Waymo object detect 2D解决方案论文拓展
半监督中的基础论文,自监督和模型一致性的代表作。
- Consistency regularization: 无监督学习的方式,数据\(A\)和经过数据增强的\(A\)计做\(A'\) ,同时输入模型\(f\) ,由于其种类相同(未知但相同),所以\(f(A)=f(A')\) ,利用分布相同进行训练即可。
- Pseudo-labeling: 伪标签,使用人工标注数据集训练模型\(f\),然后使用此模型去预测未标注数据集,结果使用阈值进行过滤当做未标注数据的标签。
假设存在数据集 \(D\),有标签数据集\(D^l\) ,无标签数据集\(D^u\) ,所以\(D=\{D^l,D^u\}\) ,训练模型\(f\),训练步骤如下:
- 有标签的数据直接使用交叉熵loss
- 无标签的数据线进行前向计算得到结果计做\(Result\) ,设定阈值\(T\),\(0 \ \ if \ softmax(Result)>T \ else \ 0\) 制作一个one-hot的label,利用此label进行交叉熵loss计算
- 在训练的初期会经常出现loss为0的情况,因为前期不稳定,无标签的置信度小于阈值
- 这篇论文主要叙述数据增强的作用,阅读较为简单
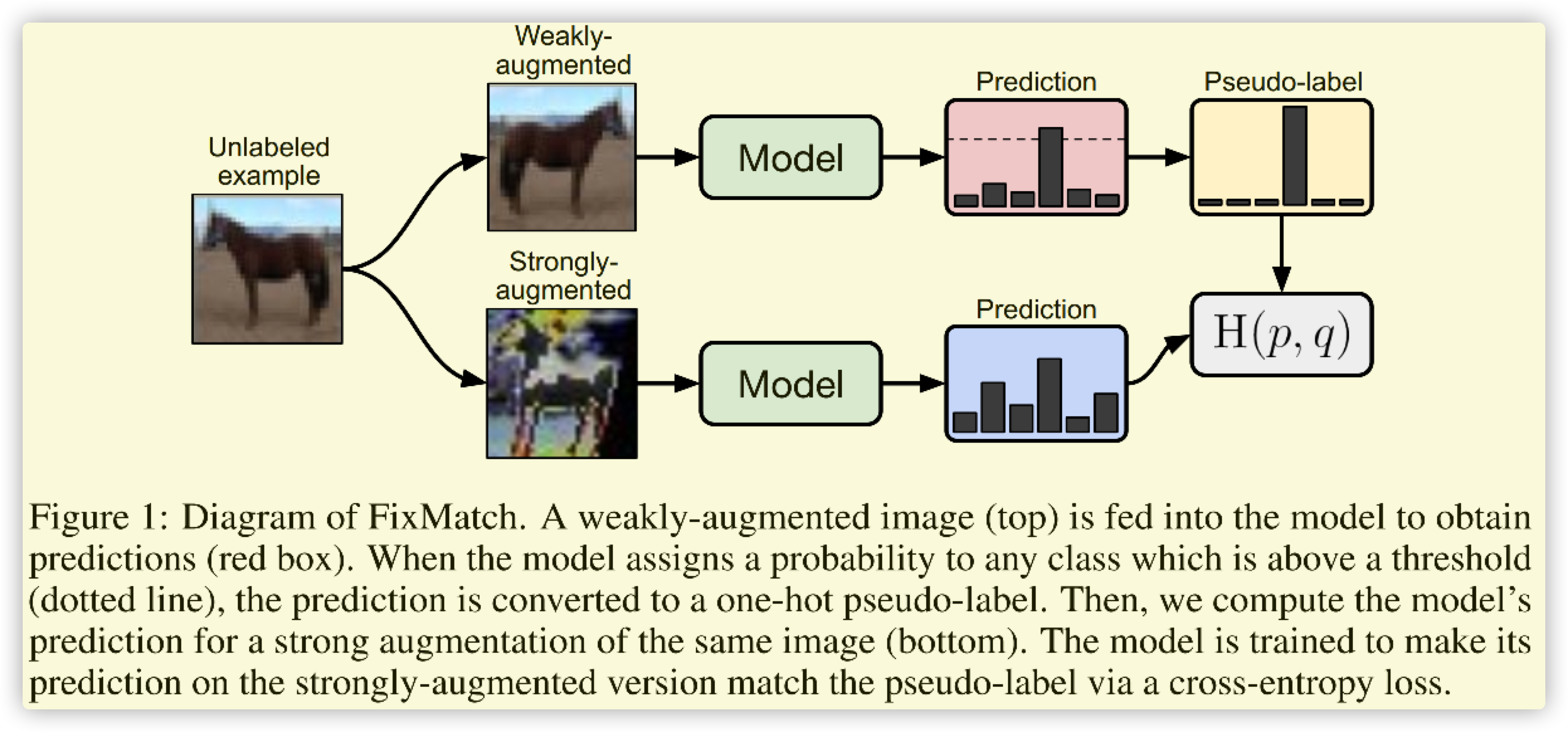
将半监督迁移至目标检测的论文,训练步骤:
使用已标注的数据训练一个大模型\(f_{large}\)
使用这个大模型对未标注数据集进行预测,经过NMS,使用置信度阈值进行过滤,获得\(Pseudo-labeling\)
如果使用数据增强(几何变换),需要将label进行对齐
计算loss即可
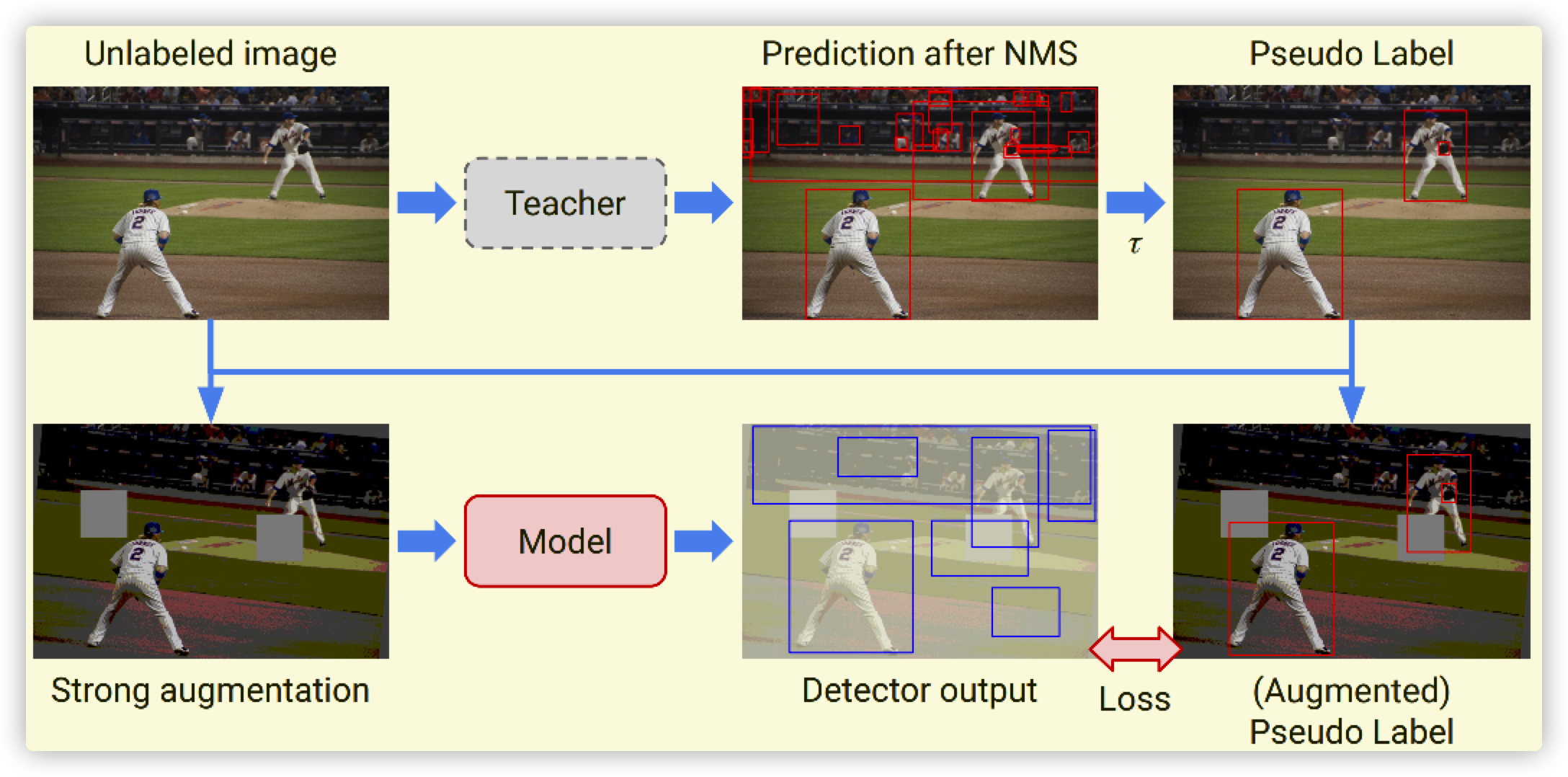
2021最新的半监督目标检测,下面的论文是其中一个模块(Co-rectify)参考论文,以下给出训练步骤:
- 先使用标注图像训练一个大模型,未标注图像直接使用大模型生成(先进行NMS,后面置信度设置一个阈值进行过滤)
- 使用伪标签训练模型\(f_a\) ,其中数据使用弱数据增强(RandomFlip)
- 使用伪标签训练模型\(f_b\),其中数据使用强数据增强(mosaic、mixup等),模型\(f_b\)可以不等于\(f_b\)
- 模型 \(f_a\) 和 \(f_b\) 预测的结果进行联合预测,假设模型\(f_a\)的Head网络为\(head_a\),其他类似。例如模型输入为 \(data\) ,\(out_a = f_a(data),out_a'=f_b(data,out_a)\) 其中\(out_a\)为模型\(f_a\)的直接输出,\(out_a'\)是模型\(f_b\)的Head层输出(相当于RPN的结果)。最后将两个结果进行加权平均即可。
\left(c_{i}, \mathbf{t}_{i}\right) &=f_{a}\left(\mathbf{x}_{u}\right) \\
\left(c_{i}^{r}, \mathbf{t}_{i}^{r}\right) &=f_{b}\left(\mathbf{x}_{u} ; \mathbf{t}_{i}\right), \\
c_{i}^{*} &=\frac{1}{2}\left(c_{i}+c_{i}^{r}\right), \\
\mathbf{t}_{i}^{*} &=\frac{1}{c_{i}+c_{i}^{r}}\left(\mathbf{t}_{i} c_{i}+\mathbf{t}_{i}^{r} c_{i}^{r}\right) .
\end{aligned}\right.
\]
- loss使用下面的函数表示,监督loss和伪监督loss
\ell_{u}=& \sum_{u}\left[\frac{1}{N_{c l s}} \sum_{i} L_{c l s}\left(p\left(c_{i} \mid A\left(\mathbf{x}_{u}\right)\right), \hat{c}_{i}^{u}\right)\right.\\
