【转】Kylin的cube模型
转自:http://www.cnblogs.com/en-heng/p/5239311.html
1. 数据仓库的相关概念
OLAP
大部分数据库系统的主要任务是执行联机事务处理和查询处理,这种处理被称为OLTP(Online Transaction Processing, OLTP),面向的是顾客,诸如:办事员、DBA等。而数据仓库主要面向知识工人(如经理、主管等)提供数据分析处理,这种处理被称为OLAP(Online Analysis Processing)。OLTP管理的是当前数据,比较琐碎,很难用于做决策。而OLAP管理的是大量历史数据,提供汇总与聚集机制,并在不同的维度、不同的粒度存储和管理信息。
| 特征 | OLTP | OLAP |
|---|---|---|
| 面向 | 办事员、DBA | 知识工人 |
| DB设计 | 基于ER,面向应用 | 星形/雪花,面向主题 |
| 数据 | 当前的、确保更新 | 历史的、跨时间维护 |
| 视图 | 详细、一般关系 | 汇总的、多维的 |
| 访问 | 读/写 | 大多数为读 |
| 度量 | 事务吞吐量 | 查询吞吐量、访问时间 |
举个简单的例子:我们会用OLTP去管理app名称与app类别的映射关系;而分析某一周app(和app类别)的UV,则会使用OLAP;并且OLAP提供了数据的多维观察——比如:在某周在华为手机上top100用户的APP。
Fact Table
事实表(Fact Table)是中心表,包含了大批数据并不冗余,其数据列可分为两类:
- 包含大量数据事实的列;
- 与维表(Dimension Table)的primary key相对应的foreign key。
Lookup Table
Lookup Table包含对事实表的某些列进行扩充说明的字段。在Kylin的quick start中给出sample cube(kylin_sales_cube)——其Fact Table为购买记录,lookup table有两个:用于对购买日期PART_DT、商品的LEAF_CATEG_ID与LSTG_SITE_ID字段进行扩展说明。
Dimension
维表(Dimension Table)是由fact table与lookup table逻辑抽象出来的表,包含了多个相关的列(即dimension),以提供对数据的多维观察;其中dimension的值的数目称为cardinatily。在kylin_sales_cube的事实表的LSTG_FORMAT_NAME被单独抽出来做一个dimension,可与其他维度组合分析数据。
Star Schema
星形模式(Star Schema)包含一个或多个事实表、一组维表,其中维表的primary key与事实表的foreign key相对应。这种模式很像星光四射,维表显示在围绕事实表的射线上。下图是我根据某数据源所建立的星形模式:
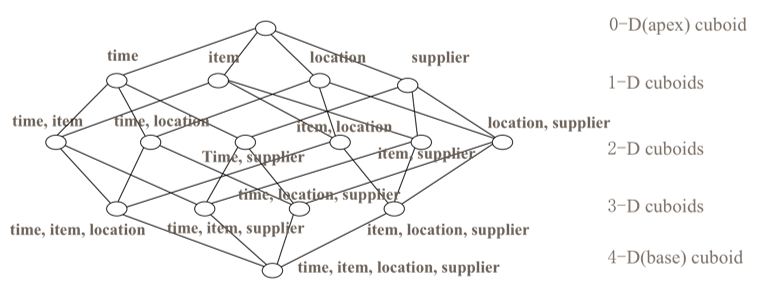
Cube
cube是所有的dimensions组合,任一dimensions的组合称为cuboid。因此,包含nn个dimensions的cube有2n2n个cuboid,如下图所示:
2. Kylin介绍
Dimension
为了减少cuboid的数目,Kylin将Dimension分为四种类型:
- Normal,为最常见的类型,与所有其他的dimension组合构成cuboid。
Mandatory,在每一次查询中都会用到dimension,在下图中A为Mandatory dimension,则与B、C总共构成了4个cuboid,相较于normal dimension的cuboid(23=823=8)减少了一半。

Hierarchy,为带层级的dimension,比如说:省份->城市, 年->季度->月->周->日;以用于做drill down。

- Derived,指该dimensions与维表的primary key是一一对应关系,可以更有效地减少cuboid数量,详细的解释参看这里;并且derived dimension只能由lookup table的列生成。
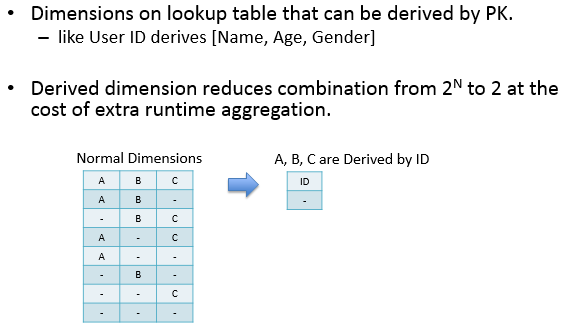
然而,Kylin的Hierarchy dimensions并没有做集合包含约束,比如:kylin_sales_cube定义Hierarchy dimension为META_CATEG_NAME->CATEG_LVL2_NAME->CATEG_LVL3_NAME,但是同一个CATEG_LVL2_NAME可以对应不同META_CATEG_NAME。因此,hierarchy 显得非常鸡肋,以至于在Kylin后台处理时被废弃了(详见Li Yang在mail group中所说):
