管中窥豹-ssh链接过多的问题分析及复盘
缘起
某一天,产品侧同事联系过来,反馈话单传输程序报错,现象如下:
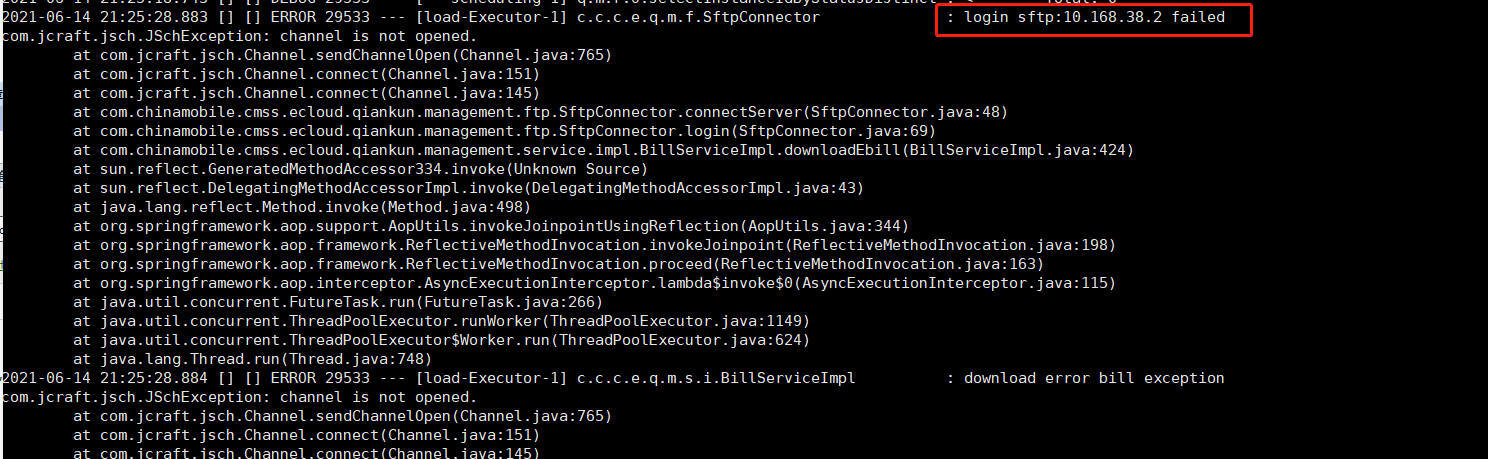
实际上,该节点仅提供了一个sftp服务,供产品侧传输话单过来进行临时存储,由计费部门取走而已。
分析
于是找运维同事上服务器看了下情况,发现有以下几个问题:
ssh进程过高(由于前期给各个部门分配的sftp账号不同,正好可以以账号名辨别来源)

根据以上信息,检查了TCP链接状态,发现绝大多数都是ESTABLISHED连接:
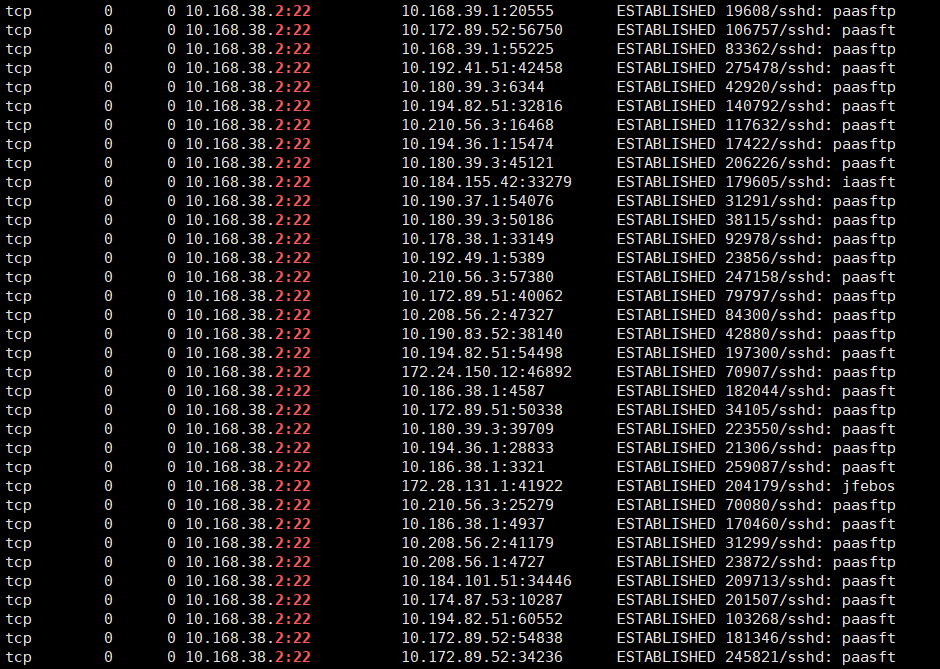
于是统计了一下TCP链接来源
#/bin/bash
for i in `netstat -ant | grep ESTABLISHED | awk '{print $5}' | awk -F: '{print $1}' | sort |uniq`
do
count=`netstat -ant | grep ESTABLISHED | grep $i|wc -l`
if [[ ${count} -ge 30 ]] ;then
echo "$i的连接数是$count"
#else
# continue
fi
done
发现链接主要集中于部分IP:
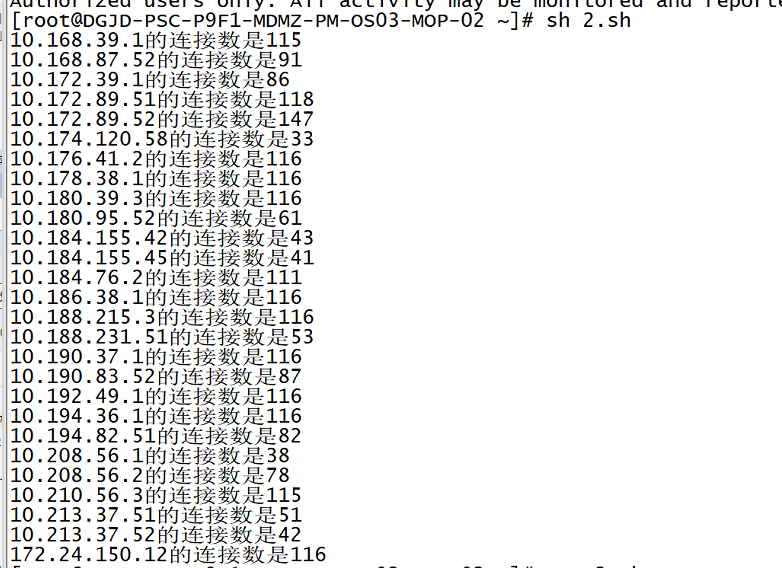
由于链接持续上涨,结合业务场景推测为ssh连接未正常释放的问题引发。
拓展
首先,链接在多天的时间内积攒到几万,并且不进行自动释放,几乎可以断定是由于客户端未释放,原因如下:
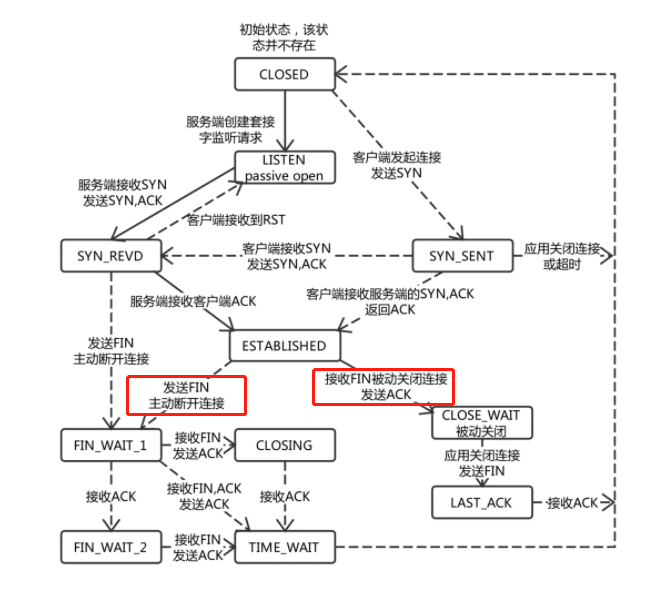
根据TCP请求的状态机,ESTABLISHED状态的链接,只有在发送FIN,或者收到FIN的时候,才会主动断开TCP链接(也就是意味着没有人发FIN);
