JAVA爬虫实践(实践一:知乎)
爬虫顺序
1.分析网站网络请求
通过浏览器F12开发者工具查看网站的内容获取方式。
2.模拟HTTP请求,获取网页内容。
可以采用HttpClient,利用JAVA HttpClient工具可以模拟HTTP GET、POST请求,可以用来获取爬虫需要的数据。JAVA的一些爬虫框架底层用到的获取网页方式也都是HttpClient。
3.解析网页HTML内容,获取可用数据和下一条请求链接。
可以采用jsoup、正则表达式、xpath等。
实践一:知乎


查看开发者工具可以看到知乎首页的内容获取有两种:
一种是GET请求,请求地址为https://www.zhihu.com/
一种是POST请求,请求地址为https://www.zhihu.com/node/TopStory2FeedList
第一种GET请求即现实中用户直接从浏览器地址栏输入知乎的网址或点击链接进行请求,这时知乎会响应返回一个只有数条内容的首页给用户。
第二种POST请求即现实中用户向下滚动页面,浏览器持续加载新内容。
第一种GET请求没有参数,响应也是HTML,较为简单。
第二种POST请求可以在开发者工具中查看它的参数和响应。
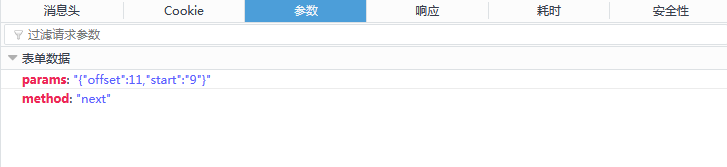
可以看到有两个请求参数
params:"{"offset":21,"start":"19"}"
method:"next"
响应为一段JSON,我们要的是下面的msg数组,所以代码中会用到json-lib这个jar包方便我们解析json。
分析完网站的网络请求后就可以进行下一步,模拟HTTP请求
首先模拟GET请求
public String doGet() throws ClientProtocolException, IOException {
String str = "";
// 创建HttpClient实例
HttpClient httpClient = new DefaultHttpClient();
// 创建Get方法实例
HttpUriRequest httpUriRequest = new HttpGet("http://www.zhihu.com");
// 添加必要的头信息
httpUriRequest.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0");
httpUriRequest.setHeader("Cookie", "这里的Cookie拷贝复制登录后请求头里的Cookie值");
httpUriRequest.setHeader("DNT", "1");
httpUriRequest.setHeader("Connection", "keep-alive");
httpUriRequest.setHeader("Upgrade-Insecure-Requests", "1");
httpUriRequest.setHeader("Cache-Control", "max-age=0");
HttpResponse response = httpClient.execute(httpUriRequest);
HttpEntity entity = response.getEntity();
if (entity != null) {
InputStream inputStream = entity.getContent();
str = convertStreamToString(inputStream);
}
return str;
}
convertStreamToString为一个将流转换为字符串的方法
public static String convertStreamToString(InputStream is)
throws IOException { InputStreamReader ir = new InputStreamReader(is, "UTF8"); BufferedReader reader = new BufferedReader(ir); StringBuilder sb = new StringBuilder(); String line = null;
try {
while ((line = reader.readLine()) != null) {
sb.append(line + "\n");
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return sb.toString();
}
模拟POST请求(两个参数即为请求参数里的两个变量)
public String doPost(int offset, int start) throws Exception {
HttpClient httpClient = new DefaultHttpClient();
HttpUriRequest httpUriRequest = RequestBuilder
.post()
.setUri("https://www.zhihu.com/node/TopStory2FeedList")
.addParameter("params", "{\"offset\":" + offset + ",\"start\":\"" + start + "\"}").addParameter("method", "next").build();
// 添加必要的头信息
httpUriRequest.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0");
httpUriRequest.setHeader("X-Xsrftoken", "这里的X-Xsrftoken拷贝复制登录后请求头里的X-Xsrftoken值");
httpUriRequest.setHeader("X-Requested-With", "XMLHttpRequest");
httpUriRequest.setHeader("Referer", "https://www.zhihu.com/");
httpUriRequest.setHeader("Cookie", "这里的Cookie拷贝复制登录后请求头里的Cookie值");
httpUriRequest.setHeader("DNT", "1");
httpUriRequest.setHeader("Connection", "keep-alive");
httpUriRequest.setHeader("Cache-Control", "max-age=0");
HttpResponse response = httpClient.execute(httpUriRequest);
String str = "";
HttpEntity entity = response.getEntity();
if (entity != null) {
InputStream instreams = entity.getContent();
str = convertStreamToString(instreams);
}
return str;
}
最后走一波main方法将数据保存至TXT文件中,在这之前要提取一下HTML中的数据
根据HTML解析数据
这里用到的Document Elements Element 都是jsoup里的元素
这段代码首先拿到到类名为feed-item-inner的HTML元素
变量所有feed-item-inner拿到类名为feed-title的标题和标签类型为textarea的内容
public String unparsedData(String html) {
Document doc = Jsoup.parse(html);
Elements feeds = doc.getElementsByAttributeValue("class", "feed-item-inner");
String writeStr = "";
for (Element feed : feeds) {
Elements title = new Elements();
Elements feedTitles = feed.getElementsByAttributeValue("class", "feed-title");
for (Element feedTitle : feedTitles) {
title = feedTitle.getElementsByTag("a");
}
Elements content = feed.getElementsByTag("textarea");
String titleHref = title.attr("href");
String titleText = title.text().trim();
String contentText = content.text().trim();
// if(!titleText.contains("人民的名义")){
// continue;
// }
System.out.println("--------------------");
System.out.println("-----标题-----");
System.out.println("链接:" + titleHref);
System.out.println("内容:" + titleText);
System.out.println("-----内容-----");
System.out.println("内容:" + contentText);
System.out.println("--------------------");
writeStr += "--------------------\n-----标题-----\n" + titleHref
+ "\n" + titleText + "\n-----内容-----\n" + contentText
+ "\n--------------------\n\n\n";
}
return writeStr;
}
最后Main方法
public void downloadFile() throws Exception {
// 模拟HTTP GET请求
String responseBody = doGet();
// 解析数据
String writeStr = unparsedData(responseBody);
// 创建新文件
String path = "D:\\testFile\\zhihu.txt";
PrintWriter printWriter = null;
printWriter = new PrintWriter(new FileWriter(new File(path)));
// 写内容
printWriter.write(writeStr);
printWriter.close();
int offset = 10;
int start = 9;
for (int time = 0; time <= 100; time++) {
// 模拟POST请求
JSONObject jsonObject = JSONObject.fromObject(doPost(offset, start));
// 解析数据(只拿JSON数据里的msg数组)
String addWriteStr = "";
JSONArray jsonArray = jsonObject.getJSONArray("msg");
Object[] arrays = jsonArray.toArray();
for (Object array : arrays) {
addWriteStr += unparsedData(array.toString());
}
// 追加文本
printWriter = new PrintWriter(new FileWriter(path, true));
printWriter.write(addWriteStr);
printWriter.close();
// 延时,调整参数
Thread.currentThread().sleep(1000);// 毫秒
offset = offset + 10;
start = start + 10;
}
}
完整代码
package spider; import java.io.BufferedReader;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.PrintWriter; import net.sf.json.JSONArray;
import net.sf.json.JSONObject; import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpUriRequest;
import org.apache.http.client.methods.RequestBuilder;
import org.apache.http.impl.client.DefaultHttpClient;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.junit.Test; @SuppressWarnings("deprecation")
public class ZhihuSpider { /**
* 模拟HTTP GET请求
*/
public String doGet() throws ClientProtocolException, IOException {
String str = "";
// 创建HttpClient实例
HttpClient httpClient = new DefaultHttpClient();
// 创建Get方法实例
HttpUriRequest httpUriRequest = new HttpGet("http://www.zhihu.com");
// 添加必要的头信息
httpUriRequest
.setHeader("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0");
httpUriRequest
.setHeader(
"Cookie",
"这里的Cookie拷贝复制登录后请求头里的Cookie值");
httpUriRequest.setHeader("DNT", "1");
httpUriRequest.setHeader("Connection", "keep-alive");
httpUriRequest.setHeader("Upgrade-Insecure-Requests", "1");
httpUriRequest.setHeader("Cache-Control", "max-age=0"); HttpResponse response = httpClient.execute(httpUriRequest); HttpEntity entity = response.getEntity();
if (entity != null) {
InputStream inputStream = entity.getContent();
str = convertStreamToString(inputStream);
}
return str;
} public static String convertStreamToString(InputStream is)
throws IOException { InputStreamReader ir = new InputStreamReader(is, "UTF8"); BufferedReader reader = new BufferedReader(ir); StringBuilder sb = new StringBuilder(); String line = null;
try {
while ((line = reader.readLine()) != null) {
sb.append(line + "\n");
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return sb.toString();
} // 下载 URL 指向的网页
@SuppressWarnings("static-access")
@Test
public void downloadFile() throws Exception {
// 模拟HTTP GET请求
String responseBody = doGet();
// 解析数据
String writeStr = unparsedData(responseBody);
// 创建新文件
String path = "D:\\testFile\\zhihu.txt";
PrintWriter printWriter = null;
printWriter = new PrintWriter(new FileWriter(new File(path)));
// 写内容
printWriter.write(writeStr);
printWriter.close();
int offset = 10;
int start = 9;
for (int time = 0; time <= 100; time++) {
// 模拟POST请求
JSONObject jsonObject = JSONObject
.fromObject(doPost(offset, start));
// 解析数据(只拿JSON数据里的msg数组)
String addWriteStr = "";
JSONArray jsonArray = jsonObject.getJSONArray("msg");
Object[] arrays = jsonArray.toArray();
for (Object array : arrays) {
addWriteStr += unparsedData(array.toString());
}
// 追加文本
printWriter = new PrintWriter(new FileWriter(path, true));
printWriter.write(addWriteStr);
printWriter.close();
// 延时,调整参数
Thread.currentThread().sleep(1000);// 毫秒
offset = offset + 10;
start = start + 10;
}
} /**
* 根据HTML解析数据
*
* @param html
* 源HTML
* @return 解析后的数据
*/
public String unparsedData(String html) {
Document doc = Jsoup.parse(html);
Elements feeds = doc.getElementsByAttributeValue("class",
"feed-item-inner");
String writeStr = "";
for (Element feed : feeds) {
Elements title = new Elements();
Elements feedTitles = feed.getElementsByAttributeValue("class",
"feed-title");
for (Element feedTitle : feedTitles) {
title = feedTitle.getElementsByTag("a");
}
Elements content = feed.getElementsByTag("textarea"); String titleHref = title.attr("href");
String titleText = title.text().trim();
String contentText = content.text().trim();
// if(!titleText.contains("人民的名义")){
// continue;
// } System.out.println("--------------------");
System.out.println("-----标题-----");
System.out.println("链接:" + titleHref);
System.out.println("内容:" + titleText);
System.out.println("-----内容-----");
System.out.println("内容:" + contentText);
System.out.println("--------------------"); writeStr += "--------------------\n-----标题-----\n" + titleHref
+ "\n" + titleText + "\n-----内容-----\n" + contentText
+ "\n--------------------\n\n\n";
}
return writeStr;
} /**
* 模拟HTTP POST请求
*
* @param offset
* 参数offset
* @param start
* 参数start
* @return 请求返回的JSON数据
*/
public String doPost(int offset, int start) throws Exception {
HttpClient httpClient = new DefaultHttpClient();
HttpUriRequest httpUriRequest = RequestBuilder
.post()
.setUri("https://www.zhihu.com/node/TopStory2FeedList")
.addParameter(
"params",
"{\"offset\":" + offset + ",\"start\":\"" + start
+ "\"}").addParameter("method", "next").build();
// 添加必要的头信息
httpUriRequest
.setHeader("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0");
httpUriRequest.setHeader("X-Xsrftoken",
"这里的X-Xsrftoken拷贝复制登录后请求头里的X-Xsrftoken值");
httpUriRequest.setHeader("X-Requested-With", "XMLHttpRequest");
httpUriRequest.setHeader("Referer", "https://www.zhihu.com/");
httpUriRequest
.setHeader(
"Cookie",
"这里的Cookie拷贝复制登录后请求头里的Cookie值");
httpUriRequest.setHeader("DNT", "1");
httpUriRequest.setHeader("Connection", "keep-alive");
httpUriRequest.setHeader("Cache-Control", "max-age=0"); HttpResponse response = httpClient.execute(httpUriRequest); String str = "";
HttpEntity entity = response.getEntity();
if (entity != null) {
InputStream instreams = entity.getContent();
str = convertStreamToString(instreams);
}
return str;
}
}
JAVA爬虫实践(实践一:知乎)的更多相关文章
- java 利用jsoup 爬取知乎首页问题
今天学了下java的爬虫,首先要下载jsoup的包,然后导入,导入过程:首先右击工程:Build Path ->configure Build Path,再点击Add External JARS ...
