lca入门———树上倍增法(博文内含例题)
倍增求LCA:
father【i】【j】表示节点i往上跳2^j次后的节点
可以转移为
father【i】【j】=father【father【i】【j-1】】【j-1】
整体思路:
先比较两个点的深度,如果深度不同,先让深的点往上跳,浅的先不动,等两个点深度一样时,if 相同 直接返回,if 不同 进行下一步;如果不同,两个点一起跳,j从大到小枚举(其实并不大),如果两个点都跳这么多后,得到的点相等,两个点都不动(因为有可能正好是LCA也有可能在LCA上方),知道得到的点不同,就可以跳上来,然后不断跳,两个点都在LCA下面那层,所以再跳1步即可,当father【i】【j】中j=0时即可,就是LCA,返回值结束
(摘自http://blog.csdn.net/dad3zz)
在网络海洋中搜寻很久后找到hzwer的宽搜求deep序,进行了学习。
以下是我的模板代码:
构造访问数组!
void make_bin()
{
bin[0]=1;
for(int i=1;i<=15;i++)
bin[i]=bin[i-1]<<1;
}
简明易懂邻接表!
void Link()
{
for(int i=1;i<=n-1;i++){//n-1 edges;or you can define a m pointing to the number of edges;
scanf("%d%d",&u[i],&v[i]);
u[i+n-1]=v[i];v[i+n-1]=u[i];//双向;
next[i]=first[u[i]];
next[i+n-1]=first[v[i]];//双向;
first[u[i]]=i;
first[v[i]]=i+n-1;//双向;
isroot[v[i]]=true;
}
}
宽搜!
void bfs()
{
int head=0,tail=1;
q[0]=root,vis[root]=true;
while(head^tail){
int now=q[head];head++;
for(int i=1;i<=15;i++){
if(bin[i]<=deep[now])
fa[now][i]=fa[fa[now][i-1]][i-1];
else break;
}
for(int i=first[now];i;i=next[i])
if(!vis[v[i]]){
vis[v[i]]=true;
fa[v[i]][0]=now;
deep[v[i]]=deep[now]+1;
q[tail++]=v[i];
}
}
}
求lca()
int lca(int x,int y)
{
if(deep[x]<deep[y])swap(x,y);
int t=deep[x]-deep[y];
for(int i=0;i<=15;i++)
if(t&bin[i])x=fa[x][i];
for(int i=15;i>=0;i--)
if(fa[x][i]^fa[y][i])
x=fa[x][i],y=fa[y][i];
if(!(x^y))return y;
return fa[x][0];
}
之后,在poj上找了一个众所周知的例题,poj1330,当做lca入门题
| Time Limit: 1000MS | Memory Limit: 10000K | |
| Total Submissions: 24757 | Accepted: 12864 |
Description
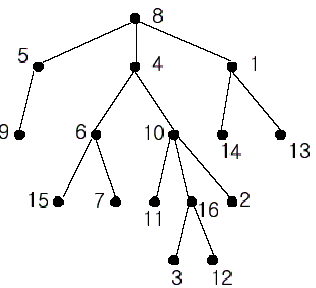
In the figure, each node is labeled with an integer from {1, 2,...,16}. Node 8 is the root of the tree. Node x is an ancestor of node y if node x is in the path between the root and node y. For example, node 4 is an ancestor of node 16. Node 10 is also an ancestor
of node 16. As a matter of fact, nodes 8, 4, 10, and 16 are the ancestors of node 16. Remember that a node is an ancestor of itself. Nodes 8, 4, 6, and 7 are the ancestors of node 7. A node x is called a common ancestor of two different nodes y and z if node
x is an ancestor of node y and an ancestor of node z. Thus, nodes 8 and 4 are the common ancestors of nodes 16 and 7. A node x is called the nearest common ancestor of nodes y and z if x is a common ancestor of y and z and nearest to y and z among their common
ancestors. Hence, the nearest common ancestor of nodes 16 and 7 is node 4. Node 4 is nearer to nodes 16 and 7 than node 8 is.
For other examples, the nearest common ancestor of nodes 2 and 3 is node 10, the nearest common ancestor of nodes 6 and 13 is node 8, and the nearest common ancestor of nodes 4 and 12 is node 4. In the last example, if y is an ancestor of z, then the nearest
common ancestor of y and z is y.
Write a program that finds the nearest common ancestor of two distinct nodes in a tree.
Input
labeled with integers 1, 2,..., N. Each of the next N -1 lines contains a pair of integers that represent an edge --the first integer is the parent node of the second integer. Note that a tree with N nodes has exactly N - 1 edges. The last line of each test
case contains two distinct integers whose nearest common ancestor is to be computed.
Output
Sample Input
2
16
1 14
8 5
10 16
5 9
4 6
8 4
4 10
1 13
6 15
10 11
6 7
10 2
16 3
8 1
16 12
16 7
5
2 3
3 4
3 1
1 5
3 5
Sample Output
4
3
Source
Source Code
| Problem: 1330 | User: ksq2013 | |
| Memory: 1224K | Time: 32MS | |
| Language: C++ | Result: Accepted |
ac代码如下:
#include<cstdio>
#include<cstring>
#include<iostream>
using namespace std;
bool vis[10100],isroot[10100];
int root,q[10100],deep[10100],fa[10100][20];
int n,bin[20],first[10100],next[10100],u[10100],v[10100];
void make_bin()
{
bin[0]=1;
for(int i=1;i<=15;i++)
bin[i]=bin[i-1]<<1;
}
void Link()
{
for(int i=1;i<=n-1;i++){
scanf("%d%d",&u[i],&v[i]);
//u[i+n-1]=v[i];v[i+n-1]=u[i];
next[i]=first[u[i]];
//next[i+n-1]=first[v[i]];
first[u[i]]=i;
//first[v[i]]=i+n-1;
isroot[v[i]]=true;
}
for(int i=1;i<=n;i++)
if(!isroot[i]){
root=i;
break;
}
}
void bfs()
{
int head=0,tail=1;
q[0]=root,vis[root]=true;
while(head^tail){
int now=q[head];head++;
for(int i=1;i<=15;i++){
if(bin[i]<=deep[now])
fa[now][i]=fa[fa[now][i-1]][i-1];
else break;
}
for(int i=first[now];i;i=next[i])
if(!vis[v[i]]){
vis[v[i]]=true;
fa[v[i]][0]=now;
deep[v[i]]=deep[now]+1;
q[tail++]=v[i];
}
}
}
int lca(int x,int y)
{
if(deep[x]<deep[y])swap(x,y);
int t=deep[x]-deep[y];
for(int i=0;i<=15;i++)
if(t&bin[i])x=fa[x][i];
for(int i=15;i>=0;i--)
if(fa[x][i]^fa[y][i])
x=fa[x][i],y=fa[y][i];
if(!(x^y))return y;
return fa[x][0];
}
int main()
{
make_bin();
int T;
scanf("%d",&T);
for(;T;T--){
memset(vis,false,sizeof(vis));
memset(isroot,false,sizeof(isroot));
memset(q,0,sizeof(q));
memset(fa,0,sizeof(fa));
memset(deep,0,sizeof(deep));
memset(first,0,sizeof(first));
memset(next,0,sizeof(next));
scanf("%d",&n);
Link();
bfs();
int x,y;
scanf("%d%d",&x,&y);
printf("%d\n",lca(x,y));
}
return 0;
}
lca入门———树上倍增法(博文内含例题)的更多相关文章
- 最近公共祖先算法LCA笔记(树上倍增法)
Update: 2019.7.15更新 万分感谢[宁信]大佬,认认真真地审核了本文章,指出了超过五处错误捂脸,太尴尬了. 万分感谢[宁信]大佬,认认真真地审核了本文章,指出了超过五处错误捂脸,太尴尬了 ...
- 树上倍增法求LCA
我们找的是任意两个结点的最近公共祖先, 那么我们可以考虑这么两种种情况: 1.两结点的深度相同. 2.两结点深度不同. 第一步都要转化为情况1,这种可处理的情况. 先不考虑其他, 我们思考这么一个问题 ...
- 【37.48%】【hdu 2587】How far away ?(3篇文章,3种做法,LCA之树上倍增)
Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Submission(s) ...
- LCA离线Tarjan,树上倍增入门题
离线Tarjian,来个JVxie大佬博客最近公共祖先LCA(Tarjan算法)的思考和算法实现,还有zhouzhendong大佬的LCA算法解析-Tarjan&倍增&RMQ(其实你们 ...
- Codeforces 609E (Kruskal求最小生成树+树上倍增求LCA)
题面 传送门 题目大意: 给定一个无向连通带权图G,对于每条边(u,v,w)" role="presentation" style="position: rel ...
- HDU 2586 倍增法求lca
How far away ? Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)To ...
- 最近公共祖先 LCA 倍增法
[简介] 解决LCA问题的倍增法是一种基于倍增思想的在线算法. [原理] 原理和同样是使用倍增思想的RMQ-ST 算法类似,比较简单,想清楚后很容易实现. 对于每个节点u , ancestors[u] ...
- 最近公共祖先 LCA (Lowest Common Ancestors)-树上倍增
树上倍增是求解关于LCA问题的两个在线算法中的一个,在线算法即不需要开始全部读入查询,你给他什么查询,他都能返回它们的LCA. 树上倍增用到一个关键的数组F[i][j],这个表示第i个结点的向上2^j ...
- 【bzoj4940】[Ynoi2016]这是我自己的发明 DFS序+树上倍增+莫队算法
题目描述 给一个树,n 个点,有点权,初始根是 1. m 个操作,每次操作: 1. 将树根换为 x. 2. 给出两个点 x,y,从 x 的子树中选每一个点,y 的子树中选每一个点,如果两个点点权相等, ...
随机推荐
- 根据werservice代码用CXF生成WSDL
原文:http://hongyegu.iteye.com/blog/619147,谢谢! import org.apache.cxf.tools.java2ws.JavaToWS; import ne ...
- sqlite学习1
Architecture  就像编译器一样,结构分为前端.虚拟机.后端 性能和限制(limitations) 使用B树来做indexes,用B+树来做table.和其他数据库一样 由于不需要鉴权.网 ...
- zookeeper入门讲解事例
zookeeper使用和原理探究(一) zookeeper介绍zookeeper是一个为分布式应用提供一致性服务的软件,它是开源的Hadoop项目中的一个子项目,并且根据google发表的<Th ...
- Android判断屏幕开关状态
方法一:使用系统服务 PowerManager pm= (PowerManager) mContext.getSystemService(Context.POWER_SERVICE); if(!pm. ...
- iOS cookie问题
获取cookie时汉字应转换为UTF8格式
- CATransform3D方法汇总
CATransform3D三维变换 struct CATransform3D { CGFloat m11, m12, m13, m14; CGFloat m21, m22, m23, m24; CGF ...
- 网络编程--ASI--(ASIHTTPRequest)介绍
ASIHTTPRequest 虽然是明日黄花,但是还是稍微归纳一下,理清思路,知道这个曾经的她都能干嘛. 1. ASI基于底层的 CFNetworking 框架,运行效率很高. 2. 黄金搭档:ASI ...
- 同步时间linux
针对对时间要求精确度高的服务器 1.安装时间服务器yum install ntp 2.同步时间ntpdate time.nist.gov 3.设置计划任务每隔10分钟同步一次 */10 * * * * ...
- 使用开源免费类库在.net中操作Excel
自从上次找到NPOI之后,根据园友提供的线索以及Google,又找到了一些开源免费的类库,所以都简单体验了一遍. 主要找到以下类库: MyXls(http://sourceforge.net/proj ...
- Java成员的访问权限控制
Java中的访问权限控制包含两个部分: 类的访问权限控制 类成员的访问权限控制 对类来说,访问权限控制修饰符可以是public或者无修饰符(默认的包访问权限): 对于类成员来说,访问权限控制修饰符可以 ...