而假设一种场景,客户端发送了FIN,但服务端因为网络或者某种原因未收到的话,TCP keepalive机制会进行多次探测,将其断开(也就是意味着keepalive机制一直存在响应)。
补充:下一篇将对TCP请求的keepalive机制做一个介绍。
根因
于是组织产品侧进行排查,最终找到原因:
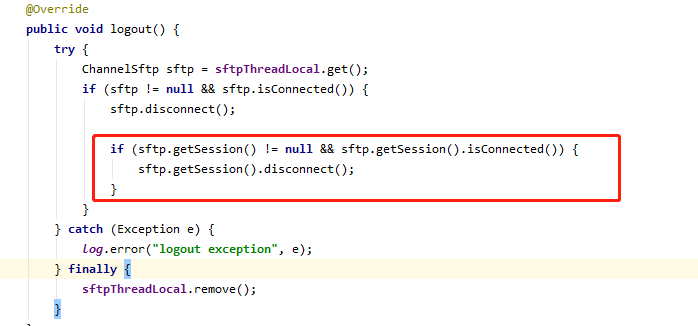
原代码中,在退出sftp任务之后,只关闭了channel,而未关闭对应的session(缺少红框内容)
根据官方example:http://www.jcraft.com/jsch/examples/Sftp.java.html ,最终关闭的应该是session,这样就不会有残留了。

复盘
至此问题解决,那么需要复盘分析了:
前期是否有做过sshd服务的性能限制配置?
经了解,前期为了限制产品侧的链接个数,已经有过配置对应的限制配置:

这里解释下这两个配置:
MaxSessions 1000 限制最大会话个数;
MaxStartups 1000:30:1200 会话个数达到1000之后的链接,有30%几率失败;会话个数达到1200后,全部失败;
可是为何实际生产中连接数达到了几十万都没有释放呢?
经过一番调查最终找到原因:每次登录会在ssh服务新建一个连接,每次代码层面进行sftp操作,会生成一个新的会话/session。
所以这个maxsession,实际上限制的是每一个连接能新建出多少个会话的个数。
对应到各种ssh工具上,有一个复制会话,有一个复制渠道(channel),对应的即是这两个概念。
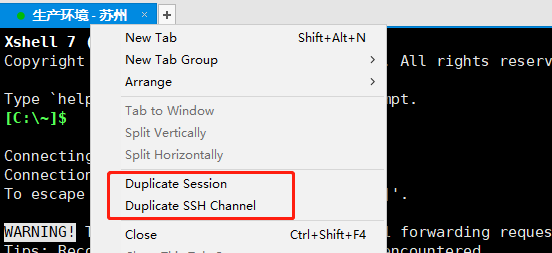
因此配置是存在的,只是没有起到预期的效果。
那么应该如何正确的配置呢?
实际上,在ulimit里面是可以配置针对用户级别的登录连接个数限制的:
/etc/security/limits.conf 文件实际是 Linux PAM(插入式认证模块,Pluggable Authentication Modules)中 pam_limits.so 的配置文件,而且只针对于单个会话。
# /etc/security/limits.conf
#
#This file sets the resource limits for the users logged in via PAM.
该文件为通过PAM登录的用户设置资源限制。
#It does not affect resource limits of the system services.
#它不影响系统服务的资源限制。
#Also note that configuration files in /etc/security/limits.d directory,
#which are read in alphabetical order, override the settings in this
#file in case the domain is the same or more specific.
请注意/etc/security/limits.d下按照字母顺序排列的配置文件会覆盖 /etc/security/limits.conf中的
domain相同的的配置
#That means for example that setting a limit for wildcard domain here
#can be overriden with a wildcard setting in a config file in the
#subdirectory, but a user specific setting here can be overriden only
#with a user specific setting in the subdirectory.
