进程控制fork与vfork
1. 进程标识符
在前面进程描述一章节里已经介绍过进程的两个基本标识符pid和ppid,现在将详细介绍进程的其他标识符。每个进程都有非负的整形表示唯一的进程ID。一个进程终止后,其进程ID就可以再次使用了。如下是一个典型进程的ID及其类型和功能。
进程名:swapper (交换进程),进程ID:0,类型:系统进程,作用:它是内核的一部分,不执行磁盘上的程序,是调度进程。
进程名:init(init进程),进程ID:1,类型:用户进程 ,作用:永远不会终止,启动系统,读取系统初始化的文件。
进程名:pagedaemon(页精灵进程),进程ID:2 ,类型:系统进程,作用:虚存系统的请页操作。
除了进程ID,每个进程还有一些其他的标识符。下列函数返回这些标识符:
#include <sys/types.h>
#include <unistd.h>
pid_t getpid(void); //返回值:调用进程的进程ID
pid_t getppid(void); //返回值:调用进程的父进程ID
uid_t getuid(void); //返回值:调用进程的实际用户ID
uid_t geteuid(void); //返回值:调用进程的有效用户ID
gid_t getgid(void); //返回值:调用进程的实际组ID
gid_t getegid(void); //返回值:调用进程的有效组ID
以上6个函数,如果执行成功,则返回对应的ID值;失败,则返回-1。除了进程ID和父进程ID这两个值不能够更改以外,其他的4个ID值在适当的条件下可以被更改。下面的示例程序用于获取当前进程的6个ID值并打印出来。我们通过代码来实际看看:
#include <stdio.h>
#include <unistd.h>
#include <errno.h>
#include <stdlib.h>
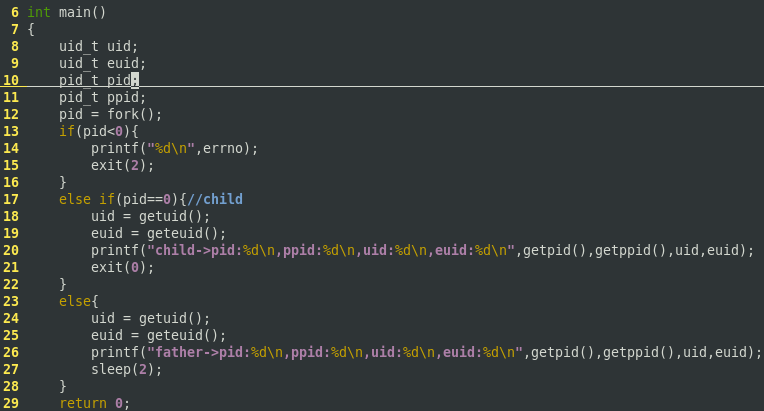
int main()
{
uid_t uid;
uid_t euid;
pid_t pid;
pid_t ppid;
pid = fork();
if(pid < )
{
printf("%d\n",errno);
exit();
}
else if(pid == ){ //child
uid = getuid();
euid = geteuid();
printf("child -> pid: %d, ppid : %d ,uid : %d, euid : %d\n",getpid(),getppid(),uid, euid);
exit();
}
else{
uid = getuid();
euid = geteuid();
printf("father -> pid: %d, ppid : %d ,uid : %d, euid : %d\n",getpid(),getppid(),uid, euid);
sleep();
}
return ;
}
 程序运行效果如下:
程序运行效果如下:

2. 实际用户和有效用户
(1)实际用户ID和实际用户组ID:标识我是谁。也就是登录用户的uid和gid,比如我的Linux以admin登录,在Linux运行的所有的命令的实际用户ID都是admin的uid,实际用户组ID都是admin的gid(可以用id命令查看)。

