《Java I/O 从0到1》 - 第Ⅱ滴血 “流”
前言
《Java I/O 从0到1》系列上一章节,介绍了File 类,这一章节介绍的是IO的核心 输入输出。I/O类库常使用流这个抽象概念。代表任何有能力产出数据的数据源对象或者是有能力接受数据的接收端对象。
流 屏蔽了实际的I/0设备中处理数据的细节。Java类库中的I/O类库分为输入输出两部分。InputStram或Reader 派生而来的类都含有 read() 基本方法,用于 读 取单个字节或者字节数组。同样,任何自OutputStream或Writer 派生而来的类都含有名为write()基本方法,用于 写 单个字节或者字节数组。但是,我们通常不会用到这些方法,他们之所以存在是因为别的类可以使用它们,以便提供更有用的接口。因此,很少使用单一的类来创建流对象,而是通过叠合多个对象来提供所期望的功能。摘自《Java 编程思想第四版》
下面呢,提供一个整理的IO思维导图(查看图片,点击图片右键 选择 新标签页中打开):
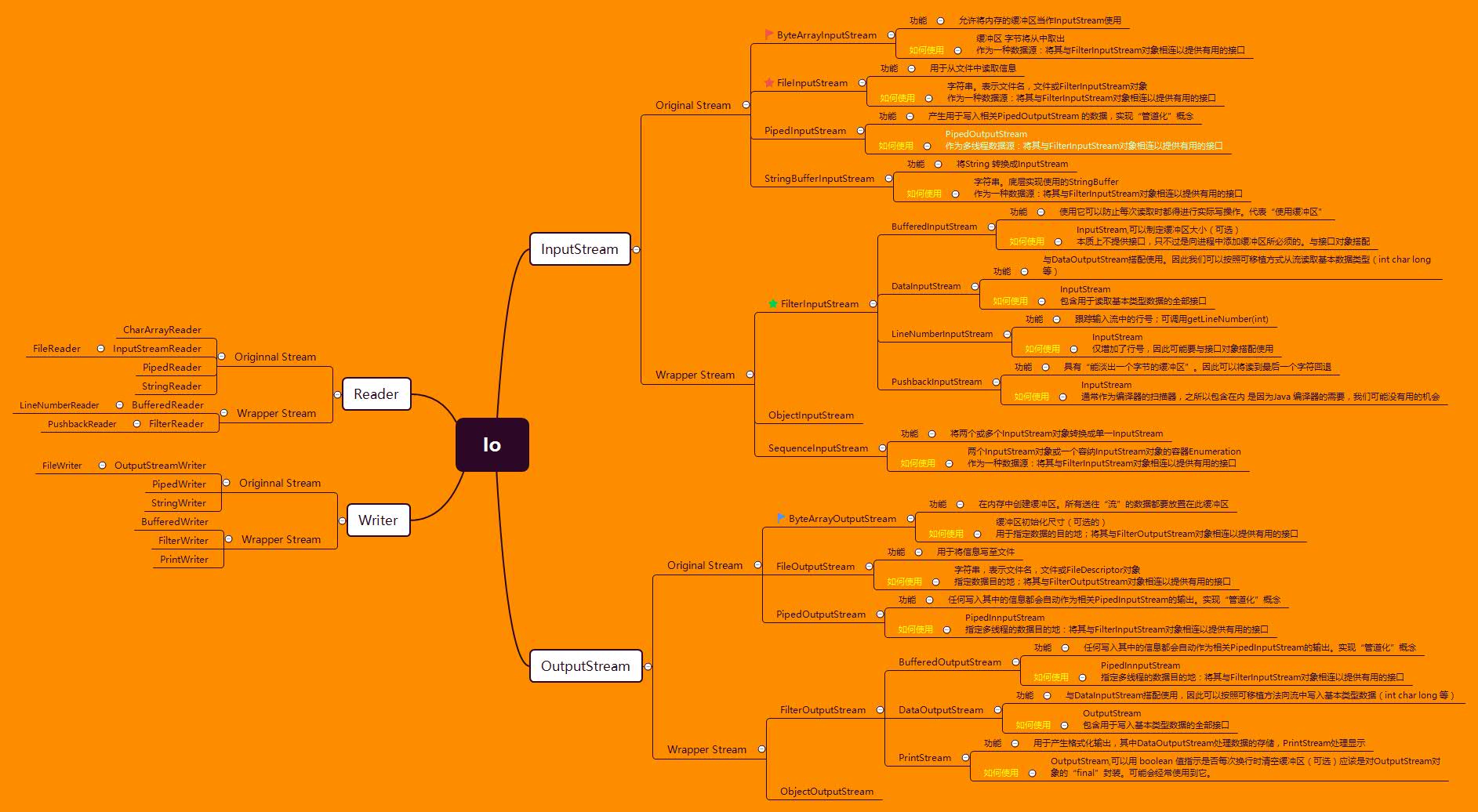
Xmind下载链接:http://pan.baidu.com/s/1gfrLcf5
InputStream:用来表示从不同数据源产生输入的类。数据源包括:字节数组,String对象,文件,“管道”等 。引用《Java 编程思想第四版》中图片。
OutputStream:决定了输出所要去往的目标。
字节流
字节流对应的类是InputStream和OutputStream,而在实际开发过程中,需要根据不同的类型选用相应的子类来处理。
a. 先根据需求进行判定,读 则使用 InputStream 类型; 写 则使用 OutputStream 类型
b. 在判定媒介对象什么类型,然后使用对应的实现类。 eg: 媒介对象是 文件 则使用FileInputStream FileOutputStream 进行操作。
方法
1. int read(byte[] b) 从此输入流中读取一个数据字节。
2. int read(byte[] b, int off, int len) 从此输入流中将最多 len 个字节的数据读入一个 byte 数组中。
3. void write(byte[] b) 将 b.length 个字节写入此输出流。
4. void write(byte[] b, int off, int len) 将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此输出流。
/**
*
* Title: writeByteToFile
* Description: 字节流写文件
* @author yacong_liu Email:2682505646@qq.com
* @date 2017年9月20日下午5:34:41
*/
private static void writeByteToFile() {
String str = new String("Hello Everyone!,My name is IO");
byte[] bytes = str.getBytes();
File file = new File("D:" + File.separator + "tmp" + File.separator + "hello.txt");
OutputStream os = null;
try {
os = new FileOutputStream(file);
os.write(bytes);
System.out.println("write success");
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
os.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
字节流 写 文件
/**
*
* Title: readByByteFromFile Description: 字节流读文件
*
* @author yacong_liu Email:2682505646@qq.com
* @date 2017年9月20日下午5:47:35
*/
public static void readByByteFromFile() {
File file = new File("D:" + File.separator + "tmp" + File.separator + "hello.txt");
byte[] byteArr = new byte[(int) file.length()];
try {
InputStream is = new FileInputStream(file);
is.read(byteArr); System.out.println(new String(byteArr) + "\n"); is.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} /**
* Console:
* Hello Everyone!,My name is IO
*/
}
字节流 读 文件
字符流
字符流对应的类似 Reader 和 Writer。
public static void writeCharToFile() {
String str = new String("Hello Everyone!,My name is IOs");