这意味着,例如使用通配符的domain会被子目录中相同的通配符配置所覆盖,但是某一用户的特定配置
只能被字母路中用户的配置所覆盖。其实就是某一用户A如果在/etc/security/limits.conf有配置,当
/etc/security/limits.d子目录下配置文件也有用户A的配置时,那么A中某些配置会被覆盖。最终取的值是 /etc/security/limits.d 下的配置文件的配置。
#
#Each line describes a limit for a user in the form:
#每一行描述一个用户配置,配置格式如下:
#<domain> <type> <item> <value>
#Where:
#<domain> can be:
# - a user name 一个用户名
# - a group name, with @group syntax 用户组格式为@GROUP_NAME
# - the wildcard *, for default entry 默认配置为*,代表所有用户
# - the wildcard %, can be also used with %group syntax,
# for maxlogin limit
#
#<type> can have the two values:
# - "soft" for enforcing the soft limits
# - "hard" for enforcing hard limits
有soft,hard和-,soft指的是当前系统生效的设置值,软限制也可以理解为警告值。
hard表名系统中所能设定的最大值。soft的限制不能比hard限制高,用-表名同时设置了soft和hard的值。
#<item> can be one of the following: <item>可以使以下选项中的一个
# - core - limits the core file size (KB) 限制内核文件的大小。
# - data - max data size (KB) 最大数据大小
# - fsize - maximum filesize (KB) 最大文件大小
# - memlock - max locked-in-memory address space (KB) 最大锁定内存地址空间
# - nofile - max number of open file descriptors 最大打开的文件数(以文件描叙符,file descripter计数)
# - rss - max resident set size (KB) 最大持久设置大小
# - stack - max stack size (KB) 最大栈大小
# - cpu - max CPU time (MIN) 最多CPU占用时间,单位为MIN分钟
# - nproc - max number of processes 进程的最大数目
# - as - address space limit (KB) 地址空间限制
# - maxlogins - max number of logins for this user 此用户允许登录的最大数目
# - maxsyslogins - max number of logins on the system 系统最大同时在线用户数
# - priority - the priority to run user process with 运行用户进程的优先级
# - locks - max number of file locks the user can hold 用户可以持有的文件锁的最大数量
# - sigpending - max number of pending signals
# - msgqueue - max memory used by POSIX message queues (bytes)
# - nice - max nice priority allowed to raise to values: [-20, 19] max nice优先级允许提升到值
# - rtprio - max realtime pr iority
因此解就很明显了,只要在limit中配置
testssh - maxlogins 1
即可,即时生效。
前期是如何测试上线的呢?
此处不作展开,测试工作之重要不容质疑;然而也不能为了测试而测试,上一个小功能就需要把所有的测试run一遍;
个中文章摊开来说恐怕小小篇幅不足讨论。
为何没有提前发现呢?
前期曾做过监控告警的接入,但接入内容仅限于openssh进程消失,22端口丢失的场景;
很显然,此处缺少进程数量,TCP链接数量,端口消耗数量监控;
一言以蔽之,也就是只有1/0监控,没有health/err的监控;
同样是以上的道理,既不能被动等待故障发现后做单个的补充,也不能因为过多细节监控项带来整体运维的复杂度;
因此个人的理解是要加上通用指标的监控项,即监控指标需要反应系统级的普遍问题或者服务级的健康度,落实到ssh服务,建议如下:
进程数量监控(no),TCP链接数量监控(yes,百分比监控),端口消耗数量监控(yes,百分比),ssh服务响应时长拨测(yes,模拟ssh登录及scp操作监控)
管中窥豹-ssh链接过多的问题分析及复盘的更多相关文章
- 使用whiptail写linux字符界面ssh链接工具2.0
先看一下效果 选择分组 选择服务器 开始链接 为什么写 之前写过一个字符界面的链接工具,但是看起来比较简陋,他是这个样子的: 看起来十分不好看.后来在网上看到shell中有一个whiptail工具可以 ...
- 写一个有字符界面的ssh链接工具
大概的样子 这是大致的样子- 写之前想说的 因为个人工作的的电脑是deepin系统的,系统本身的命令行非常好用,用第三方的ssh工具用不习惯,就想自己写一个. shell脚本是第一次写,写的不是很好, ...
- centos7 SSH链接不上
我试了下面的方法不行--(并且也排查了 ssh是正确安装的) [一]关闭selinuxvi /etc/selinux/config 然后reboot重启!!!! [二]关闭防火墙并禁止启动,有能力自己 ...
