XGBoost原理解析
摘要:对xgboost论文中的细节进行记录。
算法原理
系统设计
基于column block的并行

树学习最耗时的部分通常是对数据进行排序,为了降低排序带来的计算负荷,xgb使用基于block的结构对数据进行存储。每个block中的数据以compressed format(CSC)格式存储,每列按照数值大小进行排序。这样的数据结构仅需要在训练前计算一次,在后续的迭代过程中,可以重复使用。
对于精确算法,将所有数据保存在一个block中。建树的过程可以实现特征级别的并行,即每个线程处理一个特征。在单个线程内部,对数据的单次扫描可计算所有叶子节点在该特征上的最优分裂点。
对于近似算法,可以将不同的数据(按行)分布在不同的block中,并可以将不同的block分布到不同的机器。使用排好序的数据,qutile finding算法只需要线性扫描数据即可完成。
利用这样的结构,在对单个特征寻找分裂点时,也可以实现并行化,这也是xgb能够进行分布式并行的关键。
缓存感知(cache aware access)
block结构降低了计算的复杂度,但也带来了另外一个问题,那就是对梯度信息的读取是不连续的,如果梯度信息不能全部装进cache,这会导致cpu缓存命中率降低,从而影响性能。
在精确算法中,xgb使用cache-aware prefetch算法缓解这个问题。也就是为每个线程分配一个buffer,将梯度信息读入buffer,并以mini-batch的方式进行梯度累加。
对于近似算法,解决缓存命中失效的方法是选择合适的block size。过小的block size导致单线程的计算负载过小,并行不充分,过大的block size又会导致cache miss,因此需要做一个平衡。论文建议使用的block size为2^16。
核外计算(out of core computation)
为进行核外计算,将数据划分为多个block。计算期间,使用独立线程将磁盘上的block结构数据读进内存,因此计算和IO可以同步进行。然而,这只能解决一部分问题,因为IO占用的时间要远多于计算。因此,xgb使用以下两种方式优化:
数据压缩(block compression):将block按列进行压缩,并使用独立线程解压缩。这样可以对IO和CPU的占用时间进行对冲。
数据分区(block sharding):将数据分散到多个磁盘,每个磁盘使用一个线程读取数据,以此提高磁盘吞吐量。
单机精确算法实现
I. ObjFunction:对应于不同的Loss Function,可以完成一阶和二阶导数的计算。
II. GradientBooster:用于管理Boost方法生成的Model,注意,这里的Booster Model既可以对应于线性Booster Model,也可以对应于Tree Booster Model。
III. Updater:用于建树,根据具体的建树策略不同,也会有多种Updater。比如,在XGBoost里为了性能优化,既提供了单机多线程并行加速,也支持多机分布式加速。也就提供了若干种不同的并行建树的updater实现,按并行策略的不同,包括:
I). inter-feature exact parallelism (特征级精确并行)
II). inter-feature approximate parallelism(特征级近似并行,基于特征分bin计算,减少了枚举所有特征分裂点的开销)
III). intra-feature parallelism (特征内并行)
IV). inter-node parallelism (多机并行)
此外,为了避免overfit,还提供了一个用于对树进行剪枝的updater(TreePruner),以及一个用于在分布式场景下完成结点模型参数信息通信的updater(TreeSyncher),这样设计,关于建树的主要操作都可以通过Updater链的方式串接起来,比较一致干净,算是Decorator设计模式的一种应用。
以ColMaker(单机版的inter-feature parallelism,实现了精确建树的策略)为例,其建树操作大致如下:
updater_colmaker.cc:
ColMaker::Update()
-> Builder builder;
-> builder.Update()
-> InitData()
-> InitNewNode() // 为可用于split的树结点(即叶子结点,初始情况下只有一个
// 叶结点,也就是根结点) 计算统计量,包括gain/weight等
-> for (depth = 0; depth < 树的最大深度; ++depth)
-> FindSplit()
-> for (each feature) // 通过OpenMP获取
// inter-feature parallelism
-> UpdateSolution()
