二分类问题F-score评判指标(转载)
分类模型的评价指标Fscore
分类方法常用的评估模型好坏的方法.
0.预设问题
假设我现在有一个二分类任务,是分析100封邮件是否是垃圾邮件,其中不是垃圾邮件有65封,是垃圾邮件有35封.模型最终给邮件的结论只有两个:是垃圾邮件与 不是垃圾邮件.
经过自己的努力,自己设计了模型,得到了结果,分类结果如下:
- 不是垃圾邮件70封(其中真实不是垃圾邮件60封,是垃圾邮件有10封)
- 是垃圾邮件30封(其中真实是垃圾邮件25封,不是垃圾邮件5封)
现在我们设置,不是垃圾邮件.为正样本,是垃圾邮件为负样本
我们一般使用四个符号表示预测的所有情况:
- TP(真阳性):正样本被正确预测为正样本,例子中的60
- FP(假阳性):负样本被错误预测为正样本,例子中的10
- TN(真阴性):负样本被正确预测为负样本,例子中的25
- FN(假阴性):正样本被错误预测为负样本,例子中的5
1.评价方法介绍
先看最终的计算公式:

1.Precision(精确率)
关注预测为正样本的数据(可能包含负样本)中,真实正样本的比例
计算公式

例子解释:对上前面例子,关注的部分就是预测结果的70封不是垃圾邮件中真实不是垃圾邮件占该预测结果的比率,现在Precision=60/(600+10)=85.71%
2.Recall(召回率)
关注真实正样本的数据(不包含任何负样本)中,正确预测的比例
计算公式
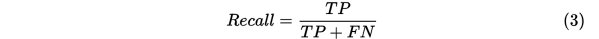
例子解释:对上前面例子,关注的部分就是真实有65封不是垃圾邮件,这其中你的预测结果中有多少预测正确了,Recall=60/(60+5)=92.31%
3.F-score中β值的介绍
β是用来平衡Precision,Recall在F-score计算中的权重,取值情况有以下三种:
- 如果取1,表示Precision与Recall一样重要
- 如果取小于1,表示Precision比Recall重要
- 如果取大于1,表示Recall比Precision重要
一般情况下,β取1,认为两个指标一样重要.此时F-score的计算公式为:
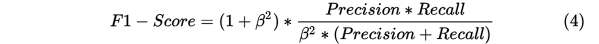
前面计算的结果,得到Fscore=(2*0.8571*0.9231)/(0.8571+0.9231)=88.89%
3.其他考虑
预测模型无非就是两个结果
- 准确预测(不管是正样子预测为正样本,还是负样本预测为负样本)
- 错误预测
那我就可以直接按照下面的公式求预测准确率,用这个值来评估模型准确率不就行了

那为什么还要那么复杂算各种值.理由是一般而言:负样本远大于正样本。
可以想象,两个模型的TN变化不大的情况下,但是TP在两个模型上有不同的值,TN>>TP是不是可以推断出:两个模型的(TN+TP)近似相等.这不就意味着两个模型按照以上公式计算的Accuracy近似相等了.那用这个指标有什么用!!!
所以说,对于这种情况的二分类问题,一般使用Fscore去评估模型.
需要注意的是:Fscore只用来评估二分类的模型,Accuracy没有这限制
参考
1.机器学习中的 precision、recall、accuracy、F1 Score
2.分类模型的评估方法-F分数(F-Score)