- Mysql取消SSH链接和恢复SSH链接
取消SSH链接//键入密码,链接上mysql mysql -u root -p USE MYSQL; GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIF ...
- 【问题:SSH】win10使用SSH链接服务器时,提示:Host key verification failed
异常原因:当前连接新建的验证信息与之前保存的验证信息不一致,将原来的验证信息删除就可以了. 1 使用以下命令,清空之前缓存的信息.或者直接打开C:\Users\Nolan\.ssh\known_hos ...
- Python --链接MYSQL数据库与简单操作 含SSH链接
项目是软硬件结合,在缺少设备的情况,需要通过接口来模拟实现与设备的交互,其中就需要通过从数据库读取商品的ID信息 出于安全考虑 现在很多数据库都不允许通过直接访问,大多数是通过SSH SSH : 数 ...
- git的介绍、git的功能特性、git工作流程、git 过滤文件、git多分支管理、远程仓库、把路飞项目传到远程仓库(非空的)、ssh链接远程仓库,协同开发
Git(读音为/gɪt/)是一个开源的分布式版本控制系统,可以有效.高速地处理从很小到非常大的项目版本管理. [1] 也是Linus Torvalds为了帮助管理Linux内核开发而开发的一个开放源码 ...
- 经典!服务端 TCP 连接的 TIME_WAIT 过多问题的分析与解决
开源Linux 专注分享开源技术知识 本文给出一个 TIME_WAIT 状态的 TCP 连接过多的问题的解决思路,非常典型,大家可以好好看看,以后遇到这个问题就不会束手无策了. 问题描述 模拟高并发的 ...
- ssh链接数设置问题
今天碰到一个问题,脚本执行scp文件拷贝,因为拷贝的服务器很多,所以拷贝脚本的实现是在把拷贝动作转后台执行,结果发现一堆文件拷贝失败.比较有迷惑性的是,拷贝失败的通常是同一个文件夹拷贝到所有服务器时失 ...
随机推荐
- js 实现 bind 的这五层,你在第几层?
最近在帮朋友复习 JS 相关的基础知识,遇到不会的问题,她就会来问我. 这不是很简单?三下五除二,分分钟解决. function bind(fn, obj, ...arr) { return fn.a ...
- 找大于等于一个数的最小的2^n
最近看hashmap源码时,发现给定初始capacity计算threshold的过程很巧妙. 1 static final int tableSizeFor(int cap) { 2 int n = ...
- UA: Literally Vulnerable靶机
前言 略有点虎头蛇尾.主要有一步没想通. web打点 nmap -sP 192.168.218.0/24 #发现主机IP 192.168.218.138 #端口扫描 nmap -sV -p- 192. ...
- 『政善治』Postman工具 — 11、Postman中对Cookie的操作
目录 1.关联接口说明 2.测试关联接口实现步骤 3.补充:Postman中将请求转换成代码 上一篇文章说明了Postman中关于Cookie的相关操作,还是以Cookie举例,来说明下一在Postm ...
- mysql基本命令(增,查,改,删)
from oldboy egon
- shell脚本 在后台执行de 命令 >> 文件 2>&1 将标准输出与错误输出共同写入到文件中(追加到原有内容的后面)
命令 >> 文件 2>&1或命令 &>> 文件 将标准输出与错误输出共同写入到文件中(追加到原有内容的后面) # ll >>aaa 2> ...
- JQuery.Gantt开发指南(转)
说明 日前需要用到甘特图,以下转载内容源自网络. • 概述 1.JQuery.Gantt是一个开源的基于JQuery库的用于实现甘特图效果的可扩展功能的JS组件库. •前端页面 o 资源引用 首先我们 ...
- 如何正确地使用RecyclerView.ListAdapter
默认是在一个fragment中实现RecyclerView. private inner class CrimeAdapter() : ListAdapter<Crime, CrimeHolde ...
- python 匹配中文字符
参考: http://hi.baidu.com/nivrrex/blog/item/e6ccaf511d0926888d543071.html http://topic.csdn. ...
- idea-创建web.xml模板
web.xml <?xml version="1.0" encoding="UTF-8"?> <web-app xmlns="htt ...