5 拉链操作
zip命令可以将多个值绑定在一起
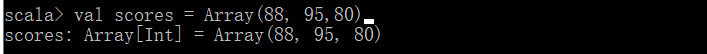
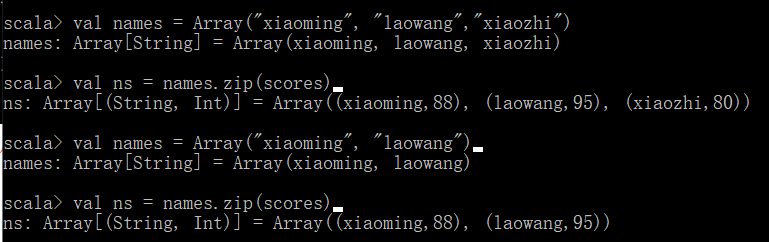
注意:如果两个数组的元素个数不一致,拉链操作后生成的数组的长度为较小的那个数组的元素个数
2. 类、对象、继承、特质
2.1 类
Scala的类与java类比起来更加简单,与python中类似
2.1.1类的定义
在scala中,类并不用声明为public,默认就是public,并且在一个Scala源文件中可以包含多个类,所有这些类都具有公有可见性
class Student {
//用val修饰的变量是只读属性,有getter但没有setter
//(相当与Java中用final修饰的变量)
val id = 666
//用var修饰的变量既有getter又有setter,下划线代表对应类型的默认值,必须指定变量的类型
var age: Int = _
//类私有字段,只能在类的内部使用,和伴生对象中使用
private var name: String = "tom"
//对象私有字段,访问权限更加严格的,只能在类的内部【当前实例中使用】
private[this] val pet = "小强"
}
//private 和 private[this]同样可以修饰方法
//类和伴生对象中的属性和方法都可以用访问权限控制符修饰
//类和伴生对象可以相互访问private修饰的变量和方法
//private[this]如果在类中定义,就只能在类的内容使用
//private[this]如果在object中定义,就只能在object的内容使用
2.1.2 构造器
(1)主构造器
每个类都有主构造器,主构造器的参数直接放置在类名后面,与类交织在一起,主构造器会执行类中定义的所有语句(new构造器所在的类即会执行)
案例
//主构造器
class Person(var name: String, var age: Int) {
println("执行主构造器")
println(name+","+age)
print("主构造器执行完")
} object Person {
def main(args: Array[String]): Unit = {
val person: Person = new Person("隔壁老王",38)
}
}
执行结果
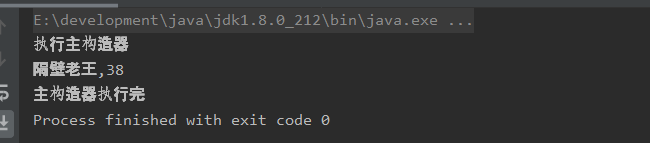
可见,在伴生对象中,new完Person对象后,Person类中的代码就被执行了
(2)辅助构造器
- 辅助构造器是对主构造器的补充和扩展,辅助构造器的第一行一定要调用主构造器或者是其他已经调用了主构造器的辅助构造器
//主构造器
class People(val name: String) {
var age: Int = _
var gender: String = _
//辅助构造器,是对主构造器的补充和扩展
def this(name: String, age: Int) {
//辅助构造器的第一行一定要调用主构造器
this(name)
this.age = age
}
def this(name: String, age: Int, gender: String) {
//辅助构造器的第一行一定要调用主构造器,或者是其他的辅助构造器
//this(name)
this(name, age)
this.gender = gender
}
}
注意:由于辅助构造器是对主构造器的扩展,所以主构造器的参数一般比辅助构造器的参数少
- 如果定义主构造器,参数没有用var或val修饰,那么就不会成为这个类的成员变量======>局部变量(见零基础学习java day07)

(3)构造器的私有化
在类名后加private就变成了私有的构造器,其只能在其伴生对象中使用

2.2 对象
2.2.1 单例对象(可参考零基础学习java day08)
在scala中,小写的object代表的是一个静态对象,也是单例对象,当满足一定条件时(和某个类名相同,就是该类的伴生对象)就是伴生对象

运行结果

可见,s1和s2是同一个实例
2.2.2 伴生对象
在Scala的类中,与类名相同并且被object修饰的对象叫做伴生对象,类和伴生对象之间可以相互访问私有的方法和属性
2.2.3 Apply方法
通常我们会在类的伴生对象中定义apply方法,当遇上伴生对象(参数1.....参数n) 时,apply方法会被调用
object ApplyDemo {
def apply(): Unit = {
println(888)
}
def apply(x: Int): Unit = {
println(x)
}
def apply(x: Int, y: Double): Unit = {
println(x + y)
}
def main(args: Array[String]): Unit = {
//静态对象名后面跟(),就是调用对应的apply方法
//ApplyDemo()
//ApplyDemo.apply()
ApplyDemo(666)
ApplyDemo(6, 7.5)
ApplyDemo.apply(6, 7.5)
val arr = Array(1, 2, 3, 4, 5)
}
}
伴生对象() ==伴生对象.apply()
2.3 继承
- Scala中继承使用extends,实现接口使用with
- 在scala中,第一次不论是继承还是实现特质,都使用extends关键字,并且extends只能用一次
多态的两个前提:父类引用指向子类;重写相应的方法
3 函数
在Scala中,方法就是方法(method),函数就是函数(function),函数本质上是一个引用
(1) 函数的定义形式

一定要调用这个函数,否则不会执行,此处的f(2)相当于f.apply(2)
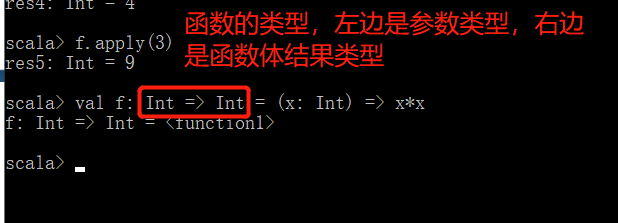
(2)函数的完整定义(加上函数的类型)
(3)匿名函数
scala中的匿名函数即不需要引用,以下便是一个匿名函数
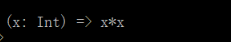
(4)单词统计例子
- 求集合中的偶数
第一种方法(非函数式编程):
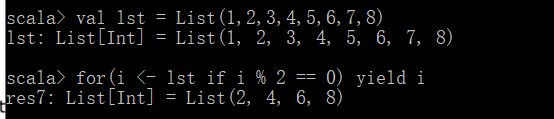
第二种方法(函数式编程)
首先定义一个函数,在将这个函数作为参数传入Scala自带的高级函数(此处是filter)中,即可得到结果
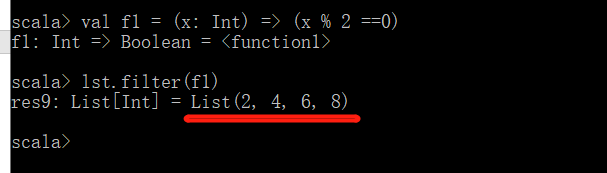
- 统计集合中单词的个数(即line中单词的个数)
a. 首先需要将单词切割,得到如下结果