- Java爬虫系列一:写在开始前
最近在研究Java爬虫,小有收获,打算一边学一边跟大家分享下,在干货开始前想先跟大家啰嗦几句. 一.首先说下为什么要研究Java爬虫 Python已经火了很久了,它功能强大,其中很擅长的一个就是写爬虫 ...
- JAVA爬虫实践(实践三:爬虫框架webMagic和csdnBlog爬虫)
WebMagic WebMagic是一个简单灵活的Java爬虫框架.基于WebMagic,你可以快速开发出一个高效.易维护的爬虫. 采用HttpClient可以实现定向的爬虫,也可以自己编写算法逻辑来 ...
- Java 理论与实践: 流行的原子——新原子类是 java.util.concurrent 的隐藏精华(转载)
简介: 在 JDK 5.0 之前,如果不使用本机代码,就不能用 Java 语言编写无等待.无锁定的算法.在 java.util.concurrent 中添加原子变量类之后,这种情况发生了变化.请跟随并 ...
- Java 理论与实践: 流行的原子
Java 理论与实践: 流行的原子 新原子类是 java.util.concurrent 的隐藏精华 在 JDK 5.0 之前,如果不使用本机代码,就不能用 Java 语言编写无等待.无锁定的算法.在 ...
- Java 理论与实践: 处理 InterruptedException
捕捉到它,然后怎么处理它? 很多 Java™ 语言方法,例如 Thread.sleep() 和 Object.wait(),都可以抛出InterruptedException.您不能忽略这个异常,因为 ...
- paip.myeclipse7 java webservice 最佳实践o228
paip.myeclipse7 java webservice 最佳实践o228 java的ws实现方案:jax-ws>>xfire ws的测试工具 webservice测试调用工具W ...
- Java 理论与实践: 非阻塞算法简介——看吧,没有锁定!(转载)
简介: Java™ 5.0 第一次让使用 Java 语言开发非阻塞算法成为可能,java.util.concurrent 包充分地利用了这个功能.非阻塞算法属于并发算法,它们可以安全地派生它们的线程, ...
- Java 理论和实践: 了解泛型
转载自 : http://www.ibm.com/developerworks/cn/java/j-jtp01255.html 表面上看起来,无论语法还是应用的环境(比如容器类),泛型类型(或者泛型) ...
随机推荐
- xamarin android制作圆角边框
xamarin android制作圆角边框 效果图如下: 关键代码: drawable文件夹新建shape_corner_down.xml <?xml version="1.0&quo ...
- .net 连接SqlServer数据库及基本增删改查
一.写在前面 因为这学期选修的 .net 课程就要上机考试了,所以总结下.net 操作 SqlServer 数据的方法.(因为本人方向是 Java,所以对.net 的了解不多,但以下所写代码均是经过测 ...
- find + xargs + cp 遇到文件名中带空格如何处理
一,需求为查询文件名为ZRSH开头的时间为7月至今的所有文件并打包 1.首先想到的就是find + xargs + cp 格式.. find 2016073* -type f -name *ZRS ...
- python如何进行内存管理
作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明.谢谢! 语言的内存管理是语言设计的一个重要方面.它是决定语言性能的重要因素.无论是C语言的 ...
- Java笔记:语法基础
Java语法基础 更新时间:2018-1-7 10:34:05 Hello World 文件名:HelloWorld.java public class HelloWorld { public sta ...
- angular4——安装
本文同样适用于NG4,最近开始学ng2了,前端小白一枚啊,做过安卓开发,做过java写的服务器啊,热爱前端啊,所以就开坑了,入坑之前建议先学下es6哦,学完后看下typescript哦,正所谓,前面基 ...
- python calendar(日历)模块
内置函数month() #!/usr/bin/python import calendar print calendar.month(2017,12) 输出: December 2017 Mo Tu ...
- [Spark内核] 第30课:Master的注册机制和状态管理解密
本課主題 Master 接收 Worker, Driver, Application Master 处理 Driver 狀态变换 Master 处理 Executor 狀态变换 [引言部份:你希望读者 ...
- HDFS Architecture
http://hadoop.apache.org/docs/r2.9.0/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html Introduction Ha ...
- php 使用beanstalk 消息队列
Beanstalkd 消息队列 一.基本信息Beanstalkd,一个高性能.轻量级的分布式内存队列系统,最初设计的目的是想通过后台异步执行耗时的任务来降低高容量Web应用系统的页面访问延迟,支持过有 ...