(2)有效用户ID和有效用户组ID:进程用来决定我们对资源的访问权限。一般情况下,有效用户ID等于实际用户ID,有效用户组ID等于实际用户组ID。当设置-用户-ID(SUID)位设置,则有效用户ID等于文件的所有者的uid,而不是实际用户ID;同样,如果设置了设置-用户组-ID(SGID)位,则有效用户组ID等于文件所有者的gid,而不是实际用户组ID。其中, 实际用户ID/实际组ID标识进程究竟是谁(即是进程在系统的唯一标识),有效用户ID/有效组ID/附加组ID决定了进程的访问权限。
suid (chmod u+s file)只能应用在可执行文件上,允许任意用户在执行文件时以文件拥有者的身份执行;
sgid (chmod g+s file)只能应用在可执行文件上,使任意用户在执行可执行文件时,将以拥有组成员的身份执行;
说明: suid 和 sgid 表示在bin在运行时,会具有拥有者的权限,换句话说,只要运行该可执行程序,那么运行者也是有权限对拥有者的所有相关文件(可执行程序会读写)
进行操作。验证代码:
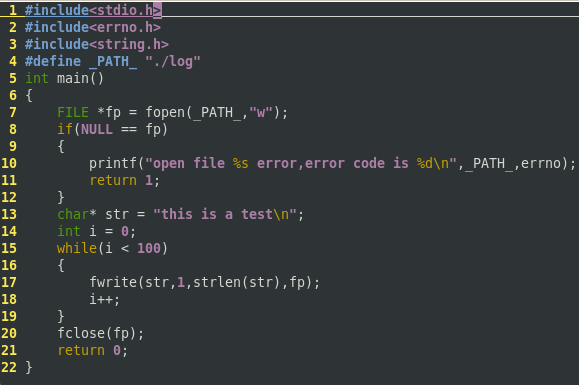
#include <stdio.h>
#include <errno.h>
#include <string.h>
#define _PATH_ "./log"
int main()
{
FILE *fp = fopen(_PATH_, "w");
if( NULL == fp ){
printf("open file is error, error code is : %d\n",_PATH_, errno);
return ;
}
char *str = "this is a test\n";
int i=;
while( i< ){
fwrite(str, , strlen(str),fp);
i++;
}
fclose(fp);
return ;
}
3. 进程创建
3.1 fork()函数创建进程
前面进程描述一节里简单介绍过进程的创建,分别通过fork()和execve()函数创建子进程,这里再进一步深入探讨有关fork()创建子进程的问题。一个现有进程可以调用fork创建一个新进程。返回值: 子进程中返回0,父进程中返回子进程ID,出错返回-1。如下:
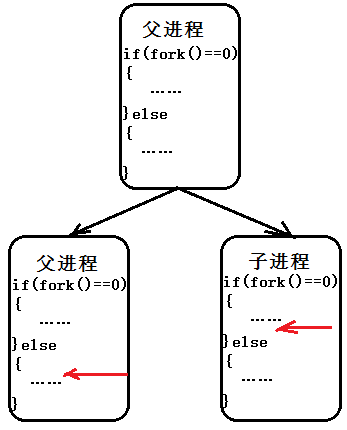
子进程是父进程的副本。例如:子进程获得父进程数据空间、堆和栈的副本(主要是数据结构的副本)。 父子进程不共享这些存储空间部分。父子进程共享正文段。由于fork之后经常归属exec,所以现在很多实现并不执行一个父进程数据段、栈和堆的完全复制。作为替代,使用了写时复制(Copy-On-Write)技术。这些区域由父子进程共享,而且内核将他们的访问权限改变为只读的。如果父子进程中的任意个试图修改这些区域,则内核只为修改区域的那块内存制作一个副本。
下面的程序演示了fork函数,从中可以看出子进程对变量所作的改变并不去影响父进程中该变量的值。
#include <unistd.h>
#include <stdio.h>
int glob = ; /* externalvariable in initialized data */