@Julian, plan to refactor the underlying aggregation group in Q4. Will drop
hierarchy concept in the backend, however in the frontend for ease of
understanding, may still call it hierarchy.
Measure
Measure为事实表的列度量,Kylin提供诸如:
- Sum
- Count
- Max
- Min
- Average
- Distinct Count (based on HyperLogLog)
等函数,一般配合group by dimesion使用。
3. 实战
下面的SQL语句是在kylin_sales_cube build成功后执行的。
sql命令select * from kylin_sales,得到fact table所缓存的列——均为dimension的主key、measure中所需计算的字段。
各个时间段内的销售额及购买量:
select part_dt, sum(price) as total_selled, count(distinct seller_id) as sellers
from kylin_sales
group by part_dt
order by part_dt查询某一时间的销售额及购买量,
select part_dt, sum(price) as total_selled, count(distinct seller_id) as sellers
from kylin_sales
where part_dt = '2014-01-01'
group by part_dt发现报错:
Error while compiling generated Java code:
public static class Record3_0 implements java.io.Serializable { public java.math.BigDecimal f0;
public boolean f1;
public org.apache.kylin.common.hll.HyperLogLogPlusCounter f2; public Record3_0(java.math.BigDecimal f0, boolean f1, ...这是因为part_dt是date类型,在解析string到date的时候出问题,应将sql语句改为:
select part_dt, sum(price) as total_selled, count(distinct seller_id) as sellers
from kylin_sales
where part_dt between '2014-01-01' and '2014-01-01'
group by part_dt
-- or
select part_dt, sum(price) as total_selled, count(distinct seller_id) as sellers
from kylin_sales
where part_dt = date '2014-01-01'
group by part_dt上面查询只用到了fact table,而没有用到lookup table。如果查询各个时间段所有二级商品类型的销售额,则需要fact table与lookup table做inner join:
select fact.part_dt, lookup.CATEG_LVL2_NAME, count(distinct seller_id) as sellers
from kylin_sales fact
inner join KYLIN_CATEGORY_GROUPINGS lookup
on fact.LEAF_CATEG_ID = lookup.LEAF_CATEG_ID and fact.LSTG_SITE_ID = lookup.SITE_ID
group by fact.part_dt, lookup.CATEG_LVL2_NAME
order by fact.part_dt desc4. 参考资料
[1] 韩家炜,《数据挖掘——概念与技术》.
[2] 教练_我要踢球, OLAP引擎——Kylin介绍.
[3] Kylin, Design Cube in Kylin.
【转】Kylin的cube模型的更多相关文章
- Kylin的cube模型
1. 数据仓库的相关概念 OLAP 大部分数据库系统的主要任务是执行联机事务处理和查询处理,这种处理被称为OLTP(Online Transaction Processing, OLTP),面向的是顾 ...
