python ocr图片中汉字识别
import os
os.chdir("C:\Program Files (x86)\Tesseract-OCR")
main = "Tesseract.exe d:/test.png d:/1.txt -l chi_sim"
r_v = os.system(main)
print(r_v)
来自:https://www.cnblogs.com/jclian91/p/9158372.html
OCR与Tesseract介绍
将图片翻译成文字一般被称为光学文字识别(Optical Character Recognition,OCR)。可以实现OCR 的底层库并不多,目前很多库都是使用共同的几个底层OCR 库,或者是在上面进行定制。
Tesseract 是一个OCR 库,目前由Google 赞助(Google 也是一家以OCR 和机器学习技术闻名于世的公司)。Tesseract 是目前公认最优秀、最精确的开源OCR 系统。
除了极高的精确度,Tesseract 也具有很高的灵活性。它可以通过训练识别出任何字体(只要这些字体的风格保持不变就可以),也可以识别出任何Unicode 字符。
Tesseract的安装与使用
Tesseract的Windows安装包下载地址为: http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe ,下载后双击直接安装即可。安装完后,需要将Tesseract添加到系统变量中。在CMD中输入tesseract -v, 如显示以下界面,则表示Tesseract安装完成且添加到系统变量中。
Linux 用户可以通过apt-get 安装:
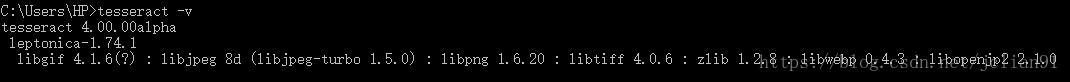
$sudo apt-get tesseract-ocr用Tesseract可以识别格式规范的文字,主要具有以下特点:
• 使用一个标准字体(不包含手写体、草书,或者十分“花哨的”字体)
• 虽然被复印或拍照,字体还是很清晰,没有多余的痕迹或污点
• 排列整齐,没有歪歪斜斜的字
• 没有超出图片范围,也没有残缺不全,或紧紧贴在图片的边缘
下面将给出几个tesseract识别图片中文字的例子。
首先是E://figures/other/poems.jpg, 输入命令 tesseract E://figures/other/poems.jpg E://figures/other/poems.txt, 则会将poems.jpg中的识别文字写入到poems.txt中,如下图:
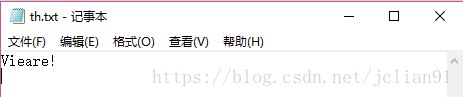
接着是稍微有点倾斜的文字图片th.jpg,识别情况如下:
可以看到识别的情况不如刚才规范字体的好,但是也能识别图片中的大部分字母。
最后是识别简体中文,需要事先安装简体中文语言包,下载地址为:https://github.com/tesseract-ocr/tessdata/find/master/chi_sim.traineddata ,再讲chi_sim.traineddata放在C:\Program Files (x86)\Tesseract-OCR\tessdata目录下。我们以图片timg.jpg为例:
输入命令:





tesseract E://figures/other/timg.jpg E://figures/other/timg.txt -l chi_sim识别结果如下:
只识别错了一个字,识别率还是不错的。
最后加一句,Tesseract对于彩色图片的识别效果没有黑白图片的效果好。

pytesseract
pytesseract是Tesseract关于Python的接口,可以使用pip install pytesseract安装。安装完后,就可以使用Python调用Tesseract了,不过,你还需要一个Python的图片处理模块,可以安装pillow.
输入以下代码,可以实现同上述Tesseract命令一样的效果:
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = 'C://Program Files (x86)/Tesseract-OCR/tesseract.exe'
text = pytesseract.image_to_string(Image.open('E://figures/other/poems.jpg'))
print(text)运行结果如下:

python ocr图片中汉字识别的更多相关文章
- 【转】Python OCR识别图片验证码
转载自:博客 对于某些网站登录的时候,往往需要输入验证码才能实现登录.如果要爬虫这类网站,往往总会比这个验证码导致无法爬取数据.以下介绍一种比较折中的方法,也是比较可行的方法: 实现思想: 1.通过截 ...
- python识别图片中的代码。
在看并发编程网的时候,有些示例代码是以图片的形式出现的,要是此时自己想复制下来的话,只能对着图片敲了,很不爽,于是搜了一下识别图片的网站,有! 把图片上传上去解析,下来txt文本,打开一看,大部分能解 ...
- python OCR 图形识别
1.pip install pyocr 2.pip install PIL 3.安装tesseract-ocr http://jaist.dl.sourceforge.net/project/tess ...
- python实战===用python识别图片中的中文
需要安装的模块 PIL pytesseract 需要下载的工具: http://download.csdn.net/download/bo_mask/10196285 因为之前百度云的链接总失效,所以 ...
- python 识别图片中的汉字
我们就识别上面的汉字. 安装软件tesseract和python库 https://www.cnblogs.com/sea-stream/p/10961580.html 然后新建一个文件夹test,把 ...
- Python识别图片中的文字
1 import os,glob 2 def photo_compression(original_imgage,tmp_image_path): 3 '''图片备份.压缩:param origina ...
- Python OCR提取普通数字图形验证中的数字
截取图形验证码: # -*- coding: UTF-8 -*- ''' Created on 2016年7月4日 @author: xuxianglin ''' import os import t ...
- python ocr中文识别库 tesseract安装及问题处理
这个破东西,折腾了快1个小时,网上的教材太乱了. 我解决的主要是windows的问题 先下载exe.(一看到这个,我就有种预感,不妙) https://digi.bib.uni-mannheim.de ...
- python识别图片中的信息
好好学习的第一步 一心一意的干好一件事儿,问自己 我做什么 我怎么做 做的结果是啥 例子1 问题 回答 我做什么: 识别图片上的信息 我怎么做: 百度+谷歌 结果是啥: 完成识别 1 安装PIL pi ...
随机推荐
- 美国LangeEylandt长岛
LangeEylandt n.长岛(美国) 纽约长岛 纽约长岛 (LongIsland)是北美洲在大西洋内的一个岛,最早追溯到十七世纪的1650年被命名为Lange Eylandt [1] ,位于北美 ...
- 车间管理难?APS系统为你智能排程
对 APS系统不熟或者不了解他的一些运行规则也是在实施项目中导致经常不能正常运行不可忽视的因素,对 APS系统的早期了解是整个项目实施运行的成功至关重要的因素. 如果不了解 APS潜在的因素和运行准则 ...
- SocksCap代理
所有Windows应用都可以使用Socks代理上网,即使不支持Socks代理的应用也可以用Socks代理上网 配置代理 点击"添加",代理类型可以修改, 支持代理测试 运行程序 点 ...
- WPF应用打包流程
1,安装工程模板插件Microsoft Visual Studio Installer Projects https://marketplace.visualstudio.com/items?item ...
- selenium 滚动屏幕操作+上传文件
执行js脚本来滚动屏幕: (x,y)x为0 纵向滚动,y为0横向滚动 负数为向上滚动 driver.execute_script('window.scrollBy(0,250)') 上传文件: 1.导 ...
- Flask介绍及简单使用
Flask Django是一个大而全的框架,Flask是一个轻量级的框架. 区别: Django内部集成了大量的组件:请求处理是逐一封装和传递: Flask本身并没有太多的功能,但是第三方组件非常丰富 ...
- MySQL Replication--TABLE_ID与行格式复制
BINLOG中的TABLE_ID 在ROW格式的二进制中,事件信息中没有列的信息,需要通过Table_Map将表名对于的表信息加载到cache中,然后根据事件信息中的列下标来定位到数据列,每次表信息加 ...
- 基于gtk的imshow:用gtk读取并显示图像
gtk实现imshow,最naive的做法是用gtk的组件去读取图像,然后show出来:后续再考虑用GTK显示用别的方式例如stb image读取的图像.先前基于GDI实现imshow时也是这一思路, ...
- curl请求https资源的时候出现400
在nginx上配置了一个新的域名, 习惯性地用curl请求看看有没有配置错误 因为是https的, 所以 $curl 'https://test.test.com/' -x 127.0.0.1:443 ...
- JMeter+Maven+CSV数据驱动
1.整个工程的目录结构: 2.工程说明: # ddcapitest XXX_API自动化测试 # 一.文件说明: 1. ddcapitest/src/是工程的入口 ddcapitest/pom.xml ...