File file = new File("D:" + File.separator + "tmp" + File.separator + "helloChar.java");
try {
Writer os = new FileWriter(file);
os.write(str);
os.close();
} catch (IOException e) {
e.printStackTrace();
}
}
字符流 写 文件
public static void readCharFromFile() {
File file = new File("D:" + File.separator + "tmp" + File.separator + "helloChar.java");
try {
Reader reader = new FileReader(file);
char[] byteArr = new char[(int) file.length()];
reader.read(byteArr);
System.out.println("文件内容: " + new String(byteArr));
reader.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
/**
* Console:
* 文件内容: Hello Everyone!,My name is IOs
*/
}
字符流 读 文件
字节字符流组合
IO流之间可以组合,但不是所有的流都能组合。组合(或者称为嵌套)的好处就是把多种类型的特性融合到一起以实现更多的功能。
public static void composeByteAndChar() {
File file = new File("D:" + File.separator + "tmp" + File.separator + "helloChar.java");
InputStream is;
try {
is = new FileInputStream(file);
Reader reader = new InputStreamReader(is);
char[] byteArr = new char[(int) file.length()];
reader.read(byteArr);
System.out.println("文件内容: " + new String(byteArr));
is.close();
reader.close();
} catch (Exception e) {
e.printStackTrace();
}
}
字节流 组合 字符流
缓冲流
缓冲就是对流进行读写操作时提供一个缓冲管道buffer来提高IO效率。(且由我说成为管道吧,其实原理都一样的嘛,前面是小管道,后面套一个大管道,然后就可以大批量的往后输送了嘛)。
原始的字节流对数据的读取都是一个字节一个字节的操作,而Buffer缓冲流在内部提供了一个buffer,读取数据时可以一次读取一大块数据到buffer中,效率要提高很多。对于磁盘IO以及大量数据来讲,使用缓冲最合适不过。
使用方面,其实很简单,只要在字节流的外面组合一层缓冲流即可。
public static void readBufferFromByte(){
File file = new File("D:" + File.separator + "tmp" + File.separator + "helloChar.java");
byte[] byteArr = new byte[(int) file.length()];
try {
// 制定缓冲流 buffer 大小
InputStream is = new BufferedInputStream(new FileInputStream(file),2*1024);
is.read(byteArr);
System.out.println("文件内容: " + new String(byteArr));
is.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
组合 缓冲流
上面的示例中,我们制定了buffer 的大小,那么这个大小范围如何确定呢?这可不是瞎编的哦。buffer的大小应该是硬件状况来确定。对于磁盘IO来说,如果硬盘每次读取4KB大小的文件块,那么我们最好设置成这个大小的整数倍。因为磁盘对于顺序读的效率是特别高的,所以如果buffer再设置的大写可能会带来更好的效率,比如设置成4*4KB或8*4KB。
还需要注意的就是磁盘本身就会有缓存,在这种情况下,BufferedInputStream会一次读取磁盘缓存大小的数据,而不是分多次的去读。所以要想得到一个最优的buffer值,我们必须得知道磁盘每次读的块大小和其缓存大小,然后根据多次试验的结果来得到最佳的buffer大小。(引用自Heaven-Wang 博客 java io 概述)。
那么,至此呢,本章节 “流”的内容就已经基本介绍完毕了,更多的内容还是需要常查看API。
《Java I/O 从0到1》 - 第Ⅱ滴血 “流”的更多相关文章
- Java I/O 从0到1 - 第Ⅰ滴血 File
前言 File 类的介绍主要会依据<Java 编程思想>以及官网API .相信大家在日常工作中,肯定会遇到文件流的读取等操作,但是在搜索过程中,并没有找到一个介绍的很简洁明了的文章.因此, ...
- 20145208 《Java程序设计》第0周学习总结
20145208 <Java程序设计>第0周学习总结 阅读心得 读了老师推荐的几个文章,虽然第四个文章"为什么一定要自学"报告资源不存在而无法阅读,其他的三篇文章都言之 ...
- Windows Intellij环境下Gradle的 “Could not determine Java version from ‘9.0.1’”的解决方式
当我导入Gradle项目初试Java spring的时候,遇到下面报错: Gradle complete project refresh failed Error:Could not determin ...
- hadoop 遇到java.net.ConnectException: to 0.0.0.0:10020 failed on connection
hadoop 遇到java.net.ConnectException: to 0.0.0.0:10020 failed on connection 这个问题一般是在hadoop2.x版本里会出 ...
- 20145328 《Java程序设计》第0周学习总结
20145328 <Java程序设计>第0周学习总结 阅读心得 从总体上来说,这几篇文章都是围绕着软件工程专业的一些现象来进行描述的,但深入了解之后就可以发现,无论是软件工程专业还是我们现 ...
- 《Java I/O 从0到1》 - 第Ⅰ滴血 File
前言 File 类的介绍主要会依据<Java 编程思想>以及官网API .相信大家在日常工作中,肯定会遇到文件流的读取等操作,但是在搜索过程中,并没有找到一个介绍的很简洁明了的文章.因此, ...
- Java升级替换java version "1.5.0"
首先进行java安装 http://www.cnblogs.com/someone9/p/8670585.html 2. 然后查看版本信息,仍然是1.5.0 [root@OKC java]# java ...
- java在线聊天项目0.5版 解决客户端向服务器端发送信息时只能发送一次问题 OutputStreamWriter DataOutputStream socket.getOutputStream()
没有解决问题之前客户端代码: package com.swift; import java.awt.BorderLayout; import java.awt.Color; import java.a ...
- Java SPI、servlet3.0与@HandlesTypes源码分析
关于Java SPI与servlet3.0的应用,这里说的很精炼,链接地址如下. https://blog.csdn.net/pingnanlee/article/details/80940993 以 ...
随机推荐
- Maven详解(四)------ 常用的Maven命令
这章我们讲讲几个常用的 Maven 命令.由于执行命令是在工程的基础上来的,所以我们要先创建一个 Maven 工程,具体如何创建,在上一篇博客已经介绍了:http://www.cnblogs.com/ ...
- fs模块(一)
模块的使用,必须先引入模块 var fs = require('fs'); 1. readFile 和 readFileSync var fs = require('fs'); //01 readFi ...
- EasuUI-js(EasyUI formatter格式化教程)常用判断收集
YN标记: formatter : function(c1, row,index) { var a = ""; if(c1 == "Y"){ a = a + & ...
- 利用js实现禁用浏览器后退
原博主链接为:http://blog.csdn.net/zc474235918/article/details/53138553 现在很多的内部系统,一些界面,都是用户手动点击退出按钮的.但是为了避免 ...
- django框架(Model)
-------------------使用MySql数据库-------------------1.进行对应mysql-python包的下载 pip install mysql-python 2.在m ...
- hashlib使用时出现: Unicode-objects must be encoded before hashing
# hashlib.md5(data)函数中,data参数的类型应该是bytes# hash前必须把数据转换成bytes类型>>> from hashlib import md5 F ...
- 编译安装httpd 2.4
author:JevonWei 版权声明:原创作品 官方网站下载httpd2.4.apr及apr-util的相关软件包,并传输到centos 7系统中的/usr/local/src(apr1.6版本过 ...
- 设置input的placeholder样式
自定义input默认placeholder样式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 inpu ...
- js变量以及其作用域详解
详见: http://blog.yemou.net/article/query/info/tytfjhfascvhzxcytp73 一.变量的类型 Javascript和Java.C这些语言不同 ...
- 6.分析request_irq和free_irq函数如何注册注销中断
上一节讲了如何实现运行中断,这些都是系统给做好的,当我们想自己写个中断处理程序,去执行自己的代码,就需要写irq_desc->action->handler,然后通过request_irq ...