更加简洁的写法

b 进行统计单词的个数
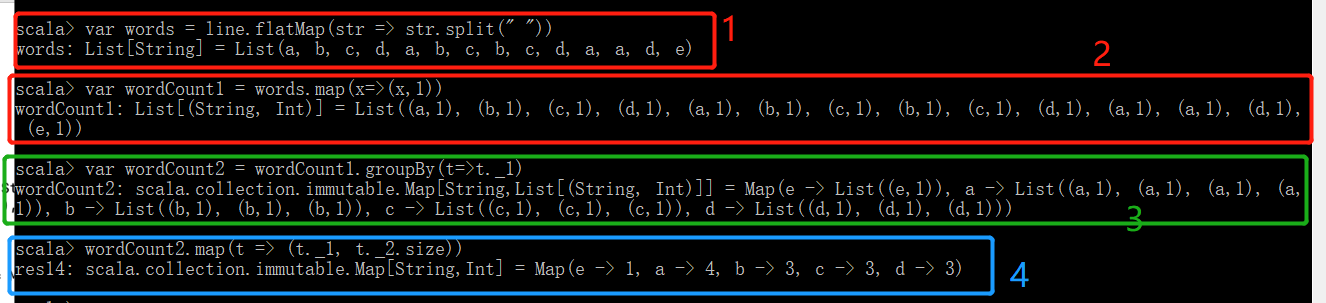
可以将上面4不组合成一步,就可以一行代码解决问题
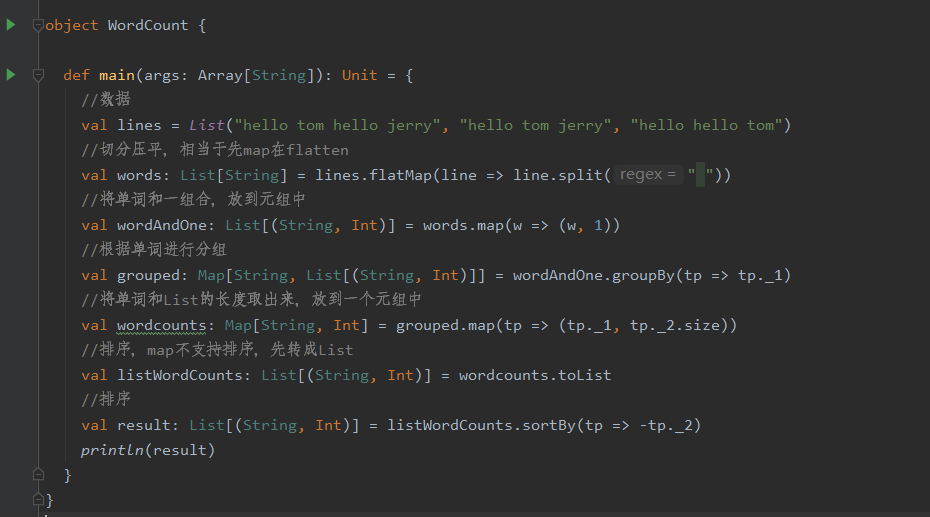
在IDEA上写词案例:
大数据学习day14-----第三阶段-----scala02------1. 元组 2.类、对象、继承、特质 3.函数(必须掌握)的更多相关文章
- 大数据学习--day14(String--StringBuffer--StringBuilder 源码分析、性能比较)
String--StringBuffer--StringBuilder 源码分析.性能比较 站在优秀博客的肩上看问题:https://www.cnblogs.com/dolphin0520/p/377 ...
- 大数据学习(一) | 初识 Hadoop
作者: seriouszyx 首发地址:https://seriouszyx.top/ 代码均可在 Github 上找到(求Star) 最近想要了解一些前沿技术,不能一门心思眼中只有 web,因为我目 ...
- 大数据学习笔记——Linux完整部署篇(实操部分)
Linux环境搭建完整操作流程(包含mysql的安装步骤) 从现在开始,就正式进入到大数据学习的前置工作了,即Linux的学习以及安装,作为运行大数据框架的基础环境,Linux操作系统的重要性自然不言 ...
- 大数据学习day29-----spark09-------1. 练习: 统计店铺按月份的销售额和累计到该月的总销售额(SQL, DSL,RDD) 2. 分组topN的实现(row_number(), rank(), dense_rank()方法的区别)3. spark自定义函数-UDF
1. 练习 数据: (1)需求1:统计有过连续3天以上销售的店铺有哪些,并且计算出连续三天以上的销售额 第一步:将每天的金额求和(同一天可能会有多个订单) SELECT sid,dt,SUM(mone ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
随机推荐
- TypeError: 'encoding' is an invalid keyword argument for this function 解决Python 2.7
在python2.7中这样调用代码 open('file/name.txt','r',encoding= 'utf-8').read() 会出现 TypeError: 'encoding' is an ...
- vue打包后反编译到源代码(reverse-sourcemap)
因为突然的疫情把我困在家了,家里的电脑没有源代码,但是需求还要改,工作还得继续... 从服务器下载了之前上传的打包后的文件,找了一圈反编译方法,得救了,在此记录一下. 1.npm install -- ...
- Access的分页代码
if giPage = 1 then begin sSQL := 'SELECT TOP 10 * FROM dw_demo WHERE '+sWhere +' ORDER BY '+sOrder+' ...
- 非对称加密和linux上的 ssh-keygen 工具使用
rsa :创造非对称加密的三个人名.原理是两个1024到2048之间的素数,以此为乘积.等... a*b=c 一般a*b为私钥端,c为公钥端.因为 c非常难算出a和b. ssh-keygen -t ...
- linux下测试读写
1.测/目录所在磁盘的纯写速度: time dd if=/dev/zero bs=1024 count=1000000 of=/1Gb.file 2.测/目录所在磁盘的纯读速度: time dd if ...
- TTMS 一个基于Java Swing的Socket通信的剧院票务管理系统
TTMS (Theater Ticket Management System) 点我进入github TTMS全称剧院票务管理系统,分为客户端和服务器端.服务器端可以接收客户端连接请求,客户端相当于我 ...
- 大一C语言学习笔记(4)---自省篇
博主"曾经"做过的傻事: #你有的*没打全 #你用/的时候没考虑()是一对的 #printf随后加\n #所有变量只要用,就一定要定义数据类型 #sqrt()代表根号 #inclu ...
- HTTP 缓存终极指南
TL;DR 错误的缓存策略是如何抵消你所做的性能优化工作的. 缓存存在于客户端并且通过chrome或者其他抓包工具查看其状态信息. 客户端通过header中的各个字段做缓存的过期判断. 代理服务器上也 ...
- Python基础(普通函数及参数)
# def my_abs(x): # if not isinstance(x,(int,float)):#参数类型做检查,只允许整数和浮点数类型的参数.数据类型检查可以用内置函数isinstance( ...
- [hdu6995]Travel on Tree
问题即查询将其按照dfs序排序后,相邻两点(包括首尾)的距离和 考虑使用莫队+set维护,时间复杂度为$o(n\sqrt{n}\log n)$,无法通过 进一步的,注意到删除是可以用链表实现的,因此考 ...