char buf[] = "a write to stdout\n";
int main(void)
{
int var; /* automatic variable on the stack */
pid_t pid;
var = ;
if (write(STDOUT_FILENO, buf, sizeof(buf)-) != sizeof(buf)-)
perror("write error");
printf("before fork\n"); /* we don't flush stdout */
if ((pid = fork()) < )
{
perror("fork error");
}
else if (pid == ) { /* child */
glob++; /* modifyvariables */
var++;
}
else {
sleep(); /* parent*/
}
printf("pid = %d, glob = %d, var = %d\n", getpid(), glob,var);
exit();
}
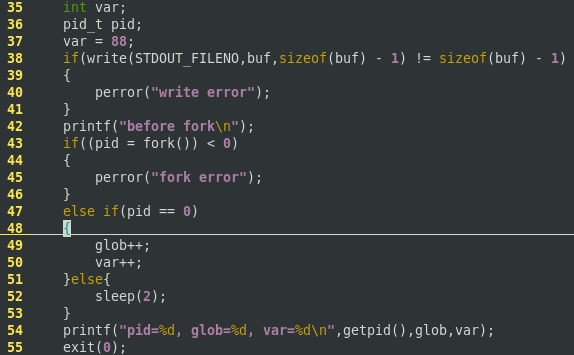
执行及输出结果:

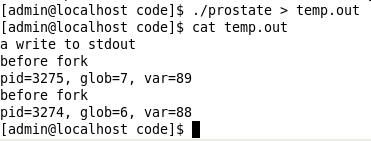
一般来说fork之后父进程和子进程的执行顺序是不确定的,这取决于内核的调度算法。在上面的程序中,父进程是自己休眠2秒钟,以使子进程先执行。程序中fork与I/O函数之间的关系: write是不带缓冲 的(http://blog.sina.com.cn/s/blog_6fb9dec201017tk3.html),因为在fork之前调用write,所以其数据只写到标准输出一次。标准I/O是缓冲的,如果标准输出到终端设备,则它是行缓冲,否则它是全缓冲。当以交互方式运行该程序时,只得到printf输出的行一次, 因为标准输出到终端缓冲区由换行符冲洗。但将标准输出重定向到一个文件时,由于缓冲区是全缓冲,遇到换行符不输出,当调用fork时,其printf的数据仍然在缓冲区中,该数据将被复制到子进程中,该缓冲区也被复制到子进程中。于是父子进程的都有了带改行内容的标准I/O缓冲区,所以每个进程终止时,会冲洗其缓冲区中的数据,得到第一个printf输出两次。
3.2 fork的文件共享特性
fork的一个特性是父进程的所有打开文件描述符都被复制到子进程中。父子进程每个相同的文件描述符共享一个文件表项。假设一个进程有三个不同的打开文件,在从fork返回时,我们有如下所示结构:
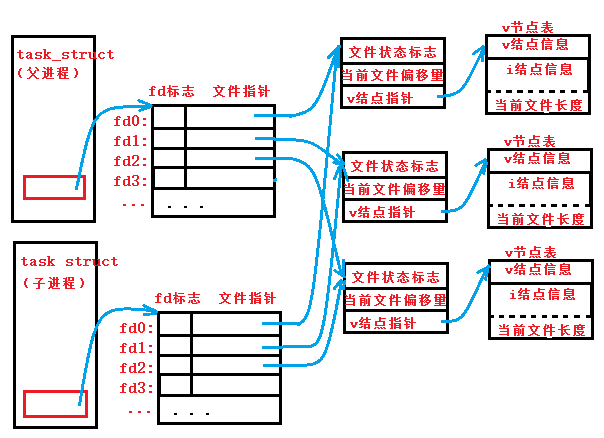
在fork之后处理的文件描述符有两种常见的情况:
1. 父进程等待子进程完成。在这种情况下,父进程不需对其描述符做任何处理。当子进程终止后,子进程对文件偏移量的修改会更新到父进程。
2. 父子进程各各执行不同的程序段。(即子进程exec之后)这种情况下,在fork之后,父子进程各自关闭他们不需要使用的文件描述符,这样就不会干扰对方使用文件描述符。 这种方法在联络服务进程中经常使用。
父子进程之间的区别:
1. fork的返回值;
2. 进程ID不同;
3. 具有不同的父进程ID;