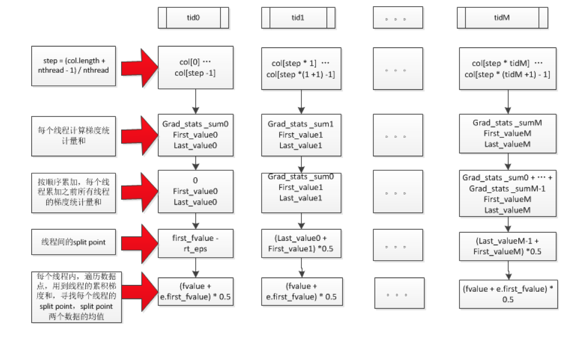
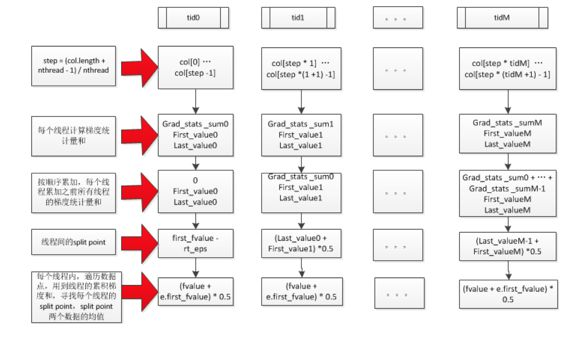
-> EnumerateSplit() // 每个执行线程处理一个特征,
// 选出每个特征的
// 最优split point
-> ParallelFindSplit()
// 多个执行线程同时处理一个特征,选出该特征
//的最优split point;
// 在每个线程里汇总各个线程内分配到的数据样
//本的统计量(grad/hess);
// aggregate所有线程的样本统计(grad/hess),
//计算出每个线程分配到的样本集合的边界特征值作为
//split point的最优分割点;
// 在每个线程分配到的样本集合对应的特征值集合进
//行枚举作为split point,选出最优分割点
-> SyncBestSolution()
// 上面的UpdateSolution()/ParallelFindSplit()
//会为所有待扩展分割的叶结点找到特征维度的最优split
//point,比如对于叶结点A,OpenMP线程1会找到特征F1
//的最优split point,OpenMP线程2会找到特征F2的最
//优split point,所以需要进行全局sync,找到叶结点A
//的最优split point。
-> 为需要进行分割的叶结点创建孩子结点
-> ResetPosition()
//根据上一步的分割动作,更新样本到树结点的映射关系
// Missing Value(i.e. default)和非Missing Value(i.e.
//non-default)分别处理
-> UpdateQueueExpand()
// 将待扩展分割的叶子结点用于替换qexpand_,作为下一轮split的
//起始基础
-> InitNewNode() // 为可用于split的树结点计算统计量

XGB vs GBDT
- 传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。
- 传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。
- xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性。
- Shrinkage(缩减),相当于学习速率(xgboost中的eta)。xgboost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把eta设置得小一点,然后迭代次数设置得大一点。(补充:传统GBDT的实现也有学习速率)
- 列抽样(column subsampling)。xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
- 对缺失值的处理。对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。
- xgboost工具支持并行。xgboost的并行不是tree粒度的并行,xgboost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。xgboost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),xgboost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
- 可并行的近似直方图算法。树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以xgboost还提出了一种可并行的近似直方图算法,用于高效地生成候选的分割点.
参考链接
https://arxiv.org/pdf/1603.02754.pdf
http://www.ra.ethz.ch/CDstore/www2011/proceedings/p387.pdf
https://www.zhihu.com/question/41354392
https://weibo.com/p/1001603801281637563132
XGBoost原理解析的更多相关文章
- [原][Docker]特性与原理解析
Docker特性与原理解析 文章假设你已经熟悉了Docker的基本命令和基本知识 首先看看Docker提供了哪些特性: 交互式Shell:Docker可以分配一个虚拟终端并关联到任何容器的标准输入上, ...
- 【算法】(查找你附近的人) GeoHash核心原理解析及代码实现
本文地址 原文地址 分享提纲: 0. 引子 1. 感性认识GeoHash 2. GeoHash算法的步骤 3. GeoHash Base32编码长度与精度 4. GeoHash算法 5. 使用注意点( ...