&\left.+\frac{\lambda}{N_{r e g}} \sum_{i}\left(\max \left(c_{i}^{u}\right) \geq \tau\right) L_{r e g}\left(p\left(\mathbf{t}_{i} \mid A\left(\mathbf{x}_{u}\right)\right), \mathbf{t}_{i}^{u}\right)\right]
\end{aligned}
\]
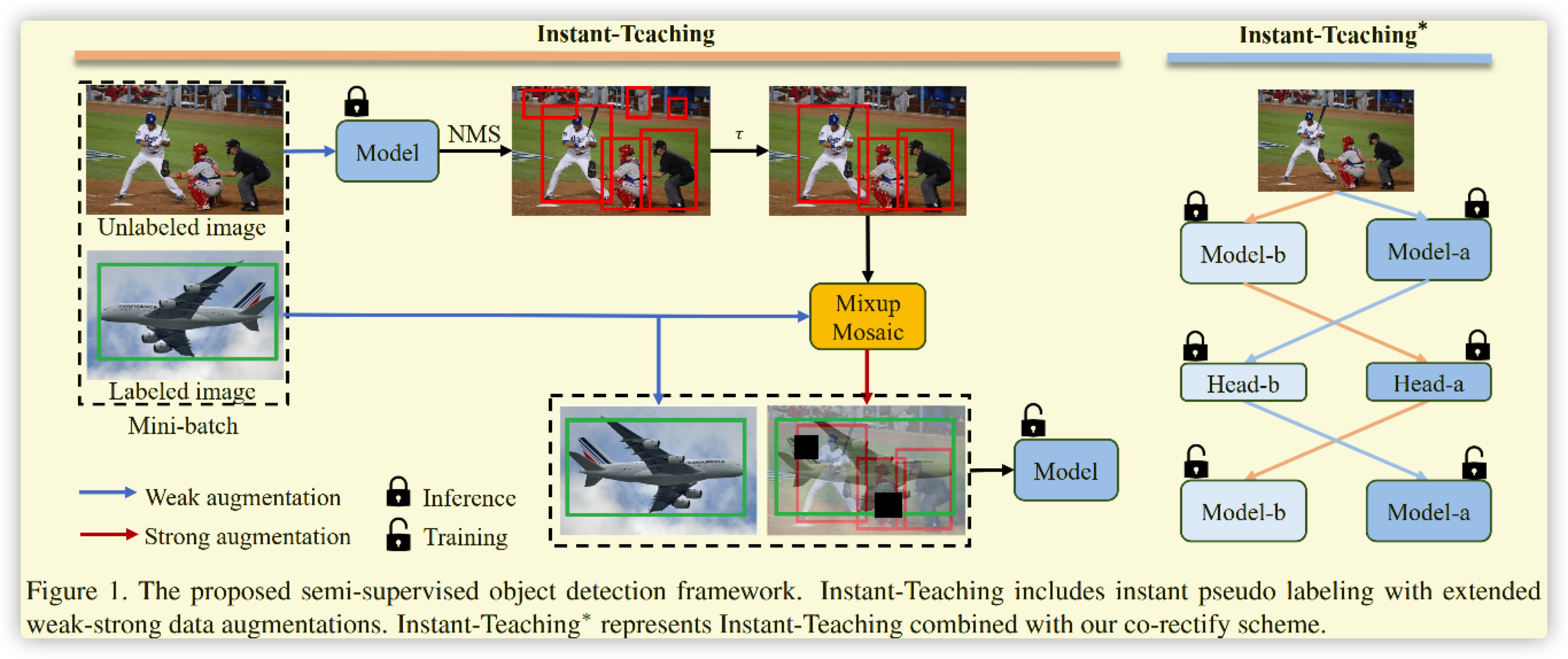
- 总结
由于看到Waymo object detect 2D比赛中有人使用此方案,所以才进行探索一下:第二名方案论文。这里总结一下这个比赛的方案,关于弱监督套路一样,以上三篇论文完全代表其发展进程了。
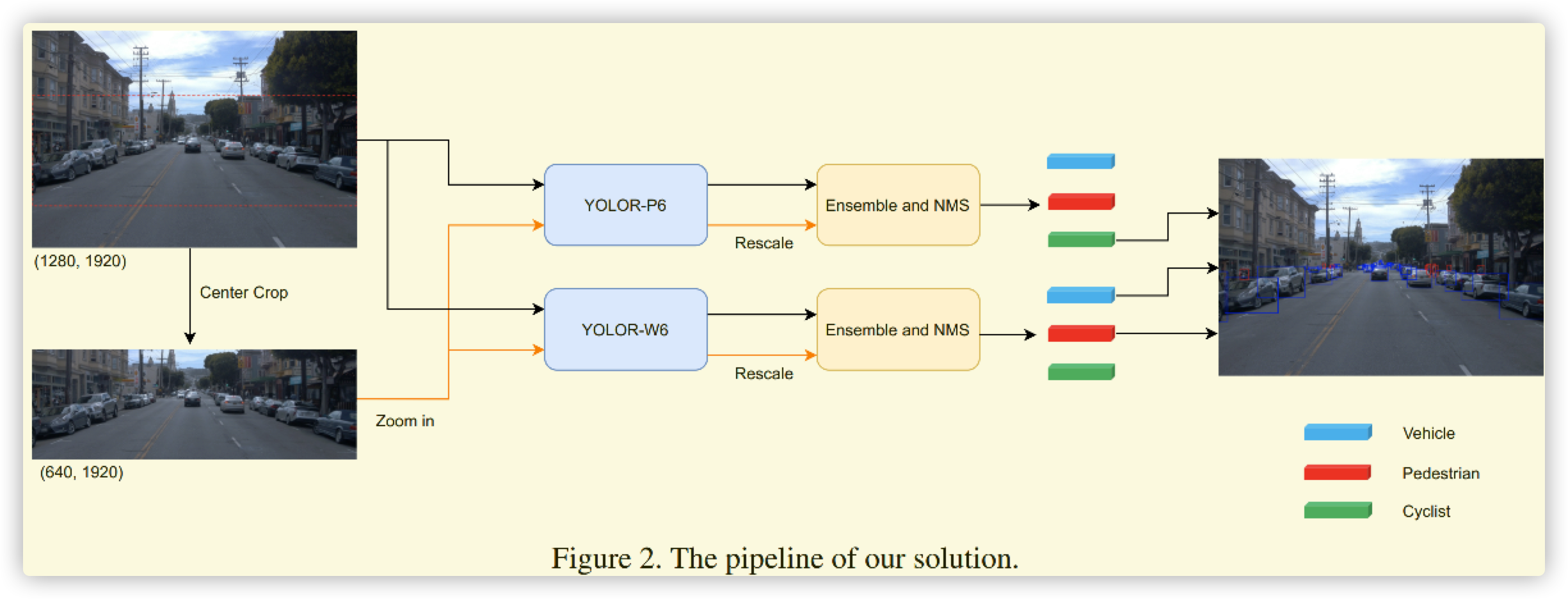
- (基础)将手动标注的图像进行训练,且此模型尽量是大模型(比赛有速度和精度要求,论文使用YoloR)。参赛给的训练数据集
- (基础)将未标注的图像进行伪标注。参赛给的测试集
- (优化)anchor的选择,由于目标差异比较大(自行车和汽车两类bbox分布较为接近、自行车单独计算),和后面模型结合起来分析
- (优化)针对小目标的处理,由于数据在图像中间分布,所以裁剪之后进行放大,提高小目标的出镜率
- (优化)使用TensorRT进行加速
- (优化)针对困难样本(模糊等),使用弱监督的Co-rectify方案,论文里面说是
we learn from the self-learning method which use multi-different models check with each other to automatically clean the dataset during the model training process to solve this problem and improve the model performance.也就仅仅一句话带过,这里后面进行拓展说明。 - (优化)Model Ensemble,多个模型进行投票。这里采用不用模型预测不同目标的方式,YOLOR-W6预测车辆和行人,YOLOR-P6预测自行车。
这里主要说明一下采用的Co-rectify方案(出自Paper),两个结构相同且参数不同的模型YOLOR-W/P,由于是单阶段网络,所以只能直接预测,而不是像原始论文使用Head分支进行。假设模型 \(f_w\) 和 \(f_p\) 预测的结果进行联合预测。如模型输入为 \(data\) ,\(out_w = f_w(data),out_w'=f_b(data)\) 其中\(out_w\)为模型\(f_a\)的直接输出,\(out_w'\)是模型\(f_b\)的输出。直接进行加权平均,会使得模型朝着一个方向学习。如原始论文中原文:
The key to the success of co-rectify is that the two models will not converge to the same model. We take two measures to ensure that the two models converge independently.
First, although the two models have the same structure, they use different initialization parameters. Second, although the two models share the same data in each mini-batch, their data augmentations and pseudo annotations are also different.
虽然说两个模型的参数是不同的,但是此处的目的是去除模糊框,如何做到两个模型就能去除模糊框?
个人猜测是1)模糊框是少数,大量的数据训练本身就能去除这类样本。2)两个型模同时训练,会增加网络的鲁棒性,毕竟每个网络都有自己擅长的点(不同目标的检测精度不同),联合之后各取所长吧。
Waymo object detect 2D解决方案论文拓展的更多相关文章
- ICCV2019论文点评:3D Object Detect疏密度点云三维目标检测
ICCV2019论文点评:3D Object Detect疏密度点云三维目标检测 STD: Sparse-to-Dense 3D Object Detector for Point Cloud 论文链 ...
- Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记
Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记 arXiv 摘要:本文提出了一种 DRL 算法进行单目标跟踪 ...
- Visual Studio 2015打开ASP.NET MVC的View提示"Object reference not set to an instance of an object"错误的解决方案
使用Visual Studio 2013打开没有问题,但Visual Studio 2015打开cshtml就会提示"Object reference not set to an insta ...
- Online Object Tracking: A Benchmark 论文笔记(转)
转自:http://blog.csdn.net/lanbing510/article/details/40411877 有博主翻译了这篇论文:http://blog.csdn.net/roamer_n ...