4. 子进程的tms_utime、 tms_stime、 tms_cutime及tms_ustime均被设置为0;
5. 父进程设置的文件锁不会被子进程继承;
6. 子进程的未处理闹钟被清除;
7. 子进程的未处理信号集被设置为空集。
fork有下面两种方法:
1. 一个父进程希望复制自己,使父子进程同时执行不同的代码段。例如,父进程等待客户端请求,生成子进程来处理请求。
2. 一个进程要执行一个不同的程序。例如子进程从fork返回后,调用exec函数。
fork调用失败的原因:
1. 系统中有太多的进程;
2. 实际用户的进程数超过了限制。
3.3 vfork函数
vfork用于创建一个新进程,且该新进程的目的是exec一个新程序。 vfork与fork都创建一个新进程,但vfork不将新进程的地址空间复制到子进程中,因为子进程会立即调用exec,于是不会存访问该地址空间。在子进程调用exec或exit之前,它在父进程的空间中运行,也就是说会更改父进程的数据段、栈和堆。 vfork和fork另一区别在于: vfork保证子进程先运行,在它调用exec或exit(这里不能使用return,原因见http://coolshell.cn/articles/12103.html)之后父进程才可能被调度运用。
下面是vfork的使用程序:
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <stdlib.h>
int g_val = ;
void fun()
{
printf("child exit\n");
}
int main()
{
int _val = ;
pid_t id = vfork();
if( id < ){
exit();
}
else if( id == ){ //child
atexit(fun);
printf("this is child process.\n");
// ++g_val; //验证第⼀点不同
// ++_val;
sleep();
exit();
}
else{
printf("this is father process\n");
//printf(“father exit, g_val = %d, _val = %d\n",g_val, _val);
}
return ;
}
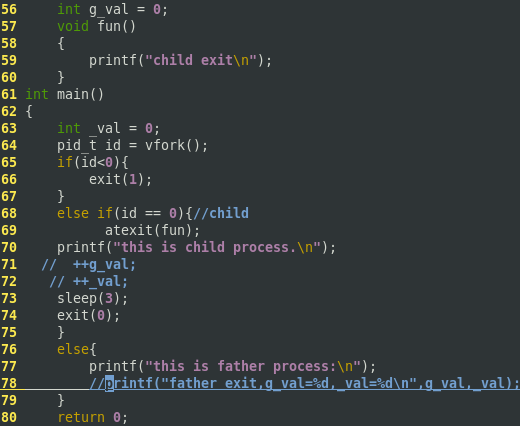

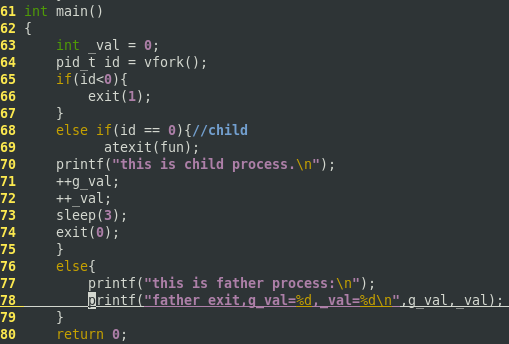

可见子进程直接改变了父进程的变量值,因为子进程在父进程的地址空间中运行。
进程控制fork与vfork的更多相关文章
- APUE学习之进程控制 - fork 与 vfork
最后编辑: 2019-11-6 版本: gcc version 5.4.0 20160609 (Ubuntu 5.4.0-6ubuntu1~16.04.11) 一.进程标识 每一个进程都有一个唯一的非 ...
- 进程控制fork vfork,父子进程,vfork保证子进程先运行
主要函数: fork 用于创建一个新进程 exit 用于终止进程 exec 用于执行一个程序 wait 将父进程挂起,等待子进程结束 getpid 获取当前进程的进程ID nice 改变进程的优先级 ...