- Web APi之过滤器执行过程原理解析【二】(十一)
前言 上一节我们详细讲解了过滤器的创建过程以及粗略的介绍了五种过滤器,用此五种过滤器对实现对执行Action方法各个时期的拦截非常重要.这一节我们简单将讲述在Action方法上.控制器上.全局上以及授 ...
- Web APi之过滤器创建过程原理解析【一】(十)
前言 Web API的简单流程就是从请求到执行到Action并最终作出响应,但是在这个过程有一把[筛子],那就是过滤器Filter,在从请求到Action这整个流程中使用Filter来进行相应的处理从 ...
- GeoHash原理解析
GeoHash 核心原理解析 引子 一提到索引,大家脑子里马上浮现出B树索引,因为大量的数据库(如MySQL.oracle.PostgreSQL等)都在使用B树.B树索引本质上是对索引字段 ...
- alibaba-dexposed 原理解析
alibaba-dexposed 原理解析 使用参考地址: http://blog.csdn.net/qxs965266509/article/details/49821413 原理参考地址: htt ...
- 支付宝Andfix 原理解析
支付宝Andfix 原理解析 使用参考地址: http://blog.csdn.net/qxs965266509/article/details/49802429 原理参考地址: http://blo ...
- xgboost原理及应用
1.背景 关于xgboost的原理网络上的资源很少,大多数还停留在应用层面,本文通过学习陈天奇博士的PPT 地址和xgboost导读和实战 地址,希望对xgboost原理进行深入理解. 2.xgboo ...
- JavaScript 模板引擎实现原理解析
1.入门实例 首先我们来看一个简单模板: <script type="template" id="template"> <h2> < ...
随机推荐
- javascript 最权威的知识点总结
JavaScript中如何检测一个变量是一个String类型?请写出函数实现typeof(obj) === "string"typeof obj === "string& ...
- 从零学脚手架(六)---production和development拆分
development.production拆分 根据文件拆分 webpack打包时分为开发模式(development)和发布模式(production),在前面使用命令参数做了简单区分. 但这种方 ...
- [Python] 波士顿房价的7种模型(线性拟合、二次多项式、Ridge、Lasso、SVM、决策树、随机森林)的训练效果对比
目录 1. 载入数据 列解释Columns: 2. 数据分析 2.1 预处理 2.2 可视化 3. 训练模型 3.1 线性拟合 3.2 多项式回归(二次) 3.3 脊回归(Ridge Regressi ...
- Java字符串==和equals的区别
首先我们来了解一下String类,Java的字符串是一旦被赋值之后无法更改的(这里的无法更改是指不能将字符串中单个或一段字符重新赋值),这也是Java虚拟机为了减少内存开销,避免字符串的重复创建设立的 ...
- 推荐一款全能测试开发神器:Mockoon!1分钟快速上手!
1. 说一下背景 在日常开发或者测试工作中,经常会因为下游服务不可用或者不稳定时,通过工具或者技术手段去模拟一个HTTP Server,或者模拟所需要的接口数据. 这个时候,很多人脑海里,都会想到可以 ...
- MongoDB 那些事(一文以蔽之)
前言 身边一直都有小伙伴在问:MongoDB到底是什么?它有到底什么特性?有什么与众不同?在什么情况下使用MongoDB最合适?以什么样的姿势是最好的?难道就一定要用吗?....说实话,这些问题都问到 ...
- docker部署skywalking
https://www.cnblogs.com/xiao987334176/p/13530575.html
- java面试-线程池使用过吗,谈谈对ThreadPoolExector的理解
一.架构说明: 二.为什么使用线程池,优势是什么? 线程池做的工作主要是控制运行的线程的数量,处理过程中将任务放入队列,然后在线程创建后启动这些任务,如果线程数量超过了最大数量,那么超出数量的线程排队 ...
- 在Vue中使用sass和less,并解决报错问题(this.getOptions is not a function)
使用 Less 下载依赖:npm install less less-loader 在mian.js 中添加: import less from "less"; Vue.use(l ...
- HarmonyOS开发者看过来,HDD上海站传递的重要信息都在这里
4月17日,颇有HarmonyOS年度总结性质的HarmonyOS开发者日活动上海站正式开始. 活动中,华为消费者业务AI与智慧全场景业务部副总裁段孟对HarmonyOS生态建设的最新进展做了发言,并 ...