- CVPR2018 关于视频目标跟踪(Object Tracking)的论文简要分析与总结
本文转自:https://blog.csdn.net/weixin_40645129/article/details/81173088 CVPR2018已公布关于视频目标跟踪的论文简要分析与总结 一, ...
- Online Object Tracking: A Benchmark 论文笔记
Factors that affect the performance of a tracing algorithm 1 Illumination variation 2 Occlusion 3 Ba ...
- Learning Rich Features from RGB-D Images for Object Detection and Segmentation论文笔记
相关工作: 将R-CNN推广到RGB-D图像,引入一种新的编码方式来捕获图像中像素的地心姿态,并且这种新的编码方式比单纯使用深度通道有了明显的改进. 我们建议在每个像素上用三个通道编码深度图像:水平视 ...
- CVPR 2020 全部论文 分类汇总和打包下载
CVPR 2020 共收录 1470篇文章,根据当前的公布情况,人工智能学社整理了以下约100篇,分享给读者. 代码开源情况:详见每篇注释,当前共15篇开源.(持续更新中,可关注了解). 算法主要领域 ...
- CVPR 2020论文收藏(转知乎:https://zhuanlan.zhihu.com/p/112337176)
CVPR 2020 共收录 1470篇文章,根据当前的公布情况,人工智能学社整理了以下约100篇,分享给读者. 代码开源情况:详见每篇注释,当前共15篇开源.(持续更新中,可关注了解). 算法主要领域 ...
随机推荐
- Linux 中如何使用 IP 命令
老版本的 Linux 中都是使用 ifconfig 命令检查和配置网络接口,但是该命令目前已经没有维护了,取而代之的是 ip 命令 ip 命令和 ifconfig 命令很相似,但是 相比起来,ip命令 ...
- JAVA8 lambda表达式权威教程!
Java 8新特性----Stream流 jdk8是Java 语言开发的一个主要版本,它支持函数式编程,新的 JavaScript 引擎,新的日期 API,新的Stream API 等等.今天就重点介 ...
- Zookeeper详细使用解析!分布式架构中的协调服务框架最佳选型实践
Zookeeper概念 Zookeeper是分布式协调服务,用于管理大型主机,在分布式环境中协调和管理服务是很复杂的过程,Zookeeper通过简单的架构和API解决了这个问题 Zookeeper实现 ...
- 一道codeforces题目引发的差分学习
Codeforces Round #688 (Div. 2) 题目:B. Suffix Operations 题意:给定一个长为n的数组a,你可以进行两种操作:1).后缀+1; 2)后缀-1: ...
- C++ primer plus读书笔记——第14章 C++中的代码重用
第14章 C++中的代码重用 1. 使用公有继承时,类可以继承接口,可能还有实现(基类的纯虚函数提供接口,但不提供实现).获得接口是is-a关系的组成部分.而使用组合,类可以获得实现,但不能获得接口. ...
- 如何在Mac OS X中开启VIM语法高亮和显示行号
VIM (Wikipedia图) Vim 是一款相当给力的源自UNIX平台的命令行文本编辑器,不过不给力的是,Mac OS X下并没有诸多Linux发行版上VIM那些牛逼哄哄的神马代码高亮显示啊,自动 ...
- 动态内存:delete作用于空指针
在学习<C++primer 第五版>(中文版)中第12章动态内存与智能指针的时候遇到了一个习题,练习12.13: 练习 12.13:如果执行下面的代码,会发生什么? auto sp=mak ...
- [MySQL数据库之事务、读现象、数据库锁机制、多版本控制MVCC、事务隔离机制]
[MySQL数据库之事务.读现象.数据库锁机制.多版本控制MVCC.事务隔离机制] 事务 1.什么是事务: 事务(Transaction),顾名思义就是要做的或所做的事情,数据库事务指的则是作为单个逻 ...
- TCP 中的两个细节点
TCP 超时和重传 没有永远不出错误的通信,这句话表明着不管外部条件多么完备,永远都会有出错的可能.所以,在 TCP 的正常通信过程中,也会出现错误,这种错误可能是由于数据包丢失引起的,也可能是由于数 ...
- Django/Flask的一些实现方法
一.导出当前项目用到的依赖到requirements.txt文件中 pip freeze > requirements.txt 二.安装当前项目需要的依赖: pip install -r req ...