- APUE8进程控制 fork vfork exec
- linux系统编程:进程控制(fork)
在linux中,用fork来创建一个子进程,该函数有如下特点: 1)执行一次,返回2次,它在父进程中的返回值是子进程的 PID,在子进程中的返回值是 0.子进程想要获得父进程的 PID 需要调用 ge ...
- UNIX高级环境编程(9)进程控制(Process Control)- fork,vfork,僵尸进程,wait和waitpid
本章包含内容有: 创建新进程 程序执行(program execution) 进程终止(process termination) 进程的各种ID 1 进程标识符(Process Identifie ...
- 进程创建函数fork()、vfork() ,以及excel()函数
一.进程的创建步骤以及创建函数的介绍 1.使用fork()或者vfork()函数创建新的进程 2.条用exec函数族修改创建的进程.使用fork()创建出来的进程是当前进程的完全复制,然而我们创建进程 ...
- linux 进程创建clone、fork与vfork
目录: 1.clone.fork与vfork介绍 2.fork说明 3.vfork说明 4.clone说明5.fork,vfork,clone的区别 内容: 1.clone.fork与vfork介绍 ...
- 1.2 Linux中的进程 --- fork、vfork、exec函数族、进程退出方式、守护进程等分析
fork和vfork分析: 在fork还没有实现copy on write之前,Unix设计者很关心fork之后立即执行exec所造成的地址空间浪费,也就是拷贝进程地址空间时的效率问题,所以引入vfo ...
- 进程控制之fork函数
一个现有进程可以调用fork函数创建一个新进程. #include <unistd.h> pid_t fork( void ); 返回值:子进程中返回0,父进程中返回子进程ID,出错返回- ...
随机推荐
- 记一些让footer始终位于网页底部的方法
上次说把网页的头部和尾部分离出来作为一个单独的文件,所有网页共用,这样比较方便修改,然而,,,我发现某些方法里尾部会紧跟在头部后面,把内容挤在下面..而且有的页面内容少的话不能把尾部挤到最下面,所以, ...
- 没有理由,就是要上一波C++的东西
从入门开始,一直在用C , 对于C++可谓是一窍不通,只能是勉强看懂C++的代码,至于写更是连头文件什么iostream是什么我都不知道,更不用说什么using namespace std :之类的东 ...
- Linux基础测试--11道题
000.创建一个目录/data mkdir /data 001.在/data 下面创建一个文件oldboy.txt touch /data/oldboy.txt 002.为oldboy.txt 增加内 ...
- jquery 模态窗口 蒙层无法覆盖flash解决办法
在应用swf的<object></object>标签中加入如下属性: <param name="wmode" value="transpar ...
- highcharts的多级下钻以及图形形态转换
<script src="https://img.hcharts.cn/jquery/jquery-1.8.3.min.js"></script> < ...
- [刷题]算法竞赛入门经典(第2版) 4-7/UVa509 - RAID!
书上具体所有题目:http://pan.baidu.com/s/1hssH0KO 代码:(Accepted,0 ms) //UVa509 - RAID! #include<iostream> ...
- Windows下安装Nodejs步骤
最近打算把我们的微信端用Vue.js重构,为什么选择Vue.js,一是之前使用的是传统的asp.net mvc,多页面应用用户体验比单页面要差.二是使用过Angular.js,感觉对开发人员要求较 ...
- 每天一道Java题[7]
题目 什么是REST原则,请解释RESTful架构,以及其设计思想? 解答 REST,全称为Representation State Transfer,是一种互联网软件的架构原则.凡是满足REST原则 ...
- 同步文件的利器-rsync
即使你只是个人用户而不是一个企业,备份你自己的数据也是非常重要的,我不想失去任何这些数据. rsync是同步文件的利器,一般用于多个机器之间的文件同步与备份,同时也支持在本地的不同目录之间互相同步文件 ...
- phpmyadmin上传sql文件大小限制问题解决方案
近几天在学生做项目时,需要使用phpmyadmin把本地数据库导入到线上数据库,有许多学生遇到了因为文件过大而上传失败的问题.今天给大家整理一下使用phpmyadmin遇到因为文件过大而导致上传失败问 ...