二分类问题F-score评判指标(转载)的更多相关文章
- 【分类模型评判指标 二】ROC曲线与AUC面积
转自:https://blog.csdn.net/Orange_Spotty_Cat/article/details/80499031 略有改动,仅供个人学习使用 简介 ROC曲线与AUC面积均是用来 ...
- 【分类模型评判指标 一】混淆矩阵(Confusion Matrix)
转自:https://blog.csdn.net/Orange_Spotty_Cat/article/details/80520839 略有改动,仅供个人学习使用 简介 混淆矩阵是ROC曲线绘制的基础 ...
- 【sklearn】性能度量指标之ROC曲线(二分类)
原创博文,转载请注明出处! 1.ROC曲线介绍 ROC曲线适用场景 二分类任务中,positive和negtive同样重要时,适合用ROC曲线评价 ROC曲线的意义 TPR的增长是以FPR的增长为代价 ...
- 二分类问题中混淆矩阵、PR以及AP评估指标
仿照上篇博文对于混淆矩阵.ROC和AUC指标的探讨,本文简要讨论机器学习二分类问题中的混淆矩阵.PR以及AP评估指标:实际上,(ROC,AUC)与(PR,AP)指标对具有某种相似性. 按照循序渐进的原 ...
- keras实现简单性别识别(二分类问题)
keras实现简单性别识别(二分类问题) 第一步:准备好需要的库 tensorflow 1.4.0 h5py 2.7.0 hdf5 1.8.15.1 Keras 2.0.8 opencv-p ...
- 【机器学习具体解释】SVM解二分类,多分类,及后验概率输出
转载请注明出处:http://blog.csdn.net/luoshixian099/article/details/51073885 CSDN−勿在浮沙筑高台 支持向量机(Support Vecto ...
- 机器学习常用性能度量中的Accuracy、Precision、Recall、ROC、F score等都是些什么东西?
一篇文章就搞懂啦,这个必须收藏! 我们以图片分类来举例,当然换成文本.语音等也是一样的. Positive 正样本.比如你要识别一组图片是不是猫,那么你预测某张图片是猫,这张图片就被预测成了正样本. ...
- P,R,F1 等性能度量(二分类、多分类)
总结自<机器学习>周志华 2.3 目录 最常用的是查准率P(precision),查全率R(recall),F1 一.对于二分类问题 二.对于多分类问题 1.macro 2.micro 最 ...
- 二分类Logistic回归模型
Logistic回归属于概率型的非线性回归,分为二分类和多分类的回归模型.这里只讲二分类. 对于二分类的Logistic回归,因变量y只有“是.否”两个取值,记为1和0.这种值为0/1的二值品质型变量 ...
随机推荐
- vue 复制文本到剪切板上
1.下载clipboard.js npm install vue-clipboard2 --save 2.引入,可以在mian.js中全局引入也可以在单个vue中引入 import Clipboard ...
- Mono 下的 ASP.NET 可以运行在哪些 Web 服务器上?
Mono has an implementation of ASP.NET 2.0, ASP.NET MVC and ASP.NET AJAX. Quick Resources: ASP.NET FA ...
- Django学习——用户自定义models问题解决
一.问题在Django中使用自定义的model的时候会出现下面的错误 ERRORS: auth.User.groups: (fields.E304) Reverse accessor for 'Use ...
- 如何解决RIP的问题
如何解决RIP的问题 RIP的问题 优化或解决的方式 收敛慢,故障恢复时间长 触发更新 缺少对全局网络拓扑的了解 路由器基于拓扑信息,独立计算路由 存在选择次优路径的风险 将链路带宽作为选路参考 ...
- Canon MF113W激光打印机双面打印方法
系统:macOS 10.14.3 打印机:Canon MF113W 黑白激光打印机(不支持自动双面打印) 方法: 1)文件->打印->纸张处理->仅奇数页->倒序->打印 ...
- Logstash之控制台输出的两种方式
输出json output { stdout { codec => json } } 输出rubydebug output { stdout { codec => rubydebug } ...
- dotnet中文字符工具类
支持繁体简体互换. using System; using System.Collections.Generic; using System.IO; using System.Linq; using ...
- ActionMq + mqttws3.1 实现持久化订阅
activemq版本:5.15.3 Eclipse Paho MQTT JavaScript library mqttws3.1:在amq安装目录下webapp-demo目录下可以找到 实现步骤请阅读 ...
- Linq 用得太随意导致的性能问题一则
问题场景 有一个很多条数据的数据库(数据源),在其中找出指定的项,这些项的 ID 位于 给定的列表中,如 TargetList 中. private readonly IDictionary<s ...
- beyond compare全文件夹比较,仅显示变化的文件
beyond compare是一款非常优秀的文件夹同步比较工具,赞. 非常强大的一点就是给定两个文件夹可以自动列出所有不同的文件和子文件夹,但是有一点可能很多人碰到过,也就是需要一个个点开才能重新比 ...