- Kylin构建Cube过程详解
1 前言 在使用Kylin的时候,最重要的一步就是创建cube的模型定义,即指定度量和维度以及一些附加信息,然后对cube进行build,当然我们也可以根据原始表中的某一个string字段(这个字段的 ...
- Kylin Flink Cube 引擎的前世今生
Apache Kylin™ 是一个开源的.分布式的分析型数据仓库,提供 Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,它能在亚秒内查询巨大的表. Ky ...
- kylin构建cube优化
前言 下面通过对kylin构建cube流程的分析来介绍cube优化思路. 创建hive中间表 kylin会在cube构建的第一步先构建一张hive的中间表,该表关联了所有的事实表和维度表,也就是一张宽 ...
- Kylin构建cube时状态一直处于pending
在安装好kylin之后我直接去访问web监控页面发现能够进去,也没有去看日志.然后在运行官方带的例子去bulid cube时去发现状态一直是pending而不是runing.这个时候才去查看日志: 2 ...
- Transform开发cube模型权限处理之不同用户数据的过滤
========================此文不再详细的说transform的开发过程====================================================== ...
- 使用ReportStudio打开cube模型创建报表出现两个最细粒度名称
本人也是第一次遇到这样的问题,此问题甚是简单,也许很简短的一句话就可以解决这个问题了,看官请留神哦 cube做好发布到cognos之后使用Analysis Studio打开结构正常 于是想到要用此数据 ...
- 如何通过java代码对kylin进行cube build
通常是用于增量 代码如下: package com.dlht.kylinDemo; import java.io.BufferedReader; import java.io.FileNotFound ...
- 创建 kylin Module/Cube
1. 首先要创建 Project 2. 再把Hive 表加载进来: 3. 创建model 3.1. 首先选择或者创建一个project 3.2.创建一个新modle 3.3. 选择数据库 ...
随机推荐
- mybatis跨XML引用
resultMap中association标签的select属性使用嵌套查询的时候需要引用其它xml文件的配置 此时可以用要引用xml的namespace.引用select的ID 如 <resu ...
- 【leetcode】Reverse Linked List II (middle)
Reverse a linked list from position m to n. Do it in-place and in one-pass. For example:Given 1-> ...
- 【linux】学习3
鸟哥 书的第7章 从 /home/dtest1 跳入 /home/dtest2 目录: cd ../dtest2 注意 cd后有空格 ..后无空格 特殊目录: . 代表此层目录 .. ...
- 【XLL API 函数】 xlFree
用于释放使用 Excel4,Excel4v,Excel12,Excel12v 分配的 XLOPER/XLOPER12 占用的内存资源. xlFree 函数释放辅助内存和重置指针为NULL但不释放XLO ...
- php正则表达式、数组
<?php $s = "he8llo5wor6ld"; $s = preg_replace("/\d/","#",$s);按照正则表达 ...
- Tmux的安装、使用与配置
tmux 安装.使用.配置 因上线需求,故需要使用tumx,方便上线 tmux功能 提供了强大的.易于使用的命令行界面 可横向.纵向分割窗口 窗格可以自由移动和调整大小,或者直接利用四个预设布局之一 ...
- Redis自定义动态字符串(sds)模块(一)
Redis开发者在开发过程中没有使用系统的原始字符串,而是使用了自定义的sds字符串,这个模块的编写是在文件:sds.h和sds.c文件中.Redis自定义的这个字符串好像也不是很复杂,远不像ngin ...
- SQL Server之存储过程基础知
什么是存储过程呢?存储过程就是作为可执行对象存放在数据库中的一个或多个SQL命令. 通俗来讲:存储过程其实就是能完成一定操作的一组SQL语句. 那为什么要用存储过程呢?1.存储过程只在创造时进行编译, ...
- ActiveMQ的几种消息持久化机制
为了避免意外宕机以后丢失信息,需要做到重启后可以恢复消息队列,消息系统一般都会采用持久化机制. ActiveMQ的消息持久化机制有JDBC,AMQ,KahaDB和LevelDB,无论使用哪种持久化方式 ...
- java中常用的工具类(二)
下面继续分享java中常用的一些工具类,希望给大家带来帮助! 1.FtpUtil Java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ...